Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Le sezioni seguenti illustrano gli scenari in cui potresti voler ampliare la formazione e come farlo utilizzando AWS le risorse. Potresti voler ampliare la formazione in una delle seguenti situazioni:
-
Scalabilità da una singola GPU a molte GPUs
-
Scalabilità da una singola istanza a più istanze
-
Utilizzo di script di formazione personalizzati
Scalabilità da una singola GPU a molte GPUs
La quantità di dati o le dimensioni del modello utilizzato nel machine learning possono creare situazioni in cui il tempo necessario per addestrare un modello è più lungo di quanto si sia disposti ad aspettare. A volte, l'addestramento non funziona affatto perché il modello o i dati di addestramento sono troppo grandi. Una soluzione consiste nell'aumentare il numero di utenti utilizzati per GPUs la formazione. In un'istanza con più istanze GPUs, ad esempio una p3.16xlarge che ne ha otto GPUs, i dati e l'elaborazione vengono suddivisi tra le otto istanze GPUs. Quando utilizzi librerie di addestramento distribuito, può verificarsi un'accelerazione quasi lineare del tempo necessario per addestrare il modello. Richiede poco più di 1/8 del tempo impiegato su p3.2xlarge con una sola GPU.
| Tipo di istanza | GPUs |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
Nota
I tipi di istanze ml utilizzati dalla SageMaker formazione hanno lo stesso numero dei GPUs tipi di istanze p3 corrispondenti. Ad esempio, ml.p3.8xlarge ha lo stesso numero GPUs di p3.8xlarge - 4.
Scalabilità da una singola istanza a più istanze
Se desideri ampliare ulteriormente il tuo addestramento, puoi utilizzare più istanze. Tuttavia, dovresti scegliere un tipo di istanza più grande prima di aggiungere altre istanze. Consulta la tabella precedente per vedere quante ce ne GPUs sono in ogni tipo di istanza p3.
Se sei passato da una singola GPU su una p3.2xlarge a quattro GPUs su unap3.8xlarge, ma decidi che hai bisogno di maggiore potenza di elaborazione, potresti ottenere prestazioni migliori e costi inferiori se scegli una p3.16xlarge prima di provare ad aumentare il numero di istanze. A seconda delle librerie utilizzate, se mantieni l'addestramento su una singola istanza, le prestazioni sono migliori e i costi sono inferiori rispetto a uno scenario in cui si utilizzano più istanze.
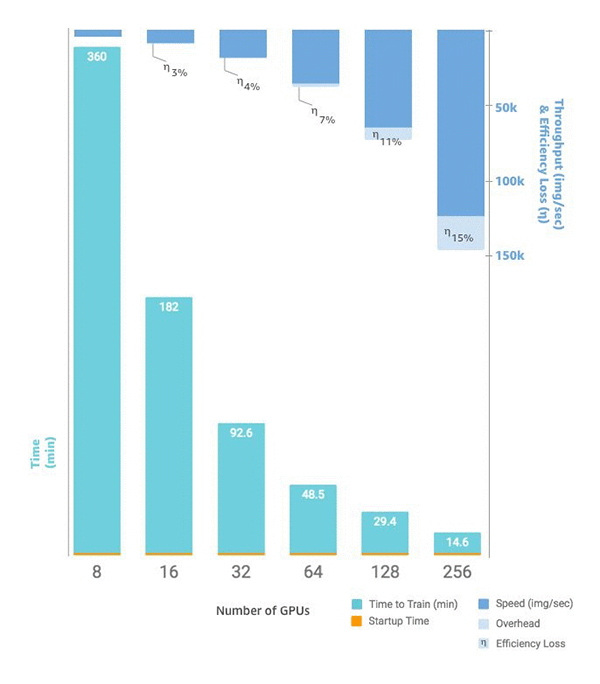
Quando sei pronto per ridimensionare il numero di istanze, puoi farlo con la funzione SageMaker AI Python estimator SDK impostando il tuo. instance_count Ad esempio, puoi impostare instance_type = p3.16xlarge e instance_count =
2. Invece di otto GPUs su una singola istanzap3.16xlarge, ne hai 16 GPUs su due istanze identiche. Il grafico seguente mostra la scalabilità e il throughput a partire da otto
Script di addestramento personalizzati
L' SageMaker intelligenza artificiale semplifica l'implementazione e la scalabilità del numero di istanze e GPUs, a seconda del framework scelto, la gestione dei dati e dei risultati può essere molto impegnativa, motivo per cui vengono spesso utilizzate librerie di supporto esterne. Questa forma più elementare di formazione distribuita richiede la modifica dello script di formazione per gestire la distribuzione dei dati.
SageMaker L'intelligenza artificiale supporta anche Horovod e le implementazioni di formazione distribuita native di ogni principale framework di deep learning. Se scegli di utilizzare esempi tratti da questi framework, puoi seguire la guida ai container di SageMaker AI per Deep Learning Containers e vari taccuini di esempio
