Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Crea un endpoint Multi-Model
Puoi utilizzare la console SageMaker AI o creare un endpoint AWS SDK per Python (Boto) multimodello. Per creare un endpoint basato su CPU o GPU tramite la console, consulta la procedura della console nelle sezioni seguenti. Se desideri creare un endpoint multimodello con AWS SDK per Python (Boto), utilizza la procedura CPU o GPU descritta nelle sezioni seguenti. I flussi di lavoro della CPU e GPU sono simili ma presentano diverse differenze, come i requisiti del container.
Argomenti
Creare un endpoint a più modelli (console)
È possibile creare endpoint a più modelli supportati da CPU e GPU tramite la console. Utilizza la seguente procedura per creare un endpoint multimodello tramite la console AI. SageMaker
Per creare un endpoint a più modelli (console)
-
Apri la console Amazon SageMaker AI all'indirizzo https://console.aws.amazon.com/sagemaker/
. -
Scegliere Model (Modello), quindi dal gruppo Inference (Inferenza) scegliere Create model (Crea modello).
-
Per Model name (Nome modello), immettere un nome.
-
Per il ruolo IAM, scegli o crea un ruolo IAM a cui è collegata la policy IAM
AmazonSageMakerFullAccess. -
Nella sezione Definizione container per Fornisci artefatti dì modello e immagine di inferenza scegliere Utilizza più modelli.
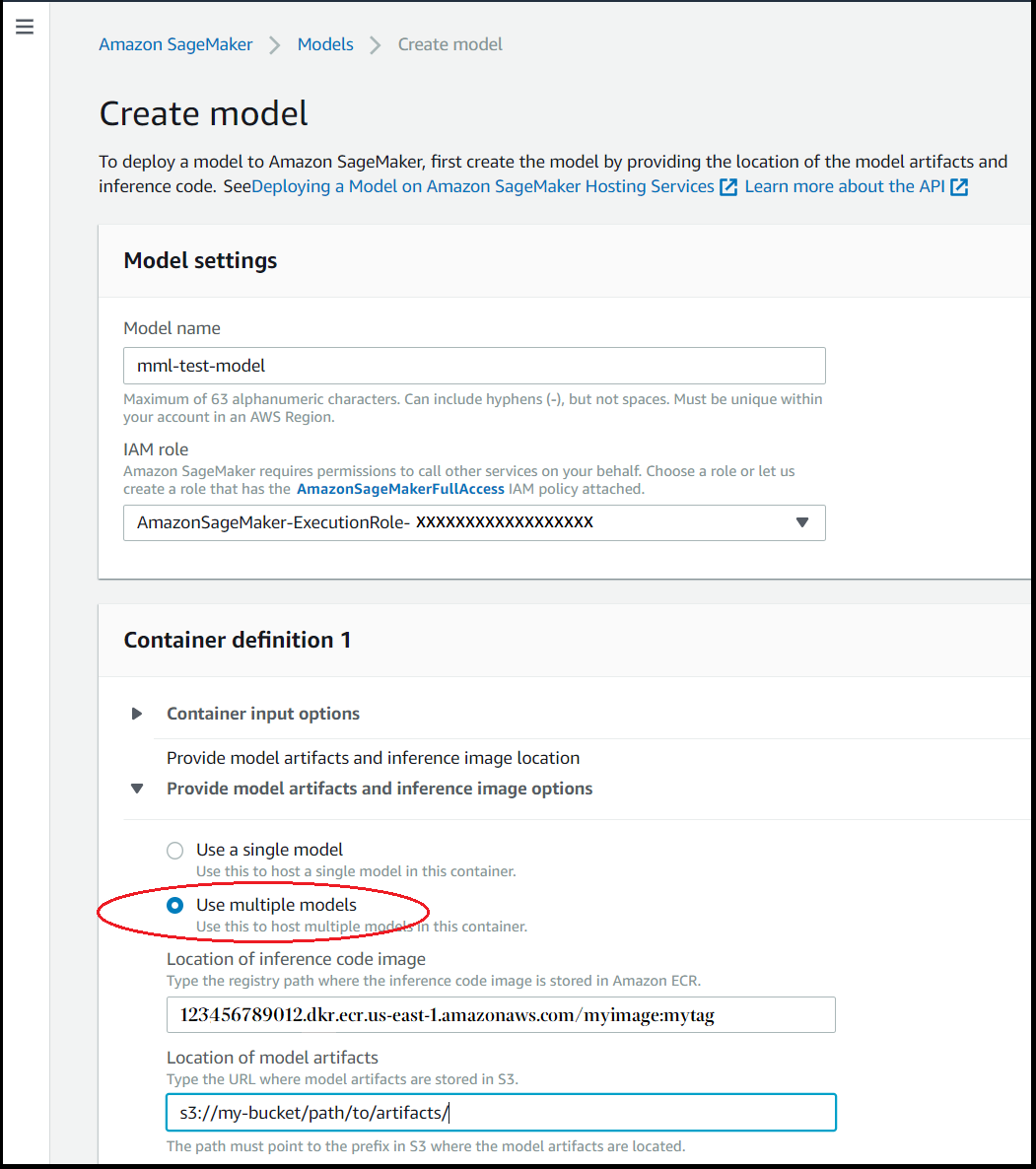
-
Per Immagine del container dell'inferenza, inserisci il percorso Amazon ECR per l'immagine del container desiderata.
Per i modelli GPU, è necessario utilizzare un container supportato da NVIDIA Triton Inference Server. Per un elenco di immagini di container che funzionano con endpoint supportati da GPU, consulta Container di inferenza Triton NVIDIA (solo supporto SM)
. Per ulteriori informazioni su NVIDIA Triton Inference Server, consulta Use Triton Inference Server with AI. SageMaker -
Scegli Crea modello.
-
Distribuire l'endpoint a più modelli come si farebbe con un endpoint a singolo modello. Per istruzioni, consulta Implementa il modello su AI Hosting Services SageMaker.
Crea un endpoint multimodello utilizzando CPU con AWS SDK per Python (Boto3)
Utilizza la sezione seguente per creare un endpoint a più modelli supportato da istanze di CPU. Puoi creare un endpoint multimodello utilizzando Amazon SageMaker AI create_modelcreate_endpointcreate_endpoint_configMode: MultiModel. È inoltre necessario passare il campo ModelDataUrl che specifica il prefisso in S3 Amazon dove si trovano gli artefatti del modello, anziché il percorso di un artefatto di singolo modello, come si farebbe quando si distribuisce un singolo modello.
Nella procedura seguente vengono illustrate le fasi chiave utilizzate nell'esempio per creare un endpoint a più modelli supportato dalla CPU.
Per distribuire il modello (AWS SDK per Python (Boto 3)
-
Procurati un container con un'immagine che supporti la l'implementazione di endpoint a più modelli. Per un elenco di algoritmi e container di framework integrati che supportano endpoint a più modelli, consulta Algoritmi, framework e istanze supportati per endpoint multi-modello. Per questo esempio, utilizziamo l'algoritmo integrato K-Nearest Algoritmo dei vicini (k-NN). Chiamiamo la funzione di utilità SageMaker Python SDK
image_uris.retrieve()per ottenere l'indirizzo per l'immagine dell'algoritmo integrato di K-Nearest Neighbors.import sagemaker region = sagemaker_session.boto_region_name image = sagemaker.image_uris.retrieve("knn",region=region) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } -
Ottieni un client AWS SDK per Python (Boto3) SageMaker AI e crea il modello che utilizza questo contenitore.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Facoltativo) Se si utilizza una pipeline di inferenza seriale, ottenere i container aggiuntivi da includere nella pipeline e includerli nell'argomento
ContainersdiCreateModel:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )Nota
È possibile utilizzare un solo endpoint abilitato a più modelli in una pipeline di inferenza seriale.
-
(Facoltativo) Se il tuo caso d'uso non trae vantaggio dalla memorizzazione nella cache del modello, imposta il valore del campo
ModelCacheSettingdel parametroMultiModelConfigsuDisablede includilo nell'argomentoContainerdella chiamata acreate_model. Il valore di default del campoModelCacheSettingèEnabled.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Configurare l'endpoint a più modelli per il modello. Si consiglia di configurare gli endpoint con almeno due istanze. Ciò consente all' SageMaker intelligenza artificiale di fornire un set di previsioni ad alta disponibilità su più zone di disponibilità per i modelli.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.m4.xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] )Nota
È possibile utilizzare un solo endpoint abilitato a più modelli in una pipeline di inferenza seriale.
-
Creare l'endpoint a più modelli utilizzando i parametri
EndpointNameeEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
Crea un endpoint multimodello utilizzando le GPU con AWS SDK per Python (Boto3)
Utilizza la sezione seguente per creare un endpoint a più modelli supportato da istanze di GPU. Crei un endpoint multimodello utilizzando Amazon SageMaker AI create_modelcreate_endpointcreate_endpoint_configMode: MultiModel. È inoltre necessario passare il campo ModelDataUrl che specifica il prefisso in S3 Amazon dove si trovano gli artefatti del modello, anziché il percorso di un artefatto di singolo modello, come si farebbe quando si distribuisce un singolo modello. Per gli endpoint a più modelli supportati da GPU, devi anche utilizzare un container con NVIDIA Triton Inference Server ottimizzato per l'esecuzione su istanze GPU. Per un elenco di immagini di container che funzionano con endpoint supportati da GPU, consulta Container di inferenza Triton NVIDIA (solo supporto SM)
Per un notebook di esempio che dimostra come creare un endpoint multimodello supportato da GPU, consulta Esegui più modelli di deep learning su GPU con endpoint Amazon AI (MME
Nella procedura seguente vengono illustrate le fasi chiave per creare un endpoint a più modelli supportato dalla GPU.
Per distribuire il modello (AWS SDK per Python (Boto 3)
-
Definizione dell'immagine del container. Per creare un endpoint multimodello con supporto GPU per i ResNet modelli, definisci il contenitore per utilizzare l'immagine del server NVIDIA Triton. Questo container supporta endpoint a più modelli ed è ottimizzato per l'esecuzione su istanze GPU. Chiamiamo la funzione di utilità SageMaker AI Python SDK
image_uris.retrieve()per ottenere l'indirizzo dell'immagine. Esempio:import sagemaker region = sagemaker_session.boto_region_name // Find the sagemaker-tritonserver image at // https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb // Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only image = "<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/sagemaker-tritonserver:<TAG>".format( account_id=account_id_map[region], region=region ) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel', "Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"}, } -
Ottieni un client AWS SDK per Python (Boto3) SageMaker AI e crea il modello che utilizza questo contenitore.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Facoltativo) Se si utilizza una pipeline di inferenza seriale, ottenere i container aggiuntivi da includere nella pipeline e includerli nell'argomento
ContainersdiCreateModel:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )Nota
È possibile utilizzare un solo endpoint abilitato a più modelli in una pipeline di inferenza seriale.
-
(Facoltativo) Se il tuo caso d'uso non trae vantaggio dalla memorizzazione nella cache del modello, imposta il valore del campo
ModelCacheSettingdel parametroMultiModelConfigsuDisablede includilo nell'argomentoContainerdella chiamata acreate_model. Il valore di default del campoModelCacheSettingèEnabled.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Configurare l'endpoint a più modelli con istanze supportate da GPU per il modello. Ti consigliamo di configurare gli endpoint con più di un'istanza per consentire un'elevata disponibilità e maggiori accessi alla cache.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.g4dn.4xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] ) -
Creare l'endpoint a più modelli utilizzando i parametri
EndpointNameeEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
