Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Trasformazione dei dati
Amazon SageMaker Data Wrangler offre numerose trasformazioni di dati ML per semplificare la pulizia, la trasformazione e la personalizzazione dei dati. Quando aggiungi una trasformazione, aggiunge una fase al flusso di dati. Ogni trasformazione aggiunta modifica il set di dati e produce un nuovo dataframe. Tutte le trasformazioni successive si applicano al dataframe risultante.
Data Wrangler include trasformazioni integrate, che puoi utilizzare per trasformare le colonne senza alcun codice. Puoi anche aggiungere trasformazioni personalizzate usando PySpark Python User-Defined (Function), pandas e SQL. PySpark Alcune trasformazioni funzionano sul posto, mentre altre creano una nuova colonna di output nel set di dati.
È possibile applicare le trasformazioni a più colonne contemporaneamente. Ad esempio, puoi eliminare più colonne in un’unica fase.
È possibile applicare le trasformazioni Numeriche di processo e Gestire mancanti solo a una singola colonna.
Usa questa pagina per saperne di più sulle trasformazioni integrate e personalizzate.
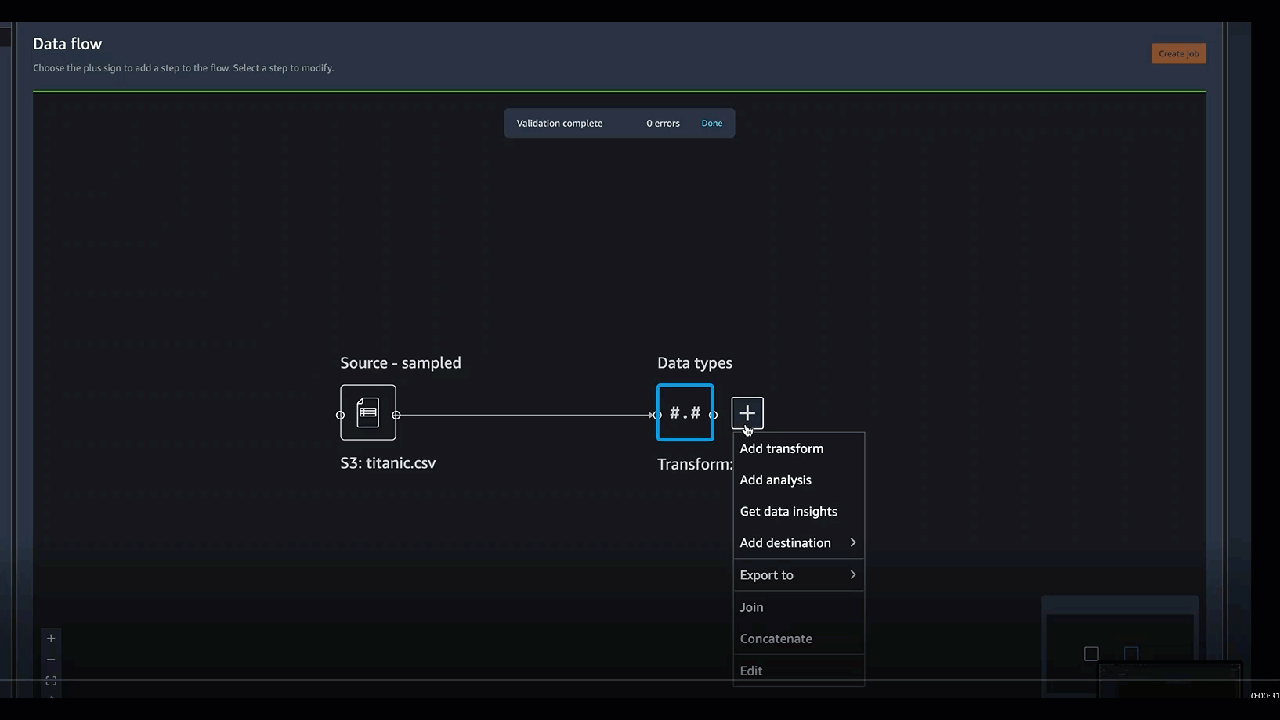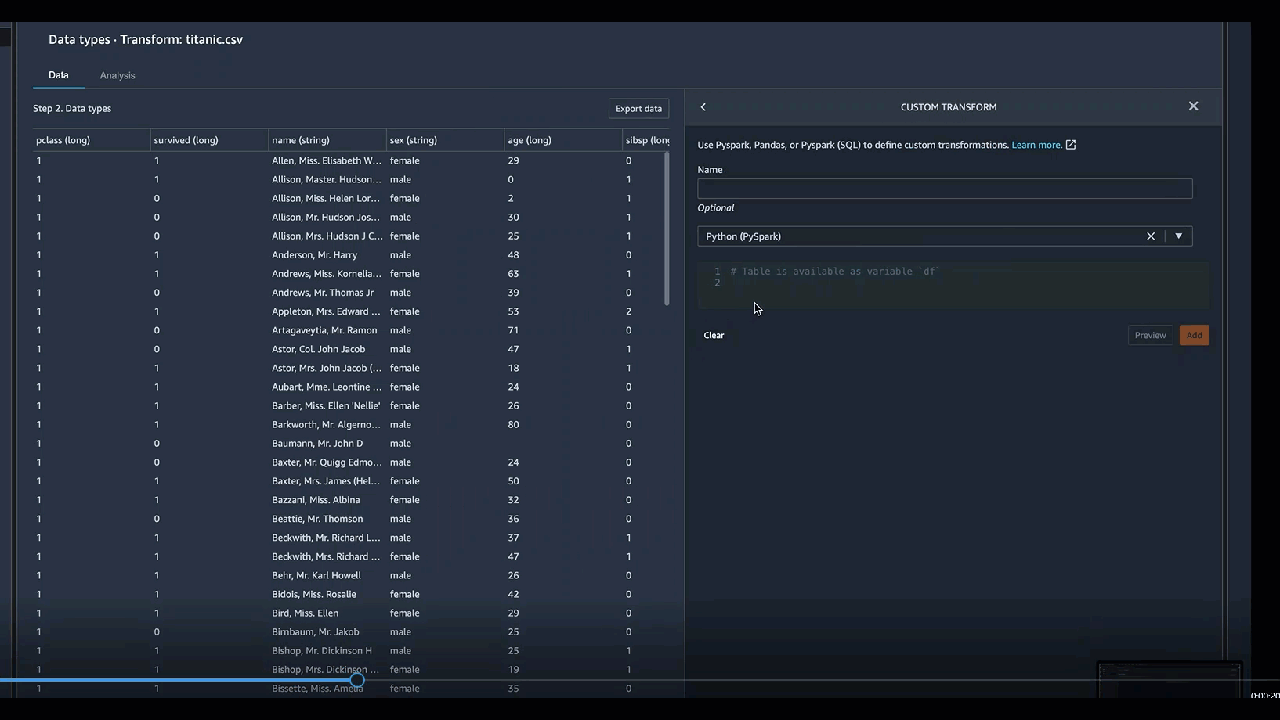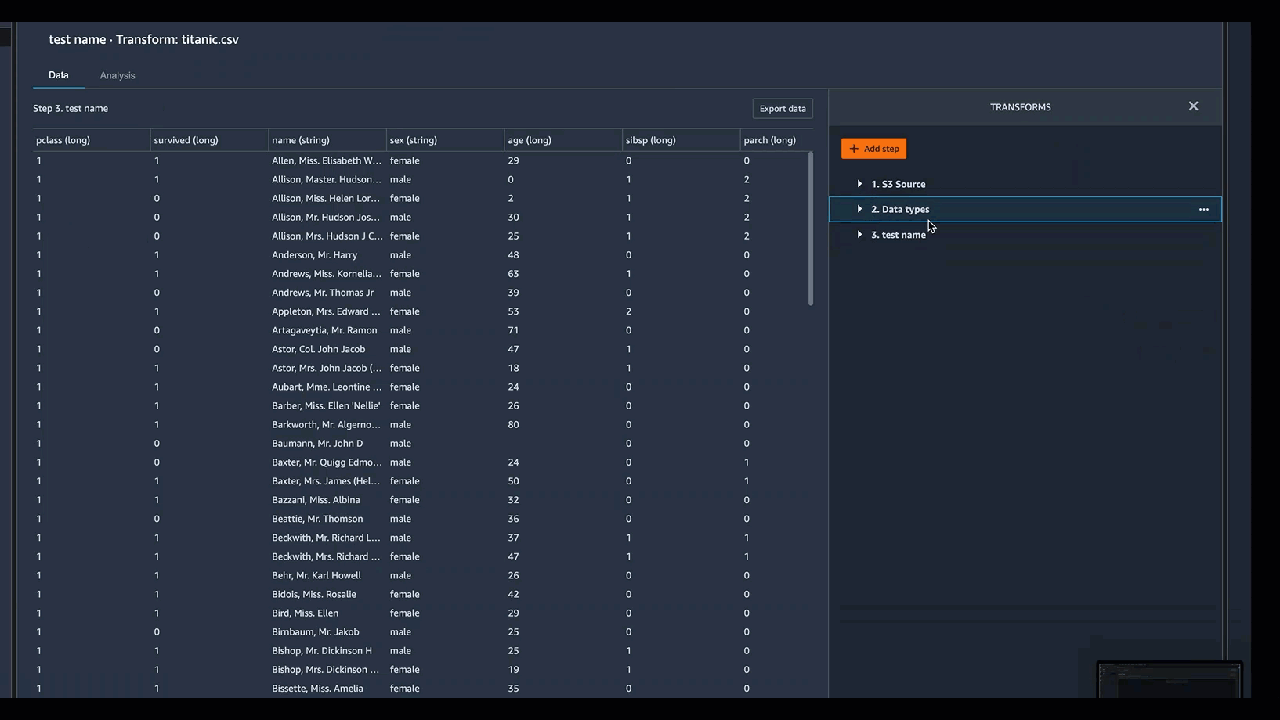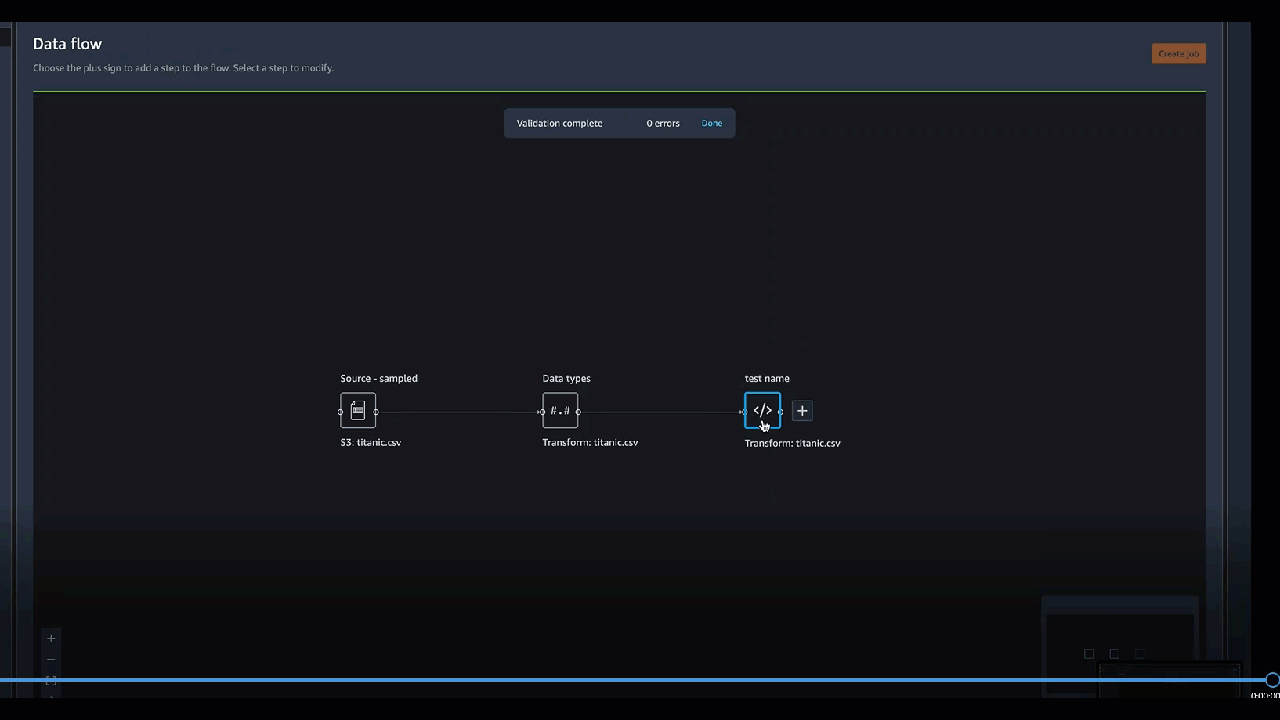
Interfaccia utente di trasformazione
La maggior parte delle trasformazioni integrate si trova nella scheda Prepara dell'interfaccia utente di Data Wrangler. Puoi accedere alle trasformazioni di unione e concatenazione tramite la visualizzazione del flusso di dati. Utilizza la tabella seguente per visualizzare in anteprima queste due viste.




Unire i set di dati
Unisci i dataframe direttamente nel tuo flusso di dati. Quando unisci due set di dati, il set di dati unito risultante viene visualizzato nel flusso. I seguenti tipi di unione sono supportati da Data Wrangler.
-
Sinistra esterno: include tutte le righe della tabella a sinistra. Se il valore della colonna unita in una riga della tabella sinistra non corrisponde a nessun valore della riga della tabella destra, tale riga contiene valori nulli per tutte le colonne della tabella destra nella tabella unita.
-
Sinistra anteriore: include le righe della tabella sinistra che non contengono valori nella tabella destra per la colonna unita.
-
Sinistra parziale: include una sola riga della tabella a sinistra per tutte le righe identiche che soddisfano i criteri dell'istruzione di unione. Ciò esclude le righe duplicate dalla tabella a sinistra che corrispondono ai criteri dell'unione.
-
Destra esterno: include tutte le righe della tabella destra. Se il valore della colonna unita in una riga della tabella destra non corrisponde a nessun valore della riga della tabella sinistra, quella riga contiene valori nulli per tutte le colonne della tabella sinistra nella tabella unita.
-
Interno: include le righe delle tabelle sinistra e destra che contengono valori corrispondenti nella colonna unita.
-
Completo esterno: include tutte le righe delle tabelle sinistra e destra. Se il valore della riga per la colonna unita in una delle due tabelle non corrisponde, vengono create righe separate nella tabella unita. Se una riga non contiene un valore per una colonna nella tabella unita, viene inserito null per quella colonna.
-
Croce cartesiana: include le righe che combinano ogni riga della prima tabella con ogni riga della seconda tabella. Si tratta di un Prodotto cartesiano
delle righe delle tabelle dell'unione. Il risultato di questo prodotto è la dimensione della tabella sinistra moltiplicata per la dimensione della tabella destra. Pertanto, consigliamo cautela nell'utilizzo di questa unione tra set di dati molto grandi.
Utilizza la procedura seguente per unire due dataframe.
-
Seleziona il segno + accanto al dataframe sinistro che desideri unire. Il primo dataframe selezionato è sempre la tabella a sinistra dell'unione.
-
Scegli Unisci.
-
Seleziona il dataframe giusto. Il secondo dataframe selezionato è sempre la tabella a destra dell'unione.
-
Scegli Configura per configurare l'unione.
-
Assegna un nome al set di dati unito utilizzando il campo Nome.
-
Seleziona un Tipo di unione.
-
Seleziona una colonna dalle tabelle sinistra e destra da unire.
-
Scegli Applica per visualizzare in anteprima il set di dati unito sulla destra.
-
Per aggiungere la tabella unita al flusso di dati, scegli Aggiungi.
Concatena i set di dati
Concatena due set di dati:
-
Scegli il segno + accanto al dataframe sinistro che desideri concatenare. Il primo dataframe selezionato è sempre la tabella a sinistra della concatenazione.
-
Scegli Concatena.
-
Seleziona il dataframe giusto. Il secondo dataframe selezionato è sempre la tabella a destra della concatenazione.
-
Scegli Configura per configurare la concatenazione.
-
Assegna un nome al set di dati concatenato utilizzando il campo Nome.
-
(Facoltativo) Seleziona la casella di controllo accanto a Rimuovi duplicati dopo la concatenazione per rimuovere le colonne duplicate.
-
(Facoltativo) Seleziona la casella di controllo accanto a Aggiungi colonna per indicare il dataframe di origine se, per ogni colonna del nuovo set di dati, desideri aggiungere un indicatore dell'origine della colonna.
-
Scegli Applica per visualizzare in anteprima il nuovo set di dati.
-
Scegli Aggiungi per aggiungere il nuovo set di dati al flusso di dati.
Bilanciamento dei dati
È possibile bilanciare i dati dei set di dati con una categoria sottorappresentata. Il bilanciamento di un set di dati può aiutarti a creare modelli migliori per la classificazione binaria.
Nota
Non è possibile bilanciare set di dati contenenti vettori di colonna.
È possibile utilizzare l'operazione Bilancia dati per bilanciare i dati utilizzando uno dei seguenti operatori:
-
Sovracampionamento casuale: duplica in modo casuale i campioni della categoria minoritaria. Ad esempio, se stai cercando di rilevare frodi, potresti avere casi di frode solo nel 10% dei tuoi dati. Per una proporzione uguale di casi fraudolenti e non fraudolenti, questo operatore duplica casualmente i casi di frode all'interno del set di dati per 8 volte.
-
Sottocampionamento casuale: all'incirca equivalente al sovracampionamento casuale. Rimuove in modo casuale i campioni dalla categoria sovrarappresentata per ottenere la proporzione di campioni desiderata.
-
Synthetic Minority Oversampling Technique (SMOTE): utilizza campioni della categoria sottorappresentata per interpolare nuovi campioni sintetici minoritari. Per ulteriori informazioni su SMOTE, consulta la descrizione seguente.
È possibile utilizzare tutte le trasformazioni per set di dati contenenti caratteristiche sia numeriche che non numeriche. SMOTE interpola i valori utilizzando campioni adiacenti. Data Wrangler utilizza la R-squared distanza per determinare l'area circostante per interpolare i campioni aggiuntivi. Data Wrangler utilizza solo caratteristiche numeriche per calcolare le distanze tra i campioni del gruppo sottorappresentato.
Per due campioni reali nel gruppo sottorappresentato, Data Wrangler interpola le caratteristiche numeriche utilizzando una media ponderata. Assegna in modo casuale dei pesi a quei campioni nell'intervallo di [0, 1]. Per quanto riguarda le caratteristiche numeriche, Data Wrangler interpola i campioni utilizzando una media ponderata dei campioni. Per i campioni A e B, Data Wrangler può assegnare in modo casuale un peso di 0,7 ad A e 0,3 a B. Il campione interpolato ha un valore di 0,7A + 0,3B.
Data Wrangler interpola caratteristiche non numeriche copiando da uno dei campioni reali interpolati. Copia i campioni con una probabilità che assegna casualmente a ciascun campione. Per i campioni A e B, può assegnare probabilità 0,8 a A e 0,2 a B. Per le probabilità assegnate, copia A l'80% delle volte.
Trasformazioni personalizzate
Il gruppo Custom Transforms consente di utilizzare Python User-Defined (Function) PySpark, panda PySpark o (SQL) per definire trasformazioni personalizzate. Per tutte e tre le opzioni, utilizza la variabile per accedere al dataframe df a cui desideri applicare la trasformazione. Per applicare il codice personalizzato al dataframe, assegna al dataframe le trasformazioni che hai apportato alla variabile df. Se non stai usando Python (User-Defined Function), non è necessario includere un'istruzione return. Scegli Anteprima per visualizzare in anteprima il risultato della trasformazione personalizzata. Scegli Aggiungi per aggiungere la trasformazione personalizzata all'elenco delle fasi precedenti.
Puoi importare le librerie più diffuse con un'istruzione import nel blocco di codice di trasformazione personalizzata, come il seguente:
-
NumPy versione 1.19.0
-
scikit-learn versione 0.23.2
-
SciPy versione 1.5.4
-
pandas versione 1.0.3
-
PySpark versione 3.0.0
Importante
La Trasformazione personalizzata non supporta colonne con spazi o caratteri speciali nel nome. Ti consigliamo di specificare nomi di colonna che contengano solo caratteri alfanumerici e caratteri di sottolineatura. È possibile utilizzare la trasformazione Rinomina colonna nel gruppo di trasformazione Gestisci colonne per rimuovere gli spazi dal nome di una colonna. Puoi anche aggiungere una Trasformazione personalizzata in Python (Pandas) simile alla seguente per rimuovere gli spazi da più colonne in un’unica fase. Questo esempio modifica rispettivamente le colonne denominate A
column e B column in A_column e B_column
df.rename(columns={"A column": "A_column", "B column": "B_column"})
Se includi istruzioni di stampa nel blocco di codice, il risultato viene visualizzato quando selezioni Anteprima. È possibile ridimensionare il pannello di trasformatore del codice personalizzato. Il ridimensionamento del pannello offre più spazio per scrivere codici. L'immagine seguente mostra il ridimensionamento del pannello.
Le sezioni seguenti forniscono contesto ed esempi aggiuntivi per la scrittura del codice di trasformazione personalizzata.
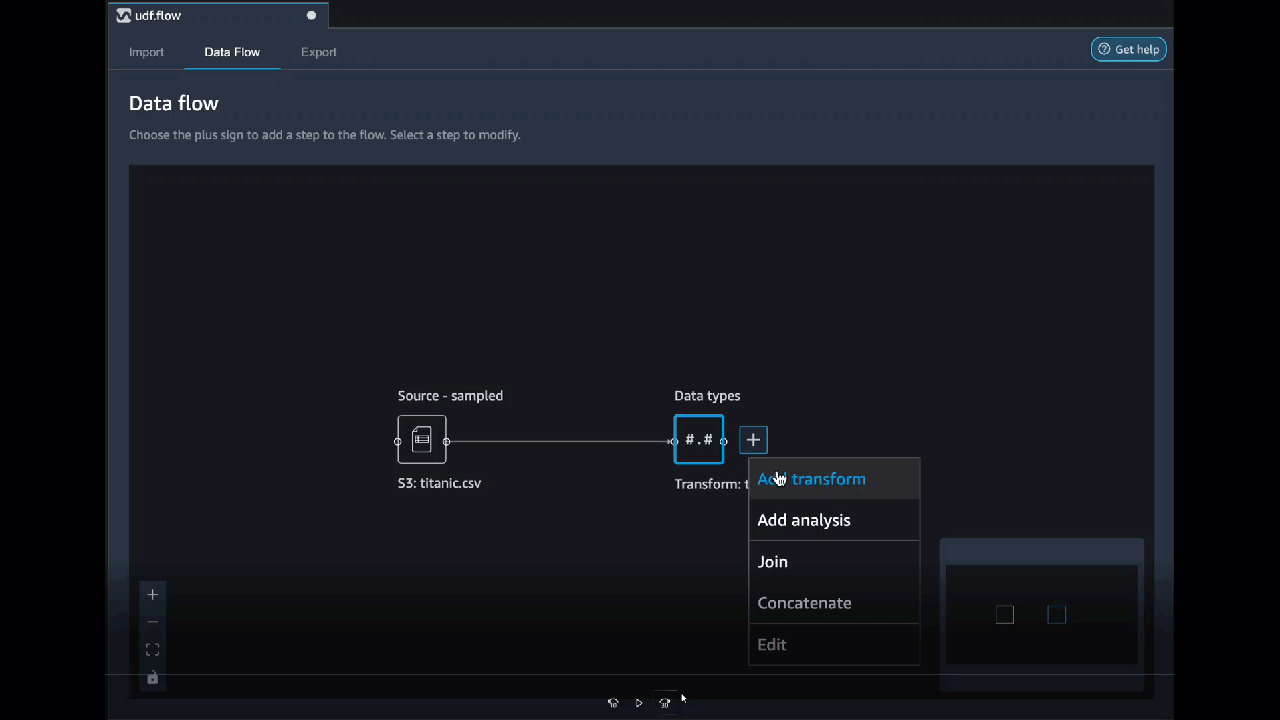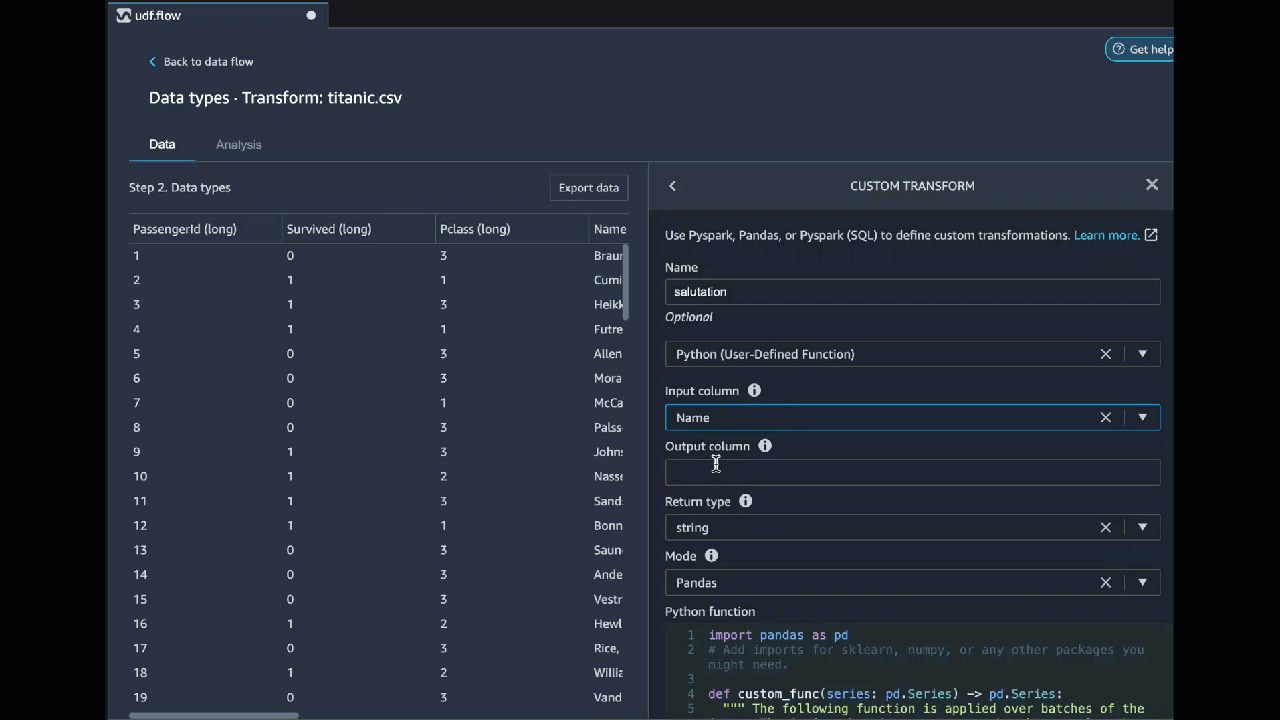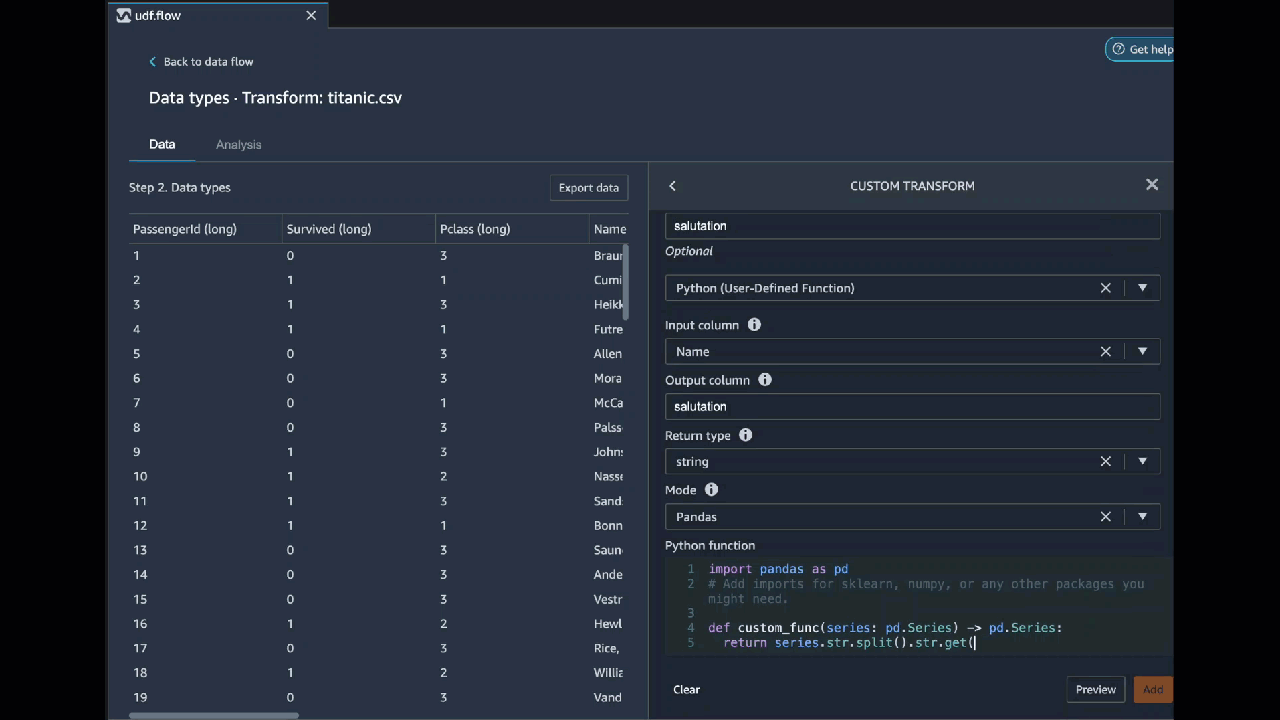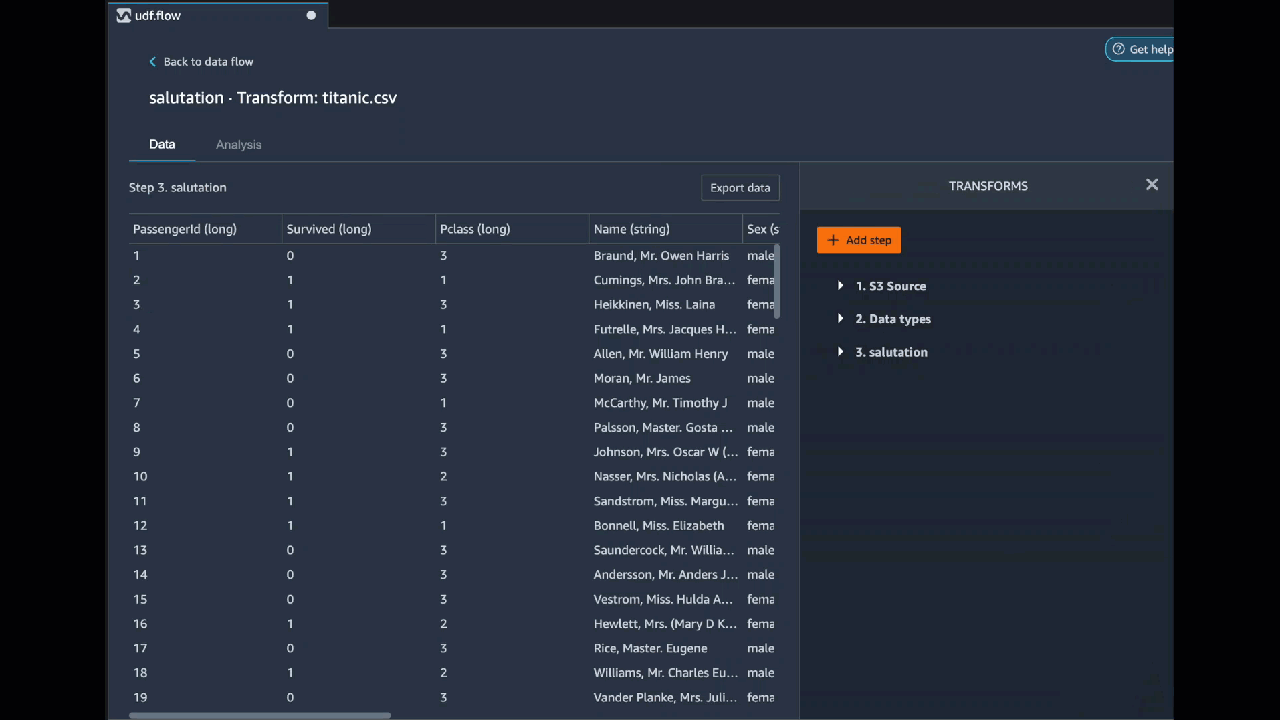
Python (funzione) User-Defined
La funzione Python ti dà la possibilità di scrivere trasformazioni personalizzate senza dover conoscere Apache Spark o pandas. Data Wrangler è ottimizzato per eseguire rapidamente il codice personalizzato. Ottieni prestazioni simili utilizzando codice Python personalizzato e un plug-in Apache Spark.
Per utilizzare il blocco di codice Python (User-Defined Function), specificate quanto segue:
-
Colonna di input: la colonna di input in cui si applica la trasformazione.
-
Modalità: la modalità di scripting, pandas o Python.
-
Tipo restituito: il tipo di dati del valore che stai restituendo.
L'uso della modalità pandas offre prestazioni migliori. La modalità Python semplifica la scrittura di trasformazioni utilizzando funzioni Python pure.
Il video seguente mostra un esempio di come utilizzare il codice personalizzato per creare una trasformazione. Utilizza il Set di dati Titanic
PySpark
L'esempio seguente estrae data e ora da un timestamp.
from pyspark.sql.functions import from_unixtime, to_date, date_format df = df.withColumn('DATE_TIME', from_unixtime('TIMESTAMP')) df = df.withColumn( 'EVENT_DATE', to_date('DATE_TIME')).withColumn( 'EVENT_TIME', date_format('DATE_TIME', 'HH:mm:ss'))
pandas
L'esempio seguente fornisce una panoramica del dataframe a cui si sta aggiungendo le trasformazioni.
df.info()
PySpark (SQL)
L'esempio seguente crea un nuovo dataframe con quattro colonne: nome, fare, pclass, survived.
SELECT name, fare, pclass, survived FROM df
Se non sai come usare PySpark, puoi usare frammenti di codice personalizzati per aiutarti a iniziare.
Data Wrangler ha una raccolta ricercabile di frammenti di codice. È possibile utilizzare i frammenti di codice per eseguire attività come eliminare colonne, raggruppare per colonne o modellare.
Per utilizzare un frammento di codice, scegli Cerca frammenti di esempio e specifica una query nella barra di ricerca. Il testo specificato nella query non deve necessariamente corrispondere esattamente al nome del frammento di codice.
L'esempio seguente mostra un frammento di codice Elimina le righe duplicate che può eliminare righe con dati simili nel set di dati. Puoi trovare il frammento di codice cercando uno dei seguenti:
-
Duplicato
-
Identico
-
Rimuovi
Il seguente frammento contiene commenti per aiutarti a comprendere le modifiche da apportare. Per la maggior parte dei frammenti, è necessario specificare i nomi delle colonne del set di dati nel codice.
# Specify the subset of columns # all rows having identical values in these columns will be dropped subset = ["col1", "col2", "col3"] df = df.dropDuplicates(subset) # to drop the full-duplicate rows run # df = df.dropDuplicates()
Per utilizzare un frammento, copia e incolla il suo contenuto nel campo Trasformazione personalizzata. Puoi copiare e incollare più frammenti di codice nel campo Trasformazione personalizzata.
Formula personalizzata
Usa la Formula personalizzata per definire una nuova colonna usando un'espressione SQL Spark per effettuare la query dei dati nel dataframe corrente. La query deve utilizzare le convenzioni delle espressioni SQL di Spark.
Importante
La Formula personalizzata non supporta colonne con spazi o caratteri speciali nel nome. Ti consigliamo di specificare nomi di colonna che contengano solo caratteri alfanumerici e caratteri di sottolineatura. È possibile utilizzare la trasformazione Rinomina colonna nel gruppo di trasformazione Gestisci colonne per rimuovere gli spazi dal nome di una colonna. Puoi anche aggiungere una Trasformazione personalizzata in Python (Pandas) simile alla seguente per rimuovere gli spazi da più colonne in un’unica fase. Questo esempio modifica rispettivamente le colonne denominate A
column e B column in A_column e B_column
df.rename(columns={"A column": "A_column", "B column": "B_column"})
È possibile utilizzare questa trasformazione per eseguire operazioni sulle colonne, facendo riferimento alle colonne per nome. Ad esempio, supponendo che il dataframe corrente contenga colonne denominate col_a e col_b, è possibile utilizzare la seguente operazione per produrre una colonna di output che sia il prodotto di queste due colonne con il codice seguente:
col_a * col_b
Altre operazioni comuni includono le seguenti, supponendo che un dataframe contenga col_a e col_b colonne:
-
Concatena due colonne:
concat(col_a, col_b) -
Aggiungi due colonne:
col_a + col_b -
Sottrai due colonne:
col_a - col_b -
Dividi due colonne:
col_a / col_b -
Prendi il valore assoluto di una colonna:
abs(col_a)
Per maggiori informazioni, consulta la documentazione di Spark
Ridurre la dimensionalità all'interno di un set di dati
Riduci la dimensionalità dei dati utilizzando Principal Component Analysis (PCA). La dimensionalità del set di dati corrisponde al numero di funzionalità. Quando si utilizza la riduzione della dimensionalità in Data Wrangler, si ottiene un nuovo set di funzionalità chiamate componenti. Ogni componente rappresenta una certa variabilità nei dati.
Il primo componente rappresenta la maggiore quantità di variazioni nei dati. Il secondo componente rappresenta la seconda maggiore quantità di variazioni nei dati e così via.
È possibile utilizzare la riduzione della dimensionalità per ridurre le dimensioni dei set di dati utilizzati per addestrare i modelli. Invece di utilizzare le funzionalità del set di dati, è possibile utilizzare i componenti principali.
Per eseguire la PCA, Data Wrangler crea assi per i dati. Un asse è una combinazione affine di colonne nel set di dati. Il primo componente principale è il valore sull'asse che presenta la maggiore varianza. Il secondo componente principale è il valore sull'asse che presenta la seconda maggiore varianza. L'ennesima componente principale è il valore sull'asse che presenta l'ennesima maggiore varianza.
È possibile configurare il numero di componenti principali restituiti da Data Wrangler. È possibile specificare direttamente il numero di componenti principali oppure specificare la percentuale di soglia di varianza. Ogni componente principale spiega una quantità di varianza nei dati. Ad esempio, si potrebbe disporre di un componente principale con un valore di 0,5. Il componente spiegherebbe il 50% della variazione dei dati. Quando si specifica una percentuale di soglia di varianza, Data Wrangler restituisce il numero minimo di componenti che soddisfano la percentuale specificata.
Di seguito sono riportati alcuni esempi di componenti principali con la quantità di varianza che spiegano nei dati.
-
Componente 1 – 0,5
-
Componente 2 – 0,45
-
Componente 3 – 0,05
Se si specifica una percentuale di soglia di varianza pari a 94 o95, Data Wrangler restituisce Component 1 e Component 2. Se si specifica una percentuale di soglia di varianza di 96, Data Wrangler restituisce tutti e tre i componenti principali.
Si può utilizzare la procedura seguente per eseguire PCA sul set di dati.
Per eseguire PCA sul set di dati, completare le seguenti operazioni.
-
Apri il flusso di dati Data Wrangler.
-
Scegli il segno + e seleziona Aggiungi.
-
Scegli Aggiungi fase.
-
Scegli riduzione della dimensionalità.
-
Per Colonne di input, scegli le funzionalità da ridurre ai componenti principali.
-
(Facoltativo) Per Numero di componenti principali, scegli il numero di componenti principali che Data Wrangler restituisce nel tuo set di dati. Se si specifica un valore per il campo, non è possibile specificare un valore per la Percentuale della soglia di varianza.
-
(Facoltativo) Per la Percentuale della soglia di varianza, specifica la percentuale di variazione dei dati che desideri venga spiegata dai componenti principali. Data Wrangler utilizza il valore predefinito
95se non specifichi un valore per la soglia di varianza. Non puoi specificare una percentuale di soglia di varianza se hai specificato un valore per il Numero di componenti principali. -
(Facoltativo) Deseleziona Centro per non utilizzare la media delle colonne come centro dei dati. Per impostazione predefinita, Data Wrangler centra i dati con la media prima del ridimensionamento.
-
(Facoltativo) Deseleziona Scala per non ridimensionare i dati con la deviazione standard unitaria.
-
(Facoltativo) Scegli Colonne per esportare i componenti in colonne separate. Scegli Vettore per visualizzare i componenti come un unico vettore.
-
(Facoltativo) Per la Colonna di output, specificate un nome per una colonna di output. Se stai inviando i componenti in colonne separate, il nome specificato è un prefisso. Se stai inviando i componenti in un vettore, il nome specificato è il nome della colonna vettoriale.
-
(Facoltativo) Seleziona Mantieni le colonne di input. Non consigliamo di selezionare questa opzione se prevedi di utilizzare solo i componenti principali per addestrare il tuo modello.
-
Scegli Anteprima.
-
Scegli Aggiungi.
Codifica categorica
I dati categoriali sono generalmente composti da un numero finito di categorie, in cui ogni categoria è rappresentata da una stringa. Ad esempio, se disponi di una tabella di dati sui clienti, una colonna che indica il Paese in cui vive una persona è di categoria. Le categorie sarebbero Afghanistan, Albania, Algeria e così via. I dati categoriali possono essere nominali o ordinali. Le categorie ordinali hanno un ordine intrinseco, mentre le categorie nominali no. Il grado più alto ottenuto (Scuola superiore, Laurea, Master e così via) è un esempio di categorie ordinali.
La codifica dei dati categoriali è il processo di creazione di una rappresentazione numerica per le categorie. Ad esempio, se le categorie sono Cane e Gatto, puoi codificare queste informazioni in due vettori: [1,0] per rappresentare Cane e [0,1] per rappresentare Gatto.
Quando codifichi le categorie ordinali, potrebbe essere necessario tradurre l'ordine naturale delle categorie nella codifica. Per esempio, puoi rappresentare il grado più alto ottenuto con la seguente mappa: {"High school": 1, "Bachelors": 2,
"Masters":3}.
Usa la codifica categoriale per codificare i dati categoriali in formato stringa in matrici di numeri interi.
I codificatori di categoria Data Wrangler creano codifiche per tutte le categorie presenti in una colonna al momento della definizione della fase. Se sono state aggiunte nuove categorie a una colonna quando si avvia un processo di Data Wrangler per elaborare il set di dati al momento t e questa colonna è stata l'input per una trasformazione di codifica categoriale di Data Wrangler al momento t-1, queste nuove categorie sono considerate mancanti nel processo Data Wrangler. L'opzione selezionata per Strategia di gestione non valida viene applicata a questi valori mancanti. Esempi di quando ciò può verificarsi sono:
-
Quando si utilizza un file.flow per creare un processo Data Wrangler per elaborare un set di dati che è stato aggiornato dopo la creazione del flusso di dati. Ad esempio, ogni mese puoi utilizzare un flusso di dati per elaborare regolarmente i dati di vendita. Se tali dati di vendita vengono aggiornati settimanalmente, è possibile inserire nuove categorie nelle colonne per le quali viene definita una fase di codifica categoriale.
-
Quando selezioni Campionamento nell'importare il set di dati, alcune categorie potrebbero essere escluse dall'esempio.
In queste situazioni, le nuove categorie sono considerate valori mancanti nel processo di Data Wrangler.
È possibile scegliere e configurare una codifica ordinale e una codifica one-hot. Utilizza le seguenti sezioni per avere ulteriori informazioni su queste opzioni.
Entrambe le trasformazioni creano una nuova colonna denominata Nome colonna di output. Specifica il formato di output di questa colonna con lo Stile di output:
-
Seleziona Vettore per produrre una singola colonna con un vettore sparso.
-
Seleziona Colonne per creare una colonna per ogni categoria con una variabile indicatore che indica se il testo nella colonna originale contiene un valore uguale a quella categoria.
Codifica ordinale
Seleziona Codifica ordinale per codificare le categorie in un numero intero compreso tra 0 e il numero totale di categorie nella Colonna di input selezionata.
Strategia di gestione non valida: seleziona un metodo per gestire i valori non validi o mancanti.
-
Scegli Ignora se desiderate omettere le righe con valori mancanti.
-
Scegli Mantieni per mantenere i valori mancanti come ultima categoria.
-
Scegli Errore se desideri che Data Wrangler generi un errore se vengono rilevati valori mancanti nella Colonna di input.
-
Scegli Sostituisci con NaN per sostituire i valori mancanti con NaN. Questa opzione è consigliata se l'algoritmo di ML è in grado di gestire i valori mancanti. In caso contrario, le prime tre opzioni di questo elenco potrebbero produrre risultati migliori.
One-Hot Codifica
Seleziona One-hot encode for Transform per utilizzare la codifica one-hot. Configura questa trasformazione utilizzando quanto segue:
-
Elimina l'ultima categoria: se
Truel'ultima categoria non ha un indice corrispondente nella codifica one-hot. Quando è possibili che manchino dei valori, una categoria mancante è sempre l'ultima e impostarla suTruesignifica che un valore mancante si traduce in un vettore tutto zero. -
Strategia di gestione non valida: seleziona un metodo per gestire i valori non validi o mancanti.
-
Scegli Ignora se desiderate omettere le righe con valori mancanti.
-
Scegli Mantieni per mantenere i valori mancanti come ultima categoria.
-
Scegli Errore se desideri che Data Wrangler generi un errore se vengono rilevati valori mancanti nella colonna di input.
-
-
L'input ordinale è codificato:: seleziona questa opzione se il vettore di input contiene dati codificati ordinali. Questa opzione richiede che i dati di input contengano numeri interi non negativi. Se Vero, l'input i viene codificato come vettore con un valore diverso da zero nella posizione i.
Codifica di similarità
Usa la codifica di similarità quando hai quanto segue:
-
Un gran numero di variabili categoriali
-
Dati di disturbo
L'encoder di similarità crea incorporamenti per colonne con dati categoriali. L'incorporamento è una mappatura di oggetti discreti, come le parole, a vettori di numeri reali. Codifica stringhe simili a vettori contenenti valori simili. Ad esempio, crea codifiche molto simili per «California» e «Calfornia».
Data Wrangler converte ogni categoria del set di dati in un set di token utilizzando un tokenizzatore da 3 grammi. Converte i token in un incorporamento utilizzando la codifica min-hash.
L'esempio seguente mostra come l'encoder di similarità crea vettori a partire da stringhe.
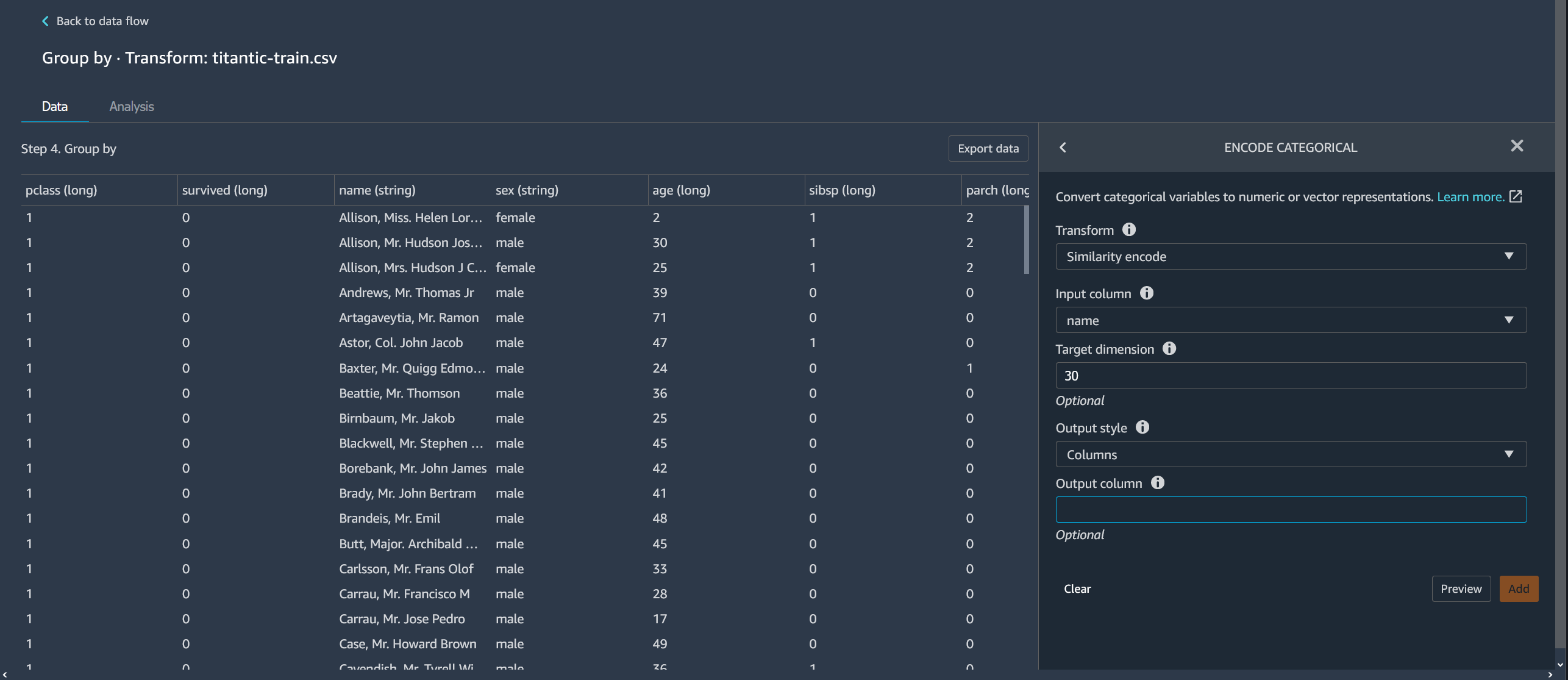
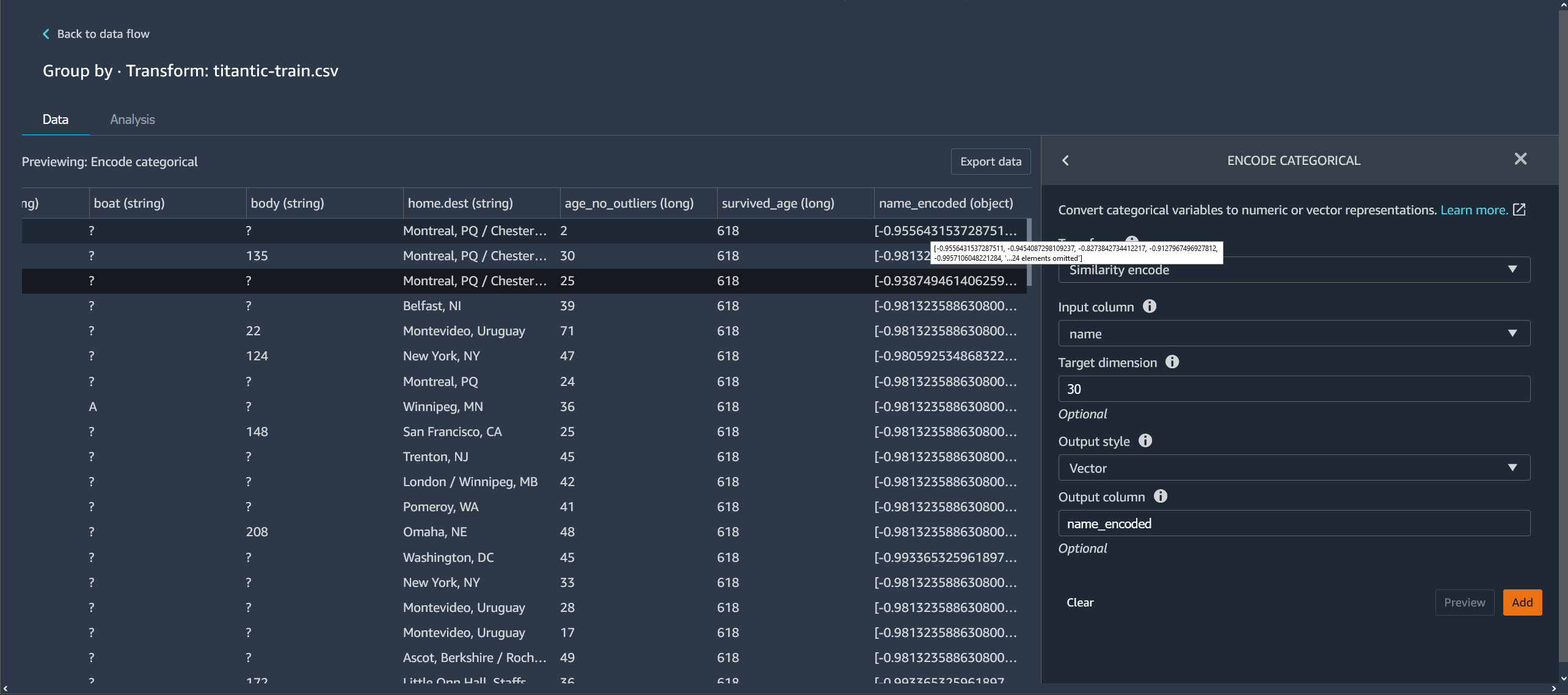
Le codifiche di similarità create da Data Wrangler:
-
Hanno una bassa dimensionalità
-
Sono scalabili per un gran numero di categorie
-
Sono robuste e resistenti ai valori di disturbo
Per i motivi precedenti, la codifica di similarità è più versatile della codifica one-hot.
Per aggiungere la trasformazione di codifica di similarità al set di dati, utilizza la procedura seguente.
Per utilizzare la codifica di similarità, completare le seguenti operazioni.
-
Accedi alla console Amazon SageMaker AI
. -
Scegli Apri Studio Classic.
-
Scegli Avvia l'applicazione.
-
Scegli Studio
-
Specificate il flusso di dati.
-
Scegli una fase con una trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Codifica categorica.
-
Specificare le impostazioni seguenti:
-
Trasformazione: Codifica per somiglianza
-
Colonna di input: la colonna contenente i dati categoriali che stai codificando.
-
Dimensione di destinazione: (facoltativa) la dimensione del vettore di incorporamento categorico. Il valore predefinito è 30. Ti consigliamo di utilizzare una dimensione target più grande se disponi di un set di dati di grandi dimensioni con molte categorie.
-
Stile di output: scegli Vettore per un singolo vettore con tutti i valori codificati. Scegli Colonna per avere i valori codificati in colonne separate.
-
Colonna di output: (facoltativo) il nome della colonna di output per un output con codifica vettoriale. Per un output con codifica a colonne, questo è il prefisso dei nomi delle colonne seguito dal numero elencato.
-
Caratterizzazione del testo
Utilizza il gruppo di trasformazione Caratterizzazione del testo per ispezionare le colonne di tipo stringa e utilizzate l'incorporamento del testo per caratterizzare queste colonne.
Questo gruppo di funzionalità contiene due funzionalità, Statistiche dei caratteri e Vettorizza. Utilizza le seguenti sezioni per avere ulteriori informazioni su queste trasformazioni. Per entrambe le opzioni, la Colonna di input deve contenere dati di testo (tipo di stringa).
Statistiche dei caratteri
Utilizza le Statistiche dei caratteri per generare statistiche per ogni riga di una colonna contenente dati di testo.
Questa trasformazione calcola i seguenti rapporti e conteggi per ogni riga e crea una nuova colonna per riportare il risultato. La nuova colonna viene denominata utilizzando il nome della colonna di input come prefisso e un suffisso specifico del rapporto o del conteggio.
-
Numero di parole: il numero totale di parole in quella riga. Il suffisso di questa colonna di output è
-stats_word_count. -
Numero di caratteri: il numero totale di caratteri in quella riga. Il suffisso di questa colonna di output è
-stats_char_count. -
Rapporto tra maiuscole: il numero di caratteri maiuscoli, dalla A alla Z, diviso per tutti i caratteri della colonna. Il suffisso di questa colonna di output è
-stats_capital_ratio. -
Rapporto tra minuscole: il numero di caratteri minuscoli, dalla a alla z, diviso per tutti i caratteri della colonna. Il suffisso di questa colonna di output è
-stats_lower_ratio. -
Rapporto tra cifre: il rapporto tra le cifre in una singola riga e la somma delle cifre nella colonna di input. Il suffisso di questa colonna di output è
-stats_digit_ratio. -
Rapporto tra caratteri speciali: il rapporto tra caratteri non alfanumerici (caratteri come #$&%: @) e la somma di tutti i caratteri nella colonna di input. Il suffisso di questa colonna di output è
-stats_special_ratio.
Vettorizza
L'incorporamento del testo implica la mappatura di parole o frasi da un vocabolario a vettori di numeri reali. Usa la trasformazione di incorporamento del testo di Data Wrangler per tokenizzare e vettorializzare i dati di testo in vettori di frequenza terminale—frequenza inversa del documento (). TF-IDF
Quando TF-IDF viene calcolata per una colonna di dati di testo, ogni parola di ogni frase viene convertita in un numero reale che ne rappresenta l'importanza semantica. I numeri più alti sono associati a parole meno frequenti, che tendono ad essere più significative.
Quando si definisce una fase di trasformazione di vettorializzazione, Data Wrangler utilizza i dati del set di dati per definire il vettorizzatore di conteggio e i metodi. TF-IDF L'esecuzione di un processo Data Wrangler utilizza gli stessi metodi.
Configura questa trasformazione utilizzando quanto segue:
-
Nome della colonna di output: questa trasformazione crea una nuova colonna con il testo incorporato. Usa questo campo per specificare un nome per questa colonna di output.
-
Tokenizer: un tokenizer converte la frase in un elenco di parole o token.
Scegli Standard per utilizzare un tokenizer che divide per spazio bianco e converte ogni parola in minuscolo. Ad esempio,
"Good dog"è tokenizzato in["good","dog"].Scegli Personalizzato per utilizzare un tokenizer personalizzato. Se scegli Personalizzato, puoi utilizzare i seguenti campi per configurare il tokenizer:
-
Lunghezza minima del token: la lunghezza minima, in caratteri, affinché un token sia valido. L’impostazione predefinita è
1. Ad esempio, se si specifica3come lunghezza minima del token, le parole comea, at, invengono eliminate dalla frase tokenizzata. -
L'espressione regolare dovrebbe dividersi sugli spazi vuoti: se selezionata, l'espressone regolare si suddivide sugli spazi vuoti. In caso contrario, corrisponde ai token. L’impostazione predefinita è
True. -
Modello espressione regolare: modello espressione regolare che definisce il processo di tokenizzazione. L’impostazione predefinita è
' \\ s+'. -
Converti in minuscolo: se selezionato, Data Wrangler converte tutti i caratteri in minuscolo prima della tokenizzazione. L’impostazione predefinita è
True.
Per ulteriori informazioni, consulta la documentazione di Spark su Tokenizer
. -
-
Vettorizzatore: il vettorizzatore converte l'elenco dei token in un vettore numerico sparso. Ogni token corrisponde a un indice nel vettore e un valore diverso da zero indica l'esistenza del token nella frase di input. Puoi scegliere tra due opzioni di vettorizzazione, Conteggio e Hashing.
-
Conta vettoriale: consente personalizzazioni che filtrano i token poco frequenti o troppo comuni. I Parametri di conteggio vettoriale includono quanto segue:
-
Frequenza minima dei termini: in ogni riga, vengono filtrati i termini (token) con frequenza minore. Se si specifica un numero intero, si tratta di una soglia assoluta (inclusa). Se si specifica una frazione compresa tra 0 (incluso) e 1, la soglia è relativa al conteggio totale dei termini. L’impostazione predefinita è
1. -
Frequenza minima dei documenti: numero minimo di righe in cui deve apparire un termine (token). Se si specifica un numero intero, si tratta di una soglia assoluta (inclusa). Se si specifica una frazione compresa tra 0 (incluso) e 1, la soglia è relativa al conteggio totale dei termini. L’impostazione predefinita è
1. -
Frequenza massima dei documenti: numero massimo di documenti (righe) in cui un termine (token) può apparire per essere incluso. Se si specifica un numero intero, si tratta di una soglia assoluta (inclusa). Se si specifica una frazione compresa tra 0 (incluso) e 1, la soglia è relativa al conteggio totale dei termini. L’impostazione predefinita è
0.999. -
Dimensione massima del vocabolario: dimensione massima del vocabolario. Il vocabolario è composto da tutti i termini (token) presenti in tutte le righe della colonna. L’impostazione predefinita è
262144. -
Output binari: se selezionato, gli output vettoriali non includono il numero di apparizioni di un termine in un documento, ma sono piuttosto un indicatore binario del suo aspetto. L’impostazione predefinita è
False.
Per ulteriori informazioni su questa opzione, consulta la documentazione di Spark su. CountVectorizer
-
-
L'hashing è computazionalmente più veloce. I parametri di vettorizzazione hash includono quanto segue:
-
Numero di funzionalità durante l'hashing: un vettorizzatore di hash mappa i token su un indice vettoriale in base al loro valore di hash. Questa funzione determina il numero di valori hash possibili. Valori elevati comportano un minor numero di collisioni tra i valori hash a fronte di un vettore di output di dimensioni maggiori.
Per saperne di più su questa opzione, consulta la documentazione di Spark su FeatureHasher
-
-
-
Apply IDF applica una trasformazione IDF, che moltiplica la frequenza del termine per la frequenza inversa standard del documento utilizzata per l'incorporamento. TF-IDF I parametri IDF includono quanto segue:
-
Frequenza minima dei documenti: numero minimo di documenti (righe) in cui deve apparire un termine (token). Se count_vectorize è il vettorizzatore scelto, ti consigliamo di mantenere il valore predefinito e di modificare solo il campo min_doc_freq nei Parametri di conteggio vettoriale. L’impostazione predefinita è
5.
-
-
Formato di output: il formato di output di ogni riga.
-
Seleziona Vettore per produrre una singola colonna con un vettore sparso.
-
Seleziona Appiattito per creare una colonna per ogni categoria con una variabile indicatore che indica se il testo nella colonna originale contiene un valore uguale a quella categoria. Puoi scegliere appiattito solo quando Vectorizer è impostato come Vettorizzatore di conteggi.
-
Serie temporale di trasformazione
In Data Wrangler, puoi trasformare i dati di serie temporali. I valori in un set di dati di serie temporali sono indicizzati in base a un periodo di tempo specifico. Ad esempio, un set di dati che mostra il numero di clienti in un negozio per ogni ora del giorno è un set di dati di serie temporali. La tabella seguente mostra un esempio di set di dati di serie temporali.
Numero orario di clienti in un negozio
| Numero di clienti | Tempo (ora) |
|---|---|
| 4 | 09:00 |
| 10 | 10:00 |
| 14 | 11:00 |
| 25 | 12:00 |
| 20 | 13:00 |
| 18 | 14:00 |
Per la tabella precedente, la colonna Numero di clienti contiene i dati di serie temporali. I dati di serie temporali sono indicizzati in base ai dati orari nella colonna Tempo (ora).
Potrebbe essere necessario eseguire una serie di trasformazioni sui dati per ottenere un formato che possa essere utilizzato per l'analisi. Utilizza il gruppo di trasformazione delle Serie temporali per trasformare i dati di serie temporali. Per ulteriori informazioni sulle trasformazioni che è possibile eseguire, consulta le sezioni successive.
Raggruppa per serie temporale
È possibile utilizzare l'operazione di raggruppamento per raggruppare i dati delle serie temporali di valori specifici in una colonna.
Ad esempio, è disponibile la tabella seguente che tiene traccia del consumo medio giornaliero di elettricità in una famiglia.
Consumo medio giornaliero di elettricità per uso domestico
| ID della famiglia | Timestamp giornaliero | Consumo di elettricità (kWh) | Numero di occupanti della famiglia |
|---|---|---|---|
| famiglia_0 | 1/1/2020 | 30 | 2 |
| famiglia_0 | 1/2/2020 | 40 | 2 |
| famiglia_0 | 1/4/2020 | 35 | 3 |
| famiglia_1 | 1/2/2020 | 45 | 3 |
| famiglia_1 | 1/3/2020 | 55 | 4 |
Se scegli di raggruppare per ID, ottieni la seguente tabella.
Consumo di elettricità raggruppato per ID famiglia
| ID della famiglia | Serie di utilizzo dell'elettricità (kWh) | Serie del numero di occupanti della famiglia |
|---|---|---|
| famiglia_0 | [30, 40, 35] | [2, 2, 3] |
| famiglia_1 | [45, 55] | [3, 4] |
Ogni voce nella sequenza delle serie temporali è ordinata in base al timestamp corrispondente. Il primo elemento della sequenza corrisponde al primo timestamp della serie. Per household_0, 30 è il primo valore della serie sull'uso dell'elettricità. Il valore 30 corrisponde al primo timestamp di 1/1/2020
È possibile includere il timestamp di inizio e il timestamp di fine. La tabella seguente mostra come vengono visualizzate queste informazioni.
Consumo di elettricità raggruppato per ID famiglia
| ID della famiglia | Serie di utilizzo dell'elettricità (kWh) | Serie del numero di occupanti della famiglia | Start_time | End_time |
|---|---|---|---|---|
| famiglia_0 | [30, 40, 35] | [2, 2, 3] | 1/1/2020 | 1/4/2020 |
| famiglia_1 | [45, 55] | [3, 4] | 1/2/2020 | 1/3/2020 |
Puoi utilizzare la procedura seguente per raggruppare in base a una colonna di serie temporali.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Serie temporali.
-
In Trasformazione, scegli Raggruppa per.
-
Specifica una colonna in Raggruppa in base a questa colonna.
-
Per Applica alle colonne, specificare un valore.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Ricampiona i dati di serie temporali
I dati di serie temporali di solito contengono osservazioni che non vengono effettuate a intervalli regolari. Ad esempio, un set di dati potrebbe contenere alcune osservazioni registrate ogni ora e altre osservazioni registrate ogni due ore.
Molte analisi, come gli algoritmi di previsione, richiedono che le osservazioni vengano eseguite a intervalli regolari. Il ricampionamento consente di stabilire intervalli regolari per le osservazioni nel set di dati.
È possibile campionare o sottocampionare una serie temporale. Il sottocampionamento aumenta l'intervallo tra le osservazioni nel set di dati. Ad esempio, se si esegue il sottocampionamento di osservazioni effettuate ogni ora o ogni due ore, ogni osservazione del set di dati viene eseguita ogni due ore. Le osservazioni orarie vengono aggregate in un unico valore utilizzando un metodo di aggregazione come la media o la mediana.
Il sovracampionamento riduce l'intervallo tra le osservazioni nel set di dati. Ad esempio, se si convertono le osservazioni effettuate ogni due ore in osservazioni orarie, è possibile utilizzare un metodo di interpolazione per dedurre le osservazioni orarie da quelle effettuate ogni due ore. Per informazioni sui metodi di interpolazione, consulta pandas. DataFrame.interpolate
È possibile ricampionare dati numerici e non numerici.
Utilizza l'operazione Ricampiona per ricampionare i dati di serie temporali. Se nel set di dati sono presenti più serie temporali, Data Wrangler standardizza l'intervallo temporale per ogni serie temporale.
La tabella seguente mostra un esempio di sottocampionamento dei dati delle serie temporali utilizzando la media come metodo di aggregazione. I dati vengono sottoposti a sottocampionamento da ogni due ore a ogni ora.
Letture della temperatura oraria nell'arco di un giorno prima del sottocampionamento
| Timestamp | Temperatura (gradi Celsius) |
|---|---|
| 12:00 | 30 |
| 1:00 | 32 |
| 2:00 | 35 |
| 3:00 | 32 |
| 4:00 | 30 |
Letture della temperatura con un campionamento ridotto a due ore
| Time stamp | Temperatura (gradi Celsius) |
|---|---|
| 12:00 | 30 |
| 2:00 | 33,5 |
| 4:00 | 35 |
Puoi utilizzare la procedura seguente per ricampionare i dati di serie temporali.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Ricampiona.
-
Per Timestamp, scegli la colonna Timestamp.
-
Per Unità di frequenza, specifica la frequenza da ricampionare.
-
(Facoltativo) Specifica un valore per la Quantità di frequenza.
-
Configura la trasformazione specificando i campi rimanenti.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Gestisci i dati di serie temporali mancanti
Se nel set di dati mancano valori, puoi eseguire una delle seguenti operazioni:
-
Per i set di dati con più serie temporali, elimina le serie temporali con valori mancanti superiori alla soglia specificata.
-
Importa i valori mancanti in una serie temporale utilizzando altri valori della serie temporale.
L'imputazione di un valore mancante implica la sostituzione dei dati specificando un valore o utilizzando un metodo inferenziale. Di seguito sono riportati i metodi che è possibile utilizzare per l'imputazione:
-
Valore costante: sostituisci tutti i dati mancanti nel set di dati con un valore specificato dall'utente.
-
Valore più comune: sostituisce tutti i dati mancanti con il valore che possiede la frequenza più alta nel set di dati.
-
Riempimento in avanti: utilizza un riempimento in avanti per sostituire i valori mancanti con il valore non mancante che precede i valori mancanti. Per la sequenza: [2, 4, 7, NaN, NaN, NaN, 8], tutti i valori mancanti vengono sostituiti con 7. La sequenza che risulta dall'utilizzo di un riempimento in avanti è [2, 4, 7, 7, 7, 7, 8].
-
Riempimento all'indietro: utilizza un riempimento all'indietro per sostituire i valori mancanti con il valore non mancante che segue i valori mancanti. Per la sequenza: [2, 4, 7, NaN, NaN, NaN, 8], tutti i valori mancanti vengono sostituiti con 8. La sequenza che risulta dall'utilizzo di un riempimento all'indietro è [2, 4, 7, 8, 8, 8, 8].
-
Interpolazione: utilizza una funzione di interpolazione per imputare i valori mancanti. Per ulteriori informazioni sulle funzioni che puoi usare per l'interpolazione, vedi pandas. DataFrame.interpolate
.
Alcuni metodi di imputazione potrebbero non essere in grado di imputare tutto il valore mancante nel set di dati. Ad esempio, un Riempimento in avanti non può imputare un valore mancante che appare all'inizio della serie temporale. È possibile imputare i valori utilizzando un riempimento in avanti o un riempimento all'indietro.
È possibile imputare i valori mancanti all'interno di una cella o all'interno di una colonna.
L'esempio seguente mostra come i valori vengono imputati all'interno di una cella.
Consumo di elettricità con valori mancanti
| ID della famiglia | Serie di utilizzo dell'elettricità (kWh) |
|---|---|
| famiglia_0 | [30, 40, 35, NaN, NaN] |
| famiglia_1 | [45, NaN, 55] |
Consumo di elettricità con valori imputati utilizzando un riempimento in avanti
| ID della famiglia | Serie di utilizzo dell'elettricità (kWh) |
|---|---|
| famiglia_0 | [30, 40, 35, 35, 35] |
| famiglia_1 | [45, 45, 55] |
L'esempio seguente mostra come i valori vengono imputati all'interno di una colonna.
Consumo medio giornaliero di elettricità per uso domestico con valori mancanti
| ID della famiglia | Consumo di elettricità (kWh) |
|---|---|
| famiglia_0 | 30 |
| famiglia_0 | 40 |
| famiglia_0 | NaN |
| famiglia_1 | NaN |
| famiglia_1 | NaN |
Consumo medio giornaliero di elettricità per uso domestico con valori imputati utilizzando un rifornimento a termine
| ID della famiglia | Consumo di elettricità (kWh) |
|---|---|
| famiglia_0 | 30 |
| famiglia_0 | 40 |
| famiglia_0 | 40 |
| famiglia_1 | 40 |
| famiglia_1 | 40 |
Per gestire i valori mancanti utilizza la procedura seguente.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Gestisci mancanti.
-
Per il tipo di input delle serie temporali, scegli se desideri gestire i valori mancanti all'interno di una cella o lungo una colonna.
-
Per Immetti i valori mancanti per questa colonna, specifica la colonna con i valori mancanti.
-
Per Metodo di imputazione dei valori, seleziona un metodo.
-
Configura la trasformazione specificando i campi rimanenti.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Se hai dei valori mancanti, puoi specificare un metodo per imputarli in Metodo per l'imputazione dei valori.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Convalida il timestamp dei dati di serie temporali
È possibile che i dati del timestamp non siano validi. È possibile utilizzare la funzione Convalida timestamp per determinare se i timestamp nel set di dati sono validi. Il timestamp potrebbe non essere valido per uno o più dei seguenti motivi:
-
La colonna del timestamp presenta dei valori mancanti.
-
I valori nella colonna del timestamp non sono formattati correttamente.
Se nel set di dati sono presenti timestamp non validi, non è possibile eseguire correttamente l'analisi. Puoi utilizzare Data Wrangler per identificare timestamp non validi e capire dove è necessario ripulire i dati.
La convalida delle serie temporali funziona in due modi:
Puoi configurare Data Wrangler per eseguire una delle seguenti operazioni se rileva valori mancanti nel set di dati:
-
Elimina le righe con i valori mancanti o non validi.
-
Identifica le righe con valori mancanti o non validi.
-
Genera un errore se rileva valori mancanti o non validi nel set di dati.
Puoi convalidare i timestamp sulle colonne che hanno il tipo timestamp o string. Se la colonna ha il tipo string, Data Wrangler converte il tipo di colonna in timestamp ed esegue la convalida.
Per convalidare i timestamp nel set di dati puoi utilizzare la procedura seguente.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Convalida i timestamp.
-
Per Colonna timestamp, scegli la colonna Timestamp.
-
Per Policy, scegli se vuoi gestire i timestamp mancanti.
-
(Facoltativo) Per la colonna di output, specifica un nome per la colonna di output.
-
Se la colonna della data e dell'ora è formattata per il tipo di stringa, scegli Trasmetti a datetime.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Standardizzazione della durata delle serie temporali
Se si dispone di dati di serie temporali archiviati come matrici, è possibile standardizzare ogni serie temporale sulla stessa durata. La standardizzazione della durata dell'array delle serie temporali potrebbe semplificare l'esecuzione dell'analisi sui dati.
È possibile standardizzare le serie temporali per le trasformazioni dei dati che richiedono una durata fissa dei dati.
Molti algoritmi di ML richiedono di appiattire i dati di serie temporali prima di utilizzarli. L'appiattimento dei dati di serie temporali consiste nel separare ogni valore di serie temporale in una colonna distinta all'interno di un set di dati. Il numero di colonne in un set di dati non può cambiare, quindi è necessario standardizzare le durate delle serie temporali: ogni array viene suddiviso in un insieme di funzionalità.
Ogni serie temporale è impostata sulla durata specificata come quantile o percentile del set di serie temporali. Ad esempio, è possibile che tu disponga di tre sequenze con le seguenti durate:
-
3
-
4
-
5
Puoi impostare la durata di tutte le sequenze come la durata della sequenza che ha il 50° percentile di durata.
Agli array di serie temporali più brevi della durata specificata vengono aggiunti i valori mancanti. Di seguito è riportato un esempio di formato di standardizzazione delle serie temporali su una durata maggiore: [2, 4, 5, NaN, NaN, NaN].
È possibile utilizzare approcci diversi per gestire i valori mancanti. Per ulteriori informazioni su tali approcci, consultare Gestisci i dati di serie temporali mancanti.
Gli array di serie temporali più lunghi della durata specificata vengono troncati.
Puoi utilizzare la procedura seguente per standardizzare la durata delle serie temporali.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Standardizza la durata.
-
Per Standardizzare la durata delle serie temporali per la colonna, scegli una colonna.
-
(Facoltativo) Per la colonna di output, specifica un nome per la colonna di output. Se non specifichi un nome, la trasformazione avverrà in loco.
-
Se la colonna datetime è formattata per il tipo di stringa, scegli Trasmetti a datetime.
-
Scegli Taglio quantile e specificate un quantile per impostare la durata della sequenza.
-
Scegli Appiattisci l'output per visualizzare i valori delle serie temporali in colonne separate.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Estrai funzionalità dai dati delle serie temporali
Se stai eseguendo un algoritmo di classificazione o regressione sui dati di serie temporali, ti consigliamo di estrarre le funzionalità dalle serie temporali prima di eseguire l'algoritmo. Le funzioni di estrazione potrebbero migliorare le prestazioni dell'algoritmo.
Utilizza le seguenti opzioni per scegliere come estrarre le funzionalità dai dati:
-
Usa Sottoinsieme minimo per specificare l'estrazione di 8 funzionalità che sai essere utili nelle analisi a valle. È possibile utilizzare un sottoinsieme minimo quando è necessario eseguire calcoli rapidamente. È inoltre possibile utilizzarlo quando l'algoritmo di ML presenta un elevato rischio di overfitting e si desidera dotarlo di un numero inferiore di funzionalità.
-
Utilizza il Sottoinsieme efficiente per specificare l'estrazione del maggior numero possibile di funzionalità senza estrarre funzionalità che richiedono un uso intensivo di calcolo nelle analisi.
-
Utilizza Tutte le funzionalità per specificare l'estrazione di tutte le funzionalità dalla serie.
-
Usa il Sottoinsieme manuale per scegliere un elenco di funzionalità che ritieni spieghino bene la variazione dei tuoi dati.
Utilizza la procedura seguente per estrarre le funzionalità dai dati di serie temporali.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Funzionalità di estrazione.
-
Per Funzionalità di estrazione per questa colonna, scegli una colonna.
-
(Facoltativo) Seleziona Appiattisci per visualizzare le funzionalità in colonne separate.
-
Per Strategia, scegli una strategia per estrarre le funzionalità.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Usa le funzionalità ritardate dei dati di serie temporali
In molti casi d'uso, il modo migliore per prevedere il comportamento futuro delle serie temporali consiste nell'utilizzare il comportamento più recente.
Gli usi più comuni delle funzionalità ritardate sono i seguenti:
-
Raccolta di una manciata di valori passati. Ad esempio, per time, t + 1, raccogli t, t - 1, t - 2 e t - 3.
-
Raccolta di valori che corrispondono al comportamento stagionale nei dati. Ad esempio, per prevedere l'occupazione di un ristorante alle 13:00, potresti voler utilizzare le funzionalità a partire dalle 13:00 del giorno precedente. L'utilizzo delle funzionalità a partire dalle 12:00 o dalle 11:00 dello stesso giorno potrebbe non essere così predittivo come l'utilizzo delle funzionalità dei giorni precedenti.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Funzionalità ritardate.
-
Per Genera funzionalità di ritardo per questa colonna, scegli una colonna.
-
Per Colonna timestamp, scegli la colonna che contiene i timestamp.
-
Per Ritardo, specificate la durata del ritardo.
-
(Facoltativo) Configura l'output utilizzando una delle seguenti opzioni:
-
Includi l'intera finestra di ritardo
-
Appiattisci l'output
-
Elimina le righe senza cronologia
-
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Crea un intervallo di date e orari nella tua serie temporale
Potresti avere dati di serie temporali che non hanno timestamp. Se sai che le osservazioni sono state effettuate a intervalli regolari, puoi generare timestamp per le serie temporali in una colonna separata. Per generare i timestamp, specifica il valore del timestamp di inizio e la frequenza dei timestamp.
Ad esempio, potresti avere le seguenti dati di serie temporali sul numero di clienti in un ristorante.
Dati di serie temporali sul numero di clienti in un ristorante
| Numero di clienti |
|---|
| 10 |
| 14 |
| 24 |
| 40 |
| 30 |
| 20 |
Se sai che il ristorante ha aperto alle 17:00 e che le osservazioni vengono effettuate ogni ora, puoi aggiungere una colonna timestamp che corrisponda ai dati delle serie temporali. Puoi visualizzare la colonna timestamp nella tabella seguente.
Dati di serie temporali sul numero di clienti in un ristorante
| Numero di clienti | Time stamp |
|---|---|
| 10 | 13:00 |
| 14 | 14:00 |
| 24 | 15:00 |
| 40 | 16:00 |
| 30 | 17:00 |
| 20 | 18:00 |
Utilizza la procedura seguente per aggiungere ai tuoi dati un intervallo di data e ora.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli l'intervallo di data/ora.
-
Per Tipo di frequenza, scegli l'unità utilizzata per misurare la frequenza dei timestamp.
-
Per Timestamp di inizio, specifica il timestamp di inizio.
-
Per Colonna di output, specificate un nome per la colonna di output.
-
(Facoltativo) Configura l'output utilizzando i campi rimanenti.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Usare una finestra mobile nella serie temporale
È possibile estrarre le funzionalità in un periodo di tempo. Ad esempio, per time (ora), t, e una finestra temporale della durata di 3 e per la riga che indica il timestamp t, aggiungiamo le caratteristiche estratte dalle serie temporali ai tempi t - 3, t -2 e t - 1. Per informazioni sull'estrazione delle funzionalità, consulta Estrai funzionalità dai dati delle serie temporali.
È possibile utilizzare la procedura seguente per estrarre le funzionalità in un periodo di tempo.
-
Apri il flusso di dati Data Wrangler.
-
Se non hai importato il set di dati, importalo nella scheda Importa dati.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Funzionalità finestra mobile.
-
Per Generare le funzionalità di finestra mobile per questa colonna, scegli una colonna.
-
Per Colonna timestamp, scegli la colonna che contiene i timestamp.
-
(Facoltativo) Per Colonna di output, specifica il nome della colonna di output.
-
Per Dimensioni della finestra, specificate le dimensioni della finestra.
-
Per Strategia, scegli la strategia di estrazione.
-
Scegli Anteprima per generare un'anteprima della trasformazione.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Personalizza datetime
Usa Featuurize date/time per creare un incorporamento vettoriale che rappresenta un campo datetime. Per utilizzare questa trasformazione, i dati datetime devono essere in uno dei seguenti formati:
-
Stringhe che descrivono datetime: Per esempio,
"January 1st, 2020, 12:44pm". -
Un timestamp Unix: un timestamp Unix descrive il numero di secondi, millisecondi, microsecondi o nanosecondi da /1970. 1/1
Puoi scegliere Formato inferisci datetime e fornire un Formato datetime. Se fornisci un formato datetime, devi usare i codici descritti nella Documentazione di Python
-
L'opzione più manuale e computazionalmente più veloce consiste nello specificare un Formato datetime e selezionare No per il Formato inferisci datetime.
-
Per ridurre il lavoro manuale, puoi scegliere il Formato inferisci datetime e non specificare un formato datetime. È anche un'operazione computazionalmente veloce; tuttavia, si presume che il primo formato datetime rilevato nella colonna di input sia il formato dell'intera colonna. Se nella colonna sono presenti altri formati, questi valori sono NaN nell'output finale. L'inferenza del formato datetime può fornire stringhe non analizzate.
-
Se non specifichi un formato e selezioni No per il Formato inferisci datetime, otterrai i risultati più affidabili. Tutte le stringhe datetime valide vengono analizzate. Tuttavia, questa operazione può essere un ordine di grandezza più lento rispetto alle prime due opzioni di questo elenco.
Quando si utilizza questa trasformazione, si specifica una Colonna di input che contiene dati datetime in uno dei formati sopra elencati. La trasformazione crea una colonna di output denominata Nome colonna di output. Il formato della colonna di output dipende dalla configurazione utilizzata utilizzando quanto segue:
-
Vettore: restituisce una singola colonna come vettore.
-
Colonne: crea una nuova colonna per ogni funzionalità. Ad esempio, se l'output contiene un anno, un mese e un giorno, vengono create tre colonne separate per anno, mese e giorno.
Inoltre, è necessario scegliere una Modalità di incorporamento. Per i modelli lineari e le reti profonde, consigliamo di scegliere la modalità ciclica. Per gli algoritmi ad albero, consigliamo di scegliere il valore ordinale.
Formattazione stringa
Le trasformazioni Formattazione stringa contengono operazioni standard di formattazione delle stringhe. Ad esempio, è possibile utilizzare queste operazioni per rimuovere caratteri speciali, normalizzare la lunghezza delle stringhe e aggiornare l'intestazione delle stringhe.
Questo gruppo di funzionalità contiene le seguenti trasformazioni. Tutte le trasformazioni restituiscono copie delle stringhe nella Colonna di input e aggiungono il risultato a una nuova colonna di output.
| Nome | Funzione |
|---|---|
| Impagina a sinistra |
Left-pad la stringa con un determinato carattere Fill alla larghezza data. Se la stringa è più lunga della larghezza, il valore restituito viene ridotto a caratteri di larghezza. |
| Impagina a destra |
Right-pad la stringa con un dato carattere Fill alla larghezza data. Se la stringa è più lunga della larghezza, il valore restituito viene ridotto a caratteri di larghezza. |
| Centro (impagina su entrambi i lati) |
Center-pad la stringa (aggiungi imbottitura su entrambi i lati della stringa) con un dato carattere Fill alla larghezza data. Se la stringa è più lunga della larghezza, il valore restituito viene ridotto a caratteri di larghezza. |
| Anteponi gli zeri |
Left-fill una stringa numerica con zeri, fino a una determinata larghezza. Se la stringa è più lunga della larghezza, il valore restituito viene ridotto a caratteri di larghezza. |
| Striscia a destra e a sinistra |
Restituisce una copia della stringa con i caratteri iniziali e finali rimossi. |
| Elimina i caratteri da sinistra |
Restituisce una copia della stringa con i caratteri iniziali rimossi. |
| Elimina i caratteri da destra |
Restituisce una copia della stringa con i caratteri finali rimossi. |
| Minuscolo |
Converte tutte le lettere del testo in lettere minuscole. |
| Maiuscolo |
Converte tutte le lettere del testo in maiuscolo. |
| Scrivi in maiuscolo |
Scrive in maiuscolo la prima lettera di ogni frase. |
| Scambio maiuscolo/minuscolo | Converte tutti i caratteri maiuscoli in minuscoli e tutti i caratteri minuscoli in caratteri maiuscoli della stringa data e la restituisce. |
| Aggiungi prefisso o suffisso |
Aggiunge un prefisso e un suffisso alla colonna della stringa. È necessario specificare almeno un Prefisso e un Suffisso. |
| Rimuovi i simboli |
Rimuove i simboli dati da una stringa. Tutti i caratteri elencati vengono rimossi. Il valore predefinito è lo spazio bianco. |
Gestisci i valori anomali
I modelli di machine learning sono sensibili alla distribuzione e alla gamma dei valori delle funzionalità. I valori anomali o rari, possono influire negativamente sulla precisione del modello e portare a tempi di addestramento più lunghi. Usa questo gruppo di funzionalità per rilevare e aggiornare i valori anomali nel tuo set di dati.
Quando si definisce una fase di trasformazione Gestisci i valori anomali, le statistiche utilizzate per rilevare i valori anomali vengono generate sui dati disponibili in Data Wrangler durante la definizione di questa fase. Queste stesse statistiche vengono utilizzate durante l'esecuzione di un processo Data Wrangler.
Utilizza le sezioni seguenti per avere ulteriori informazioni sulle trasformazioni contenute in questo gruppo. Si specifica un Nome di output e ciascuna di queste trasformazioni produce una colonna di output con i dati risultanti.
Irrobustisci i valori anomali numerici di deviazione standard
Questa trasformazione rileva e corregge i valori anomali nelle funzionalità numeriche utilizzando statistiche affidabili rispetto ai valori anomali.
È necessario definire un Quantile superiore e un Quantile inferiore per le statistiche utilizzate per calcolare i valori anomali. È inoltre necessario specificare il numero di Deviazioni standard rispetto alle quali un valore deve variare dalla media per essere considerato un valore anomalo. Ad esempio, se si specifica 3 per Deviazioni standard, un valore deve scendere di più di 3 deviazioni standard dalla media per essere considerato un valore anomalo.
Il Metodo di correzione è il metodo utilizzato per gestire i valori anomali quando vengono rilevati. È possibile scegliere tra le seguenti opzioni:
-
Taglia: utilizza questa opzione per ritagliare i valori anomali nel limite di rilevamento dei valori anomali corrispondente.
-
Rimuovi: utilizza questa opzione per rimuovere le righe con valori anomali dal dataframe.
-
Invalida: utilizzate questa opzione per sostituire valori anomali con quelli non validi.
Valori anomali numerici con deviazione standard
Questa trasformazione rileva e corregge i valori anomali nelle funzionalità numeriche utilizzando la media e la deviazione standard.
Si specifica il numero di Deviazioni standard. Un valore deve variare dalla media per essere considerato un valore anomalo. Ad esempio, se si specifica 3 per Deviazioni standard, un valore deve scendere di più di 3 deviazioni standard dalla media per essere considerato un valore anomalo.
Il Metodo di correzione è il metodo utilizzato per gestire i valori anomali quando vengono rilevati. È possibile scegliere tra le seguenti opzioni:
-
Taglia: utilizza questa opzione per ritagliare i valori anomali nel limite di rilevamento dei valori anomali corrispondente.
-
Rimuovi: utilizza questa opzione per rimuovere le righe con valori anomali dal dataframe.
-
Invalida: utilizzate questa opzione per sostituire valori anomali con quelli non validi.
Valori anomali numerici quantili
Utilizza questa trasformazione per rilevare e correggere i valori anomali nelle funzionalità numeriche utilizzando i quantili. È possibile definire un Quantile superiore e un Quantile inferiore. Tutti i valori che rientrano al di sopra del quantile superiore o al di sotto del quantile inferiore sono considerati valori anomali.
Il Metodo di correzione è il metodo utilizzato per gestire i valori anomali quando vengono rilevati. È possibile scegliere tra le seguenti opzioni:
-
Taglia: utilizza questa opzione per ritagliare i valori anomali nel limite di rilevamento dei valori anomali corrispondente.
-
Rimuovi: utilizza questa opzione per rimuovere le righe con valori anomali dal dataframe.
-
Invalida: utilizzate questa opzione per sostituire valori anomali con quelli non validi.
Min-Max Valori anomali numerici
Questa trasformazione rileva e corregge i valori anomali nelle funzionalità numeriche utilizzando soglie superiori e inferiori. Utilizza questo metodo se conosci i valori di soglia che contraddistinguono i valori anomali.
Si specifica una Soglia superiore e una Soglia inferiore e, se i valori sono rispettivamente superiori o inferiori a tali soglie, vengono considerati valori anomali.
Il Metodo di correzione è il metodo utilizzato per gestire i valori anomali quando vengono rilevati. È possibile scegliere tra le seguenti opzioni:
-
Taglia: utilizza questa opzione per ritagliare i valori anomali nel limite di rilevamento dei valori anomali corrispondente.
-
Rimuovi: utilizza questa opzione per rimuovere le righe con valori anomali dal dataframe.
-
Invalida: utilizzate questa opzione per sostituire valori anomali con quelli non validi.
Sostituisci raro
Quando si utilizza la trasformazione Sostituisci raro, si specifica una soglia e Data Wrangler trova tutti i valori che soddisfano tale soglia e li sostituisce con una stringa specificata dall'utente. Ad esempio, potresti voler utilizzare questa trasformazione per classificare tutti i valori anomali in una colonna in una categoria «Altri».
-
Stringa sostitutiva: la stringa con cui sostituire i valori anomali.
-
Soglia assoluta: una categoria è rara se il numero di istanze è inferiore o uguale a questa soglia assoluta.
-
Soglia di frazione: una categoria è rara se il numero di istanze è inferiore o uguale a questa soglia di frazione moltiplicata per il numero di righe.
-
Numero massimo di categorie comuni: numero massimo di categorie non rare che rimangono dopo l'operazione. Se la soglia non filtra un numero sufficiente di categorie, quelle con il maggior numero di presenze vengono classificate come non rare. Se impostato su 0 (impostazione predefinita), non esiste un limite rigido al numero di categorie.
Gestisci valori mancanti
I valori mancanti sono un evento comune nei set di dati di machine learning. In alcune situazioni, è opportuno attribuire ai dati mancanti un valore calcolato, ad esempio un valore medio o categoricamente comune. È possibile elaborare i valori mancanti utilizzando il gruppo di trasformazione Gestisci valori mancanti. Questo gruppo contiene le seguenti trasformazioni.
Riempi mancante
Utilizza la trasformazione Riempi mancante per sostituire i valori mancanti con un Valore di riempimento definito da te.
Imputa mancanti
Usa la trasformazione Imputa mancanti per creare una nuova colonna che contiene valori imputati in cui i valori mancanti sono stati trovati nei dati categorici e numerici di input. La configurazione dipende dal tipo di dati.
Per i dati numerici, scegli una strategia di imputazione, la strategia utilizzata per determinare il nuovo valore da imputare. Puoi scegliere di imputare la media o la mediana sui valori presenti nel tuo set di dati. Data Wrangler utilizza il valore calcolato per imputare i valori mancanti.
Per i dati categoriali, Data Wrangler imputa i valori mancanti utilizzando il valore più frequente nella colonna. Per imputare una stringa personalizzata, usa invece la trasformazione Riempi mancante.
Aggiungi indicatore per mancanti
Utilizza la trasformazione Aggiungi indicatore per mancanti per creare una nuova colonna di indicatore, che contiene un valore booleano "false" se una riga contiene un valore e "true" se una riga contiene un valore mancante.
Elimina mancanti
Utilizza l'opzione Elimina mancanti per eliminare le righe che contengono valori mancanti dalla Colonna di input.
Gestisci colonne
Puoi utilizzare le seguenti trasformazioni per aggiornare e gestire rapidamente le colonne nel tuo set di dati:
| Nome | Funzione |
|---|---|
| Escludi colonna | Elimina una colonna |
| Duplica colonna | Duplica una colonna |
| Rinomina colonna | Rinomina una colonna |
| Sposta colonna |
Sposta la posizione di una colonna nel set di dati. Scegli di spostare la colonna all'inizio o alla fine del set di dati, prima o dopo una colonna di riferimento o in un indice specifico. |
Gestisci righe
Usa questo gruppo di trasformazione per eseguire rapidamente operazioni di ordinamento e rimescolamento delle righe. Questo gruppo contiene quanto segue:
-
Ordina: ordina l'intero dataframe in base a una determinata colonna. Seleziona la casella di controllo accanto a Ordine crescente per questa opzione; in caso contrario, deseleziona la casella di controllo e per l'ordinamento verrà utilizzato l'ordine decrescente.
-
Mescola: mescola in modo casuale tutte le righe del set di dati.
Gestisci i vettori
Usa questo gruppo di trasformazione per combinare o appiattire le colonne vettoriali. Questo gruppo contiene le seguenti trasformazioni.
-
Assembla: usa questa trasformazione per combinare i vettori Spark e i dati numerici in un'unica colonna. Ad esempio, puoi combinare tre colonne: due contenenti dati numerici e una contenente vettori. Aggiungi tutte le colonne che desideri combinare nelle Colonne di input e specifica un Nome colonna di output per i dati combinati.
-
Appiattisci: usa questa trasformazione per appiattire una singola colonna contenente dati vettoriali. La colonna di input deve contenere PySpark vettori o oggetti simili a matrici. È possibile controllare il numero di colonne create specificando un Metodo per rilevare il numero di output. Ad esempio, se si seleziona Lunghezza del primo vettore, il numero di elementi nel primo vettore o matrice valido trovato nella colonna determina il numero di colonne di output che vengono create. Tutti gli altri vettori di input con troppi elementi vengono troncati. Gli input con un numero insufficiente di elementi vengono riempiti con. NaNs
È inoltre necessario specificare un Prefisso di output, che viene utilizzato come prefisso per ogni colonna di output.
Elaborazione numerica
Utilizza il gruppo di funzionalità Elaborazione numerica per elaborare dati numerici. Ogni scala in questo gruppo è definito utilizzando la libreria Spark. Sono supportate le seguenti scale:
-
Scala standard: standardizza la colonna di input sottraendo la media da ogni valore e scalando alla varianza unitaria. Per saperne di più, consulta la documentazione di Spark per. StandardScaler
-
Scala robusta: ridimensiona la colonna di input utilizzando statistiche affidabili rispetto ai valori anomali. Per saperne di più, consulta la documentazione di Spark per. RobustScaler
-
Scala min-max: trasforma la colonna di input ridimensionando ogni funzione in un determinato intervallo. Per saperne di più, consulta la documentazione di Spark per. MinMaxScaler
-
Scala assoluta max: ridimensiona la colonna di input dividendo ogni valore per il valore assoluto massimo. Per saperne di più, consulta la documentazione di Spark per. MaxAbsScaler
Campionamento
Dopo aver importato i dati, puoi utilizzare il trasformatore Campionamento per prelevarne uno o più campioni. Quando utilizzi il trasformatore di campionamento, Data Wrangler campiona il set di dati originale.
Puoi scegliere uno dei seguenti metodi di campionamento:
-
Limite: campiona il set di dati a partire dalla prima riga fino al limite specificato.
-
Randomizzato: preleva un campione casuale della dimensione specificata.
-
Stratificato: preleva un campione a caso stratificato.
È possibile stratificare un campione randomizzato per assicurarsi che rappresenti la distribuzione originale del set di dati.
Potresti eseguire la preparazione dei dati per diversi casi d'uso. Per ogni caso d'uso, puoi prendere un campione diverso e applicare un diverso set di trasformazioni.
La procedura seguente descrive la creazione di un campione casuale.
Per prelevare un campione casuale dai dati.
-
Scegli il segno + a destra del set di dati che hai importato. Il nome del set di dati si trova sotto il segno +.
-
Scegli Aggiungi trasformazione.
-
Scegli Campionamento.
-
Per Metodo di campionamento, scegli il metodo di campionamento.
-
Per Dimensione approssimativa del campione, scegli il numero approssimativo di osservazioni da inserire nel campione.
-
(Facoltativo) Specifica un numero intero per Seme casuale per creare un campione riproducibile.
La procedura seguente descrive il processo di creazione di un campione stratificato.
Per prelevare un campione stratificato dai dati.
-
Scegli il segno + a destra del set di dati che hai importato. Il nome del set di dati si trova sotto il segno +.
-
Scegli Aggiungi trasformazione.
-
Scegli Campionamento.
-
Per Metodo di campionamento, scegli il metodo di campionamento.
-
Per Dimensione approssimativa del campione, scegli il numero approssimativo di osservazioni da inserire nel campione.
-
Per Stratifica colonna, specifica il nome della colonna che vuoi stratificare.
-
(Facoltativo) Specifica un numero intero per Seme casuale per creare un campione riproducibile.
Ricerca e modifica
Usa questa sezione per cercare e modificare modelli specifici all'interno delle stringhe. Ad esempio, puoi trovare e aggiornare stringhe all'interno di frasi o documenti, dividere le stringhe per delimitatori e trovare le occorrenze di stringhe specifiche.
In Cerca e modifica sono supportate le seguenti trasformazioni. Tutte le trasformazioni restituiscono copie delle stringhe nella Colonna di input e aggiungono il risultato a una nuova colonna di output.
| Nome | Funzione |
|---|---|
|
Trova una sottostringa |
Restituisce l'indice della prima occorrenza della Sottostringa che hai cercato. Puoi iniziare e terminare la ricerca rispettivamente da Inizio e Fine. |
|
Trova la sottostringa (da destra) |
Restituisce l'indice dell'ultima occorrenza della Sottostringa che hai cercato. Puoi iniziare e terminare la ricerca rispettivamente con Inizio e Fine. |
|
Abbina il prefisso |
Restituisce un valore booleano se la stringa contiene un determinato Pattern. Un pattern può essere una sequenza di caratteri o un'espressione regolare. Facoltativamente, puoi fare distinzione tra maiuscole e minuscole nel pattern. |
|
Trova tutte le occorrenze |
Restituisce un array con tutte le occorrenze di un determinato pattern. Un pattern può essere una sequenza di caratteri o un'espressione regolare. |
|
Estrai usando espressione regolare |
Restituisce una stringa che corrisponde a un determinato pattern di espressione regolare. |
|
Estrai tra i delimitatori |
Restituisce una stringa con tutti i caratteri trovati tra il Delimitatore sinistro e il Delimitatore destro. |
|
Estrai dalla posizione |
Restituisce una stringa, a partire dalla Posizione iniziale della stringa di input, che contiene tutti i caratteri fino alla posizione iniziale più la Lunghezza. |
|
Trova e sostituisci la sottostringa |
Restituisce una stringa con tutte le corrispondenze di un determinato Pattern (espressione regolare) sostituite dalla Stringa sostitutiva. |
|
Sostituisci tra i delimitatori |
Restituisce una stringa con la sottostringa trovata tra la prima apparizione di un Delimitatore sinistro e l'ultima apparizione di un Delimitatore destro sostituita dalla Stringa di sostituzione. Se non viene trovata alcuna corrispondenza, non verrà sostituito nulla. |
|
Sostituzione dalla posizione |
Restituisce una stringa con la sottostringa compresa tra la Posizione iniziale e la Posizione iniziale più la Lunghezza sostituita dalla Stringa di sostituzione. Se la Posizione iniziale più la Lunghezza è maggiore della lunghezza della stringa sostitutiva, l'output contiene... |
|
Converti le espressioni regolari in espressioni mancanti |
Converte una stringa in |
|
Suddividi la stringa per delimitatore |
Restituisce un array di stringhe dalla stringa di input, suddiviso per Delimitatore, con un Numero massimo di suddivisioni (opzionale). Per impostazione predefinita, il delimitatore è lo spazio bianco. |
Suddividi dati
Usa la trasformazione Suddividi dati per suddividere il tuo set di dati in due o tre set di dati. Ad esempio, puoi suddividere il tuo set di dati in uno utilizzato per addestrare il modello e uno utilizzato per testarlo. È possibile determinare la proporzione del set di dati da inserire in ciascuna suddivisione. Ad esempio, se stai suddividendo un set di dati in due set di dati, il set di dati di addestramento può contenere l'80% dei dati mentre il set di dati di test ne ha il 20%.
La suddivisione dei dati in tre set di dati consente di creare set di dati di addestramento, convalida e test. Puoi vedere le prestazioni del modello sul set di dati di test eliminando la colonna di destinazione.
Il tuo caso d'uso determinerà la quantità di set di dati originali che ciascuno dei tuoi set di dati riceverà e il metodo da utilizzare per suddividere i dati. Ad esempio, potresti voler utilizzare una suddivisione stratificata per assicurarti che la distribuzione delle osservazioni nella colonna di destinazione sia la stessa tra i set di dati. È possibile utilizzare le seguenti trasformazioni di suddivisione:
-
Suddivisione randomizzata: ogni suddivisione è un campione casuale e non sovrapposto del set di dati originale. Per set di dati più grandi, l'utilizzo di una suddivisione randomizzata potrebbe essere costoso dal punto di vista computazionale e richiedere più tempo di una suddivisione ordinata.
-
Suddivisione ordinata: suddivide il set di dati in base all'ordine sequenziale delle osservazioni. Ad esempio, per una suddivisione 80/20 train-test, le prime osservazioni che costituiscono l'80% del set di dati vanno al set di dati di addestramento. L'ultimo 20% delle osservazioni va al set di dati di test. Le suddivisioni ordinate sono efficaci nel mantenere l'ordine esistente dei dati tra le suddivisioni.
-
Suddivisione stratificata: divide il set di dati per garantire che il numero di osservazioni nella colonna di input abbia una rappresentazione proporzionale. Per una colonna di input contenente le osservazioni 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, una 80/20 divisione sulla colonna significherebbe che circa l'80% degli 1, l'80% dei 2 e l'80% dei 3 vanno al training set. Circa il 20% di ogni tipo di osservazione va al set di test.
-
Suddividi per chiave: evita che i dati con la stessa chiave si trovino in più di una suddivisione. Ad esempio, se disponi di un set di dati con la colonna «id_cliente» e lo utilizzi come chiave, nessun ID cliente è presente in più di una suddivisione.
Dopo aver suddiviso i dati, puoi applicare trasformazioni aggiuntive a ciascun set di dati. Per la maggior parte dei casi d'uso, non sono necessarie.
Data Wrangler calcola le proporzioni delle suddivisioni in termini di prestazioni. È possibile scegliere una soglia di errore per impostare la precisione delle suddivisioni. Le soglie di errore più basse riflettono in modo più accurato le proporzioni specificate per le suddivisioni. Se si imposta una soglia di errore più elevata, si ottengono prestazioni migliori, ma una precisione inferiore.
Per una suddivisione dei dati perfetta, imposta la soglia di errore su 0. Per ottenere prestazioni migliori, puoi specificare una soglia compresa tra 0 e 1. Se specifichi un valore maggiore di 1, Data Wrangler interpreta tale valore come 1.
Se hai 10000 righe nel tuo set di dati e specifichi una 80/20 divisione con un errore di 0,001, otterresti osservazioni che si avvicinano a uno dei seguenti risultati:
-
8.010 osservazioni nel set di addestramento e 1.990 nel set di test
-
7.990 osservazioni nel set di addestramento e 2.010 nel set di test
Il numero di osservazioni per il test impostato nell'esempio precedente è compreso nell'intervallo tra 8.010 e 7.990.
Per impostazione predefinita, Data Wrangler utilizza un seme casuale per rendere riproducibili le suddivisioni. È possibile specificare un valore diverso per il seme per creare una suddivisione riproducibile diversa.
Analizza il valore come tipo
Usa questa trasformazione per convertire una colonna in un nuovo tipo. I tipi di dati supportati da Data Wrangler sono:
-
Long
-
Float
-
Booleano
-
Data, nel formato dd-MM-yyyy, che rappresenta rispettivamente giorno, mese e anno.
-
Stringa
Convalida stringa
Utilizzate le trasformazioni Convalida stringa per creare una nuova colonna che indichi che una riga di dati di testo soddisfa una condizione specificata. Ad esempio, puoi utilizzare una trasformazione Convalida stringa per verificare che una stringa contenga solo caratteri minuscoli. In Convalida stringa sono supportate le seguenti trasformazioni.
Le seguenti trasformazioni sono incluse in questo gruppo di trasformazioni. Se una trasformazione emette un valore booleano, True viene rappresentato con un 1 e False viene rappresentata con uno 0.
| Nome | Funzione |
|---|---|
|
Lunghezza delle stringhe |
Restituisce |
|
Inizia con |
Restituisce |
|
Ends with |
Restituisce |
|
È alfanumerico |
Restituisce |
|
È alfa (lettere) |
Restituisce |
|
È una cifra |
Restituisce |
|
È spazio |
Restituisce |
|
È titolo |
Restituisce |
|
È in minuscolo |
Restituisce |
|
È in maiuscolo |
Restituisce |
|
È numerico |
Restituisce |
|
È decimale |
Restituisce |
Unnest dei dati JSON
Se hai un file.csv, potresti avere valori nel tuo set di dati che sono stringhe JSON. Allo stesso modo, potresti avere dati annidati nelle colonne di un file Parquet o di un documento JSON.
Utilizza l'operatore Strutturato appiattito per separare le chiavi di primo livello in colonne separate. Una chiave di primo livello è una chiave che non è annidata all'interno di un valore.
Ad esempio, potresti avere un set di dati contenente una colonna relativa alle persone con informazioni demografiche su ogni persona archiviate come stringhe JSON. Una stringa JSON potrebbe assomigliare alla seguente.
"{"seq": 1,"name": {"first": "Nathaniel","last": "Ferguson"},"age": 59,"city": "Posbotno","state": "WV"}"
L'operatore Strutturato appiattito converte le seguenti chiavi di primo livello in colonne aggiuntive del set di dati:
-
seq
-
nome
-
età
-
città
-
stato
Data Wrangler inserisce i valori delle chiavi come valori sotto le colonne. Nell'esempio seguente vengono mostrati i nomi e i valori delle colonne del JSON.
seq, name, age, city, state 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV
Per ogni valore del set di dati contenente JSON, l'operatore Strutturato appiattito crea colonne per le chiavi di primo livello. Per creare colonne per chiavi annidate, richiama nuovamente l'operatore. Nell'esempio precedente, la chiamata all'operatore crea le colonne:
-
nome
-
cognome
L'esempio seguente mostra il set di dati che risulta richiamando l'operazione.
seq, name, age, city, state, name_first, name_last 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV, Nathaniel, Ferguson
Scegli Chiavi su cui appiattire per specificare le chiavi di primo livello che desideri estrarre come colonne separate. Se non specifichi alcuna chiave, per impostazione predefinita Data Wrangler estrae tutte le chiavi.
Esplodi array
Usa Esplodi array per espandere i valori dell'array in righe di output separate. Ad esempio, l'operazione può prendere ogni valore dell'array, [[1, 2, 3,], [4, 5, 6], [7, 8, 9]] e creare una nuova colonna con le seguenti righe:
[1, 2, 3] [4, 5, 6] [7, 8, 9]
Data Wrangler nomina la nuova colonna, input_colonna_nome_appiattito.
È possibile chiamare l'operazione Esplodi array più volte per ottenere i valori annidati dell'array in colonne di output separate. L'esempio seguente mostra il risultato di una chiamata all'operazione più volte su un set di dati con un array annidato.
Inserimento dei valori di una matrice nidificata in colonne separate
| id | array | id | elementi_array | id | elementi_elemento_array |
|---|---|---|---|---|---|
| 1 | [[gatto, cane], [pipistrello, rana]] | 1 | [gatto, cane] | 1 | gatto |
| 2 |
[[rosa, petunia], [giglio, margherita]] |
1 | [pipistrello, rana] | 1 | cane |
| 2 | [rosa, petunia] | 1 | pipistrello | ||
| 2 | [giglio, margherita] | 1 | rana | ||
| 2 | 2 | rosa | |||
| 2 | 2 | petunia | |||
| 2 | 2 | giglio | |||
| 2 | 2 | margherita |
Trasformazione dei dati di immagine
Usa Data Wrangler per importare e trasformare le immagini che utilizzi per le tue pipeline di machine learning (ML). Dopo aver preparato i dati delle immagini, puoi esportarli dal flusso di Data Wrangler alla pipeline di ML.
Puoi utilizzare le informazioni fornite qui per acquisire familiarità con l'importazione e la trasformazione dei dati di immagine in Data Wrangler. Data Wrangler utilizza OpenCV per importare immagini. Per ulteriori informazioni sui formati di immagine supportati, consulta Lettura e scrittura di file immagine
Dopo aver acquisito familiarità con i concetti di trasformazione dei dati di immagine, segui il seguente tutorial, Prepara i dati delle immagini con Amazon SageMaker
I seguenti settori e casi d'uso sono esempi in cui l'applicazione della machine learning ai dati delle immagini trasformati può essere utile:
-
Produzione: identificazione dei difetti negli articoli della linea di assemblaggio
-
Cibo: individuazione di alimenti avariati o marci
-
Medicina: individuazione delle lesioni nei tessuti
Quando lavori con dati di immagine in Data Wrangler, segui il seguente processo:
-
Importa: seleziona le immagini scegliendo la directory che le contiene nel bucket Amazon S3.
-
Trasforma: utilizza le trasformazioni integrate per preparare le immagini per la tua pipeline di machine learning.
-
Esporta: esporta le immagini che hai trasformato in una posizione accessibile dalla pipeline.
Utilizza la procedura seguente per importare i dati di immagine.
Per importare i dati delle immagini
-
Vai alla pagina Crea connessione.
-
Seleziona Amazon S3.
-
Specifica il percorso del file Amazon S3 che contiene i dati di immagine.
-
Per Tipo di file, scegli Immagine.
-
(Facoltativo) Scegli Importa directory annidate per importare immagini da più percorsi Amazon S3.
-
Scegli Importa.
Per le trasformazioni delle immagini integrate Data Wrangler utilizza la libreria open source imgaug
-
ResizeImage
-
EnhanceImage
-
CorruptImage
-
SplitImage
-
DropCorruptedImages
-
DropImageDuplicates
-
Luminosità
-
ColorChannels
-
Scala di grigi
-
Ruota
Utilizza la procedura seguente per trasformare le tue immagini senza scrivere il codice.
Per trasformare i dati dell'immagine senza scrivere il codice
-
Dal flusso Data Wrangler, scegli il segno + accanto al nodo che rappresenta le immagini che hai importato.
-
Scegli Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli la trasformazione e configurala.
-
Scegli Anteprima.
-
Scegli Aggiungi.
Oltre a utilizzare le trasformazioni fornite da Data Wrangler, puoi anche utilizzare frammenti di codice personalizzati. Per ulteriori informazioni sull'utilizzo di frammenti di codice personalizzati, consulta Trasformazioni personalizzate. Puoi importare le librerie OpenCV e imgaug all'interno dei tuoi frammenti di codice e utilizzare le trasformazioni ad esse associate. Il seguente è un esempio di un frammento di codice che rileva i bordi all'interno delle immagini.
# A table with your image data is stored in the `df` variable import cv2 import numpy as np from pyspark.sql.functions import column from sagemaker_dataprep.compute.operators.transforms.image.constants import DEFAULT_IMAGE_COLUMN, IMAGE_COLUMN_TYPE from sagemaker_dataprep.compute.operators.transforms.image.decorators import BasicImageOperationDecorator, PandasUDFOperationDecorator @BasicImageOperationDecorator def my_transform(image: np.ndarray) -> np.ndarray: # To use the code snippet on your image data, modify the following lines within the function HYST_THRLD_1, HYST_THRLD_2 = 100, 200 edges = cv2.Canny(image,HYST_THRLD_1,HYST_THRLD_2) return edges @PandasUDFOperationDecorator(IMAGE_COLUMN_TYPE) def custom_image_udf(image_row): return my_transform(image_row) df = df.withColumn(DEFAULT_IMAGE_COLUMN, custom_image_udf(column(DEFAULT_IMAGE_COLUMN)))
Quando applica trasformazioni nel flusso di Data Wrangler, Data Wrangler le applica solo a un campione delle immagini nel set di dati. Per ottimizzare l'esperienza con l'applicazione, Data Wrangler non applica le trasformazioni a tutte le immagini.
Per applicare le trasformazioni a tutte le immagini, esporta il flusso Data Wrangler in una posizione Amazon S3. Puoi utilizzare le immagini che hai esportato nelle tue pipeline di addestramento o inferenza. Usa un nodo di destinazione o un notebook Jupyter per esportare i tuoi dati. Puoi accedere a entrambi i metodi per esportare i tuoi dati dal flusso Data Wrangler. Per ulteriori informazioni sull'uso di questi metodi, consulta Esportazione in Amazon S3.
Filtrare i dati
Usa Data Wrangler per filtrare i dati nelle tue colonne. Quando si filtrano i dati in una colonna, si specificano i seguenti campi:
-
Nome colonna: il nome della colonna che stai utilizzando per filtrare i dati.
-
Condizione: il tipo di filtro che applichi ai valori nella colonna.
-
Valore: il valore o la categoria nella colonna a cui stai applicando il filtro.
Puoi applicare un filtro alle seguenti condizioni:
-
=: restituisce valori che corrispondono al valore o alla categoria specificati.
-
!= : restituisce valori che non corrispondono al valore o alla categoria specificati.
-
>= : per dati Long o Float, filtra i valori maggiori o uguali al valore specificato.
-
<= : per dati Long o Float, filtra i valori inferiori o uguali al valore specificato.
-
> : per dati Long o Float, filtra i valori che sono maggiori del valore specificato.
-
< : per dati Long o Float, filtra i valori inferiori al valore specificato.
Per una colonna che contiene le categorie male e female, puoi filtrare tutti i valori male. Puoi anche filtrare tutti i valori female. Poiché nella colonna sono presenti solo valori male e female, il filtro restituisce una colonna contenente solo valori female.
Puoi inoltre aggiungere più filtri. I filtri possono essere applicati su più colonne o sulla stessa colonna. Ad esempio, se stai creando una colonna con valori solo all'interno di un determinato intervallo, aggiungi due filtri diversi. Un filtro specifica che la colonna deve avere valori maggiori del valore fornito. L'altro filtro specifica che la colonna deve avere valori inferiori al valore fornito.
Utilizza la seguente procedura per aggiungere la trasformazione del filtro ai tuoi dati.
Per filtrare i dati
-
Dal flusso Data Wrangler, scegli il segno + accanto al nodo con i dati che stai filtrando.
-
Scegli Aggiungi trasformazione.
-
Scegli Aggiungi fase.
-
Scegli Filtra dati.
-
Specifica i seguenti campi:
-
Nome colonna: la colonna che stai filtrando.
-
Condizione: la condizione del filtro.
-
Valore: il valore o la categoria nella colonna a cui stai applicando il filtro.
-
-
(Facoltativo) Scegli il segno + dopo il filtro che hai creato.
-
Configurare il filtro.
-
Scegli Anteprima.
-
Scegli Aggiungi.
Colonne della mappa per Amazon Personalize
Data Wrangler si integra con Amazon Personalize, un servizio di machine learning completamente gestito che genera consigli sugli articoli e segmenti di utenti. Puoi utilizzare la trasformazione Colonne Map per Amazon Personalize per ottenere i dati in un formato interpretabile da Amazon Personalize. Per ulteriori informazioni sulle trasformazioni specifiche di Amazon Personalize, consulta Importazione di dati con Amazon SageMaker Data Wrangler. Per ulteriori informazioni su Amazon Personalize, consulta Che cos'è Amazon Personalize?
