Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione, archiviazione e condivisione di funzionalità con l’archivio delle caratteristiche
Il processo di sviluppo del machine learning (ML) include l’estrazione di dati non elaborati e la loro trasformazione in funzionalità (input significativi per il modello di ML). Queste funzionalità vengono quindi archiviate in modo fruibile per l’esplorazione dei dati, l’addestramento di ML e l’inferenza di ML. Amazon SageMaker Feature Store semplifica il modo in cui crei, archivia, condividi e gestisci le funzionalità. Per farlo, fornisce opzioni di archivio delle caratteristiche e riduce il lavoro ripetitivo di elaborazione e cura dei dati.
Tra le altre cose, con l’archivio delle caratteristiche puoi:
-
Semplificare l’elaborazione, l’archiviazione, il recupero e la condivisione delle funzionalità per lo sviluppo del ML tra account o all’interno di un’organizzazione.
-
Monitorare lo sviluppo del codice di elaborazione delle funzionalità, applicare il Processore di funzionalità ai dati non elaborati e inserire le tue funzionalità nell’archivio delle caratteristiche in modo coerente. In questo modo si riduce l’asimmetria addestramento-servizio, un problema comune nel machine learning, in cui la differenza tra le prestazioni durante l’addestramento e quelle durante il servizio può influire sull’accuratezza del modello di ML.
-
Archiviare funzionalità e metadati associati in gruppi di funzionalità, in modo che le funzionalità possano essere facilmente rilevate e riutilizzate. I gruppi di funzionalità sono soggetti a cambiamenti e possono modificare il proprio schema dopo la creazione.
-
Creare gruppi di funzionalità che possono essere configurati per includere un archivio online o offline, o entrambi, per gestire le funzionalità e automatizzare il modo in cui vengono archiviate per le attività di ML.
-
L’archivio online conserva solo i record più recenti per le funzionalità. È progettato principalmente per supportare previsioni in tempo reale che richiedono letture a bassa latenza in millisecondi e scritture ad alto throughput.
-
L’archivio offline conserva tutti i record relativi alle funzionalità come database cronologico. È destinato principalmente all’esplorazione dei dati, all’addestramento dei modelli e alle previsioni batch.
-
Il diagramma seguente mostra come utilizzare l’archivio delle caratteristiche nell’ambito della pipeline di ML. Dopo aver letto i dati non elaborati, puoi utilizzare l’archivio delle caratteristiche per trasformare questi dati in funzionalità e inserirli nel tuo gruppo di funzionalità. Le funzionalità possono essere importate tramite streaming o in batch negli archivi online e offline del gruppo di funzionalità. Le funzionalità possono quindi essere utilizzate per l’esplorazione dei dati, l’addestramento dei modelli e l’inferenza in tempo reale o in batch.
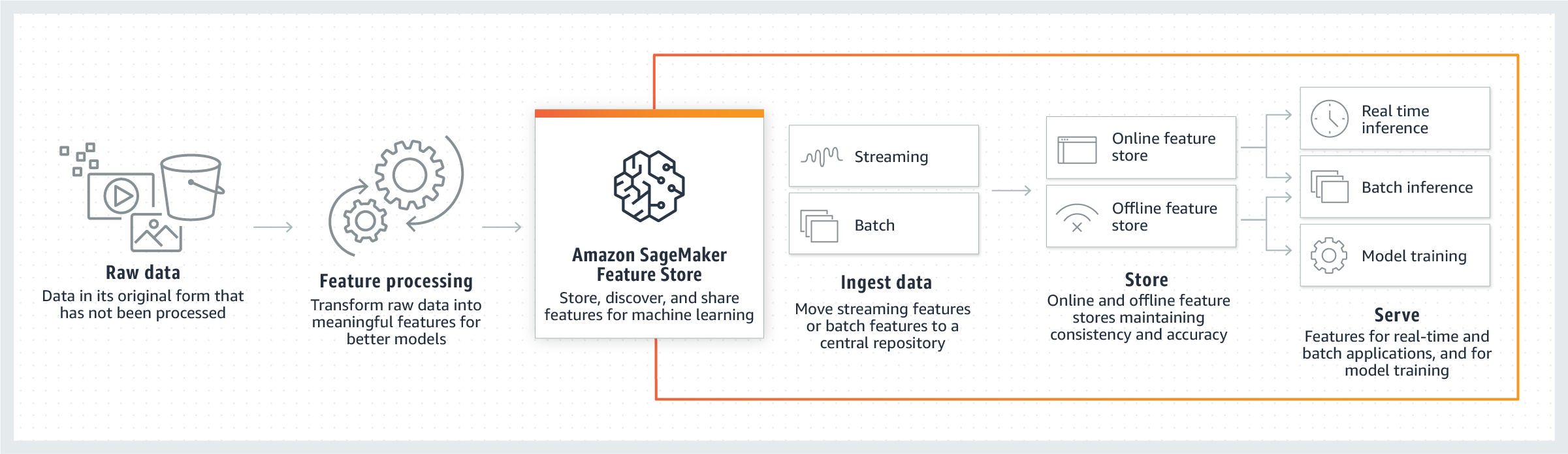
Funzionamento di Feature Store
Nel Feature Store, le funzionalità sono archiviate in una raccolta denominata gruppo di funzionalità. È possibile visualizzare un gruppo di funzionalità come una tabella in cui ogni colonna è una funzionalità, con un identificativo univoco per ogni riga. In linea di principio, un gruppo di funzionalità è composto da funzionalità e valori specifici per ciascuna funzionalità. Un Record è una raccolta di valori per funzionalità che corrispondono a un RecordIdentifier univoco. Complessivamente, un FeatureGroup è un gruppo di funzionalità definite in FeatureStore per descrivere un Record.
Puoi utilizzare Feature Store nelle seguenti modalità:
-
Online: in modalità online, le funzionalità vengono elaborate con letture a bassa latenza (millisecondi) e utilizzate per previsioni ad alta resa. Questa modalità richiede l'archiviazione di un gruppo di funzionalità in un archivio online.
-
Offline: in modalità offline, grandi flussi di dati vengono inviati a un archivio offline, che può essere utilizzato per l’addestramento e l'inferenza in batch. Questa modalità richiede che un gruppo di funzionalità venga memorizzato in un archivio offline. L’archivio offline utilizza il tuo bucket S3 per l'archiviazione e può inoltre recuperare dati utilizzando le query Athena.
-
Online e offline: include sia la modalità online sia quella offline.
Puoi inserire dati in gruppi di funzionalità nel Feature Store in due modi: in streaming o in batch. Quando si importano dati tramite streaming, una raccolta di record viene inviata al Feature Store mediante chiamata API PutRecord sincrona. Questa API consente di mantenere i valori delle funzionalità più recenti nel Feature Store e di inviare nuovi valori delle funzionalità non appena viene rilevato un aggiornamento.
In alternativa, Feature Store può elaborare e importare dati in batch. Ad esempio, puoi creare funzionalità utilizzando Amazon SageMaker Data Wrangler ed esportare un notebook da Data Wrangler. Il notebook può essere un SageMaker processo di elaborazione che inserisce le funzionalità in batch in un gruppo di funzionalità del Feature Store. Questa modalità consente l'inserimento in batch nell'archivio offline. Supporta inoltre l'inserimento nell’archivio online se il gruppo di funzionalità è configurato per l'utilizzo sia online sia offline.
Creazione di gruppi di funzionalità
Per importare funzionalità nel Feature Store, occorre prima specificare il gruppo di funzionalità e le definizioni delle funzionalità (nome della funzionalità e tipo di dati) per tutte le funzionalità che appartengono al gruppo di funzionalità. Dopo la loro creazione, i gruppi di funzionalità sono mutevoli e possono evolvere il loro schema. I nomi dei gruppi di funzionalità sono univoci all'interno di un e Regione AWS . Account AWS Insieme a un gruppo di funzionalità, puoi creare anche i metadati di tale gruppo. I metadati possono contenere una breve descrizione, una configurazione di archiviazione, funzionalità per l’identificazione di ogni record e l’ora dell’evento. Inoltre, i metadati possono includere tag per archiviare informazioni come l’autore, l’origine dati, la versione e altro.
Importante
I nomi FeatureGroup o i metadati associati, come la descrizione o i tag, non devono contenere informazioni personali identificabili (PII) o informazioni riservate.
Ricerca, individuazione e condivisione di funzionalità
Dopo aver creato un gruppo di funzionalità nel Feature Store, altri utenti autorizzati del Feature Store possono individuarlo e condividerlo. Gli utenti possono sfogliare un elenco di tutti i gruppi di funzionalità nel Feature Store o individuare i gruppi di funzionalità esistenti effettuando una ricerca del gruppo di funzionalità per nome, descrizione, nome identificativo del record, data di creazione e tag.
Real-time inferenza per le funzionalità memorizzate nel negozio online
Con Feature Store, puoi arricchire le funzionalità memorizzate nell'archivio online in tempo reale con dati provenienti da una fonte di streaming (rielaborazione di dati di streaming da un'altra applicazione) e fornire le funzionalità con una bassa latenza in millisecondi per l'inferenza in tempo reale.
È inoltre possibile eseguire unioni tra diversi FeatureGroups per l'inferenza in tempo reale eseguendo query su due diversi FeatureGroups nell'applicazione client.
Archivio offline per l'addestramento dei modelli e l'inferenza in batch
Feature Store offre l'archiviazione offline dei valori delle funzionalità nel bucket S3. I dati vengono archiviati nel bucket S3 utilizzando uno schema di prefisso basato sull'ora dell'evento. L’archivio offline è un archivio di sola aggiunta, che consente a Feature Store di mantenere un record storico di tutti i valori delle funzionalità. I dati vengono memorizzati nell'archivio offline in formato Parquet per ottimizzare l'archiviazione e l'accesso alle query.
Puoi eseguire query, esplorare e visualizzare le funzionalità utilizzando Data Wrangler dalla console. Feature Store supporta la combinazione di dati per produrre, addestrare, convalidare e testare set di dati, consentendo di estrarre dati in momenti diversi.
Inserimento dei dati sulle funzionalità
È possibile creare pipeline di generazione di funzionalità per elaborare batch di grandi dimensioni (1 milione di righe di dati o più) o piccoli batch per scrivere dati sulle funzionalità nell'archivio offline o online. Le fonti di streaming come Amazon Managed Streaming for Apache Kafka o Amazon Kinesis possono essere utilizzate anche come fonti di dati da cui estrarre le funzionalità e inviarle direttamente all'archivio online per l’addestramento, l'inferenza o la creazione di funzionalità.
Puoi inviare i record al Feature Store mediante chiamata API PutRecord sincrona. Poiché si tratta di una chiamata API sincrona, consente di inviare piccoli batch di aggiornamenti in una singola chiamata API. Ciò consente di mantenere sempre aggiornati i valori delle funzionalità, pubblicandoli non appena viene rilevato un aggiornamento. Queste sono anche dette funzionalità di streaming.
Quando i dati sulle funzionalità vengono acquisiti e aggiornati, Feature Store archivia i dati storici per tutte le funzionalità nell'archivio offline. Per l'acquisizione in batch, puoi estrarre i valori delle funzionalità dal tuo bucket S3 o utilizzare Athena per eseguire query. Puoi anche utilizzare Data Wrangler per elaborare e progettare nuove funzionalità, che possono quindi essere esportate in un bucket S3 di tua scelta a cui accedere tramite Feature Store. Per l'inserimento in batch, puoi configurare un processo di elaborazione per importare in batch i tuoi dati nel Feature Store, oppure puoi estrarre i valori delle funzionalità dal tuo bucket S3 utilizzando Athena.
Per rimuovere un file Record dal tuo archivio online, usa la chiamata DeleteRecord API. L’operazione aggiungerà anche il record eliminato all'archivio offline.
Resilienza nel Feature Store
Feature Store è distribuito su più zone di disponibilità (AZ). Una AZ è una posizione isolata all'interno di un Regione AWS. Se non è possibile utilizzare alcune AZ, Feature Store può utilizzarne altre. Per ulteriori informazioni sulle AZ, consulta Resilienza nell'IA di Amazon SageMaker.
