Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Importa
Puoi utilizzare Amazon SageMaker Data Wrangler per importare dati dalle seguenti fonti di dati: Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift e Snowflake. Il set di dati che importi può includere fino a 1000 colonne.
Argomenti
Alcune fonti di dati consentono di aggiungere più connessioni dati:
-
È possibile connettersi a più cluster Amazon Redshift. Ogni cluster diventa un'origine dati.
-
Puoi effettuare una query a qualsiasi database Athena del tuo account per importare dati da quel database.
Quando importi un set di dati da un'origine dati, questo viene visualizzato nel flusso di dati. Data Wrangler deduce automaticamente il tipo di dati di ogni colonna del set di dati. Per modificare questi tipi, seleziona la fase Tipi di dati e poi Modifica tipi di dati.
Quando importi dati da Athena o Amazon Redshift, i dati importati vengono automaticamente archiviati nel bucket AI S3 SageMaker predefinito per AWS la regione in cui utilizzi Studio Classic. Inoltre, Athena archivia i dati visualizzati in anteprima in Data Wrangler in questo bucket. Per ulteriori informazioni, consulta Archiviazione di dati importati.
Importante
Il bucket Amazon S3 predefinito potrebbe non avere le impostazioni di sicurezza meno permissive, come la policy del bucket e la crittografia lato server (SSE). Ti consigliamo vivamente di aggiungere una policy sui bucket per limitare l'accesso ai set di dati importati in Data Wrangler.
Importante
Inoltre, se utilizzi la policy gestita per l' SageMaker IA, ti consigliamo vivamente di limitarla alla policy più restrittiva che ti consenta di soddisfare il tuo caso d'uso. Per ulteriori informazioni, consulta Concedi un'autorizzazione al ruolo IAM per utilizzare Data Wrangler.
Tutte le origini dati ad eccezione di Amazon Simple Storage Service (Amazon S3) richiedono di specificare una query SQL per importare i dati. Per ogni query, è necessario specificare quanto segue:
-
Catalogo dati
-
Database
-
Tabella
Puoi specificare il nome del database o del catalogo dati nei menu a discesa o all'interno della query. Di seguito vengono mostrati esempi di query.
-
select * from: la query non utilizza nulla di quanto specificato nei menu a discesa dell'interfaccia utente (UI) per l'esecuzione. Interrogaexample-data-catalog-name.example-database-name.example-table-nameexample-table-nameall'interno diexample-database-namedentroexample-data-catalog-name -
select * from: la query utilizza il catalogo di dati specificato nel menu a discesa Data catalog per l'esecuzione. Esegue una queryexample-database-name.example-table-nameexample-table-nameall'interno diexample-database-namedentro il catalogo di dati che hai specificato. -
select * from: la query richiede di selezionare i campi dei menu a discesa Data catalog e Database name. Esegue una queryexample-table-nameexample-table-nameall'interno del catalogo, dentro il detabase e il catalogo di dati che hai specificato.
Il collegamento tra Data Wrangler e l'origine dati è una connessione. La connessione viene utilizzata per importare dati dalla propria origine dati.
Esistono i seguenti tipi di connessioni:
-
Diretta
-
Catalogata
Data Wrangler ha sempre accesso ai dati più recenti tramite una connessione diretta. Se i dati in origine dati sono stati aggiornati, è possibile utilizzare la connessione per importare i dati. Ad esempio, se qualcuno aggiunge un file a uno dei tuoi bucket Amazon S3, puoi importare il file.
Una connessione catalogata è il risultato di un trasferimento di dati. I dati nella connessione catalogata non contengono necessariamente i dati più recenti. Ad esempio, potresti configurare un trasferimento di dati tra Salesforce e Amazon S3. Se è disponibile un aggiornamento dei dati di Salesforce, devi trasferirli nuovamente. Puoi automatizzare il processo di trasferimento dei dati. Per ulteriori informazioni sul trasferimento di dati, consultare Importare dati da piattaforme Software as a Service (SaaS).
Importa i dati da Amazon S3
È possibile utilizzare Amazon Simple Storage Service (Amazon S3) per memorizzare e recuperare qualsiasi volume di dati, in qualunque momento e da qualunque luogo tramite il Web. Puoi eseguire queste attività utilizzando AWS Management Console, che è un'interfaccia Web semplice e intuitiva, e l'API Amazon S3. Se hai archiviato il set di dati localmente, ti consigliamo di aggiungerlo a un bucket S3 per l'importazione in Data Wrangler. Per sapere come fare, consulta Caricamento di un oggetto nel bucket nella Guida per l'utente di Amazon Simple Storage Service.
Data Wrangler utilizza S3 Select
Importante
Se prevedi di esportare un flusso di dati e avviare un job Data Wrangler, importare dati in un feature SageMaker store di intelligenza artificiale o creare una pipeline SageMaker AI, tieni presente che queste integrazioni richiedono che i dati di input di Amazon S3 si trovino nella stessa regione. AWS
Importante
Se stai importando un file CSV, assicurati che soddisfi i seguenti requisiti:
-
Un record nel set di dati non può contenere più di una riga.
-
Una barra rovesciata,
\, è l'unico carattere di escape valido. -
Il set di dati deve utilizzare uno dei seguenti delimitatori:
-
Virgola –
, -
Due punti –
: -
Punto e virgola –
; -
Pipeline –
| -
Scheda –
[TAB]
-
Per risparmiare spazio, puoi importare file CSV compressi.
Data Wrangler ti dà la possibilità di importare l'intero set di dati o di campionarne una parte. Per Amazon S3 sono disponibili le seguenti opzioni di campionamento:
-
Nessuno: importa l'intero set di dati.
-
First K: campiona le prime righe K del set di dati, dove K è un numero intero specificato.
-
Randomizzato: preleva un campione a caso della dimensione specificata dall'utente.
-
Stratificato: preleva un campione a caso stratificato. Un campione stratificato mantiene il rapporto dei valori di una colonna.
Dopo aver importato i dati, puoi anche utilizzare il trasformatore di campionamento per prelevare uno o più campioni dall'intero set di dati. Per ulteriori informazioni sul trasformatore di campionamento, consulta Campionamento.
Puoi utilizzare uno dei seguenti identificatori di risorse per importare i dati:
-
Un URI Amazon S3 che utilizza un bucket Amazon S3 o un punto di accesso Amazon S3
-
Un alias del punto di accesso Amazon S3
-
Un nome della risorsa Amazon (ARN) che utilizza un Punto di accesso Amazon S3 o un bucket Amazon S3
I punti di accesso Amazon S3 sono endpoint di rete denominati che vengono collegati ai bucket. Ogni punto di accesso dispone di autorizzazioni e controlli di rete distinti che puoi configurare. Per maggiori informazioni sui punti di accesso, vedi Gestione dell'accesso ai dati con Punti di accesso Amazon S3.
Importante
Se utilizzi un Amazon Resource Name (ARN) per importare i tuoi dati, deve trattarsi di una risorsa situata nella stessa Regione AWS che stai utilizzando per accedere ad Amazon SageMaker Studio Classic.
Puoi importare un singolo file o più file come set di dati. Puoi utilizzare l'operazione di importazione multifile quando si dispone di un set di dati suddiviso in file separati. Prende tutti i file da una directory Amazon S3 e li importa come un unico set di dati. Per informazioni sui tipi di file che puoi importare e su come importarli, consulta le seguenti sezioni.
Puoi anche utilizzare i parametri per importare un sottoinsieme di file che corrispondono a un modello. I parametri consentono di scegliere in modo più selettivo i file da importare. Per iniziare a utilizzare i parametri, modifica l'origine dati e applicali al percorso che stai utilizzando per importare i dati. Per ulteriori informazioni, consulta Riutilizzo dei flussi di dati per set di dati diversi.
Importazione dei dati da Athena
Usa Amazon Athena per importare dati da Amazon Simple Storage Service (Amazon S3) in Data Wrangler. In Athena, scrivi query SQL standard per selezionare i dati che importi da Amazon S3. Per ulteriori informazioni, consulta Che cos'è Amazon Athena?
Puoi usare il AWS Management Console per configurare Amazon Athena. È necessario creare almeno un database in Athena prima di iniziare a eseguire le query. Per maggiori informazioni su come iniziare a lavorare con Athena, consulta la sezione Nozioni di base.
Athena è direttamente integrata con Data Wrangler. Puoi scrivere query Athena senza dover uscire dall'interfaccia utente di Data Wrangler.
Oltre a scrivere semplici query Athena in Data Wrangler, puoi anche usare:
-
Gruppi di lavoro Athena per la gestione dei risultati delle query. Per ulteriori informazioni sui gruppi di lavoro, consulta Gestione dei risultati di query.
-
Configurazioni del ciclo di vita per l'impostazione dei periodi di conservazione dei dati. Per altre informazioni sulla conservazione dei dati, consulta Impostazione dei periodi di conservazione dei dati.
Esegui una query su Athena all'interno di Data Wrangler
Nota
Data Wrangler non supporta le query federate.
Se utilizzi AWS Lake Formation con Athena, assicurati che le autorizzazioni IAM di Lake Formation non abbiano la precedenza sulle autorizzazioni IAM per il database. sagemaker_data_wrangler
Data Wrangler ti dà la possibilità di importare l'intero set di dati o di campionarne una parte. Per Athena sono disponibili le seguenti opzioni di campionamento:
-
Nessuno: importa l'intero set di dati.
-
First K: campiona le prime righe K del set di dati, dove K è un numero intero specificato.
-
Randomizzato: preleva un campione a caso della dimensione specificata dall'utente.
-
Stratificato: preleva un campione a caso stratificato. Un campione stratificato mantiene il rapporto dei valori di una colonna.
La procedura seguente mostra come importare un set di dati da Athena in Data Wrangler.
Per importare un set di dati in Data Wrangler da Athena
-
Accedi ad Amazon SageMaker AI Console
. -
Scegli Studio
-
Scegli Launch app.
-
Dall'elenco a discesa, seleziona Studio.
-
Scegli l'icona Home.
-
Selezionare Data (Dati).
-
Scegli Data Wrangler.
-
Scegli Import data (Importa dati).
-
In Available (Disponibile), seleziona Amazon Athena.
-
Per Data Catalog, scegli un catalogo di dati.
-
Utilizza l'elenco a discesa Database per selezionare il database su cui eseguire le query. Quando si seleziona un database, è possibile visualizzare in anteprima tutte le tabelle del database utilizzando le tabelle elencate in Details (Dettagli).
-
(Opzionale) Scegli Advanced configuration (Advanced configuration (Configurazione avanzata).
-
Scegli un Workgroup (Gruppo di lavoro).
-
Se il tuo gruppo di lavoro non ha imposto la posizione di output di Amazon S3 o se non utilizzi un gruppo di lavoro, specifica un valore per Amazon S3 location of query results (Posizione Amazon S3 dei risultati delle query).
-
(Facoltativo) Per Data retention period, (Periodo di conservazione dei dati) seleziona la casella di controllo per impostare un periodo di conservazione dei dati e specifica il numero di giorni in cui archiviare i dati prima che vengano eliminati.
-
(Facoltativo) Per impostazione predefinita, Data Wrangler salva la connessione. È possibile scegliere di deselezionare la casella di controllo e non salvare la connessione.
-
-
Per Sampling (Campionamento), scegliete un metodo di campionamento. Scegliete None (Nessuno) per disattivare il campionamento.
-
Inserisci la tua query nell'editor di query e usa il pulsante Esegui (Run) per eseguire la query. Dopo una query riuscita, puoi visualizzare l'anteprima del risultato nell'editor.
Nota
I dati di Salesforce utilizzano il tipo
timestamptz. Se staieseguendo una query sulla colonna del timestamp che hai importato in Athena da Salesforce, trasmetti i dati nella colonna al tipotimestamp. La seguente query imposta la colonna del timestamp nel tipo corretto.# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
Per importare i risultati della query, seleziona Import (Importa).
Dopo aver completato la procedura precedente, il set di dati che hai interrogato e importato viene visualizzato nel flusso di Data Wrangler.
Per impostazione predefinita, Data Wrangler salva le impostazioni di connessione come nuova connessione. Quando importi i tuoi dati, la query che hai già specificato appare come una nuova connessione. Le connessioni salvate memorizzano informazioni sui gruppi di lavoro Athena e sui bucket Amazon S3 che stai utilizzando. Quando ti connetti nuovamente alla origine dati, puoi scegliere la connessione salvata.
Gestione dei risultati di query
Data Wrangler supporta l'utilizzo dei gruppi di lavoro Athena per gestire i risultati delle query all'interno di un account AWS . Puoi specificare una posizione di output Amazon S3 per ogni gruppo di lavoro. Puoi anche specificare se l'output della query può essere inviato a diverse ubicazioni Amazon S3. Per ulteriori informazioni, consulta Uso dei gruppi di lavoro per controllare l'accesso alle query e i costi.
Il tuo gruppo di lavoro potrebbe essere configurato per applicare la posizione di output delle query di Amazon S3. Non puoi modificare la posizione di output dei risultati delle query per tali gruppi di lavoro.
Se non utilizzi un gruppo di lavoro o non specifichi una posizione di output per le tue query, Data Wrangler utilizza il bucket Amazon S3 predefinito nella stessa AWS regione in cui si trova l'istanza di Studio Classic per archiviare i risultati delle query Athena. Crea tabelle temporanee in questo database per spostare l'output della query in questo bucket Amazon S3. Elimina queste tabelle dopo l'importazione dei dati; tuttavia il database, sagemaker_data_wrangler, persiste. Per ulteriori informazioni, consulta Archiviazione di dati importati.
Per utilizzare i gruppi di lavoro Athena, configura la policy IAM che consente l'accesso ai gruppi di lavoro. Se utilizzi un SageMaker AI-Execution-Role, ti consigliamo di aggiungere la policy al ruolo. Per ulteriori informazioni sulla policy IAM per i gruppi di lavoro, consulta Policy IAM per l'accesso ai gruppi di lavoro. Per esempi di policy per i gruppi di lavoro, consulta Esempi di policy per i gruppi di lavoro.
Impostazione dei periodi di conservazione dei dati
Data Wrangler imposta automaticamente un periodo di conservazione dei dati per i risultati della query. I risultati vengono eliminati dopo la durata del periodo di conservazione. Ad esempio, il periodo di conservazione predefinito è di cinque giorni. I risultati della query vengono eliminati dopo cinque giorni. Questa configurazione è progettata per aiutarti a ripulire i dati che non utilizzi più. La pulizia dei dati impedisce l'accesso agli utenti non autorizzati. Inoltre, aiuta a controllare i costi di archiviazione dei dati su Amazon S3.
Se non imposti un periodo di conservazione, la configurazione del ciclo di vita di Amazon S3 determina la durata di archiviazione degli oggetti. Il criterio di conservazione dei dati che hai specificato per la configurazione del ciclo di vita rimuove i risultati delle query che sono più vecchi della configurazione del ciclo di vita che hai specificato. Per ulteriori informazioni, consulta Impostazione della configurazione del ciclo di vita in un bucket.
Data Wrangler utilizza le configurazioni del ciclo di vita di Amazon S3 per gestire la conservazione e la scadenza dei dati. È necessario concedere le autorizzazioni del ruolo di esecuzione di Amazon SageMaker Studio Classic IAM per gestire le configurazioni del ciclo di vita dei bucket. Utilizza la seguente procedura per concedere le autorizzazioni.
Per concedere le autorizzazioni a gestire la configurazione del ciclo di vita, procedi come segue.
-
Accedi AWS Management Console e apri la console IAM all'indirizzo. https://console.aws.amazon.com/iam/
-
Scegli Ruoli.
-
Nella barra di ricerca, specifica il ruolo di esecuzione di Amazon SageMaker AI utilizzato da Amazon SageMaker Studio Classic.
-
Seleziona il ruolo.
-
Scegli Add Permissions (Aggiungi autorizzazioni).
-
Scegli Create inline policy (Crea policy in linea).
-
Per Service (Servizio), specifica S3 e sceglilo.
-
Nella sezione Leggi, scegli GetLifecycleConfiguration.
-
Nella sezione Scrittura, scegli PutLifecycleConfiguration.
-
In Risorse, scegli Specifiche.
-
Per Azioni, seleziona l'icona a forma di freccia accanto a Gestione delle autorizzazioni.
-
Scegli PutResourcePolicy.
-
In Risorse, scegli Specifiche.
-
Scegli la casella di controllo accanto a Qualsiasi in questo account.
-
Scegli Verifica policy.
-
Per Nome, specificare un nome.
-
Scegli Crea policy.
Importazione di dati da Amazon Redshift
Amazon Redshift è un servizio di data warehouse nel cloud in scala petabyte interamente gestito. La prima fase necessaria per creare un data warehouse è avviare un set di nodi, detto cluster Amazon Redshift. Dopo avere effettuato il provisioning del cluster, puoi caricare il set di dati e quindi eseguire query di analisi dei dati.
Puoi connetterti e eseguire query su uno o più cluster Amazon Redshift in Data Wrangler. Per utilizzare questa opzione di importazione, devi creare almeno un cluster in Amazon Redshift. Per scoprire come, consulta la pagina Nozioni di base su Amazon Redshift.
Puoi generare i risultati della query Amazon Redshift in una delle seguenti posizioni:
-
Il bucket Amazon S3 predefinito
-
Una posizione di output Amazon S3 specificata
Puoi importare l'intero set di dati o campionarne una parte. Per Amazon Redshift sono disponibili le seguenti opzioni di campionamento:
-
Nessuno: importa l'intero set di dati.
-
First K: campiona le prime righe K del set di dati, dove K è un numero intero specificato.
-
Randomizzato: preleva un campione a caso della dimensione specificata dall'utente.
-
Stratificato: preleva un campione a caso stratificato. Un campione stratificato mantiene il rapporto dei valori di una colonna.
Il bucket Amazon S3 predefinito si trova nella stessa AWS regione in cui si trova l'istanza di Studio Classic per archiviare i risultati delle query di Amazon Redshift. Per ulteriori informazioni, consulta Archiviazione di dati importati.
Per il bucket Amazon S3 predefinito o per il bucket specificato, sono disponibili le seguenti opzioni di crittografia:
-
La crittografia AWS lato servizio predefinita con una chiave gestita Amazon S3 () SSE-S3
-
Una chiave AWS Key Management Service (AWS KMS) specificata
Una AWS KMS chiave è una chiave di crittografia che puoi creare e gestire. Per ulteriori informazioni sulle chiavi KMS, consulta AWS Key Management Service.
Puoi specificare una AWS KMS chiave utilizzando la chiave ARN o l'ARN del tuo account. AWS
Se utilizzi la policy gestita da IAM, AmazonSageMakerFullAccess, per concedere a un ruolo l’autorizzazione per utilizzare Data Wrangler in Studio Classic, il nome dell’utente del database deve avere il prefisso sagemaker_access.
Utilizza le seguenti procedure per scoprire come aggiungere un nuovo cluster.
Nota
Data Wrangler utilizza l'API dati Amazon Redshift Data con credenziali temporanee. Per ulteriori informazioni su questa API, consulta Uso dell'API dati di Amazon Redshift nella Guida alla gestione di Amazon Redshift.
Per connettere a un cluster Amazon Redshift
-
Accedi ad Amazon SageMaker AI Console
. -
Scegli Studio
-
Scegli Launch app.
-
Dall'elenco a discesa, seleziona Studio.
-
Scegli l'icona Home.
-
Selezionare Data (Dati).
-
Scegli Data Wrangler.
-
Scegli Import data (Importa dati).
-
In Available (Disponibile), seleziona Amazon Athena.
-
Scegli Amazon Redshift.
-
Scegli Temporary credentials (IAM) (Credenziali temporanee (IAM) per Type (Tipo)
-
Inserisci un Nome di connessione. Questo è un nome usato da Data Wrangler per identificare questa connessione.
-
Inserisci l'identificatore del cluster per specificare a quale cluster desideri connetterti. Nota: inserisci solo l'identificatore del cluster e non l'endpoint completo del cluster Amazon Redshift.
-
Inserisci il Database Name (Nome del database) a cui vuoi collegarti.
-
Inserisci un Database User (utente del database) per identificare l'utente che desideri utilizzare per connetterti al database.
-
Per UNLOAD IAM Role (SCARICARE il ruolo IAM), inserisci l'ARN del ruolo IAM che il cluster Amazon Redshift dovrebbe assumere per spostare e scrivere dati su Amazon S3. Per ulteriori informazioni su questo ruolo, consulta Autorizzazione di Amazon Redshift ad accedere ad AWS altri servizi per tuo conto nella Amazon Redshift Management Guide.
-
Scegli Connetti.
-
(Facoltativo) Per Amazon S3 output location (Posizione di output di Amazon S3), specifica l'URI S3 per archiviare i risultati della query.
-
(Facoltativo) Per l'KMS key ID (ID della chiave KMS), specifica l'ARN della chiave o la chiave AWS KMS o l'alias. L'immagine seguente mostra dove è possibile trovare entrambe le chiavi in AWS Management Console.
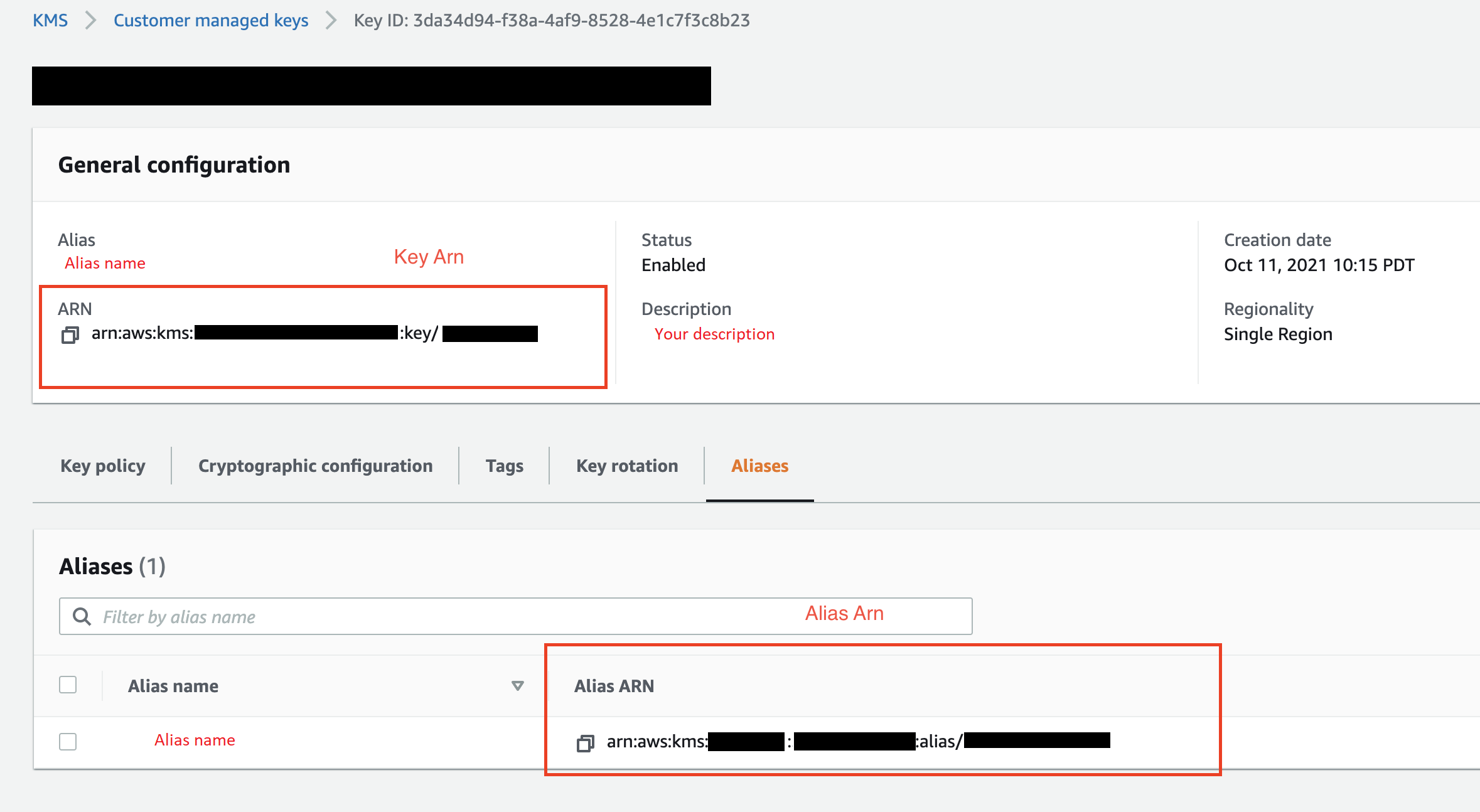
L'immagine seguente mostra tutti i campi della procedura precedente.
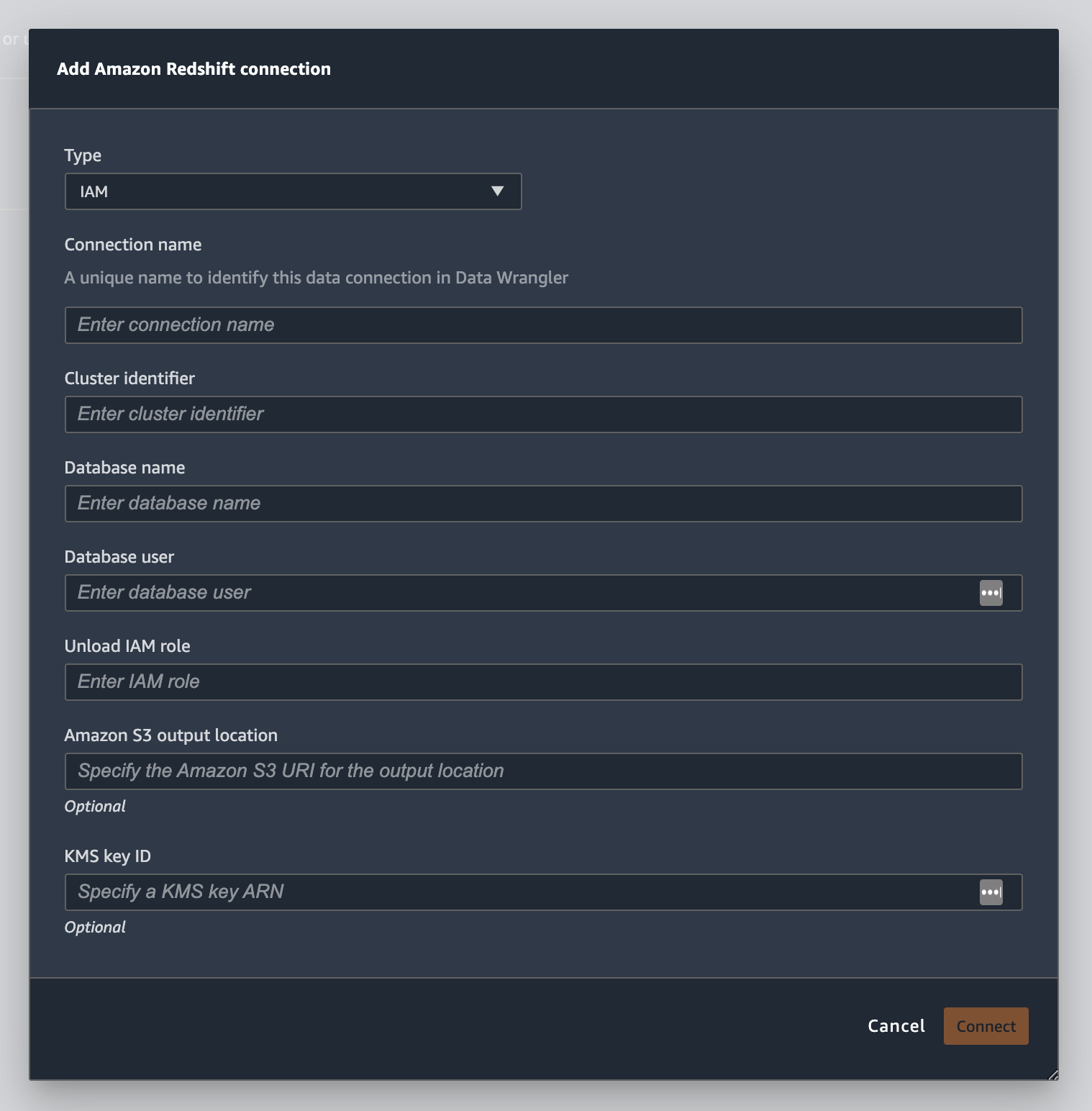
Una volta stabilita con successo, la connessione viene visualizzata come origine dati in Data Import (Importazione dati). Seleziona questa origine dati eseguire una query sul tuo database e importare i dati.
Per eseguire una query e importare i dati da Amazon Redshift
-
Seleziona la connessione sulla quale vuoi effettuare la query da Data Sources (Origine dati).
-
Seleziona uno Schema. Per saperne di più sugli schemi di Amazon Redshift, vedi Schemi nella Guida per gli sviluppatori di database di Amazon Redshift.
-
(Facoltativo) In Advanced configuration (Configurazione avanzata), specifica il metodo di Sampling (Campionamento) che desideri utilizzare.
-
Inserisci la tua query nell'editor di query e scegli Run (Esegui) per eseguire la query. Dopo una query riuscita, puoi visualizzare l'anteprima del risultato nell'editor.
-
Seleziona Import dataset (Importa set di dati) per importare il set di dati che è stato interrogato.
-
Inserire un Dataset name (Nome set di dati). Se aggiungi un Dataset name che contiene spazi, questi spazi vengono sostituiti da caratteri di sottolineatura quando il set di dati viene importato.
-
Scegliere Aggiungi.
Per modificare un set di dati, esegui le operazioni descritte di seguito.
-
Accedi al tuo flusso Data Wrangler.
-
Scegli la + accanto a Source - Sampled.
-
Modifica i dati che stai importando.
-
Seleziona Apply (Applica)
Importazione di dati da Amazon EMR
Puoi usare Amazon EMR come fonte di dati per il tuo flusso Amazon SageMaker Data Wrangler. Amazon EMR è una piattaforma cluster gestita che puoi utilizzare per elaborare e analizzare grandi quantità di dati. Per ulteriori informazioni su Amazon EMR consulta Che cos'è Amazon EMR su EKS? Per importare un set di dati da EMR, devi connetterti ad esso ed effettuare la query.
Importante
È necessario soddisfare i seguenti prerequisiti per connettersi a un cluster Amazon EMR:
Prerequisiti
-
Configurazioni di rete
-
Hai un Amazon VPC nella regione che stai utilizzando per avviare Amazon SageMaker Studio Classic e Amazon EMR.
-
Sia Amazon EMR che Amazon SageMaker Studio Classic devono essere avviati in sottoreti private. Possono trovarsi nella stessa sottorete o in diverse sottoreti.
-
Amazon SageMaker Studio Classic deve essere in VPC-only modalità.
Per maggiori informazioni sulla creazione di un VPC, consulta Creazione di un VPC.
Per ulteriori informazioni sulla creazione di un VPC, consulta Connect SageMaker Studio Classic Notebooks in un VPC a risorse esterne.
-
I cluster Amazon EMR che esegui devono trovarsi nello stesso Amazon VPC.
-
I cluster Amazon EMR e Amazon VPC devono trovarsi nello stesso account. AWS
-
I tuoi cluster Amazon EMR utilizzano Hive o Presto.
-
I cluster Hive devono consentire il traffico in entrata dai gruppi di sicurezza di Studio Classic sulla porta 10000.
-
I cluster Presto devono consentire il traffico in entrata dai gruppi di sicurezza di Studio Classic sulla porta 8889.
Nota
Il numero di porta è diverso per i cluster Amazon EMR che utilizzano ruoli IAM. Passa alla fine della sezione dei prerequisiti per ulteriori informazioni.
-
-
-
SageMaker Studio Classic
-
Amazon SageMaker Studio Classic deve eseguire Jupyter Lab versione 3. Per informazioni sull'aggiornamento della versione di Jupyter Lab, consulta Visualizza e aggiorna la JupyterLab versione di un'applicazione dalla console.
-
Amazon SageMaker Studio Classic ha un ruolo IAM che controlla l'accesso degli utenti. Il ruolo IAM predefinito che utilizzi per eseguire Amazon SageMaker Studio Classic non prevede policy che possano darti accesso ai cluster Amazon EMR. È necessario collegare la policy di concessione delle autorizzazioni al ruolo IAM. Per ulteriori informazioni, consulta Configurazione della visualizzazione dei cluster Amazon EMR.
-
Il ruolo IAM deve anche disporre della seguente policy collegate
secretsmanager:PutResourcePolicy. -
Se utilizzi un dominio Studio Classic che hai già creato, assicurati che
AppNetworkAccessTypesia in VPC-only modalità. Per informazioni sull'aggiornamento di un dominio alla VPC-only modalità d'uso, consultaChiudi e aggiorna Amazon SageMaker Studio Classic.
-
-
Cluster Amazon EMR
-
Devi avere Hive o Presto installato nel cluster.
-
La versione di Amazon EMR deve essere la 5.5.0 o successiva.
Nota
Amazon EMR supporta la terminazione automatica. La terminazione automatica impedisce ai cluster inattivi di funzionare e ti evita di incorrere in costi. Le seguenti sono le versioni che supportano la terminazione automatica:
-
Per le versioni 6.x, 6.1.0 o successive.
-
Per le versioni 5.x, versione 5.30.0 o successive.
-
-
-
Cluster Amazon EMR che utilizzano ruoli di runtime IAM
-
Utilizza le pagine seguenti per configurare i ruoli di runtime IAM per il cluster Amazon EMR. È necessario abilitare la crittografia in transito quando si utilizzano ruoli di runtime:
-
È necessario Lake Formation come strumento di governance per i dati all'interno dei database. È inoltre necessario utilizzare il filtro esterno dei dati per il controllo degli accessi.
-
Per ulteriori informazioni su Lake Formation, vedi What is AWS Lake Formation?
-
Per ulteriori informazioni sull'integrazione di Lake Formation in Amazon EMR, consulta Integrazione di servizi di terze parti con Lake Formation.
-
-
La versione del tuo cluster deve essere 6.9.0 o successiva.
-
Accesso a AWS Secrets Manager. Per maggiori informazioni su Secrets Manager vedi Cos'è AWS Secrets Manager?
-
I cluster Hive devono consentire il traffico in entrata dai gruppi di sicurezza di Studio Classic sulla porta 10000.
-
Un Amazon VPC è una rete virtuale logicamente isolata dalle altre reti sul cloud. AWS Amazon SageMaker Studio Classic e il tuo cluster Amazon EMR esistono solo all'interno di Amazon VPC.
Utilizza la seguente procedura per avviare Amazon SageMaker Studio Classic in un Amazon VPC.
Per avviare Studio Classic all’interno di un VPC, procedi come segue.
-
Accedi alla console SageMaker AI all'indirizzo https://console.aws.amazon.com/sagemaker/
. -
Scegli Launch SageMaker Studio Classic.
-
Scegli Configurazione standard.
-
In Ruolo di esecuzione predefinito, scegli il ruolo IAM per configurare Studio Classic.
-
Scegli il VPC su cui hai lanciato i cluster Amazon EMR.
-
In Subnet (Sottorete), scegli una sottorete privata.
-
Per i Security group(s) (gruppi di sicurezza) specifica i gruppi di sicurezza che stai utilizzando per il controllo tra i tuoi VPC.
-
Scegli VPC Only (Solo VPC).
-
(Facoltativo) AWS utilizza una chiave di crittografia predefinita. Puoi anche specificare una chiave AWS Key Management Service per crittografare i dati.
-
Scegli Next (Successivo).
-
In Studio settings (Impostazioni Studio), scegli le configurazioni più adatte a te.
-
Scegli Avanti per saltare le impostazioni di SageMaker Canvas.
-
Scegli Next (Avanti) per ignorare le impostazioni di RStudio.
Se non disponi di un cluster Amazon EMR pronto, utilizza la seguente procedura per crearne uno. Per ulteriori informazioni su Amazon EMR consulta Che cos'è Amazon EMR su EKS?
Per creare un cluster, effettua quanto segue:
-
Passare alla AWS Management Console.
-
Nella barra di ricerca, specificare
Amazon EMR. -
Scegli Create cluster (Crea cluster).
-
Per Cluster name (Nome cluster inserisci un nome per il tuo cluster.
-
Per Release, seleziona la versione di rilascio del cluster.
Nota
Amazon EMR supporta la terminazione automatica per le seguenti versioni:
-
Per le versioni 6.x, versioni 6.1.0 o versioni successive
-
Per le versioni 5.x, versioni 5.30.0 o successive
La terminazione automatica impedisce ai cluster inattivi di funzionare e ti evita di incorrere in costi.
-
-
(Facoltativo) Per Applications (Applicazioni), scegli Presto.
-
Scegli l'applicazione che stai eseguendo sul cluster.
-
In Networking (Rete), per Hardware configuration (Configurazione hardware), specifica le impostazioni di configurazione hardware.
Importante
Per il networking, scegli il VPC su cui è in esecuzione Amazon SageMaker Studio Classic e scegli una sottorete privata.
-
In Security and access (Sicurezza e accesso), specifica le impostazioni di sicurezza.
-
Scegli Create (Crea).
Per un tutorial sulla creazione di un cluster Amazon EMR, consulta Nozioni di base su Amazon EMR. Per informazioni sulle best practice per la configurazione di un cluster, consulta Considerazioni e best practice.
Nota
Per quanto riguarda lebest practice di sicurezza, Data Wrangler può connettersi solo ai VPC su sottoreti private. Non puoi connetterti al nodo master a meno che non lo utilizzi AWS Systems Manager per le tue istanze Amazon EMR. Per ulteriori informazioni, vedere Protezione dell'accesso ai cluster EMR utilizzando AWS Systems Manager
Attualmente puoi utilizzare i seguenti metodi per accedere a un cluster Amazon EMR:
-
Nessuna autenticazione
-
Lightweight Directory Access Protocol (LDAP)
-
IAM (ruolo Runtime)
Il mancato utilizzo dell'autenticazione o dell'utilizzo di LDAP può richiedere la creazione di più cluster e profili di istanza Amazon EC2. Se sei un amministratore, potresti dover fornire a gruppi di utenti diversi livelli di accesso ai dati. Questi metodi possono comportare un sovraccarico amministrativo che rende più difficile la gestione degli utenti.
Consigliamo di utilizzare un ruolo di runtime IAM che offra a più utenti la possibilità di connettersi allo stesso cluster Amazon EMR. Un ruolo di runtime è un ruolo IAM che puoi assegnare a un utente che si connette a un cluster Amazon EMR. Puoi configurare il ruolo IAM di runtime in modo che disponga di autorizzazioni specifiche per ogni gruppo di utenti.
Utilizza le seguenti sezioni per creare un cluster Amazon EMR Presto o Hive con LDAP attivato.
Utilizza le seguenti sezioni per utilizzare l'autenticazione LDAP per i cluster Amazon EMR che hai già creato.
Utilizza la procedura seguente per importare i dati da un cluster.
Per importare i dati da un cluster, esegui le operazioni descritte di seguito.
-
Apri un flusso di Data Wrangler.
-
Scegli Crea connessione.
-
Scegli Amazon EMR.
-
Scegli una delle seguenti operazioni.
-
(Facoltativo) Per Secrets ARN, specifica l'Amazon Resource Number (ARN) del database all'interno del cluster. I segreti forniscono una sicurezza aggiuntiva. Per ulteriori informazioni sui segreti, consulta Cos'è AWS Secrets Manager? Per informazioni sulla creazione di un segreto per il tuo cluster, consulta Creare un AWS Secrets Manager segreto per il tuo cluster.
Importante
Se si utilizza un ruolo di runtime IAM per l'autenticazione è necessario specificare un segreto.
-
Dalla tabella a discesa, scegli un cluster.
-
-
Scegli Next (Successivo).
-
Per Seleziona un endpoint per il
example-cluster-namecluster, scegli un motore di query. -
(Facoltativo) Seleziona Save connection (Salva connessione).
-
Scegliere Next, select login (Quindi, seleziona il login) e scegliere uno dei seguenti.
-
Nessuna autenticazione
-
LDAP
-
IAM
-
-
Per Accedi al
example-cluster-namecluster, specifica il nome utente e la password per il cluster. -
Scegli Connetti.
-
Nell'editor di query, specificare una query SQL.
-
Scegli Esegui.
-
Scegli Importa.
Creare un AWS Secrets Manager segreto per il tuo cluster
Se stai usando un ruolo runtime IAM per accedere al tuo cluster Amazon EMR, devi memorizzare le credenziali che usi per accedere ad Amazon EMR come segreto di Secrets Manager. Tutte le credenziali utilizzate per accedere al cluster vengono archiviate all'interno del segreto.
È necessario memorizzare nel segreto le seguenti informazioni:
-
Endpoint JDBC:
jdbc:hive2:// -
Nome DNS: il nome DNS del cluster Amazon EMR. È l'endpoint per il nodo primario o il nome host.
-
Porta:
8446
Puoi anche memorizzare le seguenti informazioni aggiuntive all'interno del segreto:
-
Ruolo IAM: il ruolo IAM che stai utilizzando per accedere al cluster. Data Wrangler utilizza il tuo ruolo di esecuzione SageMaker AI per impostazione predefinita.
-
Percorso truststore: per impostazione predefinita, Data Wrangler crea un percorso truststore per te. Inoltre puoi utilizzare il tuo personale percorso truststore. Per ulteriori informazioni sui percorsi truststore, consulta la sezione In-transit Encryption in 2. HiveServer
-
Password Truststore: per impostazione predefinita, Data Wrangler crea una password truststore per te. Inoltre puoi utilizzare il tuo personale percorso truststore. Per ulteriori informazioni sui percorsi truststore, vedere In-transit encryption in HiveServer 2.
Utilizzare la procedura seguente per memorizzare le credenziali all'interno di un segreto di Secrets Manager.
Per memorizzare le credenziali come segrete, procedi come segue.
-
Passare alla AWS Management Console.
-
Nella barra di ricerca specifica Secrets Manager.
-
Scegli AWS Secrets Manager.
-
Scegli Archivia un nuovo segreto.
-
Per Secret type (Tipo di segreto), scegli Other type of secret (Altro tipo di segreto).
-
In Key/valuecoppie, seleziona Plaintext.
-
Per i cluster che eseguono Hive, puoi utilizzare il seguente modello per l'autenticazione IAM.
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}Nota
Dopo aver importato i dati, si applicano le trasformazioni. Successivamente esporterai i dati trasformati in una posizione specifica. Se utilizzi un notebook Jupyter per esportare i dati trasformati in Amazon S3, devi utilizzare il percorso truststore specificato nell'esempio precedente.
Un segreto di Secrets Manager archivia l'URL JDBC del cluster Amazon EMR come segreto. L'utilizzo di un segreto è più sicuro dell'immissione diretta delle credenziali.
Utilizza la seguente procedura per memorizzare l'URL JDBC come segreto.
Per memorizzare l'URL JDBC come segreto, esegui le operazioni descritte di seguito.
-
Passare alla AWS Management Console.
-
Nella barra di ricerca specifica Secrets Manager.
-
Scegli AWS Secrets Manager.
-
Scegli Archivia un nuovo segreto.
-
Per Secret type (Tipo di segreto), scegli Other type of secret (Altro tipo di segreto).
-
Per Key/value le coppie, specifica
jdbcURLcome chiave e un URL JDBC valido come valore.Il formato di un URL JDBC valido dipende dal fatto che si utilizzi l'autenticazione e che si utilizzi Hive o Presto come motore di query. L'elenco seguente mostra i formati URL JBDC validi per le diverse configurazioni possibili.
-
Hive, nessuna autenticazione –
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive, autenticazione LDAP –
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
Per Hive con SSL abilitato, il formato URL JDBC dipende dall'utilizzo o meno di un file Java Keystore per la configurazione TLS. Il file Java Keystore aiuta a verificare l'identità del nodo principale del cluster Amazon EMR. Per utilizzare un file Java Keystore, generalo su un cluster EMR e caricalo su Data Wrangler. Per generare un file, usa il seguente comando sul cluster Amazon EMR,
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks. Per informazioni sull'esecuzione di comandi su un cluster Amazon EMR, consulta Protezione dell'accesso ai cluster EMR utilizzando AWS Systems Manager. Per caricare un file, seleziona la freccia rivolta verso l'alto nella barra di navigazione a sinistra dell'interfaccia utente di Data Wrangler. I seguenti sono i formati URL JDBC validi per Hive con SSL abilitato:
-
Senza un file Java Keystore:
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
Con un file Keystore Java:
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Presto, nessuna autenticazione — jdbc:presto: //:8889/;
emr-cluster-master-public-dns -
Per Presto con autenticazione LDAP e SSL abilitato, il formato URL JDBC dipende dall'utilizzo o meno di un file Java Keystore per la configurazione TLS. Il file Java Keystore aiuta a verificare l'identità del nodo principale del cluster Amazon EMR. Per utilizzare un file Java Keystore, generalo su un cluster EMR e caricalo su Data Wrangler. Per caricare un file, seleziona la freccia rivolta verso l'alto nella barra di navigazione a sinistra dell'interfaccia utente di Data Wrangler. Per informazioni sulla creazione di un file Java Keystore per Presto, consulta Java Keystore File per TLS.
Per informazioni sull'esecuzione di comandi su un cluster Amazon EMR, consulta Protezione dell'accesso ai cluster EMR utilizzando AWS Systems Manager . -
Senza un file Java Keystore:
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
Con un file Keystore Java:
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
Durante il processo di importazione dei dati da un cluster Amazon EMR, potresti riscontrare problemi. Per informazioni sulla loro risoluzione, consulta Soluzione dei problemi di Amazon EMR.
Importazione di dati da Databricks (JDBC)
Puoi usare Databricks come fonte di dati per il tuo flusso Amazon SageMaker Data Wrangler. Per importare un set di dati da Databricks, utilizza la funzionalità di importazione JDBC (Connettività Java Databricks) per accedere al database Databricks. Dopo aver effettuato l'accesso al database, specifica una query SQL per ottenere i dati e importarli.
Partiamo dal presupposto che tu abbia un cluster Databricks in esecuzione e che abbia configurato il driver JDBC su di esso. Per informazioni, consulta le seguenti pagine di documentazione Databricks:
Data Wrangler memorizza il tuo URL JDBC in. AWS Secrets ManagerÈ necessario concedere le autorizzazioni per il ruolo di esecuzione di Amazon SageMaker Studio Classic IAM per utilizzare Secrets Manager. Utilizza la seguente procedura per concedere le autorizzazioni.
Per concedere le autorizzazioni a Secrets Manager, procedi come segue.
-
Accedi AWS Management Console e apri la console IAM all'indirizzo https://console.aws.amazon.com/iam/
. -
Scegli Ruoli.
-
Nella barra di ricerca, specifica il ruolo di esecuzione di Amazon SageMaker AI utilizzato da Amazon SageMaker Studio Classic.
-
Seleziona il ruolo.
-
Scegli Add Permissions (Aggiungi autorizzazioni).
-
Scegli Create inline policy (Crea policy in linea).
-
Per Service (Servizio), specifica Secrets Manager e sceglilo.
-
Per Azioni, seleziona l'icona a forma di freccia accanto a Gestione delle autorizzazioni.
-
Scegli PutResourcePolicy.
-
In Risorse, scegli Specifiche.
-
Scegli la casella di controllo accanto a Qualsiasi in questo account.
-
Scegli Verifica policy.
-
Per Nome, specificare un nome.
-
Scegli Crea policy.
Puoi utilizzare le partizioni per importare i tuoi dati più velocemente. Le partizioni offrono a Data Wrangler la capacità di elaborare i dati in parallelo. Per impostazione predefinita, Data Wrangler utilizza 2 partizioni. Nella la maggior parte dei casi d'uso, 2 partizioni offrono velocità di elaborazione dei dati quasi ottimali.
Se scegli di specificare più di 2 partizioni, puoi anche specificare una colonna per suddividere i dati. Il tipo di valori nella colonna deve essere un numero o una data.
Ti consigliamo di utilizzare le partizioni solo se conosci la struttura dei dati e il modo in cui vengono elaborati.
Puoi importare l'intero set di dati o campionarne una parte. Per un database Databricks, sono disponibili le seguenti opzioni di campionamento:
-
Nessuno: importa l'intero set di dati.
-
First K: campiona le prime righe K del set di dati, dove K è un numero intero specificato.
-
Randomizzato: preleva un campione a caso della dimensione specificata dall'utente.
-
Stratificato: preleva un campione a caso stratificato. Un campione stratificato mantiene il rapporto dei valori di una colonna.
Utilizza la procedura seguente per importare i dati da un database Databricks.
Per importare i dati da Databricks, esegui le operazioni descritte di seguito.
-
Accedi ad Amazon SageMaker AI Console
. -
Scegli Studio
-
Scegli Launch app.
-
Dall'elenco a discesa, seleziona Studio.
-
Dalla scheda Import data (Importa dati) del flusso Data Wrangler, scegli Databricks.
-
Specificate i seguenti campi:
-
Dataset name (Nome del set di dati): un nome che desideri utilizzare per il set di dati nel flusso di Data Wrangler.
-
Driver: com.simba.spark.jdbc.Driver.
-
URL JDBC: l'URL del database Databricks. La formattazione dell'URL può variare tra le istanze di Databricks. Per informazioni su come trovare l'URL e specificare i parametri al suo interno, consulta Parametri di configurazione e connessione JDBC
. Di seguito è riportato un esempio di come è possibile formattare un URL: jdbc:spark: //aws-sagemaker-datawrangler.cloud.databricks.com:; transportMode=http; ssl=1; httpPath=//0909-200301-cut318; =3; UID=; PWD=. 443/default sql/protocolv1 o/3122619508517275 AuthMech tokenpersonal-access-tokenNota
È possibile specificare un ARN segreto che contenga l'URL JDBC anziché specificare l'URL JDBC stesso. Il segreto deve contenere una coppia chiave-valore con il seguente formato:
jdbcURL:. Per ulteriori informazioni, consulta What is Secrets Manager?JDBC-URL
-
-
Specificare un'istruzione SQL SELECT.
Nota
Data Wrangler non supporta Common Table Expressions (CTE) o tabelle temporanee all'interno di una query.
-
Per Sampling (Campionamento), scegliete un metodo di campionamento.
-
Scegli Esegui.
-
(Facoltativo) Per PREVIEW (ANTEPRIMA), scegli l'ingranaggio per aprire le impostazioni Partition settings (Impostazioni della partizione).
-
Specificare il numero di partizioni. Puoi partizionare per colonna se specifichi il numero di partizioni:
-
Enter number of partitions (Inserisci il numero di partizioni): specifica un valore maggiore di 2.
-
(Facoltativo) Partition by column (Partizione per colonna): specificare i seguenti campi. È possibile eseguire il partizionamento in base a una colonna solo se è stato specificato un valore in Enter number of partitions (Immettere il numero di partizioni).
-
Select column (Seleziona colonna): seleziona la colonna che stai utilizzando per la partizione dati. Il tipo di dati nella colonna deve essere un numero o una data.
-
Upper bound (Limite superiore): dai valori nella colonna che hai specificato, il limite superiore è il valore che stai utilizzando nella partizione. Il valore specificato non modifica i dati che stai importando. Influisce solo sulla velocità di importazione. Per prestazioni ottimali, specifica un limite superiore vicino al massimo della colonna.
-
Lower bound (Limite inferiore): dai valori nella colonna che hai specificato, il limite inferiore è il valore che stai utilizzando nella partizione. Il valore specificato non modifica i dati che stai importando. Influisce solo sulla velocità di importazione. Per prestazioni ottimali, specifica un limite inferiore vicino al minimo della colonna.
-
-
-
-
Scegli Importa.
Importare dati da Salesforce Data Cloud
Puoi utilizzare Salesforce Data Cloud come fonte di dati in Amazon Data Wrangler per preparare SageMaker i dati in Salesforce Data Cloud per l'apprendimento automatico.
Con Salesforce Data Cloud come origine dati in Data Wrangler, puoi connetterti rapidamente ai tuoi dati Salesforce senza scrivere una sola riga di codice. Puoi unire i dati di Salesforce con i dati provenienti da qualsiasi altra origine dati in Data Wrangler.
Dopo aver effettuato la connessione al data cloud, puoi completare le seguenti operazioni:
-
Visualizza i tuoi dati con visualizzazioni integrate
-
Comprendi i dati e identifica potenziali errori e valori estremi
-
Trasforma i dati con più di 300 trasformazioni integrate
-
Esporta i dati che hai trasformato
Configurazione amministratore
Importante
Prima di iniziare, assicurati che i tuoi utenti utilizzino Amazon SageMaker Studio Classic versione 1.3.0 o successiva. Per informazioni su come verificare la versione di Studio Classic e aggiornarla, consulta Prepara i dati ML con Amazon SageMaker Data Wrangler.
Quando si configura l'accesso a Salesforce Data Cloud, è necessario completare le seguenti attività:
-
Ottenere l'URL del dominio Salesforce. Salesforce fa riferimento all'URL del dominio anche come URL dell'organizzazione.
-
Ottenere le credenziali OAuth da Salesforce.
-
Ottenere l'URL di autorizzazione e l'URL del token per il dominio Salesforce.
-
Creazione di un AWS Secrets Manager segreto con la configurazione OAuth.
-
Creazione di una configurazione del ciclo di vita che Data Wrangler utilizza per leggere le credenziali dal segreto.
-
Concedere a Data Wrangler le autorizzazioni per leggere il segreto.
Dopo aver eseguito le attività precedenti, gli utenti possono accedere a Salesforce Data Cloud utilizzando OAuth.
Nota
I tuoi utenti potrebbero riscontrare problemi dopo aver configurato tutto. Per informazioni sulla risoluzione dei problemi, consulta Risoluzione dei problemi di Salesforce.
Utilizza la procedura seguente per ottenere l'URL del dominio.
-
Vai alla pagina di accesso di Salesforce.
-
Per Quick find (Ricerca rapida), specifica My Domain (Il mio dominio).
-
Copia il valore di Current My Domain URL (URL attuale del mio dominio) in un file di testo.
-
Aggiungi
https://all'inizio dell'URL.
Dopo aver ottenuto l'URL del dominio Salesforce, puoi utilizzare la seguente procedura per ottenere le credenziali di accesso da Salesforce e consentire a Data Wrangler di accedere ai tuoi dati Salesforce.
Per ottenere le credenziali di accesso da Salesforce e fornire l'accesso a Data Wrangler, procedi come segue.
-
Vai all'URL del tuo dominio Salesforce e accedi al tuo account.
-
Scegliere l'icona a forma di ingranaggio.
-
Nella barra di ricerca visualizzata, specifica App Manager.
-
Seleziona New Connected App (Nuova app connessa).
-
Specificate i seguenti campi:
-
Nome dell'app connessa: puoi specificare qualsiasi nome, ma ti consigliamo di scegliere un nome che includa Data Wrangler. Ad esempio, puoi specificare Salesforce Data Cloud Data Wrangler Integration.
-
Nome API: utilizza il valore predefinito.
-
Email di contatto: specifica il tuo indirizzo e-mail.
-
Nella API heading (Enable OAuth Settings) (Intestazione API (Attiva impostazioni OAuth)), seleziona la casella di controllo per attivare le impostazioni OAuth.
-
Per URL di callback, specifica l'URL di Amazon SageMaker Studio Classic. Per ottenere l'URL di Studio Classic, accedi da AWS Management Console e copia l'URL.
-
-
In Selected OAuth Scopes (Ambiti OAuth selezionati), sposta quanto segue da Available OAuth Scopes (Ambiti OAuth disponibili) a Selected OAuth Scopes:
-
Gestisci i dati degli utenti tramite API (
api) -
Esegui le richieste in qualsiasi momento (
refresh_token,offline_access) -
Esegui query ANSI SQL sui dati di Salesforce Data Cloud (
cdp_query_api) -
Gestisci i dati del profilo di Salesforce Customer Data Platform (
cdp_profile_api)
-
-
Scegli Save (Salva). Dopo aver salvato le modifiche, Salesforce apre una nuova pagina.
-
Scegli Continue (Continua)
-
Vai a Consumer Key and Secret (Chiave e segreto del consumatore).
-
Scegli Manage Consumer Details (Gestisci i dettagli del consumatore). Salesforce ti reindirizza a una nuova pagina in cui potresti dover passare l'autenticazione a due fattori.
-
Importante
Copia la Chiave consumatore e il Segreto consumatore in un editor di testo. Queste informazioni sono necessarie per connettere il data cloud a Data Wrangler.
-
Torna a Manage Connected Apps (Gestisci app connesse).
-
Vai Connected App Name (Nome app connessa) e al nome della tua applicazione.
-
Scegli Gestisci.
-
Seleziona Edit Policies (Modifica policy).
-
Cambia IP Relaxation in Relax IP restrictions.
-
Scegli Save (Salva).
-
Dopo aver fornito l'accesso a Salesforce Data Cloud, devi fornire le autorizzazioni agli utenti. Utilizza la seguente procedura per concedere le autorizzazioni.
Per fornire ai tuoi utenti le autorizzazioni, procedi come segue.
-
Vai alla pagina iniziale del setup.
-
Nella barra di navigazione a sinistra, cerca Users (Utenti) e scegli la voce di menu Users.
-
Scegli il collegamento ipertestuale con il tuo nome utente.
-
Vai a Permission Set Assignments (Assegnazioni dei set di autorizzazioni).
-
Scegli Edit Assignments (Modifica assegnazioni).
-
Aggiungi le autorizzazioni seguenti:
-
Customer Data Platform Admin (Amministratore della piattaforma dati dei clienti)
-
Customer Data Platform Data Aware Specialist
-
-
Scegli Save (Salva).
Dopo aver ottenuto le informazioni per il dominio Salesforce, devi ottenere l'URL di autorizzazione e l'URL del token per il AWS Secrets Manager segreto che stai creando.
Utilizza la procedura seguente per ottenere l'URL di autorizzazione e l'URL del token.
Per ottenere l'URL di autorizzazione e l'URL del token
-
Accedi all'URL del tuo dominio Salesforce.
-
Utilizza uno dei seguenti metodi per ottenere gli URL. Se utilizzi una distribuzione Linux con
curled èjqinstallata, ti consigliamo di utilizzare il metodo che funziona solo su Linux.-
(Solo Linux) Specifica il seguente comando nel terminale.
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
Accedi a
example-org-URL/.well-known/openid-configuration -
Copia
authorization_endpointetoken_endpointin un editor di testo. -
Crea il seguente oggetto JSON:
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
Dopo aver creato l'oggetto di configurazione OAuth, puoi creare un AWS Secrets Manager segreto che lo memorizzi. Per creare il segreto, utilizzare la procedura seguente.
Per creare un segreto, procedere come descritto qui di seguito:
-
Passare alla console AWS Secrets Manager
. -
Scegliere Store a secret (Archivia un nuovo segreto).
-
Selezionare Other type of secret (Altro tipo di segreti).
-
In Key/valuecoppie seleziona Plaintext.
-
Sostituisci il JSON vuoto con le seguenti impostazioni di configurazione.
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
Scegli Next (Successivo).
-
Per Secret Name (Nome segreto), specifica il nome del segreto.
-
In Tag seleziona Add (Aggiungi).
-
Per Key (Chiave), specifica sagemaker:partner. Per Value, ti consigliamo di specificare un valore che potrebbe essere utile per il tuo caso d'uso. Tuttavia, puoi specificare qualsiasi valore.
Importante
È necessario creare la chiave. Non puoi importare i tuoi dati da Salesforce se non li crei.
-
-
Scegli Next (Successivo).
-
Scegli Store.
-
Scegli il segreto creato.
-
Prendi nota dei seguenti campi:
-
L'Amazon Resource Number (ARN) del segreto .
-
Il nome del segreto.
-
Dopo aver creato il segreto, devi aggiungere le autorizzazioni affinché Data Wrangler possa leggere il segreto. Utilizza la seguente procedura per aggiungere le autorizzazioni.
Per aggiungere le autorizzazioni di lettura per Data Wrangler, esegui queste operazioni.
-
Accedi alla console Amazon SageMaker AI
. -
Scegli Domini.
-
Scegli il dominio che stai utilizzando per accedere a Data Wrangler.
-
Scegli il tuo User Profile (Profilo utente).
-
In Details (Dettagli), trova il Execution role (Ruolo di esecuzione). Il suo ARN presenta il formato seguente:
arn:aws:iam::111122223333:role/. Prendi nota del ruolo di esecuzione dell' SageMaker IA. All'interno dell'ARN, è tutto ciò che segueexample-rolerole/. -
Passare alla IAM console
(Console IAM). -
Nella barra di ricerca Search IAM, specifica il nome del ruolo di esecuzione SageMaker AI.
-
Seleziona il ruolo.
-
Scegli Add Permissions (Aggiungi autorizzazioni).
-
Scegli Create inline policy (Crea policy in linea).
-
Scegli la scheda JSON.
-
Specifica la seguente politica all'interno dell'editor.
-
Scegli Esamina la policy.
-
Per Nome, specificare un nome.
-
Scegli Crea policy.
Dopo aver concesso a Data Wrangler le autorizzazioni per leggere il segreto, devi aggiungere una configurazione del ciclo di vita che utilizzi il tuo segreto Secrets Manager al tuo profilo utente Amazon SageMaker Studio Classic.
Utilizza la procedura seguente per creare una configurazione del ciclo di vita e aggiungerla al profilo Studio Classic.
Per creare una configurazione del ciclo di vita e aggiungerla al profilo Studio Classic, procedi come segue.
-
Accedi alla console Amazon SageMaker AI.
-
Scegli Domini.
-
Scegli il dominio che stai utilizzando per accedere a Data Wrangler.
-
Scegli il tuo User Profile (Profilo utente).
-
Se vedi le seguenti applicazioni, eliminale:
-
KernelGateway
-
JupyterKernel
Nota
L’eliminazione delle applicazioni comporta l’aggiornamento di Studio Classic. L'esecuzione degli aggiornamenti può richiedere alcuni istanti.
-
-
In attesa degli aggiornamenti, scegli Lifecycle configurations(Configurazioni del ciclo di vita).
-
Assicurati che la pagina in cui ti trovi visualizzi Configurazioni del ciclo di vita di Studio Classic.
-
Scegli Crea configurazione.
-
Assicurati che Jupyter server app sia stata selezionata.
-
Scegli Next (Successivo).
-
In Name (Nome), specifica un nome per la configurazione.
-
Per Scripts, specificate il seguente script:
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
Seleziona Invia.
-
Nel riquadro di navigazione a sinistra, scegli Domini.
-
Scegli il tuo dominio.
-
Scegliere Environment (Ambiente).
-
In Configurazioni del ciclo di vita per le app personali di Studio Classic, scegli Collega.
-
Seleziona Existing configuration (Configurazione esistente).
-
In Configurazioni del ciclo di vita di Studio Classic, seleziona la configurazione del ciclo di vita che hai creato.
-
Choose Attach to domain (Collega al dominio).
-
Seleziona la casella di controllo accanto alla configurazione del ciclo di vita che hai collegato.
-
Seleziona Set as default (Imposta come predefinito).
È possibile che si verifichino problemi durante l'adattamento della configurazione del ciclo di vita. Per informazioni su come eseguirne il debug, consulta Configurazioni del ciclo di vita di debug in Amazon Studio Classic SageMaker
Guida per Data Scientist
Utilizza quanto segue per connettere Salesforce Data Cloud e accedere ai tuoi dati in Data Wrangler.
Importante
L'amministratore deve utilizzare le informazioni nelle sezioni precedenti per configurare Salesforce Data Cloud. Se riscontri problemi, contattali per ricevere assistenza sulla risoluzione dei problemi.
Per aprire Studio Classic e verificarne la versione, consulta la procedura seguente.
-
Segui i passaggi Prerequisiti per accedere a Data Wrangler tramite Amazon SageMaker Studio Classic.
-
Accanto all’utente che intendi utilizzare per avviare Studio Classic, seleziona Avvia applicazione.
-
Scegli Studio
Per creare un set di dati in Data Wrangler con dati provenienti da Salesforce Data Cloud
-
Accedi ad Amazon SageMaker AI Console
. -
Scegli Studio
-
Scegli Launch app.
-
Dall'elenco a discesa, seleziona Studio.
-
Scegli l'icona Home.
-
Selezionare Data (Dati).
-
Scegli Data Wrangler.
-
Scegli Import data (Importa dati).
-
In Available (Disponibile), scegli Salesforce Data Cloud.
-
Per Connection name (Nome connessione), specifica un nome per la connessione a Salesforce Data Cloud.
-
Per Org URL, specifica l'URL dell'organizzazione nel tuo account Salesforce. Puoi ottenere l'URL dai tuoi amministratori.
-
Scegli Connetti.
-
Specifica le tue credenziali per accedere a Salesforce.
Puoi iniziare a creare un set di dati utilizzando i dati di Salesforce Data Cloud dopo esserti connesso ad esso.
Dopo aver selezionato una tabella, è possibile scrivere query ed eseguirle. L'output della query viene visualizzato in Query results (Risultati della query).
Dopo aver stabilito l'output della query, è possibile importare l'output della query in un flusso di Data Wrangler per eseguire trasformazioni dei dati.
Dopo aver creato un set di dati, vai alla schermata Data flow per iniziare a trasformare i tuoi dati
Importazione di dati da Snowflake
Puoi usare Snowflake come fonte di dati in Data Wrangler per preparare SageMaker i dati in Snowflake per l'apprendimento automatico.
Con Snowflake come origine dati in Data Wrangler, puoi connetterti rapidamente a Snowflake senza scrivere una sola riga di codice. Puoi unire i tuoi dati in Snowflake con i dati provenienti da qualsiasi altra origine dati in Data Wrangler.
Una volta connesso, puoi eseguire query in modo interattivo sui dati archiviati in Snowflake, trasformarli con più di 300 trasformazioni di dati preconfigurati, comprendere i dati e identificare potenziali errori e valori estremi con un set di robusti modelli di visualizzazione preconfigurati, identificare rapidamente le incongruenze nel flusso di lavoro di preparazione dei dati e diagnosticare i problemi prima che i modelli vengano implementati in produzione. Infine, puoi esportare il flusso di lavoro di preparazione dei dati su Amazon S3 per utilizzarlo con altre funzionalità di SageMaker intelligenza artificiale come Amazon SageMaker Autopilot, Amazon SageMaker Feature Store e Amazon Pipelines. SageMaker
Puoi crittografare l'output delle tue query utilizzando una chiave che hai creato. AWS Key Management Service Per ulteriori informazioni su AWS KMS, consulta. AWS Key Management Service
Guida per l'amministratore
Importante
Per ulteriori informazioni sul controllo granulare degli accessi e sulle migliori pratiche, consulta Controllo degli accessi di sicurezza
Questa sezione è dedicata agli amministratori di Snowflake che stanno configurando l'accesso a Snowflake da Data Wrangler. SageMaker
Importante
L'utente è responsabile della gestione e del monitoraggio del controllo degli accessi all'interno di Snowflake. Data Wrangler non aggiunge un livello di controllo degli accessi rispetto a Snowflake.
Il controllo degli accessi include quanto segue:
-
I dati a cui un utente accede
-
(Facoltativo) L'integrazione di storage che offre a Snowflake la possibilità di scrivere risultati di query in un bucket Amazon S3
-
Le interrogazioni che un utente può eseguire
(Facoltativo) Configura le autorizzazioni di importazione dei dati Snowflake
Per impostazione predefinita, Data Wrangler interroga i dati in Snowflake senza crearne una copia in una posizione Amazon S3. Utilizza le seguenti informazioni se stai configurando un'integrazione di storage con Snowflake. I tuoi utenti possono utilizzare un'integrazione di storage per archiviare i risultati delle query in una posizione Amazon S3.
I tuoi utenti potrebbero avere diversi livelli di accesso ai dati sensibili. Per una sicurezza ottimale dei dati, fornisci a ogni utente la propria integrazione di archiviazione. Ogni integrazione di storage dovrebbe avere una propria policy di governance dei dati.
Questa funzionalità non è al momento disponibile nelle Regioni opt-in.
Snowflake richiede le seguenti autorizzazioni su un bucket e una directory S3 per poter accedere ai file nella directory:
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
Creare una policy IAM
Devi creare una policy IAM per configurare le autorizzazioni di accesso affinché Snowflake possa caricare e scaricare dati da un bucket Amazon S3.
Di seguito è riportato il documento di policy JSON che utilizzi per creare la policy:
# Example policy for S3 write access # This needs to be updated { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::bucket/prefix/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::bucket/", "Condition": { "StringLike": { "s3:prefix": ["prefix/*"] } } } ] }
Per informazioni e procedure sulla creazione di policy con documenti relativi alle policy, consulta Creazione di policy IAM.
Per la documentazione che fornisce una panoramica sull'utilizzo delle autorizzazioni IAM con Snowflake, consulta le seguenti risorse:
Per concedere al data scientist l'autorizzazione all'utilizzo del ruolo Snowflake per l'integrazione dello storage, devi eseguire GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role;.
-
integration_nameè il nome dell'integrazione dello storage. -
snowflake_roleè il nome del Snowflake role(Ruolo Snowflake) predefinito assegnato all'utente data scientist.
Configurazione dell'accesso Snowflake OAuth
Invece di chiedere agli utenti di inserire direttamente le loro credenziali in Data Wrangler, puoi fare in modo che utilizzino un provider di identità per accedere a Snowflake. Di seguito sono riportati i collegamenti alla documentazione Snowflake per i provider di identità supportati da Data Wrangler.
Utilizza la documentazione dei link precedenti per configurare l'accesso al tuo provider di identità. Le informazioni e le procedure in questa sezione aiutano a capire come utilizzare correttamente la documentazione per accedere a Snowflake all'interno di Data Wrangler.
Il tuo provider di identità deve riconoscere Data Wrangler come applicazione. Utilizzare la procedura seguente per registrare Data Wrangler come applicazione all'interno del provider di identità:
-
Seleziona la configurazione che avvia il processo di registrazione di Data Wrangler come applicazione.
-
Fornisci agli utenti del provider di identità l'accesso a Data Wrangler.
-
Attiva l'autenticazione del client OAuth memorizzando le credenziali del client come segreto. AWS Secrets Manager
-
Specificate un URL di reindirizzamento utilizzando il seguente formato: https://.studio.
domain-IDRegione AWS.sagemaker. aws/jupyter/default/labImportante
Stai specificando l'ID del dominio Amazon SageMaker AI e Regione AWS quello che stai utilizzando per eseguire Data Wrangler.
Importante
Devi registrare un URL per ogni dominio Amazon SageMaker AI e Regione AWS dove esegui Data Wrangler. Gli utenti di un dominio Regione AWS che non dispongono di URL di reindirizzamento configurati per loro non potranno autenticarsi con il provider di identità per accedere alla connessione Snowflake.
-
Assicurati che il codice di autorizzazione e i tipi di concessione del token di aggiornamento siano consentiti per l'applicazione Data Wrangler.
All'interno del tuo provider di identità, devi configurare un server che invii token OAuth a Data Wrangler a livello di utente. Il server invia i token con Snowflake come destinatario.
Snowflake utilizza il concetto di ruoli distinti in cui vengono utilizzati i ruoli IAM. AWSÈ necessario configurare il provider di identità per utilizzare qualsiasi ruolo e utilizzare il ruolo predefinito associato all'account Snowflake. Ad esempio, se un utente ha systems administrator come ruolo predefinito nel proprio profilo Snowflake, la connessione da Data Wrangler a Snowflake utilizza systems administrator come ruolo.
Completa la procedura seguente per configurare il server.
Per configurare il server, procedere nel seguente modo: Stai lavorando all'interno di Snowflake per tutte le fasi tranne l'ultima.
-
Inizia a configurare il server o l'API.
-
Configura il server di autorizzazione per utilizzare il codice di autorizzazione e aggiornare i tipi di concessione del token.
-
Specifica la durata del token di accesso.
-
Imposta il timeout di inattività del token di aggiornamento. Il timeout di inattività è periodo di tempo in cui il token di aggiornamento scade se non viene utilizzato.
Nota
Se stai pianificando processi in Data Wrangler, ti consigliamo di impostare il tempo di timeout di inattività maggiore della frequenza del processo di elaborazione. In caso contrario, alcuni processi di elaborazione potrebbero non riuscire perché il token di aggiornamento scadrà prima che possano essere eseguiti. Quando il token di aggiornamento scade, l'utente deve autenticarsi nuovamente accedendo alla connessione che ha stabilito per Snowflake tramite Data Wrangler.
-
Specificare come nuovo ambito
session:role-any.Nota
Per Azure AD, copia l'identificatore univoco per l'ambito. Data Wrangler richiede di fornirgli l'identificatore.
-
Importante
All'interno dell'integrazione di sicurezza OAuth esterna per Snowflake, abilita
external_oauth_any_role_mode.
Importante
Data Wrangler non supporta i token di aggiornamento a rotazione. L'utilizzo di token di aggiornamento a rotazione.potrebbe causare errori di accesso o la necessità di accedere frequentemente agli utenti.
Importante
Se il token di aggiornamento scade, gli utenti devono autenticarsi nuovamente accedere alla connessione che hanno stabilito per Snowflake tramite Data Wrangler.
Dopo aver configurato il provider OAuth, fornisci a Data Wrangler le informazioni necessarie per connettersi al provider. Puoi utilizzare la documentazione del tuo provider di identità per ottenere i valori per i seguenti campi:
-
Token URL: l'URL del token che il provider di identità invia a Data Wrangler.
-
Authorization URL: l'URL del server di autorizzazione del provider di identità.
-
ID client: l'ID del provider di identità.
-
Client secret: il segreto riconosciuto solo dal server di autorizzazione o dall'API.
-
(Solo Azure AD) Le credenziali dell'ambito OAuth che hai copiato.
Archivia i campi e i valori in modo AWS Secrets Manager segreto e li aggiungi alla configurazione del ciclo di vita di Amazon SageMaker Studio Classic che stai utilizzando per Data Wrangler. Una configurazione del ciclo di vita è uno script di shell. Utilizzala per rendere accessibile a Data Wrangler il nome della risorsa Amazon (ARN) del segreto. Per informazioni sulla creazione di segreti, consulta Move i segreti hardcoded to. AWS Secrets Manager Per informazioni sull’utilizzo delle configurazioni del ciclo di vita in Studio Classic, consulta Usa le configurazioni del ciclo di vita per personalizzare Amazon Studio Classic SageMaker.
Importante
Prima di creare un segreto di Secrets Manager, assicurati che il ruolo di esecuzione SageMaker AI che stai utilizzando per Amazon SageMaker Studio Classic disponga delle autorizzazioni per creare e aggiornare segreti in Secrets Manager. Per ulteriori informazioni sull'aggiunta di autorizzazioni, consulta la sezione Esempio: autorizzazione alla creazione di segreti.
Per Okta e Ping Federate, il formato del segreto è il seguente:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"OKTA"|"PING_FEDERATE", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize" }
Per Azure AD, il formato del segreto è il seguente:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"AZURE_AD", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize", "datasource_oauth_scope":"api://appuri/session:role-any)" }
È necessario disporre di una configurazione del ciclo di vita che utilizzi il segreto di Secrets Manager che hai creato. È possibile creare la configurazione del ciclo di vita o modificarne una già creata. La configurazione deve utilizzare lo script seguente.
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
Per informazioni sulla configurazione del ciclo di vita, consulta Crea e associa una configurazione del ciclo di vita con Amazon Studio Classic SageMaker. Durante il processo di configurazione, esegui queste operazioni:
-
Imposta il tipo di applicazione della configurazione su
Jupyter Server. -
Collega la configurazione al dominio Amazon SageMaker AI che contiene i tuoi utenti.
-
Fai eseguire la configurazione per impostazione predefinita. Deve essere eseguita ogni volta che un utente accede a Studio Classic. In caso contrario, le credenziali salvate nella configurazione non saranno disponibili agli utenti quando utilizzano Data Wrangler.
-
La configurazione del ciclo di vita crea un file con il nome
snowflake_identity_provider_oauth_confignella cartella home dell'utente. Il file contiene il segreto di Secrets Manager. Assicurati che si trovi nella cartella home dell'utente ogni volta che viene inizializzata l'istanza del server Jupyter.
Connettività privata tra Data Wrangler e Snowflake tramite AWS PrivateLink
Questa sezione spiega come utilizzare per AWS PrivateLink stabilire una connessione privata tra Data Wrangler e Snowflake. Le diverse fasi vengono spiegate nelle sezioni seguenti.
Crea un VPC
Se non disponi di un VPC configurato, segui le istruzioni Crea un nuovo VPC per crearne uno.
Una volta scelto il VPC che desideri utilizzare per stabilire una connessione privata, fornisci le seguenti credenziali all'amministratore Snowflake per abilitare AWS PrivateLink:
-
ID VPC
-
AWS ID dell'account
-
L'URL dell'account corrispondente che utilizzi per accedere a Snowflake
Importante
Come descritto nella documentazione di Snowflake, l'attivazione dell'account Snowflake può richiedere fino a due giorni lavorativi.
Configura Snowflake AWS PrivateLink Integrazione
Dopo AWS PrivateLink l'attivazione, recupera la AWS PrivateLink configurazione per la tua regione eseguendo il seguente comando in un foglio di lavoro Snowflake. Accedi alla console Snowflake e inserisci quanto segue in Worksheets (Fogli di lavoro): select
SYSTEM$GET_PRIVATELINK_CONFIG();
-
Recupera i valori per quanto segue:
privatelink-account-name,privatelink_ocsp-url,privatelink-account-url, eprivatelink_ocsp-urldall'oggetto JSON risultante. Gli esempi di ogni valore sono mostrati nel frammento seguente. Memorizza questi valori per un uso successivo.privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
Passa alla AWS console e vai al menu VPC.
-
Dal pannello laterale sinistro, scegli il link Endpoints per accedere alla configurazione degli Endpoint VPC.
Una volta lì, scegli Create Endpoint (Crea endpoint).
-
Seleziona il pulsante di opzione Find service by name (Trova servizio per nome), come mostrato nello screenshot seguente.
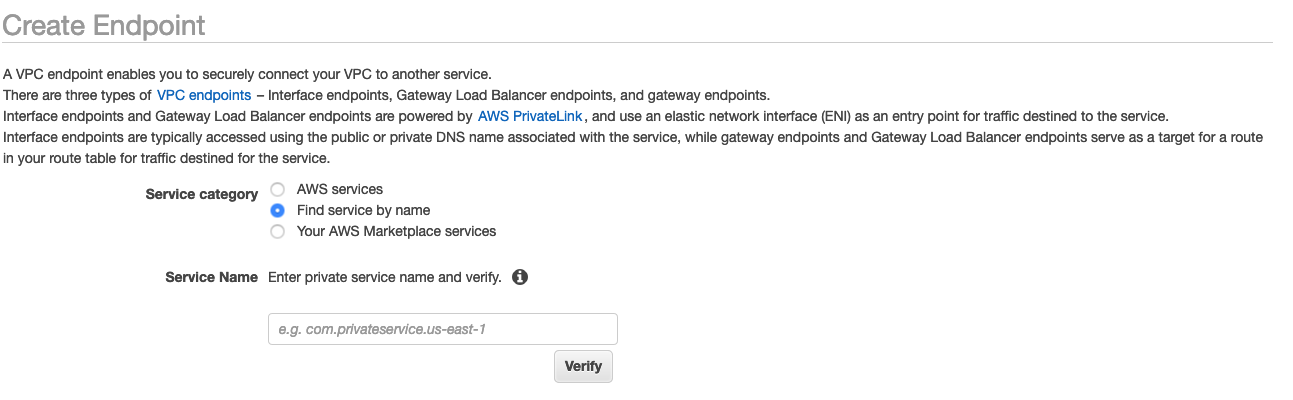
-
Nel campo Nome del servizio, incolla il valore
privatelink-vpce-idrecuperato nella fase precedente e scegli Verifica.Se la connessione è riuscita, sullo schermo viene visualizzato un avviso verde che indica il Service name found (Nome del servizio trovato) e le opzioni VPC e Subnet (sottorete) si espandono automaticamente, come mostrato nella schermata seguente. A seconda della Regione selezionata, la schermata risultante potrebbe mostrare il nome di un'altra Regione AWS .
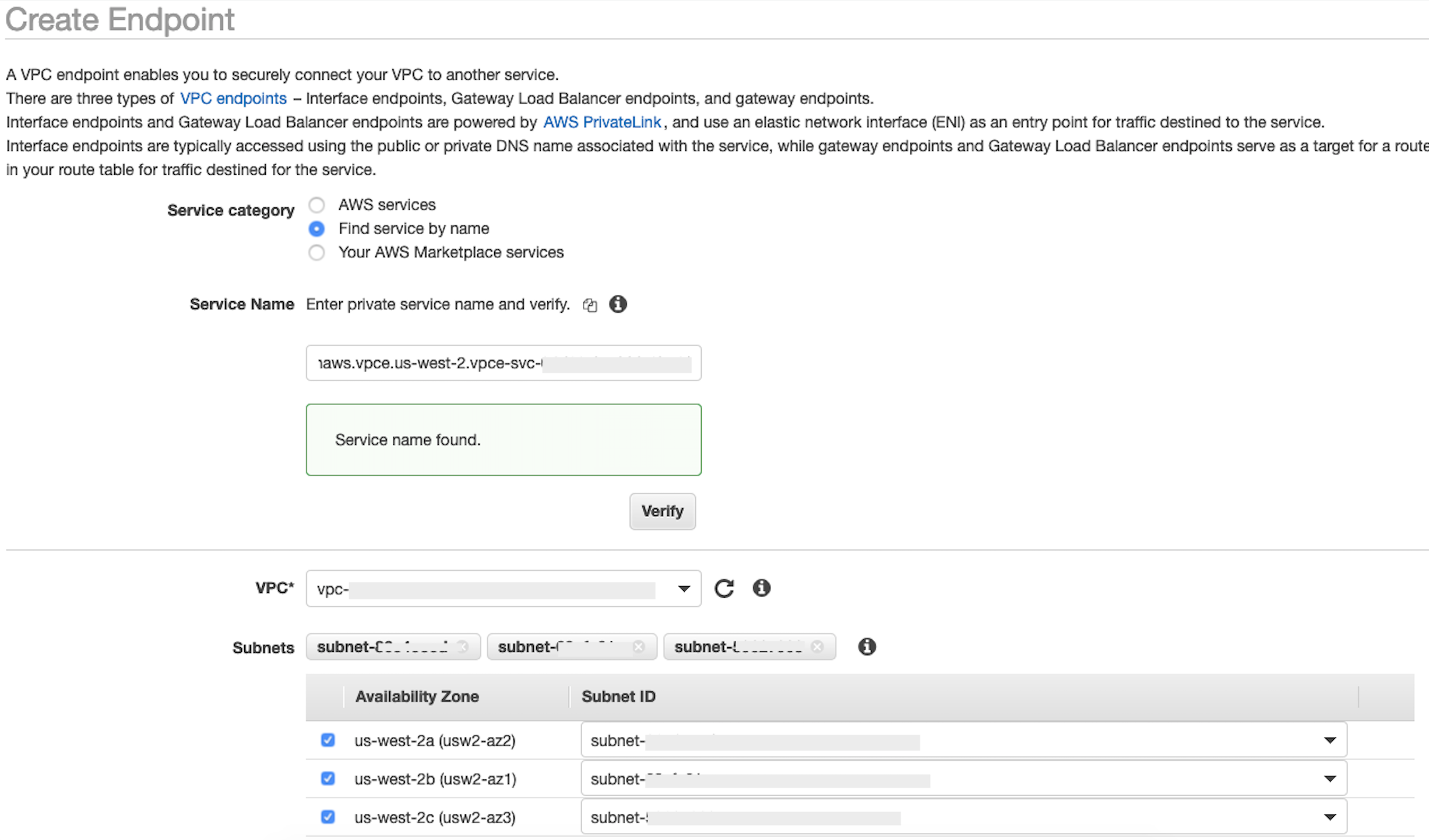
-
Seleziona lo stesso ID VPC che hai inviato a Snowflake dall'elenco a discesa VPC.
-
Se non hai ancora creato una sottorete, esegui la seguente serie di istruzioni sulla creazione di una sottorete.
-
Seleziona Subnet (Sottorete) dall'elenco a discesa VPC. Quindi seleziona Create subnet (Crea sottorete) e segui le istruzioni per creare un sottoinsieme nel tuo VPC. Assicurati di selezionare l'ID VPC che hai inviato a Snowflake.
-
In Security Group Configuration (Configurazione del gruppo di sicurezza), seleziona Create New Security Group (Crea nuovo gruppo di sicurezza) per aprire la schermata predefinita del Security Group (Gruppo di sicurezza) in una nuova scheda. In questa nuova scheda, seleziona Create Security Group (Crea gruppo di sicurezza).
-
Fornisci un nome per il nuovo gruppo di sicurezza (ad esempio
datawrangler-doc-snowflake-privatelink-connection) e una descrizione. Assicurati di selezionare l'ID VPC che hai usato nelle fasi precedenti. -
Aggiungi due regole per consentire il traffico dall'interno del tuo VPC a questo endpoint VPC.
Accedi al tuo VPC nella sezione Your VPCs (I tuoi VPC) in una scheda separata e recupera il blocco CIDR per il tuo VPC. Poi scegli Add Rule (Aggiungi regola) nella sezione Inbound Rules (Regole in entrata). Seleziona
HTTPSper il tipo, lascia Source (Origine) come Custom (Personalizzata) nel modulo e incolla il valore recuperato dalla chiamata precedentedescribe-vpcs(ad esempio10.0.0.0/16). -
Scegli Crea gruppo di sicurezza. Recupera ilSecurity Group ID (ID del gruppo di sicurezza) dal gruppo di sicurezza appena creato (ad esempio
sg-xxxxxxxxxxxxxxxxx). -
Nella schermata di configurazione VPC Endpoint (Endpoint VPC), rimuovi il gruppo di sicurezza predefinito. Incolla l'ID del gruppo di sicurezza nel campo di ricerca e seleziona la casella di controllo.
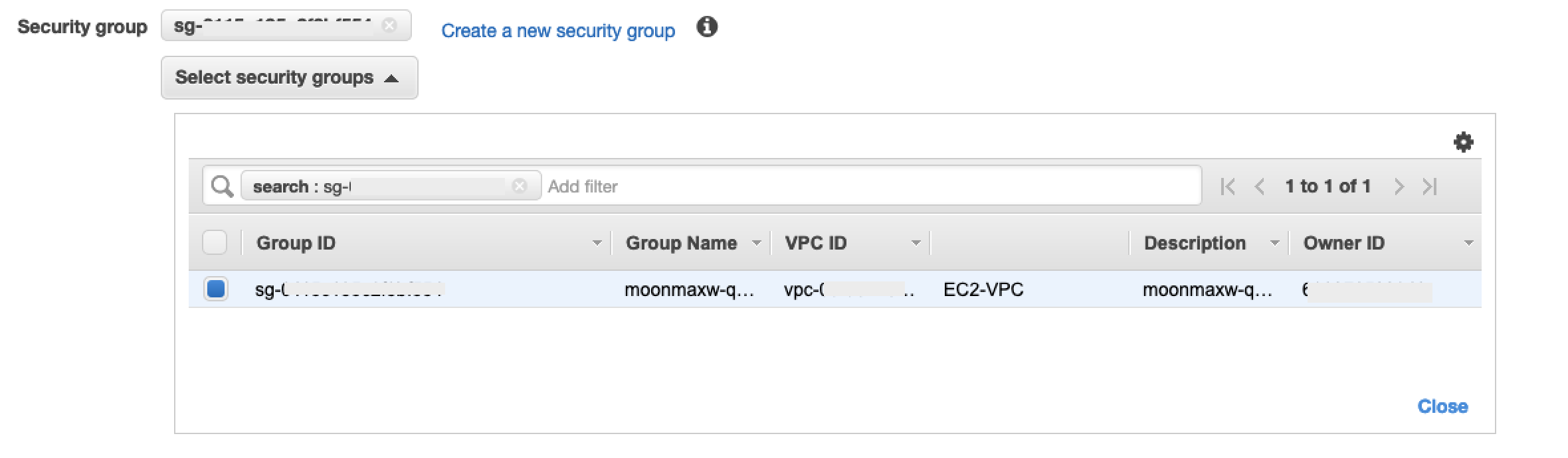
-
Seleziona Create endpoint (Crea endpoint).
-
Se la creazione dell'endpoint ha esito positivo, viene visualizzata una pagina contenente un collegamento alla configurazione dell'endpoint VPC, specificata dall'ID VPC. Seleziona il link per visualizzare la configurazione completa.

Recupera il record più in alto nell'elenco dei nomi DNS. Questo può essere differenziato dagli altri nomi DNS perché include solo il nome della Regione (ad esempio
us-west-2) e nessuna notazione in lettere della zona di disponibilità (comeus-west-2a). Archivia queste informazioni per un uso successivo.
Configura DNS per gli endpoint Snowflake nel tuo VPC
In questa sezione viene descritto come configurare DNS per gli endpoint Snowflake nel VPC. Ciò consente al tuo VPC di risolvere le richieste all'endpoint AWS PrivateLink Snowflake.
-
Vai al menu Route 53
all'interno della tua AWS console. -
Seleziona l'opzione Hosted Zones (Zona ospitata) (se necessario, espandi il menu a sinistra per trovare questa opzione).
-
Scegli Create Hosted Zone (Crea zona ospitata).
-
Nel campo Domain name (Nome dominio), fai riferimento al valore memorizzato per
privatelink-account-urlnelle fasi precedenti. In questo campo, l'ID dell'account Snowflake viene rimosso dal nome DNS e utilizza solo il valore che inizia con l'identificatore della Regione. Successivamente viene creato anche un Resource Record Set (Set di registri delle risorse) per il sottodominio, ad esempioregion.privatelink.snowflakecomputing.com. -
Seleziona il pulsante di opzione per Private Hosted Zone (Zona ospitata privata) nella sezione Type (Tipo). Il tuo codice regionale potrebbe non essere
us-west-2. Fai riferimento al nome DNS che ti è stato restituito da Snowflake.
-
Nella sezione VPCs to associate with the hosted zone (VPC da associare alla zona ospitata), seleziona la Regione in cui si trova il tuo VPC e l'ID VPC utilizzato nelle fasi precedenti.
-
Scegli Crea zona ospitata.
-
-
Quindi, crea due record, uno per
privatelink-account-urle uno altro perprivatelink_ocsp-url-
Nel menu Hosted Zone, scegli Create Record Set (Crea set di record).
-
In Record name (Nome del record), inserisci solo l'ID del tuo account Snowflake (i primi 8 caratteri in
privatelink-account-url) -
In Record type (Tipo di record), seleziona CNAME.
-
In Valore, inserisci il nome DNS per l'endpoint VPC regionale recuperato nell'ultima fase della sezione Configurazione dell’integrazione AWS PrivateLink di Snowflake.
-
Scegli Crea record.
-
Ripeti le fasi precedenti per il record OCSP con cui abbiamo annotato come
privatelink-ocsp-url, iniziando conocspfino all'ID Snowflake di 8 caratteri per il nome del record (Comeocsp.xxxxxxxx).
-
-
Configurare endpoint in entrata del resolver Route 53 del VPC
Questa sezione spiega come configurare gli endpoint in entrata dei resolver Route 53 del VPC.
-
Vai al menu Route 53
all'interno della tua AWS console. -
Nel pannello a sinistra della sezione Security (Sicurezza), seleziona l'opzione Security Groups (Gruppi di sicurezza).
-
-
Scegli Crea gruppo di sicurezza.
-
Fornisci un nome per il tuo gruppo di sicurezza (ad esempio
datawranger-doc-route53-resolver-sg) e una descrizione. -
Seleziona l'ID VPC utilizzato nelle fasi precedenti.
-
Crea regole che consentano il DNS su UDP e TCP dall'interno del blocco VPC CIDR.

-
Scegli Crea gruppo di sicurezza. Prendi nota del Security Group ID perché aggiunge una regola per consentire il traffico verso il gruppo di sicurezza degli endpoint VPC.
-
-
Vai al menu Route 53
all'interno della tua AWS console. -
Nella sezione Resolver, seleziona l'opzione Inbound Endpoint (Endpoint in entrata).
-
-
Scegli Create inbound endpoint (Crea endpoint in entrata).
-
Fornire un nome endpoint.
-
Dall'elenco a discesa VPC in the Region (VPC nella Regione), seleziona l'ID VPC che hai utilizzato in tutte le fasi precedenti.
-
Nell'elenco a discesa Security group for this endpoint (Gruppo di sicurezza per questo endpoint), seleziona l'ID del gruppo di sicurezza dalla fase 2 di questa sezione.
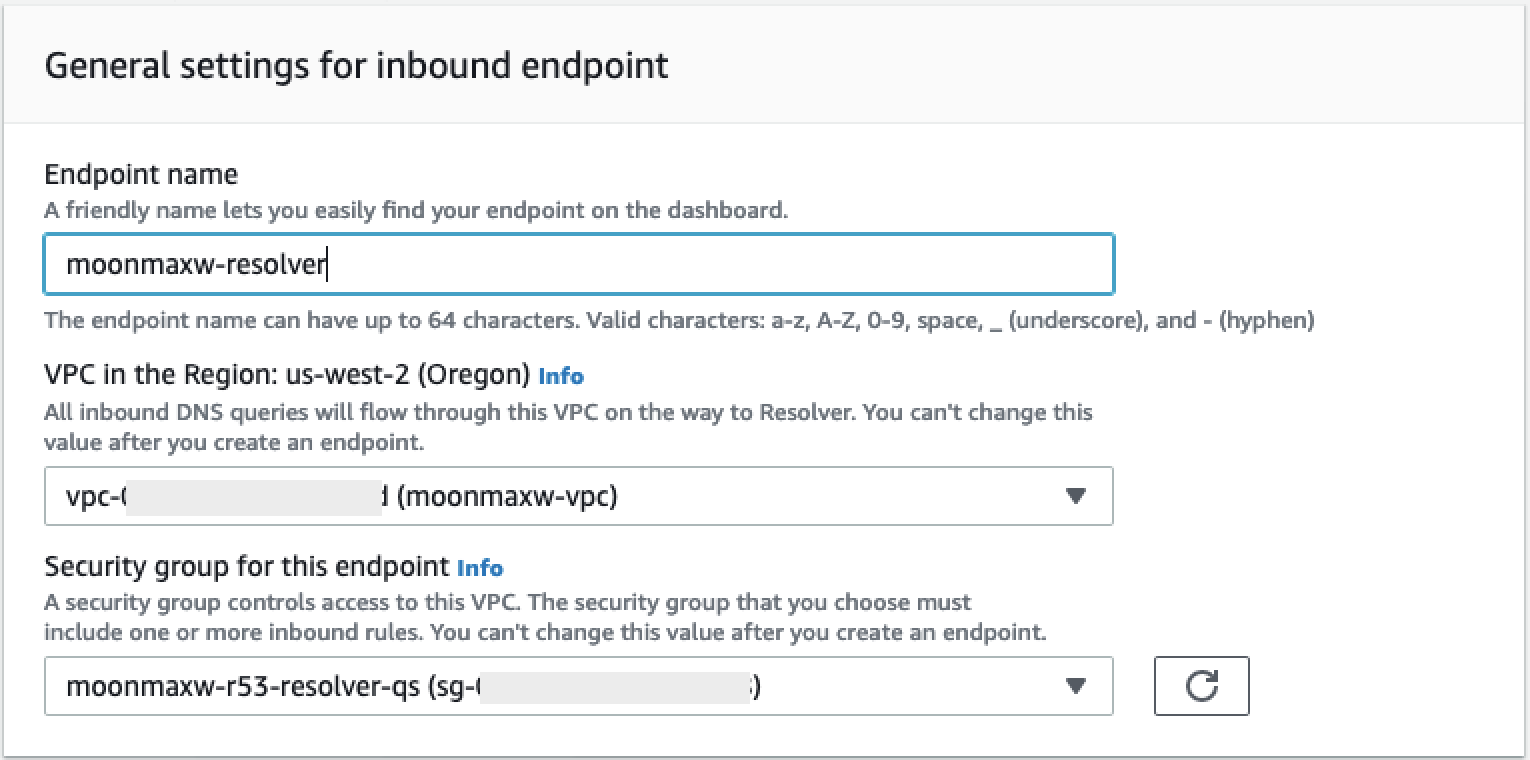
-
Nella sezione IP Address (Indirizzo IP), seleziona una zona di disponibilità, seleziona una sottorete e lascia selezionato automaticamente il selettore radio Use an IP address that is selected automatically (Usa un indirizzo IP selezionato automaticamente) per ogni indirizzo IP.
-
Seleziona Invia.
-
-
Seleziona Inbound endpoint (Endpoint in entrata) dopo averlo creato.
-
Una volta creato l'endpoint in entrata, annota i due indirizzi IP dei resolver.

SageMaker Endpoint AI VPC
Questa sezione spiega come creare endpoint VPC per: Amazon SageMaker Studio Classic, SageMaker Notebooks, SageMaker API, Runtime Runtime e Amazon Feature Store SageMaker Runtime. SageMaker
Creare un gruppo di sicurezza applicato a tutti gli endpoint.
-
Vai al menu EC2
nella console. AWS -
Nella sezione Network & Security (Rete e sicurezza), seleziona l'opzione Security groups (Gruppi di sicurezza).
-
Scegliere Create Security Group (Crea gruppo di sicurezza).
-
Indicare un nome e una descrizione del gruppo di sicurezza (come
datawrangler-doc-sagemaker-vpce-sg). Successivamente viene aggiunta una regola per consentire il traffico su HTTPS dall' SageMaker IA a questo gruppo.
Creazione dell'endpoint
-
Vai al menu VPC
nella AWS console. -
Seleziona l'opzione Endpoints.
-
Scegliere Create Endpoint (Crea endpoint).
-
Cerca il servizio inserendone il nome nel campo Search (Cerca).
-
Dall'elenco a discesa VPC, seleziona il VPC in cui esiste la connessione Snowflake. AWS PrivateLink
-
Nella sezione Subnet, seleziona le sottoreti che hanno accesso alla connessione Snowflake. PrivateLink
-
Per Enable DNS Name (Abilita nome DNS, lasciare la casella di controllo selezionata.
-
Nella sezione Security Groups (Gruppi di sicurezza), seleziona il gruppo di sicurezza creato nella sezione precedente.
-
Scegliere Create Endpoint (Crea endpoint).
Configurazione di Studio Classic e Data Wrangler
In questa sezione viene spiegato come configurare Studio Classic e Data Wrangler.
-
Configura il gruppo di sicurezza.
-
Accedi al menu Amazon EC2 nella AWS console.
-
Seleziona l'opzione Security Groups (Gruppi di sicurezza) nella sezione Network & Security (Rete e sicurezza).
-
Scegli Crea gruppo di sicurezza.
-
Fornisci un nome e una descrizione per il tuo gruppo di sicurezza (ad esempio
datawrangler-doc-sagemaker-studio). -
Creare le seguenti regole in entrata.
-
La connessione HTTPS al gruppo di sicurezza che hai fornito per la PrivateLink connessione Snowflake che hai creato nella fase di configurazione dell'integrazione Snowflake. PrivateLink
-
La connessione HTTP al gruppo di sicurezza che hai fornito per la connessione Snowflake che hai creato nella fase di configurazione dell'integrazione PrivateLink con Snowflake. PrivateLink
-
Il gruppo di sicurezza UDP e TCP per DNS (porta 53) a Route 53 Resolver Inbound Endpoint che crei nella fase 2 di Configurare endpoint in entrata del resolver Route 53 del VPC.
-
-
Scegli il pulsante Crea gruppo di sicurezza nell'angolo in basso a destra.
-
-
Configura Studio Classic.
-
Vai al menu SageMaker AI nella console. AWS
-
Dalla console di sinistra, seleziona l'opzione SageMaker AI Studio Classic.
-
Se non hai alcun dominio configurato, è presente il menu Get Started (Inizia).
-
Seleziona l'opzione Standard Setup (Configurazione standard) dal menu Get Started.
-
Per Authentication method (Metodo di autenticazione), scegliere AWS Identity and Access Management (IAM).
-
Dal menu Permissions (Autorizzazioni), puoi creare un nuovo ruolo o utilizzare un ruolo preesistente, a seconda del tuo caso d'uso.
-
Se scegli Create a new role (Crea un nuovo ruolo), ti viene presentata la possibilità di fornire un nome per il bucket S3 e viene generata una policy automatica.
-
Se hai già creato un ruolo con autorizzazioni per i bucket S3 a cui richiedi l'accesso, seleziona il ruolo dall'elenco a discesa. A questo ruolo deve essere collegata la policy
AmazonSageMakerFullAccess.
-
-
Seleziona l'elenco a discesa Rete e archiviazione per configurare il VPC, la sicurezza e le SageMaker sottoreti utilizzate dall'IA.
-
In VPC, seleziona il VPC in cui esiste la connessione Snowflake. PrivateLink
-
In Subnet (s), seleziona le sottoreti che hanno accesso alla connessione Snowflake. PrivateLink
-
In Accesso diretto per Studio Classic, seleziona Solo VPC.
-
In Security Group(s) seleziona il gruppo di sicurezza creato nella fase 1.
-
-
Scegli Invia.
-
-
Modifica il gruppo di sicurezza AI. SageMaker
-
Crea le seguenti regole in entrata:
-
Porta 2049 ai gruppi di sicurezza NFS in entrata e in uscita creati automaticamente da SageMaker AI nel passaggio 2 (i nomi dei gruppi di sicurezza contengono l'ID di dominio Studio Classic).
-
Accesso diretto a tutte le porte TCP (richiesto solo per SageMaker AI for VPC).
-
-
-
Modificare i gruppi di sicurezza degli endpoint VPC:
-
Accedi al menu Amazon EC2 nella AWS console.
-
Individua il gruppo di sicurezza che hai creato nella fase precedente.
-
Aggiungi una regola in entrata che consenta il traffico HTTPS proveniente dal gruppo di sicurezza creato nella fase 1.
-
-
Creare un profilo utente.
-
Dal pannello di controllo di SageMaker Studio Classic, scegli Aggiungi utente.
-
Fornisci un nome utente.
-
Per Execution Role (Ruolo di esecuzione), scegli se creare un nuovo ruolo o se utilizzare un ruolo preesistente.
-
Se scegli Create a new role (Crea un nuovo ruolo), ti viene presentata la possibilità di fornire un nome per il bucket Amazon S3 e viene generata una policy automatica.
-
Se hai già creato un ruolo con autorizzazioni ai bucket Amazon S3 a cui richiedi l'accesso, seleziona il ruolo dall'elenco a discesa. A questo ruolo deve essere collegata la policy
AmazonSageMakerFullAccess.
-
-
Seleziona Invia.
-
-
Creare un flusso di dati (segui la guida per data scientist descritta in una sezione precedente).
-
Quando aggiungete una connessione Snowflake, inserite il valore di
privatelink-account-name(dal passaggio Configurazione dell' PrivateLinkintegrazione con Snowflake) nel campo del nome dell'account Snowflake (alfanumerico), anziché il semplice nome dell'account Snowflake. Tutto il resto rimane invariato.
-
Fornire informazioni al data scientist
Fornisci al data scientist le informazioni di cui ha bisogno per accedere a Snowflake da Amazon SageMaker AI Data Wrangler.
Importante
I tuoi utenti devono eseguire Amazon SageMaker Studio Classic versione 1.3.0 o successiva. Per informazioni su come verificare la versione di Studio Classic e aggiornarla, consulta Prepara i dati ML con Amazon SageMaker Data Wrangler.
-
Per consentire al tuo data scientist di accedere a Snowflake da SageMaker Data Wrangler, forniscigli uno dei seguenti:
-
Per l'autenticazione di base, un nome account Snowflake, un nome utente e una password.
-
Per OAuth, un nome utente e una password nel provider di identità.
-
Per quanto riguarda l'ARN, il Secrets Manager rende segreto il nome della risorsa Amazon (ARN).
-
Un segreto creato con AWS Secrets Manager e l'ARN del segreto. Usa la seguente procedura per creare il segreto per Snowflake se scegli questa opzione.
Importante
Se i data scientist utilizzano l'opzione Snowflake Credentials (User name and Password) (Credenziali Snowflake (nome utente e password)) per connettersi a Snowflake, è possibile utilizzare Secrets Manager per archiviare le credenziali in un luogo segreto. Secrets Manager ruota i segreti come parte di un piano di sicurezza delle best practice. Il segreto creato in Secrets Manager è accessibile solo se il ruolo di Studio Classic viene configurato insieme al profilo utente di Studio Classic. Questo richiede l’aggiunta dell’autorizzazione
secretsmanager:PutResourcePolicyalla policy collegata al tuo ruolo di Studio Classic.Ti consigliamo vivamente di definire l’ambito della policy relativa al ruolo in modo da utilizzare ruoli distinti per i diversi gruppi di utenti di Studio Classic. È possibile aggiungere ulteriori autorizzazioni basate sulle risorse per i segreti di Secrets Manager. Vedi Manage Secret Policy per le chiavi di condizione che puoi utilizzare.
Per informazioni sulla creazione di un segreto, consulta Creazione di un segreto. I segreti che crei ti verranno addebitati.
-
-
(Facoltativo) Fornisci al data scientist il nome dell'integrazione di storage che hai creato utilizzando la seguente procedura Creare un'integrazione di archiviazione cloud in Snowflake
. Questo è il nome della nuova integrazione e viene chiamata integration_namenel comando SQLCREATE INTEGRATIONche hai eseguito, illustrato nel frammento seguente:CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
Guida per Data Scientist
Utilizza quanto segue per connettere Snowflake e accedere ai tuoi dati in Data Wrangler.
Importante
L'amministratore deve utilizzare le informazioni nelle sezioni precedenti per configurare Snowflake. Se riscontri problemi, contattali per ricevere assistenza sulla risoluzione dei problemi.
Puoi collegarti a Snowflake in uno dei seguenti modi:
-
Specificando le credenziali Snowflake (nome account, nome utente e password) in Data Wrangler.
-
Fornendo un nome della risorsa Amazon (ARN) di un segreto contenente le credenziali.
-
Utilizzando un provider OAuth (Open Standard for Access Delegation) che si connetta a Snowflake. L'amministratore può darti accesso a uno dei seguenti provider OAuth:
Parla con il tuo amministratore del metodo da utilizzare per connetterti a Snowflake.
Le seguenti sezioni contengono informazioni su come connettersi a Snowflake utilizzando i metodi precedenti.
Puoi iniziare il processo di importazione dei dati da Snowflake dopo esserti connesso.
In Data Wrangler, puoi visualizzare i data warehouse, i database e gli schemi, oltre all'icona a forma di occhio con cui puoi visualizzare l'anteprima della tabella. Selezionando l'icona Preview Table (anteprima della tabella), viene generata l'anteprima dello schema di quella tabella. È necessario selezionare un warehouse prima di visualizzare l'anteprima di una tabella.
Importante
Se stai importando un set di dati con colonne di tipo TIMESTAMP_TZ o TIMESTAMP_LTZ, aggiungi ::string ai nomi delle colonne della tua query. Per maggiori informazioni, consulta Procedura: scaricare i dati TIMESTAMP_TZ e TIMESTAMP_LTZ su un file Parquet
Dopo aver selezionato un data warehouse, un database e uno schema, potrai scrivere query ed eseguirle. L'output della query viene visualizzato in Query results (Risultati della query).
Dopo aver stabilito l'output della query, è possibile importare l'output della query in un flusso di Data Wrangler per eseguire trasformazioni dei dati.
Dopo aver importato i dati, accedi al flusso di Data Wrangler e inizia ad aggiungervi trasformazioni. Per un elenco di trasformazioni disponibili, consulta Trasformazione dei dati.
Importare dati da piattaforme Software as a Service (SaaS)
Puoi utilizzare Data Wrangler per importare dati da più di quaranta piattaforme software as a service (SaaS). Per importare i dati dalla tua piattaforma SaaS, tu o il tuo amministratore dovete utilizzare Amazon AppFlow per trasferire i dati dalla piattaforma ad Amazon S3 o Amazon Redshift. Per ulteriori informazioni su Amazon AppFlow, consulta What is Amazon AppFlow? Se non hai bisogno di usare Amazon Redshift, ti consigliamo di trasferire i dati su Amazon S3 per un processo più semplice.
Data Wrangler supporta il trasferimento di dati dalle seguenti piattaforme SaaS:
L'elenco precedente contiene collegamenti a ulteriori informazioni sulla configurazione dell'origine dati. Tu o il tuo amministratore potete fare riferimento ai collegamenti precedenti dopo aver letto le seguenti informazioni.
Quando accedi alla scheda Import (Importa) del flusso di Data Wrangler, vedi le origine dati nelle seguenti sezioni:
-
Disponibilità
-
Configurazione origini dati
Puoi connetterti a origine dati in Available (Disponibile) senza bisogno di configurazioni aggiuntive. Puoi scegliere l'origine dati e importare i tuoi dati.
In Configurazione delle sorgenti dati, richiedi a te o al tuo amministratore di utilizzare Amazon AppFlow per trasferire i dati dalla piattaforma SaaS ad Amazon S3 o Amazon Redshift. Per informazioni sull'esecuzione di un trasferimento, consulta Utilizzo di Amazon AppFlow per trasferire i dati.
Dopo aver eseguito il trasferimento dei dati, la piattaforma SaaS viene visualizzata come origine dati in Available (Disponibile). Puoi sceglierla e importare i dati che hai trasferito in Data Wrangler. I dati trasferiti vengono visualizzati sotto forma di tabelle su cui è possibile effettuare delle query.
Utilizzo di Amazon AppFlow per trasferire i dati
Amazon AppFlow è una piattaforma che puoi utilizzare per trasferire dati dalla tua piattaforma SaaS ad Amazon S3 o Amazon Redshift senza dover scrivere alcun codice. Per eseguire un trasferimento di dati, utilizza AWS Management Console
Importante
Devi assicurarti di aver impostato le autorizzazioni per eseguire un trasferimento di dati. Per ulteriori informazioni, consulta AppFlow Autorizzazioni Amazon.
Dopo aver aggiunto le autorizzazioni, puoi trasferire i dati. All'interno di Amazon AppFlow, crei un flusso per trasferire i dati. Un flusso è una serie di configurazioni. Puoi usarlo per specificare se stai eseguendo il trasferimento dei dati in base a una pianificazione o se stai partizionando i dati in file separati. Dopo aver configurato il flusso, lo esegui per trasferire i dati.
Per informazioni sulla creazione di un flusso, consulta Creazione di flussi in Amazon AppFlow. Per informazioni sull'esecuzione di un flusso, consulta Attivare un AppFlow flusso Amazon.
Dopo il trasferimento dei dati, utilizza la seguente procedura per accedere ai dati in Data Wrangler.
Importante
Prima di provare ad accedere ai tuoi dati, assicurati che il tuo ruolo IAM abbia la seguente policy:
Per impostazione predefinita, il ruolo IAM che utilizzi per accedere a Data Wrangler è il SageMakerExecutionRole. Per ulteriori informazioni sull'aggiunta di policy, consultare Aggiunta di autorizzazioni di identità IAM (console).
Per connettersi a un'origine dati, esegui le operazioni descritte di seguito.
-
Accedi ad Amazon SageMaker AI Console
. -
Scegli Studio
-
Scegli Launch app.
-
Dall'elenco a discesa, seleziona Studio.
-
Scegli l'icona Home.
-
Selezionare Data (Dati).
-
Scegli Data Wrangler.
-
Scegli Import data (Importa dati).
-
In Available (Disponibile), scegli l'origine dati.
-
Per il campo Name, specificare il nome della connessione.
-
(Opzionale) Scegli Advanced configuration (Advanced configuration (Configurazione avanzata).
-
Scegli un Workgroup (Gruppo di lavoro).
-
Se il tuo gruppo di lavoro non ha imposto la posizione di output di Amazon S3 o se non utilizzi un gruppo di lavoro, specifica un valore per Amazon S3 location of query results (Posizione Amazon S3 dei risultati delle query).
-
(Facoltativo) Per Data retention period, (Periodo di conservazione dei dati) seleziona la casella di controllo per impostare un periodo di conservazione dei dati e specifica il numero di giorni in cui archiviare i dati prima che vengano eliminati.
-
(Facoltativo) Per impostazione predefinita, Data Wrangler salva la connessione. È possibile scegliere di deselezionare la casella di controllo e non salvare la connessione.
-
-
Scegli Connetti.
-
Specificare una query.
Nota
Per aiutarti a specificare una query, puoi scegliere una tabella nel pannello di navigazione a sinistra. Data Wrangler mostra il nome della tabella e un'anteprima della tabella. Scegli l'icona accanto al nome tabella per copiare il nome. È possibile utilizzare il nome della tabella nella query.
-
Scegli Esegui.
-
Scegli Import query (Importa query).
-
Per Dataset name, specificare il nome del set di dati.
-
Scegliere Aggiungi.
Quando accedi alla schermata Import data (Importa dati), puoi vedere la connessione che hai creato. Puoi usare la connessione per importare più dati.
Archiviazione di dati importati
Importante
Ti consigliamo vivamente di seguire le best practice per proteggere il tuo bucket Amazon S3 seguendo Security best practices (Best practice di sicurezza).
Quando esegui una query sui dati da Amazon Athena o Amazon Redshift, il set di dati richiesto viene automaticamente archiviato in Amazon S3. I dati vengono archiviati nel bucket SageMaker AI S3 predefinito per la AWS regione in cui utilizzi Studio Classic.
I bucket S3 predefiniti hanno la seguente convenzione di denominazione: sagemaker-. Ad esempio, se il numero del tuo account è 111122223333 e utilizzi Studio Classic in region-account
numberus-east-1, i set di dati importati vengono archiviati in sagemaker-us-east-1-111122223333.
I flussi di Data Wrangler dipendono dalla posizione di questo set di dati Amazon S3, quindi non dovresti modificare questo set di dati in Amazon S3 mentre utilizzi un flusso dipendente. Se modifichi questa posizione S3 e desideri continuare a utilizzare il flusso di dati, devi rimuovere tutti gli oggetti nel file.flow trained_parameters Per farlo, scarica il file .flow da Studio Classic e, per ogni istanza trained_parameters, elimina tutte le voci. Quando hai finito, trained_parameters dovrebbe essere un oggetto JSON vuoto:
"trained_parameters": {}
Quando esporti e utilizzi il flusso di dati per elaborare i dati, il file .flow che esporti si riferisce a questo set di dati in Amazon S3. Per ottenere ulteriori informazioni, usare le sezioni indicate di seguito.
Archiviazione di importazione Amazon Redshift
Data Wrangler memorizza i set di dati che risultano dalla tua query in un file Parquet nel bucket AI S3 predefinito. SageMaker
Questo file è memorizzato con il seguente prefisso (directory): redshift/ uuid /data/, dove viene creato un identificatore univoco per ogni query. uuid
Ad esempio, se il bucket predefinito èsagemaker-us-east-1-111122223333, un singolo set di dati richiesto da Amazon Redshift si trova in s3://sagemaker-us-east-1 -//data/. 111122223333/redshift uuid
Archiviazione di importazione Amazon Athena
Quando esegui una query su un database Athena e importi un set di dati, Data Wrangler archivia il set di dati, nonché un sottoinsieme di tale set di dati o preview files (file di anteprima), in Amazon S3.
Il set di dati che importi selezionando Import dataset (Importa set di dati) viene archiviato in formato Parquet in Amazon S3.
I file di anteprima vengono scritti in formato CSV quando si seleziona Run (Esegui) nella schermata di importazione di Athena e contengono fino a 100 righe del set di dati sottoposto a query.
Il set di dati da interrogare si trova sotto il prefisso (directory): athena/ uuid /data/, dove viene creato un identificatore univoco per ogni query. uuid
Ad esempio, se il bucket predefinito èsagemaker-us-east-1-111122223333, un singolo set di dati interrogato da Athena si trova in /athena/ /data/. s3://sagemaker-us-east-1-111122223333 uuid example_dataset.parquet
Il sottoinsieme del set di dati memorizzato per l'anteprima dei dataframe in Data Wrangler è memorizzato con il prefisso: athena/.
