Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Usa l'algoritmo di SageMaker previsione AI DeepAR
L'algoritmo di previsione Amazon SageMaker AI DeepAR è un algoritmo di apprendimento supervisionato per la previsione di serie temporali scalari (unidimensionali) utilizzando reti neurali ricorrenti (RNN). I metodi di previsione tradizionali, ad esempio il Modello autoregressivo integrato a media mobile (ARIMA, Autoregressive Integrated Moving Average) o il Livellamento esponenziale (ETS, Exponential Smoothing), associano un singolo modello a ogni singola serie temporale. Quindi utilizzano il modello per estrapolare le serie temporali in futuro.
In molte applicazioni, tuttavia, sono presenti molte serie temporali simili in un set di unità trasversali. Ad esempio, potresti avere raggruppamenti di serie temporali per la richiesta di diversi prodotti, carichi del server e pagine Web. Per questo tipo di applicazione, è possibile utilizzare l’addestramento di un singolo modello per tutte le serie temporali. DeepAR adotta questo approccio. Quando il set di dati contiene centinaia di serie temporali correlate, DeepAR ottiene risultati migliori rispetto ai metodi ARIMA ed ETS standard. È anche possibile utilizzare il modello addestrato per generare previsioni per le nuove serie temporali simili a quelle su cui è stato addestrato.
L'input di addestramento per l'algoritmo DeepAR è una o, preferibilmente, più serie temporali target che sono state generate dallo stesso processo o da processi simili. Sulla base di questo set di dati di input, l'algoritmo addestra un modello che ne apprende un'approssimazione e la utilizza per prevedere l'evoluzione della serie temporale target. process/processes Ogni serie temporale target può essere opzionalmente associata a un vettore di caratteristiche di categoria (indipendenti dal tempo) statiche fornite dal campo cat e un vettore di serie temporali (dipendenti dal tempo) dinamiche fornite dal campo dynamic_feat. SageMaker L'intelligenza artificiale addestra il modello DeepAR campionando casualmente esempi di addestramento da ciascuna serie temporale target nel set di dati di addestramento. Ogni esempio di addestramento è costituito da una coppia di finestre di contesto e di previsione adiacenti con lunghezze predefinite fisse. Per controllare fino a quando nel passato può vedere la rete, usa l'iperparametro context_length. Per controllare fino a quando possono essere proiettate le previsioni future, usa l'iperparametro prediction_length. Per ulteriori informazioni, consulta Come funziona l'algoritmo DeepAR.
Argomenti
Input/Output Interfaccia per l'algoritmo DeepAr
DeepAR supporta due canali di dati. Il canale train obbligatorio descrive il set di dati di addestramento. Il canale test facoltativo descrive un set di dati che viene utilizzato dall'algoritmo per valutare l'accuratezza del modello dopo l’addestramento. Puoi fornire i set di dati di test e addestramento nel formato JSON Lines
Quando specifichi i percorsi per i dati di addestramento e di test, puoi indicare un singolo file o una directory contenente più file che possono essere memorizzati in sottodirectory. Se specifichi una directory, DeepAR utilizza come input del canale corrispondente tutti i file presenti nella directory, ad eccezione di quelli che iniziano con un punto (.) e quelli denominati _SUCCESS. In tal modo puoi utilizzare direttamente le cartelle di output prodotte dai processi Spark come canali di input per i processi di addestramento DeepAR.
Per impostazione predefinita, il modello DeepAR determina il formato di input dall'estensione del file (.json, .json.gz o .parquet) nel percorso di input specificato. Se il percorso non termina in una di queste estensioni, devi specificare esplicitamente il formato SDK per Python. Utilizza il parametro content_type della classe s3_input
I record dei file di input devono contenere i seguenti campi:
-
start: una stringa con il formatoYYYY-MM-DD HH:MM:SS. Il timestamp iniziale non è in grado di contenere le informazioni sul fuso orario. -
target: una matrice di numeri interi o valori a virgola mobile che rappresentano le serie temporali. Puoi codificare i valori mancanti come letteralinullo come stringhe"NaN"in JSON oppure come valori in virgola mobilenanin Parquet. -
dynamic_feat(opzionale): una matrice di matrici di numeri interi o valori a virgola mobile che rappresenta il vettore delle serie temporali di funzionalità personalizzate (funzionalità dinamiche). Se imposti questo campo, tutti i record devono avere lo stesso numero di matrici interne (lo stesso numero di serie temporali di caratteristiche). Inoltre, ogni matrice interna deve avere la stessa lunghezza del valoretargetassociato piùprediction_length. I valori mancanti non sono supportati nelle caratteristiche. Ad esempio, se la serie temporale target rappresenta la richiesta di prodotti diversi, undynamic_featassociato potrebbe essere una serie temporale booleana che indica se una promozione è stata applicata (1) o meno (0) al prodotto specifico:{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(opzionale): una serie di funzionalità categoriali che possono essere utilizzate per codificare i gruppi a cui appartiene il record. Le caratteristiche di categoria devono essere codificate come una sequenza in base 0 di numeri interi positivi. Ad esempio, il dominio di categoria {R, G, B} può essere codificato come {0, 1, 2}. Tutti i valori di ciascun dominio di categoria devono essere rappresentati nel set di dati di addestramento. In tal modo l'algoritmo DeepAR può prevedere solo le categorie che sono state osservate durante l’addestramento. Inoltre, ciascuna caratteristica di categoria è incorporata in uno spazio a bassa dimensione le cui dimensioni sono supervisionate dall'iperparametroembedding_dimension. Per ulteriori informazioni, consulta Iperparametri DeepAR.
Se usi un file JSON, il formato del file deve essere JSON Lines
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
In questo esempio, ogni serie temporale ha due caratteristiche di categoria associate e le caratteristiche di una serie temporale.
Per Parquet, puoi usare gli stessi tre campi come colonne. Inoltre, "start" può essere il tipo datetime. Puoi comprimere i file Parquet usando gzip (gzip) o la libreria di compressione Snappy (snappy).
Se l'algoritmo viene addestrato senza i campi cat e dynamic_feat, apprende un modello "globale", che è un modello indipendente rispetto all'identità specifica della serie temporale target durante l'inferenza ed è subordinato solo alla sua forma.
Se il modello è subordinato ai dati caratteristica cat e dynamic_feat forniti per ogni serie temporale, la previsione sarà probabilmente influenzata dal carattere della serie temporale con le caratteristiche cat corrispondenti. Ad esempio, se la serie temporale target rappresenta la richiesta di articoli di vestiario, puoi associare un vettore cat bidimensionale che codifica il tipo di articolo (ad esempio 0 = scarpe, 1 = vestito) nel primo componente e il colore di un articolo (ad esempio, 0 = rosso, 1 = blu) nel secondo componente. L'aspetto di un input di esempio è simile al seguente.
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
Durante l'inferenza, puoi richiedere previsioni per target con valori cat che sono combinazioni dei valori cat osservati nei dati di addestramento, ad esempio:
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
Le seguenti linee guida si applicano ai dati di addestramento:
-
L'ora di inizio e la durata della serie temporale può differire. Ad esempio, nel marketing, i prodotti spesso sono inseriti in un catalogo di vendita al dettaglio in date diverse, pertanto la loro date di inizio differiscono naturalmente. Tutte le serie devono, tuttavia, avere la stessa frequenza, il numero di caratteristiche di categoria e il numero di caratteristiche dinamiche.
-
Il file di addestramento viene ordinato casualmente in base alla posizione delle serie temporali nel file. In altre parole, le serie temporali sono disposte in ordine casuale nel file.
-
Assicurati di impostare correttamente il campo
start. L'algoritmo usa il timestampstartper determinare le caratteristiche interne. -
Se utilizzi le caratteristiche di categoria (
cat), tutte le serie temporali devono avere lo stesso numero di caratteristiche di categoria. Se il set di dati contiene il campocat, l'algoritmo lo utilizza ed estrae la cardinalità dei gruppi dal set di dati. Per impostazione predefinita,cardinalityè"auto". Se il set di dati contiene il campocat, ma non lo vuoi utilizzare, puoi disabilitarlo impostandocardinalitysu"". Se un modello è stato addestrato utilizzando una caratteristicacat, è necessario includerla per l'inferenza. -
Se il set di dati contiene il campo
dynamic_feat, l'algoritmo lo utilizza automaticamente. Tutte le serie temporali devono avere lo stesso numero di serie temporali di caratteristiche. I punti temporali in ciascuna delle serie temporali di caratteristiche corrispondono uno a uno ai punti temporali nel target. Inoltre, la voce nel campodynamic_featdeve avere la stessa lunghezza della voce nel campotarget. Se il set di dati contiene il campodynamic_feat, ma non lo vuoi utilizzare, puoi disabilitarlo impostandonum_dynamic_featsu"". Se il modello è stato addestrato con il campodynamic_feat, è necessario specificare il campo per l'inferenza. Inoltre, ciascuna delle caratteristiche deve avere la lunghezza del target fornito in aggiunta allaprediction_length. In altre parole, sarà necessario fornire il valore della caratteristica in futuro.
Se specifichi dati di canale di testing opzionali, l'algoritmo DeepAR valuta il modello addestrato con parametri di precisione differenti. L'algoritmo calcola la radice dell'errore quadratico medio (RMSE) sui dati di test come segue:
![Formula RMSE: Sqrt (1/nT(Sum [i, t] (y-hat (i, t) -y (i, t)) ^2)).](images/deepar-1.png)
dove yi,t è il valore true della serie temporale i al momento t e ŷi,t corrisponde alla previsione media. La somma è superiore a tutte le serie temporali n nel set di test e agli ultimi punti temporali T per ogni serie temporale, dove Τ corrisponde all'orizzonte di previsione. Puoi specificare la lunghezza dell'orizzonte di previsione impostando l'iperparametro prediction_length. Per ulteriori informazioni, consulta Iperparametri DeepAR.
Inoltre, l'accuratezza della distribuzione della previsione viene valutata dall'algoritmo utilizzando la perdita quantile ponderata. Per un quantile nell'intervallo [0, 1], la perdita quantile ponderata è definita come segue:
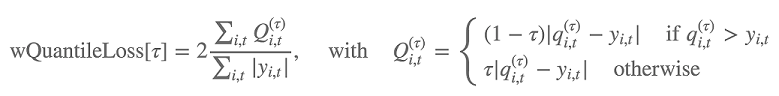
dove qi,t(τ) è il quantile τ della distribuzione che il modello prevede. Per specificare per quali quantili calcolare la perdita, puoi imposta l'iperparametro test_quantiles. Inoltre, la media delle perdite quantile prescritte viene riportata come parte dei log di addestramento. Per informazioni, consulta Iperparametri DeepAR.
Per l'inferenza, DeepAR accetta il formato JSON e i seguenti campi:
-
"instances", che include una o più serie temporali in formato JSON Lines -
Un nome di
"configuration", che comprende i parametri per la generazione della previsione
Per ulteriori informazioni, consulta Formati di inferenza DeepAR.
Best practice per l'utilizzo dell'algoritmo DeepAR
Quando prepari i dati delle serie temporali, segui queste best practice per ottenere i risultati migliori:
-
Fornisci sempre l'intera serie temporale per l’addestramento, il test e la chiamata del modello per l'inferenza, eccetto quando dividi il set di dati per l’addestramento e il test. Indipendentemente dal modo in cui imposti
context_length, non suddividere la serie temporale oppure specificane solo una parte. Il modello utilizza i punti di dati più indietro rispetto al valore impostato incontext_lengthper la caratteristica dei valori ritardati. -
Quando ottimizzi un modello DeepAR, puoi dividere il set di dati per creare un set di dati di addestramento e un set di dati di test. In una valutazione tipica, esegui il test del modello sulle stesse serie temporali utilizzate per l’addestramento, ma sui futuri punti temporali
prediction_lengthche seguono immediatamente dopo l'ultimo punto temporale visibile durante l’addestramento. Puoi creare set di dati di addestramento e di test che soddisfano questo criterio utilizzando l'intero set di dati (l'intera durata di tutte le serie temporali disponibili) come set di test e rimuovendo gli ultimi puntiprediction_lengthda ogni serie temporale per l’addestramento. Durante l’addestramento, il modello non vede i valori di target per i punti temporali su cui viene valutato per il test. Durante il test, l'algoritmo trattiene gli ultimi puntiprediction_lengthdi ogni serie temporale nel set di test e genera una previsione. Quindi confronta la previsione con i valori trattenuti. Puoi creare valutazioni più complesse ripetendo le serie temporali più volte nel set di test, ma tagliandole in corrispondenza di diversi endpoint. Grazie a questo approccio, i parametri di accuratezza vengono calcolati su più previsioni da diversi punti temporali. Per ulteriori informazioni, consulta Ottimizzazione di un modello DeepAR. -
Evita di utilizzare valori molto grandi (>400) per
prediction_lengthperché rende il modello lento e meno accurato. Se vuoi eseguire previsioni ancora più nel futuro, considera l'aggregazione dei dati a una frequenza inferiore. Ad esempio, utilizza5minanziché1min. -
Dal momento che vengono utilizzati i ritardi, un modello può guardare più indietro nelle serie temporali rispetto al valore specificato per
context_length. Pertanto, non è necessario impostare questo parametro su un valore elevato. Ti consigliamo di iniziare con il valore utilizzato perprediction_length. -
Consigliamo di eseguire il training di un modello DeepAR su tutte le serie temporali disponibili. Sebbene un modello DeepAR addestrato su una singola serie temporale possa comunque funzionare bene, gli algoritmi di previsione standard, come ARIMA o ETS, potrebbero fornire risultati più accurati. L'algoritmo DeepAR inizia a ottenere risultati migliori dei metodi standard quando il set di dati contiene centinaia di serie temporali correlate. Al momento, DeepAR richiede che il numero totale di osservazioni disponibili in tutte le serie temporali di addestramento sia almeno 300.
Raccomandazioni dell'istanza EC2 per l'algoritmo DeepAR
Puoi addestrare DeepAR su entrambe le istanze GPU e CPU e nelle impostazioni a macchina singola e a macchine multiple. Ti consigliamo di iniziare con un'istanza CPU singola (ad esempio, ml.c4.2xlarge o ml.c4.4xlarge) e di passare a istanze GPU e a macchine multiple solo quando necessario. L'utilizzo delle GPU e delle macchine multiple migliora il throughput solo per i modelli più grandi (con molte celle per livello e molti livelli) e per i mini-batch di grandi dimensioni (ad esempio, maggiori di 512).
Per l'inferenza, DeepAR supporta solo le istanze CPU.
La specifica di valori elevati per context_length, prediction_length, num_cells, num_layers o mini_batch_size può creare modelli che sono troppo grandi per le istanze small. In questo caso, utilizza un tipo di istanza più grande o riduci i valori per questi parametri. Questo problema si verifica spesso anche durante l'esecuzione dei processi di ottimizzazione iperparametri. In tal caso, utilizza un tipo di istanza sufficientemente grande per il processo di ottimizzazione del modello e prendi in considerazione la limitazione dei valori superiori dei parametri critici per evitare errori di processo.
Notebook di esempio di DeepAR
Per un taccuino di esempio che mostra come preparare un set di dati di serie temporali per addestrare l'algoritmo SageMaker AI DeepAR e come implementare il modello addestrato per eseguire inferenze, vedi la demo di DeepAR sul set di dati sull'elettricità, che illustra le funzionalità avanzate di DeepAR su
Per ulteriori informazioni sull'algoritmo Amazon SageMaker AI DeepAR, consulta i seguenti post di blog:
