Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Risultati delle raccomandazioni
Ogni risultato del processo del suggeritore di inferenza include InstanceType, InitialInstanceCount e EnvironmentParameters, che sono parametri di variabili di ambiente ottimizzati per il container per migliorarne la latenza e il throughput. I risultati includono anche parametri relativi a prestazioni e costi come MaxInvocations, ModelLatency, CostPerHour, CostPerInference, CpuUtilization e MemoryUtilization.
Nella tabella seguente forniamo una descrizione di questi parametri. Questi parametri possono aiutarti a restringere la ricerca per trovare la migliore configurazione di endpoint adatta al proprio caso d'uso. Ad esempio, se si ritiene importante il rapporto prezzo/prestazioni complessive con un'enfasi sulla produttività, allora è opportuno concentrarsi su CostPerInference.
| Parametro | Descrizione | Caso d'uso |
|---|---|---|
|
|
L'intervallo di tempo impiegato da un modello per rispondere visto dall' SageMaker IA. Questo intervallo include il tempo per le comunicazioni locali impiegato per inviare la richiesta e recuperare la risposta dal container di un modello e il tempo richiesto per completare l'inferenza nel container. Unità: millisecondi |
Carichi di lavoro sensibili alla latenza, come la pubblicazione di annunci e le diagnosi mediche |
|
|
Il numero massimo di richieste Unità: nessuna |
Carichi di lavoro incentrati sul throughput, come l'elaborazione video o l'inferenza in batch |
|
|
Il costo orario stimato per il proprio endpoint in tempo reale. Unità: dollari americani |
Carichi di lavoro sensibili ai costi senza termini di latenza |
|
|
Il costo stimato per chiamata di inferenza per l'endpoint in tempo reale. Unità: dollari americani |
Massimizza il rapporto prezzo/prestazioni complessive con particolare attenzione al throughput |
|
|
L'utilizzo previsto della CPU al massimo numero di invocazioni al minuto per l'istanza dell'endpoint. Unità: percentuale |
Comprendi lo stato dell'istanza durante il benchmarking grazie alla visibilità dell'utilizzo della CPU principale dell'istanza |
|
|
L'utilizzo della memoria previsto al massimo numero di invocazioni al minuto per l'istanza dell'endpoint. Unità: percentuale |
Comprendi lo stato dell'istanza durante il benchmarking grazie alla visibilità sull'utilizzo della memoria principale dell'istanza |
In alcuni casi potresti voler esplorare altre metriche di SageMaker AI Endpoint Invocation come. CPUUtilization Ogni risultato del processo del suggeritore di inferenza include i nomi degli endpoint attivati durante il test di carico. Puoi utilizzarli CloudWatch per rivedere i log di questi endpoint anche dopo che sono stati eliminati.
L'immagine seguente è un esempio di CloudWatch metriche e grafici che puoi esaminare per un singolo endpoint in base ai risultati delle tue raccomandazioni. Questo risultato delle raccomandazioni deriva da un processo predefinito. Il modo di interpretare i valori scalari dei risultati delle raccomandazioni consiste nel fatto che si basano sul momento in cui il grafico delle invocazioni inizia ad appianarsi per la prima volta. Ad esempio, il valore ModelLatency riportato si trova all'inizio del plateau intorno a 03:00:31.
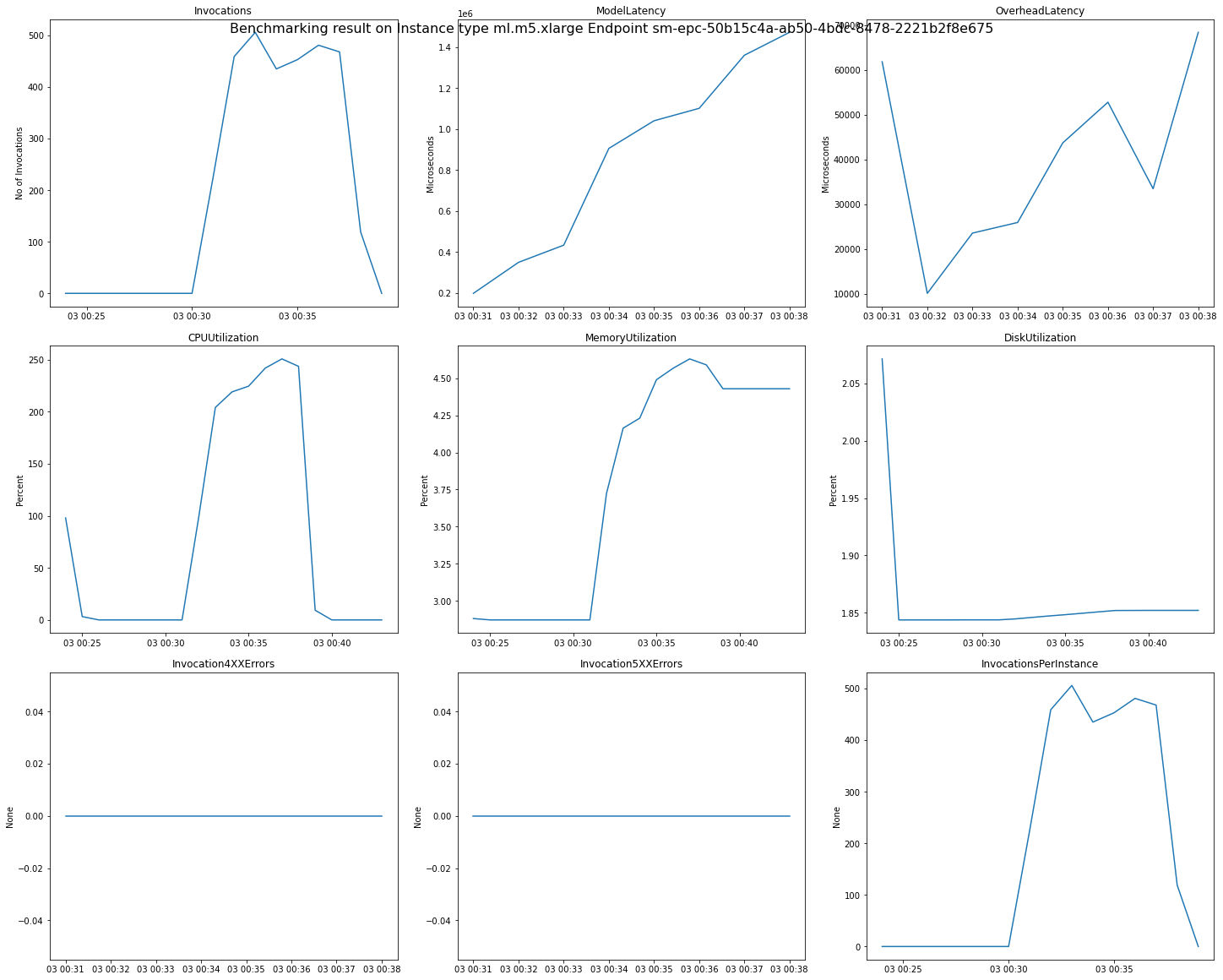
Per le descrizioni complete delle CloudWatch metriche utilizzate nei grafici precedenti, consulta le metriche di SageMaker AI Endpoint Invocation.
Puoi anche vedere parametri delle prestazioni come ClientInvocations e NumberOfUsers pubblicati dal suggeritore di inferenza nello spazio dei nomi /aws/sagemaker/InferenceRecommendationsJobs. Per un elenco completo di parametri e descrizioni pubblicati dal suggeritore di inferenza, consulta SageMaker Metriche dei lavori di Inference Recommender.
Consulta il notebook Amazon SageMaker Inference Recommender - CloudWatch Metrics
