Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configura il fornitore del modello
Nota
In questa sezione, partiamo dal presupposto che il linguaggio e i modelli di incorporamento che intendi utilizzare siano già distribuiti. Per i modelli forniti da AWS, dovresti già disporre del tuo SageMaker endpoint o ARN dell'accesso ad Amazon Bedrock. Per gli altri fornitori di modelli, è necessario utilizzare la API chiave per autenticare e autorizzare le richieste al modello.
Jupyter AI supporta un'ampia gamma di fornitori di modelli e modelli linguistici, consulta l'elenco dei modelli supportati per rimanere aggiornato sugli ultimi modelli disponibili
La configurazione di Jupyter AI varia a seconda che si utilizzi l'interfaccia utente della chat o i comandi magici.
Configura il provider del modello nell'interfaccia utente della chat
Nota
È possibile configurare diversi modelli LLMs e incorporarli seguendo le stesse istruzioni. Tuttavia, è necessario configurare almeno un modello linguistico.
Per configurare l'interfaccia utente della chat
-
In JupyterLab, accedi all'interfaccia della chat selezionando l'icona della chat (
 ) nel pannello di navigazione a sinistra.
) nel pannello di navigazione a sinistra. -
Scegli l'icona di configurazione (
 ) nell'angolo in alto a destra del riquadro sinistro. Si apre il pannello di configurazione AI di Jupyter.
) nell'angolo in alto a destra del riquadro sinistro. Si apre il pannello di configurazione AI di Jupyter. -
Compila i campi relativi al tuo fornitore di servizi.
-
Per i modelli forniti da JumpStart Amazon Bedrock
-
Nell'elenco a discesa dei modelli linguistici, seleziona
sagemaker-endpointi modelli distribuiti con JumpStart obedrockper i modelli gestiti da Amazon Bedrock. -
I parametri variano a seconda che il modello sia distribuito su Amazon Bedrock SageMaker o su Amazon Bedrock.
-
Per i modelli distribuiti con: JumpStart
-
Inserisci il nome dell'endpoint in Nome dell'endpoint, quindi il nome Regione AWS in cui viene distribuito il modello in Nome regione. Per recuperare gli ARN SageMaker endpoint, vai a https://console.aws.amazon.com/sagemaker/
e scegli Inferenza ed Endpoints nel menu a sinistra. -
Incolla lo schema JSON di richiesta personalizzato per il tuo modello e il percorso di risposta corrispondente per analizzare l'output del modello.
Nota
Puoi trovare il formato di richiesta e risposta di vari modelli di JumpStart base nei seguenti taccuini di esempio
. Ogni taccuino prende il nome dal modello che illustra.
-
-
-
(Facoltativo) Seleziona un modello di incorporamento a cui hai accesso. I modelli di incorporamento vengono utilizzati per acquisire informazioni aggiuntive dai documenti locali, consentendo al modello di generazione del testo di rispondere alle domande nel contesto di tali documenti.
-
Scegli Salva modifiche e vai all'icona della freccia sinistra (
 ) nell'angolo in alto a sinistra del riquadro sinistro. Si apre l'interfaccia utente della chat di Jupyter AI. Puoi iniziare a interagire con il tuo modello.
) nell'angolo in alto a sinistra del riquadro sinistro. Si apre l'interfaccia utente della chat di Jupyter AI. Puoi iniziare a interagire con il tuo modello.
-
-
Per i modelli ospitati da provider di terze parti
-
Nell'elenco a discesa del modello linguistico, seleziona l'ID del tuo provider. Puoi trovare i dettagli di ciascun provider, incluso il relativo ID, nell'elenco
dei fornitori di modelli di Jupyter AI. -
(Facoltativo) Seleziona un modello di incorporamento a cui hai accesso. I modelli di incorporamento vengono utilizzati per acquisire informazioni aggiuntive dai documenti locali, consentendo al modello di generazione del testo di rispondere alle domande nel contesto di tali documenti.
-
Inserisci le chiavi dei tuoi modelli. API
-
Scegli Salva modifiche e vai all'icona della freccia sinistra (
) nell'angolo in alto a sinistra del riquadro sinistro. Si apre l'interfaccia utente della chat di Jupyter AI. Puoi iniziare a interagire con il tuo modello.
-
-
L'istantanea seguente è un'illustrazione del pannello di configurazione dell'interfaccia utente della chat impostato per richiamare un modello FLAN-T5-Small fornito e distribuito in. JumpStart SageMaker
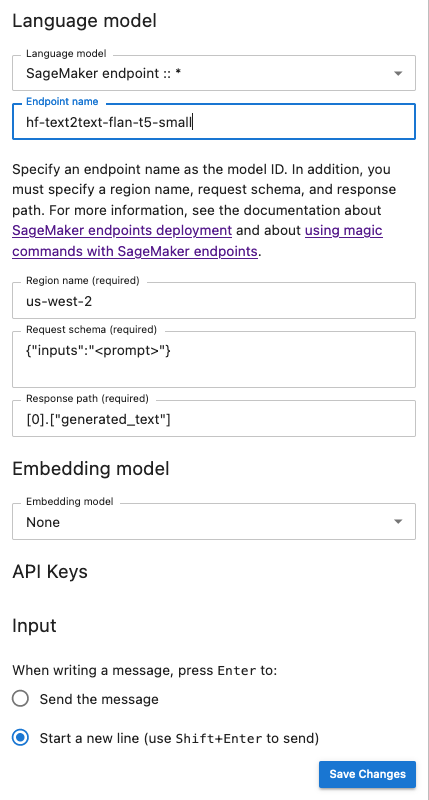
Passa parametri aggiuntivi del modello e parametri personalizzati alla tua richiesta
Il tuo modello potrebbe aver bisogno di parametri aggiuntivi, come un attributo personalizzato per l'approvazione del contratto con l'utente o modifiche ad altri parametri del modello come la temperatura o la lunghezza di risposta. Ti consigliamo di configurare queste impostazioni come opzione di avvio dell' JupyterLabapplicazione utilizzando una configurazione del ciclo di vita. Per informazioni su come creare una configurazione del ciclo di vita e collegarla al dominio o a un profilo utente dalla SageMaker console
Utilizzate lo JSON schema seguente per configurare i parametri aggiuntivi:
{ "AiExtension": { "model_parameters": { "<provider_id>:<model_id>": { Dictionary of model parameters which is unpacked and passed as-is to the provider.} } } } }
Lo script seguente è un esempio di file di JSON configurazione che puoi utilizzare durante la creazione di un' JupyterLab applicazione LCC per impostare la lunghezza massima di un modello AI21 Labs Jurassic-2 distribuito su Amazon Bedrock. L'aumento della lunghezza della risposta generata dal modello può impedire il troncamento sistematico della risposta del modello.
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:ai21.j2-mid-v1": {"model_kwargs": {"maxTokens": 200}}}}}' # equivalent to %%ai bedrock:ai21.j2-mid-v1 -m {"model_kwargs":{"maxTokens":200}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
Lo script seguente è un esempio di file di JSON configurazione per la creazione di un' JupyterLab applicazione LCC utilizzata per impostare parametri di modello aggiuntivi per un modello Anthropic Claude distribuito su Amazon Bedrock.
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:anthropic.claude-v2":{"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":25 0,"max_tokens_to_sample":2}}}}}' # equivalent to %%ai bedrock:anthropic.claude-v2 -m {"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":250,"max_tokens_to_sample":2000}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
Dopo aver LCC collegato il tuo dominio o profilo utente, aggiungilo LCC al tuo spazio quando avvii l'applicazione. JupyterLab Per garantire che il file di configurazione venga aggiornato daLCC, eseguilo more ~/.jupyter/jupyter_jupyter_ai_config.json in un terminale. Il contenuto del file deve corrispondere al contenuto del JSON file passato aLCC.
Configura il fornitore del modello in un notebook
Per richiamare un modello tramite Jupyter AI all'interno dei notebook Studio Classic JupyterLab o utilizzando i comandi e magic %%ai%ai
-
Installa le librerie client specifiche del tuo fornitore di modelli nell'ambiente notebook. Ad esempio, quando si utilizzano modelli OpenAI, è necessario installare la libreria
openaiclient. Puoi trovare l'elenco delle librerie client richieste per provider nella colonna Pacchetti Python dell'elenco dei fornitori di modelli AI di Jupyter.Nota
Per i modelli ospitati da AWS,
boto3è già installato nell'immagine SageMaker Distribution utilizzata da JupyterLab o in qualsiasi immagine Data Science utilizzata con Studio Classic. -
-
Per i modelli ospitati da AWS
Assicurati che il tuo ruolo di esecuzione sia autorizzato a richiamare il tuo SageMaker endpoint per i modelli forniti da Amazon Bedrock JumpStart o che tu abbia accesso ad Amazon Bedrock.
-
Per i modelli ospitati da fornitori di terze parti
Esporta la API chiave del tuo provider nell'ambiente del tuo notebook utilizzando variabili di ambiente. È possibile utilizzare il seguente comando magico. Sostituisci il
provider_API_keycomando con la variabile di ambiente che si trova nella colonna Variabile di ambiente dell'elenco dei fornitori di modelli Jupyter AI per il tuo provider. %env provider_API_key=your_API_key
-
