Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica dell'apprendimento automatico con Amazon SageMaker
Questa sezione descrive un tipico flusso di lavoro di machine learning (ML) e descrive come eseguire tali attività con Amazon SageMaker.
Nell'apprendimento automatico, si insegna a un computer a fare previsioni o inferenze. In primo luogo, utilizzi un algoritmo e i dati di esempio per addestrare un modello. Quindi, integri il modello nella tua applicazione per generare inferenze in tempo reale e su larga scala.
Il diagramma seguente mostra il flusso di lavoro tipico per la creazione di un modello ML. Include tre fasi di un flusso circolare che tratteremo più dettagliatamente procedendo nel diagramma:
-
Genera dati di esempio
-
Addestra un modello
-
Implementa il modello
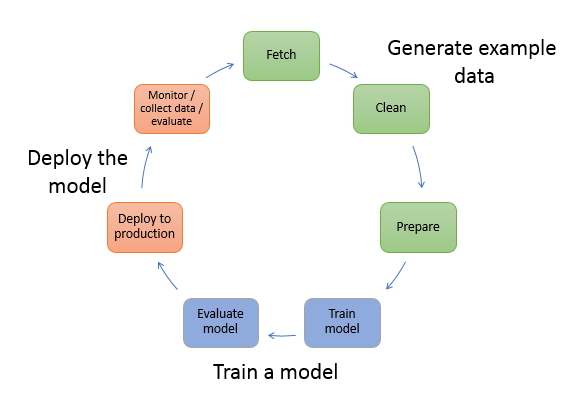
Il diagramma mostra come eseguire le seguenti attività negli scenari più tipici:
-
Generazione di dati di esempio: per addestrare un modello, sono necessari dati di esempio. Il tipo di dati di cui hai bisogno dipende dal problema aziendale che desideri risolvere con il modello. Ciò si riferisce alle inferenze che si desidera che il modello generi. Ad esempio, se desideri creare un modello che preveda un numero a partire da un'immagine di input di una cifra scritta a mano. Per addestrare questo modello, sono necessarie immagini di esempio di numeri scritti a mano.
I data scientist spesso dedicano tempo all'esplorazione e alla preelaborazione di dati di esempio prima di utilizzarli per l'addestramento dei modelli. Per pre-elaborare i dati, in genere devi eseguire le seguenti operazioni:
-
Recupera i dati: potresti avere archivi di dati di esempio interni o utilizzare set di dati disponibili pubblicamente. In genere, estrai uno o più set di dati in un unico repository.
-
Pulisci i dati: per migliorare l'addestramento dei modelli, ispeziona i dati e puliscili, se necessario. Ad esempio, se i dati hanno un
country nameattributo con valoriUnited StateseUS, puoi modificare i dati per renderli coerenti. -
Preparazione o trasformazione dei dati: per migliorare le prestazioni, è possibile eseguire ulteriori trasformazioni dei dati. Ad esempio, potresti scegliere di combinare gli attributi per un modello che preveda le condizioni che richiedono lo scongelamento di un aereo. Invece di utilizzare separatamente gli attributi di temperatura e umidità, è possibile combinare tali attributi in un nuovo attributo per ottenere un modello migliore.
In SageMaker, puoi preelaborare dati di esempio utilizzando SageMaker APIsSageMaker SDKPython
in un ambiente IDE di sviluppo integrato (). Con SDK for Python (Boto3) puoi recuperare, esplorare e preparare i tuoi dati per l'addestramento dei modelli. Per informazioni sulla preparazione, l'elaborazione e la trasformazione dei dati, consulta, e. Consigli per scegliere lo strumento giusto per la preparazione dei dati in SageMaker Carichi di lavoro di trasformazione dei dati con Processing SageMaker Crea, archivia e condividi funzionalità con Feature Store -
-
Addestramento di un modello: la formazione sul modello include sia la formazione che la valutazione del modello, come segue:
-
Addestramento del modello: per addestrare un modello, è necessario un algoritmo o un modello base preaddestrato. L'algoritmo che scegli dipende da un numero di fattori. Per una soluzione integrata, puoi utilizzare uno degli algoritmi forniti. SageMaker Per un elenco degli algoritmi forniti da SageMaker e le relative considerazioni, vedere. Algoritmi integrati e modelli preaddestrati in Amazon SageMaker Per una soluzione di addestramento basata sull'interfaccia utente che fornisce algoritmi e modelli, consulta SageMaker JumpStart modelli preaddestrati.
Hai bisogno di risorse di calcolo per l’addestramento. L'utilizzo delle risorse dipende dalla dimensione del set di dati di allenamento e dalla rapidità con cui sono necessari i risultati. È possibile utilizzare risorse che vanno da una singola istanza generica a un cluster distribuito di istanze. GPU Per ulteriori informazioni, consulta Addestra un modello con Amazon SageMaker.
-
Valutazione del modello: dopo aver addestrato il modello, lo si valuta per determinare se l'accuratezza delle inferenze è accettabile. Per addestrare e valutare il tuo modello, usa SageMaker Python SDK
per inviare richieste al modello per inferenze tramite uno dei metodi disponibili. IDEs Per ulteriori informazioni sulla valutazione del modello, consulta. Monitoraggio della qualità di dati e modelli con Amazon SageMaker Model Monitor
-
-
Implementazione del modello: in genere si riprogetta un modello prima di integrarlo con l'applicazione e distribuirlo. Con i servizi SageMaker di hosting, puoi implementare il tuo modello in modo indipendente, separandolo dal codice dell'applicazione. Per ulteriori informazioni, consulta Implementa modelli per l'inferenza.
Il machine learning è un ciclo continuo. Dopo aver distribuito un modello, si monitorano le inferenze, si raccolgono più dati di alta qualità e si valuta il modello per identificare eventuali deviazioni. Quindi aumentate la precisione delle inferenze aggiornando i dati di addestramento per includere i dati di alta qualità appena raccolti. Man mano che diventano disponibili altri dati di esempio, continuate a riaddestrare il modello per aumentare la precisione.
