Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Automatizza l'etichettatura dei dati
Se lo desideri, Amazon SageMaker Ground Truth può utilizzare l'apprendimento attivo per automatizzare l'etichettatura dei dati di input per determinati tipi di attività integrate. L'apprendimento attivo è una tecnica di machine learning che consente di identificare i dati che devono essere etichettati dai worker. In Ground Truth, questa funzionalità è chiamata etichettatura dei dati automatica. L'etichettatura dei dati automatica aiuta a ridurre i costi e i tempi necessari per etichettare il set di dati rispetto al solo impiego di esseri umani. Quando utilizzi l'etichettatura automatica, devi sostenere costi di formazione e inferenza. SageMaker
Si consiglia di utilizzare l'etichettatura dei dati automatica su set di dati di grandi dimensioni perché le reti neurali utilizzate con l'apprendimento attivo richiedono una quantità significativa di dati per ogni nuovo set di dati. In genere, man mano che fornisci più dati, aumenta il potenziale per le previsioni di alta precisione. I dati saranno etichettati automaticamente solo se la rete neurale utilizzata nel modello di etichettatura automatica può raggiungere un livello di accuratezza sufficientemente elevato. Pertanto, con set di dati più grandi, puoi etichettare automaticamente i dati perché la rete neurale può ottenere una precisione sufficiente per l'etichettatura automatica. L'etichettatura dei dati automatica è più appropriata quando disponi di migliaia di oggetti dati. Il numero minimo di oggetti consentiti per l'etichettatura dei dati automatica è di 1.250, ma consigliamo vivamente di fornire un minimo di 5.000 oggetti.
L'etichettatura dei dati automatica è disponibile solo per i seguenti tipi di attività integrate Ground Truth:
-
Creare un processo di classificazione delle immagini (etichetta singola)
-
Identifica i contenuti delle immagini utilizzando la segmentazione semantica
-
Rilevamento di oggetti (Classificare gli oggetti dell'immagine utilizzando un riquadro di delimitazione)
-
Classificazione del testo con classificazione del testo (etichetta singola)
I processi di etichettatura in streaming non supportano l'etichettatura dei dati automatica.
Per ulteriori informazioni su come creare un flusso di lavoro di apprendimento attivo personalizzato utilizzando il tuo modello, consulta Imposta un flusso di lavoro di apprendimento attivo con il tuo modello.
Le quote dei dati di input si applicano ai processi di etichettatura dei dati automatica. Per informazioni sulle dimensioni del set di dati, sulla dimensione dei dati di input e sui limiti di risoluzione, consulta Quote dei dati di input.
Nota
Prima di utilizzare un modello di etichettatura automatica in produzione, devi perfezionare o testare il prodotto, o eseguire entrambe le attività. Puoi ottimizzare il modello (o creare e ottimizzare un altro modello supervisionato di tua scelta) sul set di dati prodotto dal processo di etichettatura per ottimizzare l'architettura e gli iperparametri del modello. Se decidi di utilizzare il modello per inferenza senza ottimizzazione, ti consigliamo di verificare la sua precisione su un sottoinsieme rappresentativo (ad esempio, selezionato casualmente) del set di dati etichettato con Ground Truth e che corrisponda alle tue aspettative.
Come funziona
Puoi abilitare l'etichettatura dei dati automatica quando crei un processo di etichettatura. Ecco come funziona:
-
Quando Ground Truth avvia un processo di etichettatura dei dati automatica, seleziona un campione casuale di oggetti di dati di input e lo invia ai worker umani. Se più del 10% di questi oggetti di dati fallisce, il processo di etichettatura avrà esito negativo. Se il processo di etichettatura fallisce, oltre a esaminare ogni messaggio di errore restituito da Ground Truth, verifica che i dati di input vengano visualizzati correttamente nell'interfaccia utente del worker, che le istruzioni siano chiare e che i worker abbiano tempo sufficiente per completare le attività.
-
Quando i dati etichettati vengono restituiti, vengono utilizzati per creare un set di addestramento e un set di convalida. Ground Truth utilizza questi set di dati per addestrare e convalidare il modello utilizzato per l'etichettatura automatica.
-
Ground Truth esegue un processo di addestramento in batch, utilizzando il modello convalidato per l'inferenza sui dati di convalida. L'inferenza in batch produce un punteggio di attendibilità e un parametro di qualità per ogni oggetto nei dati di convalida.
-
Il componente di etichettatura automatica utilizzerà questi parametri di qualità e i punteggi di attendibilità per creare una soglia di attendibilità che garantisca etichette di qualità.
-
Ground Truth esegue un processo di trasformazione in batch sui dati non etichettati nel set di dati, utilizzando lo stesso modello convalidato per l'inferenza. Questo produce un punteggio di attendibilità per ogni oggetto.
-
Il componente di etichettatura automatica Ground Truth determina se il punteggio di attendibilità prodotto nella fase 5 per ciascun oggetto soddisfa la soglia richiesta determinata nella fase 4. Se il punteggio di attendibilità soddisfa il valore di soglia, la qualità prevista dell'etichettatura automatica supera il livello di attendibilità richiesto e tale oggetto è considerato auto-etichettato.
-
La fase 6 produce un set di dati non etichettati con punteggi di attendibilità. Ground Truth seleziona i punti dati con punteggi di attendibilità bassi da questo set di dati e li invia ai worker umani.
-
Ground Truth utilizza i dati esistenti etichettati dai worker umani e questi dati aggiuntivi etichettati dai worker umani per aggiornare il modello.
-
Il processo viene ripetuto fino a quando il set di dati è completamente etichettato o fino a quando non viene soddisfatta un'altra condizione di arresto. Ad esempio, l'etichettatura automatica si interrompe se viene raggiunto il budget relativo all’annotazione umana.
Le fasi precedenti avvengono in iterazioni. Seleziona ogni scheda nella tabella seguente per visualizzare un esempio dei processi che avvengono in ogni iterazione di un processo di etichettatura automatico con rilevamento di oggetti. Il numero di oggetti dati utilizzati in una determinata fase in queste immagini (ad esempio, 200) è specifico di questo esempio. Se ci sono meno di 5.000 oggetti da etichettare, la dimensione del set di convalida è pari al 20% dell'intero set di dati. Se ci sono più di 5.000 oggetti da etichettare, la dimensione del set di convalida è pari al 10% dell'intero set di dati. Puoi controllare il numero di etichette umane raccolte per iterazione di apprendimento attivo modificando il valore per MaxConcurrentTaskCount quando utilizzi l'operazione API CreateLabelingJob. Questo valore è impostato su 1.000 quando crei un processo di etichettatura utilizzando la console. Nel flusso di apprendimento attivo illustrato nella scheda Apprendimento attivo, questo valore è impostato su 200.
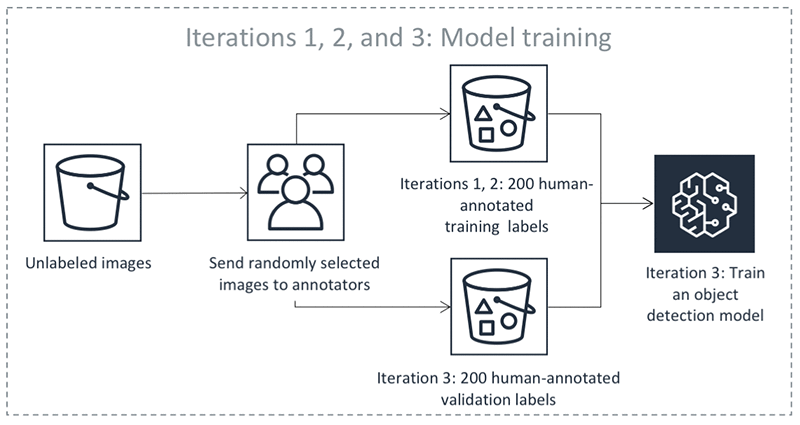
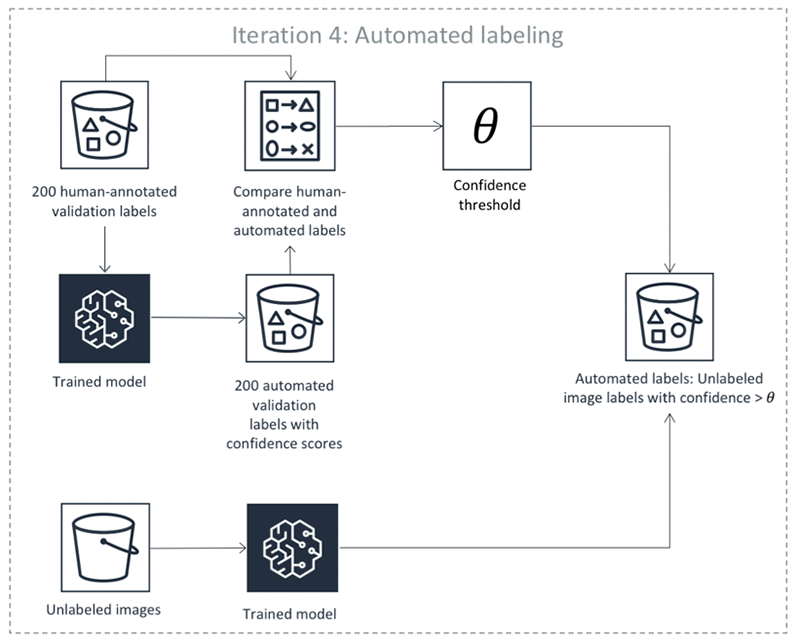
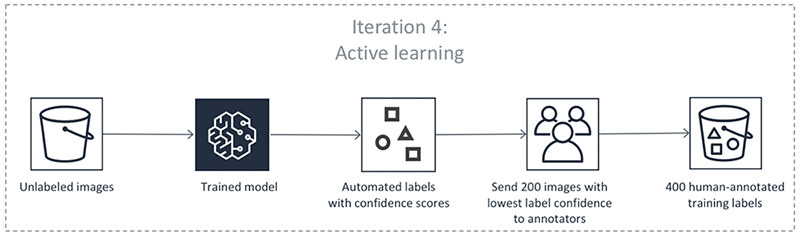
Precisione delle etichette automatiche
La definizione di accuratezza dipende dal tipo di attività integrata utilizzata con l'etichettatura automatica. Per tutti i tipi di attività, questi requisiti di accuratezza sono predeterminati da Ground Truth e non possono essere configurati manualmente.
-
Per la classificazione delle immagini e del testo, Ground Truth utilizza la logica per trovare un livello di attendibilità di previsione delle etichette che corrisponda ad almeno il 95% di accuratezza dell'etichetta. Ciò significa che Ground Truth si aspetta che l'accuratezza delle etichette automatiche sia almeno del 95% rispetto alle etichette che gli etichettatori umani fornirebbero per quegli esempi.
-
Per i riquadri di delimitazione, la media prevista dell'Intersection Over Union (IoU)
delle immagini etichettate automaticamente è 0,6. Per trovare l'IoU medio, Ground Truth calcola l'IoU medio di tutti i riquadri previsti e mancati sull'immagine per ogni classe, quindi calcola la media di questi valori tra le classi. -
Per la segmentazione semantica, l'IoU medio previsto delle immagini etichettate automaticamente è 0,7. Per trovare l'IoU medio, Ground Truth prende la media dei valori IoU di tutte le classi nell'immagine (escluso lo sfondo).
Ad ogni iterazione di apprendimento attivo (fasi 3-6 nell'elenco precedente), la soglia di attendibilità viene rilevata utilizzando il set di convalida con annotazioni umane in modo che l'accuratezza prevista degli oggetti etichettati automaticamente soddisfi determinati requisiti di accuratezza predefiniti.
Crea un processo di etichettatura automatizzato dei dati (console)
Per creare un processo di etichettatura che utilizzi l'etichettatura automatica nella console SageMaker AI, utilizza la seguente procedura.
Per creare un processo di etichettatura dei dati (console) automatica
-
Apri la sezione dei lavori di etichettatura di Ground Truth della console SageMaker AI:https://console.aws.amazon.com/sagemaker/groundtruth
. -
Usando Creazione di un processo di etichettatura (console) come guida, completa le sezioni Panoramica dei processi e Tipo di attività. Tieni presente che l'etichettatura automatica non è supportata per i tipi di attività personalizzati.
-
In Worker, scegli il tipo di forza lavoro.
-
Nella stessa sezione, scegli Abilita l'etichettatura dei dati automatica.
-
Configura lo strumento Bounding BoxCome guida, crea le istruzioni per i lavoratori nello strumento di
Task Typeetichettatura della sezione. Ad esempio, se hai selezionato Segmentazione semantica come tipo di processo di etichettatura, questa sezione sarà intitolata Strumento di etichettatura della segmentazione semantica. -
Per visualizzare in anteprima le istruzioni del worker e il pannello di controllo, scegli Anteprima.
-
Scegli Create (Crea) . Così facendo, verranno creati e avviati il processo di etichettatura e il processo di etichettatura automatica.
Puoi vedere il tuo lavoro di etichettatura apparire nella sezione Labeling jobs della SageMaker console AI. I dati di output verranno visualizzati nel bucket Amazon S3 specificato durante la creazione del processo di etichettatura. Per ulteriori informazioni sul formato e la struttura dei file dei dati di output del processo di etichettatura, consulta Etichettatura dei dati di output del lavoro.
Crea un processo automatizzato di etichettatura dei dati (API)
Per creare un processo di etichettatura automatizzato dei dati utilizzando l' SageMaker API, utilizza il LabelingJobAlgorithmsConfigparametro dell'CreateLabelingJoboperazione. Per informazioni su come avviare un processo di etichettatura utilizzando l'operazione CreateLabelingJob, consulta Creazione di un processo di etichettatura (API).
Specificate nel parametro l'Amazon Resource Name (ARN) dell'algoritmo che state utilizzando per l'etichettatura automatica dei dati. LabelingJobAlgorithmSpecificationArn Scegli uno dei quattro algoritmi Ground Truth integrati supportati con l'etichettatura automatica:
-
Creare un processo di classificazione delle immagini (etichetta singola)
-
Identifica i contenuti delle immagini utilizzando la segmentazione semantica
-
Rilevamento di oggetti (Classificare gli oggetti dell'immagine utilizzando un riquadro di delimitazione)
-
Classificazione del testo con classificazione del testo (etichetta singola)
Al termine di un processo di etichettatura dei dati automatica, Ground Truth restituisce l'ARN del modello utilizzato per il processo di etichettatura dei dati automatica. Utilizzate questo modello come modello di partenza per tipi di lavori di etichettatura automatica simili fornendo l'ARN, in formato stringa, nel parametro. InitialActiveLearningModelArn Per recuperare l'ARN del modello, utilizzate AWS Command Line Interface un comando AWS CLI() simile al seguente.
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
Per crittografare i dati sul volume di archiviazione collegato alle istanze di calcolo ML utilizzate nell'etichettatura automatica, includete una chiave AWS Key Management Service (AWS KMS) nel parametro. VolumeKmsKeyId Per informazioni sulle chiavi AWS KMS, vedi Cos'è AWS il servizio di gestione delle chiavi? nella Guida per gli sviluppatori del servizio di gestione delle AWS chiavi.
Per un esempio che utilizza l'CreateLabelingJoboperazione per creare un processo di etichettatura automatizzato dei dati, vedi l'esempio object_detection_tutorial nella sezione AI Examples SageMaker , Ground Truth Labeling Jobs di un'istanza di notebook AI. SageMaker Per informazioni su come creare e aprire un'istanza del notebook, consulta Crea un'istanza Amazon SageMaker Notebook. Per informazioni su come accedere ai notebook di esempio di intelligenza artificiale, consulta. SageMaker Accedi a taccuini di esempio
EC2 Istanze Amazon necessarie per l'etichettatura automatica dei dati
La tabella seguente elenca le istanze Amazon Elastic Compute Cloud (Amazon EC2) necessarie per eseguire l'etichettatura automatica dei dati per i lavori di formazione e inferenza in batch.
| Tipo di processo di etichettatura dei dati automatica | Tipo di istanza di addestramento | Tipo di istanza di inferenza |
|---|---|---|
|
Classificazione delle immagini |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
Rilevamento di oggetti (riquadro di delimitazione) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
Classificazione del testo |
ml.c5.2xlarge |
ml.m4.xlarge |
|
Segmentazione semantica |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* Nella Regione Asia Pacifico (Mumbai) (ap-south-1) usa invece ml.p2.8xlarge.
Ground Truth gestisce le istanze utilizzate per processi di etichettatura dei dati automatica. Crea, configura e termina le istanze in base alle necessità per eseguire il processo. Queste istanze non vengono visualizzate nella dashboard delle EC2 istanze Amazon.
Imposta un flusso di lavoro di apprendimento attivo con il tuo modello
Puoi creare un flusso di lavoro di apprendimento attivo con il tuo algoritmo per eseguire addestramento e inferenze in quel flusso di lavoro per etichettare automaticamente i tuoi dati. Il notebook bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb lo dimostra utilizzando l'algoritmo integrato di intelligenza artificiale,. SageMaker BlazingText Questo notebook fornisce uno stack che è possibile utilizzare per eseguire questo flusso di lavoro. AWS CloudFormation AWS Step FunctionsÈ possibile trovare il taccuino e i file di supporto in questo GitHub repository
Puoi trovare questo taccuino anche nell'archivio SageMaker AI Examples. Consulta Use Example Notebooks per scoprire come trovare un notebook di esempio Amazon SageMaker AI.
