Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Model Monitor FAQs
Fai riferimento a quanto segue FAQs per ulteriori informazioni su Amazon SageMaker Model Monitor.
D: In che modo Model Monitor e SageMaker Clarify aiutano i clienti a monitorare il comportamento dei modelli?
I clienti possono monitorare il comportamento del modello in base a quattro dimensioni: qualità dei dati, qualità del modello, deriva dal bias e deriva dall'attribuzione delle funzionalità tramite SageMaker Amazon Model Monitor e Clarify. SageMaker Model Monitor
D: Cosa succede in background quando Sagemaker Model Monitor è abilitato?
Amazon SageMaker Model Monitor automatizza il monitoraggio dei modelli alleviando la necessità di monitorare i modelli manualmente o di creare strumenti aggiuntivi. Per automatizzare il processo, Model Monitor offre la possibilità di creare una serie di statistiche e vincoli della baseline utilizzando i dati con cui il modello è stato addestrato, quindi di impostare una pianificazione per monitorare le previsioni fatte sull'endpoint. Model Monitor utilizza delle regole per rilevare deviazioni nei modelli e avvisa l'utente qualora si verifichino. Le fasi di seguito descrivono lo scenario in cui è abilitato il monitoraggio del modello:
-
Abilita il monitoraggio del modello: per un endpoint in tempo reale, è necessario consentire l'acquisizione dei dati dalle richieste in entrata a un modello di ML distribuito e delle previsioni del modello risultanti. Per un processo di trasformazione di batch, abilita l'acquisizione dei dati in ingresso e in uscita della trasformazione in batch.
-
Processo di elaborazione della baseline: devi creare una baseline dal set di dati utilizzato per l’addestramento del modello. La baseline calcola i parametri e suggerisce i relativi vincoli. Ad esempio, il punteggio di richiamo per il modello non dovrebbe regredire e scendere al di sotto di 0,571, oppure il punteggio di precisione non dovrebbe scendere al di sotto di 1,0. Le previsioni in tempo reale o in batch del modello vengono confrontate con i vincoli e vengono segnalate come violazioni se non rientrano nei valori vincolati.
-
Processo di monitoraggio: quindi crei una pianificazione di monitoraggio specificando i dati da raccogliere, la frequenza di raccolta, la modalità di analisi e i report da produrre.
-
Unisci lavoro: è applicabile solo se utilizzi Amazon SageMaker Ground Truth. Model Monitor confronta le previsioni fatte dal modello con le etichette Ground Truth per misurare la qualità del modello. Affinché ciò funzioni, devi etichettare periodicamente i dati acquisiti dall'endpoint o dal processo di trasformazione di batch e caricarli su Amazon S3.
Dopo aver creato e caricato le etichette Ground Truth, includi la posizione delle etichette come parametro quando crei il processo di monitoraggio.
Quando si utilizza Model Monitor per monitorare un processo di trasformazione di batch invece di un endpoint in tempo reale, anziché ricevere richieste a un endpoint e tenere traccia delle previsioni, Model Monitor monitora gli input e gli output dell'inferenza. In una pianificazione di Model Monitor, il cliente fornisce il numero e il tipo di istanze da utilizzare nel processo di elaborazione. Queste risorse rimangono riservate fino all'eliminazione della pianificazione, indipendentemente dallo stato dell'esecuzione corrente.
D: Cos'è Acquisizione dei dati, perché è necessario e come posso abilitarlo?
Per registrare gli input all'endpoint del modello e gli output dell'inferenza dal modello distribuito su Amazon S3, puoi abilitare una funzionalità chiamata Acquisizione dei dati. Per maggiori dettagli su come abilitarla per un processo di trasformazione di batch e per gli endpoint in tempo reale, consulta Acquisizione dei dati dall'endpoint in tempo reale e Acquisizione dei dati dal processo di trasformazione di batch.
D: L'abilitazione di Acquisizione dei dati influisce sulle prestazioni di un endpoint in tempo reale?
L'acquisizione dei dati avviene in modo asincrono senza influire sul traffico di produzione. Dopo aver abilitato l'acquisizione dei dati, i payload della richiesta e della risposta, insieme ad alcuni metadati aggiuntivi, vengono salvati nel percorso Amazon S3 specificato in DataCaptureConfig. Tieni presente che può verificarsi un ritardo nella propagazione dei dati acquisiti su Amazon S3.
Puoi anche visualizzare i dati acquisiti elencando i file di acquisizione dei dati archiviati in Amazon S3. Il formato del percorso di Amazon S3 è: s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl. Acquisizione dei dati di Amazon S3 deve trovarsi nella stessa Regione della pianificazione di Model Monitor. Dovresti inoltre assicurarti che i nomi delle colonne per il set di dati della baseline contengano solo lettere minuscole e un trattino basso (_) come unico separatore.
D: Perché è necessario Ground Truth per il monitoraggio dei modelli?
Le etichette Ground Truth sono necessarie per le seguenti funzionalità di Model Monitor:
-
Il monitoraggio della qualità del modello confronta le previsioni fatte dal modello con le etichette Ground Truth per misurare la qualità del modello stesso.
-
Il monitoraggio del bias del modello monitora le previsioni per rilevare eventuali distorsioni. Il bias può essere introdotto nei modelli di machine learning implementati quando i dati di addestramento utilizzati differiscono dai dati impiegati per generare previsioni. Ciò è particolarmente evidente se i dati di addestramento utilizzati cambiano nel tempo (ad esempio la fluttuazione dei tassi ipotecari) e la previsione del modello non è altrettanto accurata a meno che il modello non venga ri-addestrato con dati aggiornati. Ad esempio, un modello per la previsione dei prezzi delle case può diventare distorto se i tassi ipotecari utilizzati per addestrare il modello differiscono dai tassi ipotecari attuali nel mondo reale.
D: Per i clienti che utilizzano Ground Truth per l'etichettatura, quali sono le fasi da eseguire per monitorare la qualità del modello?
Il monitoraggio della qualità del modello confronta le previsioni fatte dal modello con le etichette Ground Truth per misurare la qualità del modello stesso. Affinché ciò funzioni, devi etichettare periodicamente i dati acquisiti dall'endpoint o dal processo di trasformazione di batch e caricarli su Amazon S3. Oltre alle acquisizioni, l'esecuzione del monitoraggio dei bias del modello richiede anche i dati di Ground Truth. In casi d'uso reali, i dati di Ground Truth devono essere raccolti e caricati regolarmente nella posizione Amazon S3 designata. Per abbinare le etichette Ground Truth ai dati di previsione acquisiti, deve esserci un identificatore univoco per ogni record nel set di dati. Per la struttura di ciascun record dei dati di Ground Truth, consulta Inserimento delle etichette Ground Truth e unione con le previsioni.
Il seguente esempio di codice può essere utilizzato per generare dati artificiali di Ground Truth per un set di dati tabulare.
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
Nell'esempio di codice seguente viene illustrato come generare traffico artificiale da inviare all'endpoint del modello. Nota l'attributo inferenceId usato sopra per l'invocazione. Se è presente, viene utilizzato per unire i dati di Ground Truth (altrimenti, viene utilizzato eventId).
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
È necessario caricare i dati Ground Truth in un bucket Amazon S3 con lo stesso formato di percorso dei dati acquisiti, che è il seguente: s3://<bucket>/<prefix>/yyyy/mm/dd/hh
Nota
La data in questo percorso è la data in cui viene raccolta l'etichetta Ground Truth. Non deve corrispondere alla data in cui è stata generata l'inferenza.
D: In che modo i clienti possono personalizzare le pianificazioni di monitoraggio?
Oltre a utilizzare i meccanismi di monitoraggio integrati, è possibile creare pianificazioni e procedure personalizzate di monitoraggio utilizzando script di pre-elaborazione e post-elaborazione o utilizzando o costruendo il proprio container. È importante notare che gli script di pre-elaborazione e post-elaborazione funzionano solo con processi di qualità dei dati e dei modelli.
Amazon ti SageMaker offre la capacità di monitorare e valutare i dati osservati dagli endpoint del modello. A tal fine, è necessario creare una baseline con cui confrontare il traffico in tempo reale. Una volta che la baseline è pronta, imposta una pianificazione per la valutazione e il confronto continui rispetto ad essa. Durante la creazione di una pianificazione, puoi fornire lo script di pre-elaborazione e post-elaborazione.
L'esempio seguente mostra come personalizzare le pianificazioni di monitoraggio con script di pre-elaborazione e post-elaborazione.
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
D: Quali sono alcuni scenari o casi d'uso in cui posso sfruttare uno script di pre-elaborazione?
È possibile utilizzare gli script di pre-elaborazione quando è necessario trasformare gli input a Model Monitor. Considera ad esempio gli scenari riportati di seguito:
-
Script di pre-elaborazione per la trasformazione dei dati.
Supponiamo che l'output del modello sia una matrice:
[1.0, 2.1]. Il contenitore Model Monitor funziona solo con JSON strutture tabulari o appiattite, come.{“prediction0”: 1.0, “prediction1” : 2.1}È possibile utilizzare uno script di pre-elaborazione come nell'esempio seguente per trasformare l'array nella struttura corretta. JSONdef preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
Escludi determinati record dai calcoli dei parametri di Model Monitor.
Supponiamo che il modello abbia funzionalità opzionali e che si utilizzi
-1per indicare che la funzionalità opzionale ha un valore mancante. Se disponi di un sistema di monitoraggio per la qualità dei dati, è consigliabile rimuovere-1dalla matrice dei valori di input in modo che non venga incluso nei calcoli dei parametri di monitoraggio. Per rimuovere tali valori puoi usare uno script come quello riportato di seguito.def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Applica una strategia di campionamento personalizzata.
Puoi anche applicare una strategia di campionamento personalizzata nello script di pre-elaborazione. A tale scopo, configura il container proprietario e predefinito di Model Monitor in modo che ignori una percentuale dei record in base alla frequenza di campionamento specificata. Nell'esempio seguente, il gestore campiona il 10% dei record restituendo il record nel 10% delle chiamate al gestore e in caso contrario un elenco vuoto.
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
Utilizza la registrazione personalizzata.
Puoi registrare tutte le informazioni di cui hai bisogno dal tuo script su Amazon CloudWatch. Questo può essere utile per eseguire il debug dello script di pre-elaborazione in caso di errore. L'esempio seguente mostra come utilizzare l'
preprocess_handlerinterfaccia per accedere CloudWatch.def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
Nota
Quando lo script di pre-elaborazione viene eseguito su dati di trasformazione in batch, il tipo di input non è sempre l'oggetto CapturedData. Per CSV i dati, il tipo è una stringa. Per JSON i dati, il tipo è un dizionario Python.
D: Quando posso utilizzare uno script di post-elaborazione?
È possibile utilizzare uno script di post-elaborazione come estensione dopo la corretta esecuzione del monitoraggio. Quello che segue è semplicemente un esempio, ma è possibile eseguire o richiamare qualsiasi funzione aziendale necessaria dopo una corretta esecuzione del monitoraggio.
def postprocess_handler(): print("Hello from the post-processing script!")
D: Quando devo prendere in considerazione l'idea di creare il mio container per il monitoraggio dei modelli?
SageMaker fornisce un contenitore predefinito per l'analisi dei dati acquisiti dagli endpoint o i processi di trasformazione in batch per set di dati tabulari. Tuttavia, ci sono scenari in cui potrebbe essere meglio creare il proprio container. Considerare i seguenti scenari:
-
Hai requisiti normativi e di conformità che impongono di utilizzare solo i container creati e gestiti internamente all'organizzazione.
-
Se desideri includere alcune librerie di terze parti, puoi inserire un
requirements.txtfile in una directory locale e farvi riferimento utilizzando ilsource_dirparametro nello SageMaker stimatore, che consente l'installazione della libreria in fase di esecuzione. Tuttavia, se disponete di molte librerie o dipendenze che aumentano il tempo di installazione durante l'esecuzione del processo di formazione, potreste volerle sfruttare. BYOC -
Il tuo ambiente non impone alcuna connettività Internet (o Silo), il che impedisce il download dei pacchetti.
-
Desideri monitorare i dati in formati di dati diversi da quelli tabulari, ad esempio nei casi NLP d'uso CV.
-
Quando hai bisogno di parametri di monitoraggio aggiuntivi rispetto a quelli supportati da Model Monitor.
D: Ho dei modelli NLP di CV. Come posso monitorarli per rilevare la deviazione dei dati?
Il contenitore predefinito SageMaker di Amazon supporta set di dati tabulari. Se desideri monitorare NLP i modelli CV, puoi portare il tuo contenitore sfruttando i punti di estensione forniti da Model Monitor. Per maggiori dettagli sui requisiti, consulta Bring your own containers. Di seguito vengono mostrati altri esempi:
-
Per una spiegazione dettagliata su come utilizzare Model Monitor per un caso d'uso di visione artificiale, consulta Detecting and Analyzing incorrect predictions
. -
Per uno scenario in cui Model Monitor può essere utilizzato per un caso NLP d'uso, consulta Rileva la deriva NLP dei dati utilizzando Amazon SageMaker Model
Monitor personalizzato.
D: Desidero eliminare l'endpoint del modello per il quale Model Monitor è stato abilitato, ma non posso farlo perché la pianificazione del monitoraggio è ancora attiva. Cosa devo fare?
Se desideri eliminare un endpoint di inferenza ospitato in SageMaker cui Model Monitor è abilitato, devi prima eliminare la pianificazione di monitoraggio del modello (con o). DeleteMonitoringSchedule CLIAPI Quindi, puoi eliminare l'endpoint.
D: SageMaker Model Monitor calcola metriche e statistiche per l'input?
Model Monitor calcola parametri e statistiche per l'output, non per l'input.
D: SageMaker Model Monitor supporta endpoint multimodello?
No, Model Monitor attualmente supporta solo gli endpoint a modello singolo e non supporta il monitoraggio di endpoint multi-modello.
D: SageMaker Model Monitor fornisce dati di monitoraggio sui singoli contenitori in una pipeline di inferenza?
Model Monitor supporta il monitoraggio delle pipeline di inferenza, ma l'acquisizione e l'analisi dei dati viene eseguita per l'intera pipeline, non per i singoli container nella pipeline.
D: Cosa posso fare per prevenire l'impatto sulle richieste di inferenza quando è impostata l'acquisizione dei dati?
Per prevenire l'impatto sulle richieste di inferenza, Acquisizione dei dati interrompe l'acquisizione delle richieste a livelli elevati di utilizzo del disco. Si consiglia di mantenere l'utilizzo del disco al di sotto del 75% per garantire che l'acquisizione dei dati continui a ricevere le richieste.
D: Amazon S3 Data Capture può trovarsi in una AWS regione diversa da quella in cui è stato impostato il programma di monitoraggio?
Acquisizione dei dati di Amazon S3 deve trovarsi nella stessa Regione della pianificazione di monitoraggio.
D: Cos'è una baseline e come posso crearne una? Posso creare una baseline personalizzata?
La baseline viene utilizzata come riferimento per confrontare le previsioni in tempo reale o in batch del modello. Calcola statistiche e parametri insieme ai relativi vincoli. Durante il monitoraggio, tutti questi elementi vengono utilizzati congiuntamente per identificare le violazioni.
Per utilizzare la soluzione predefinita di Amazon SageMaker Model Monitor, puoi sfruttare Amazon SageMaker Python SDK
Il risultato di un processo della baseline consiste in due file: statistics.json e constraints.json. Lo schema per le statistiche e lo schema per i vincoli contengono lo schema dei rispettivi file. Si consiglia di visualizzare i vincoli generati e modificarli, se necessario, prima di utilizzarli per il monitoraggio. In base al dominio e al problema aziendale, è possibile rendere un vincolo più aggressivo o attenuarlo per controllare il numero e la natura delle violazioni.
D: Quali sono le linee guida per creare un set di dati della baseline?
Il requisito principale per qualsiasi tipo di monitoraggio è disporre di un set di dati della baseline da utilizzare per calcolare parametri e vincoli. In genere, questo è il set di dati di addestramento utilizzato dal modello, ma in alcuni casi è possibile scegliere di utilizzare un altro set di dati di riferimento.
I nomi delle colonne del set di dati della baseline devono essere compatibili con Spark. Per mantenere la massima compatibilità tra Spark JSON e parquetCSV, è consigliabile utilizzare solo lettere minuscole e utilizzarle solo come separatore. _ I caratteri speciali tra cui “ ” possono causare problemi.
D: Cosa sono i parametri StartTimeOffset e EndTimeOffset e quando vengono utilizzati?
Quando Amazon SageMaker Ground Truth è necessario per monitorare lavori come la qualità dei modelli, devi assicurarti che un processo di monitoraggio utilizzi solo i dati per i quali è disponibile Ground Truth. I end_time_offset parametri start_time_offset and di EndpointInputstart_time_offset e end_time_offset. Questi parametri devono essere specificati nel formato di durata ISO 8601
-
Se i risultati di Ground Truth arrivano 3 giorni dopo che sono state fatte le previsioni, imposta
start_time_offset="-P3D"eend_time_offset="-P1D", ovvero rispettivamente 3 giorni e 1 giorno. -
Se i risultati di Ground Truth arrivano 6 ore dopo le previsioni e hai una pianificazione oraria, imposta
start_time_offset="-PT6H"eend_time_offset="-PT1H", ovvero 6 ore e 1 ora.
D: Posso eseguire lavori di monitoraggio "on demand"?
Sì, è possibile eseguire lavori di monitoraggio «su richiesta» eseguendo un SageMaker processo di elaborazione. Per Batch Transform, Pipelines ha un MonitorBatchTransformStep
D: Come configuro Model Monitor?
È possibile configurare Model Monitor nei modi seguenti:
-
Amazon SageMaker Python SDK
: esiste un modulo Model Monitor che contiene classi e funzioni che aiutano a suggerire linee di base, creare pianificazioni di monitoraggio e altro ancora. Consulta gli esempi di notebook Amazon SageMaker Model Monitor per notebook dettagliati che sfruttano SageMaker SDK Python per configurare Model Monitor. -
Pipeline: le pipeline sono integrate con Model Monitor through the Step and. QualityCheck ClarifyCheckStepAPIs È possibile creare una SageMaker pipeline che contenga questi passaggi e che possa essere utilizzata per eseguire lavori di monitoraggio su richiesta ogni volta che la pipeline viene eseguita.
-
Amazon SageMaker Studio Classic: puoi creare un programma di monitoraggio della qualità dei dati o dei modelli insieme a pianificazioni di distorsione del modello e spiegabilità direttamente dall'interfaccia utente selezionando un endpoint dall'elenco degli endpoint del modello distribuiti. È possibile creare pianificazioni per altri tipi di monitoraggio selezionando la scheda pertinente nell'interfaccia utente.
-
SageMaker Model Dashboard: puoi abilitare il monitoraggio sugli endpoint selezionando un modello che è stato distribuito su un endpoint. Nella schermata seguente della SageMaker console, un modello denominato
group1è stato selezionato dalla sezione Modelli della dashboard dei modelli. In questa pagina è possibile creare una pianificazione di monitoraggio e modificare, attivare o disattivare le pianificazioni di monitoraggio e gli avvisi esistenti. Per una guida dettagliata su come visualizzare gli avvisi e le pianificazioni di monitoraggio dei modelli, consulta Visualizzazione delle pianificazioni e degli avvisi di Model Monitor.
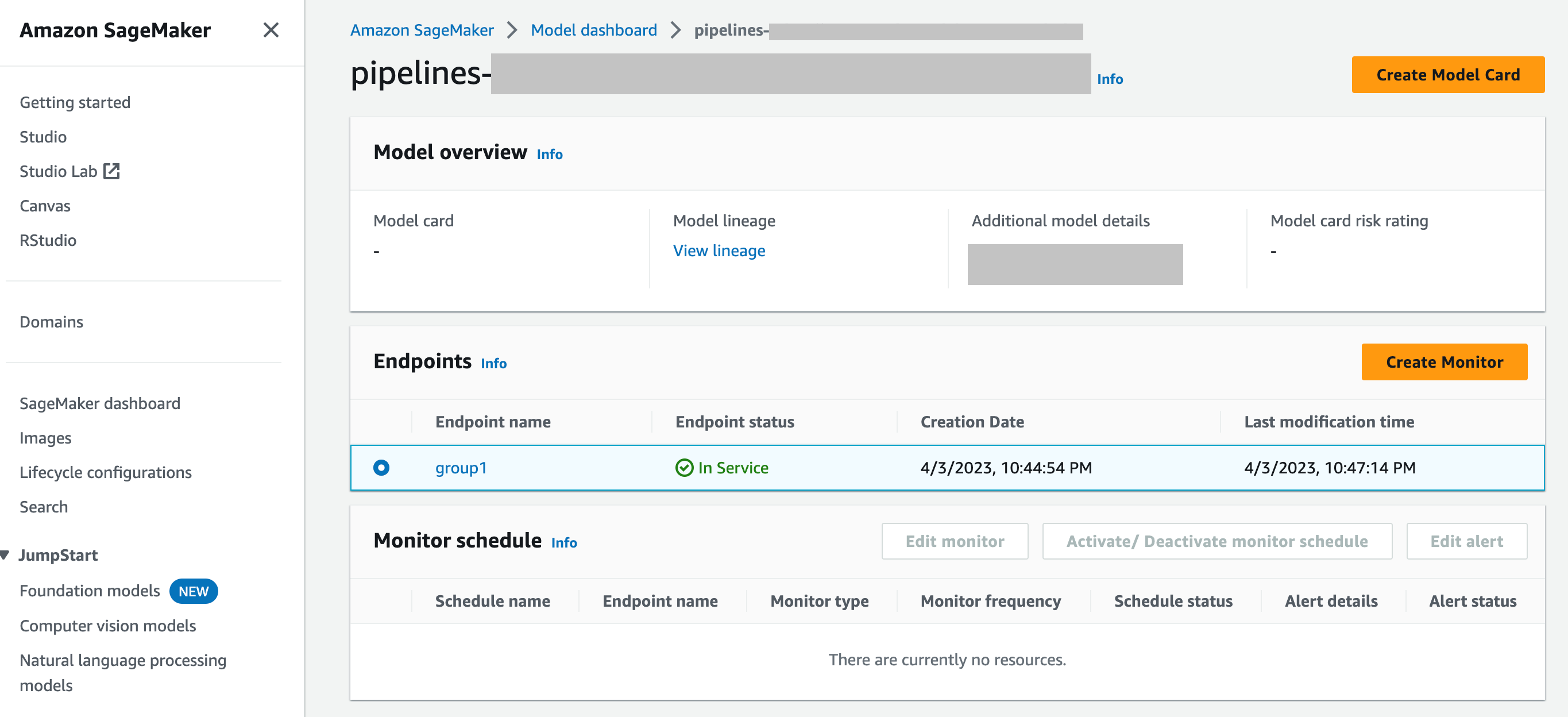
D: Come si integra Model Monitor con SageMaker Model Dashboard
SageMaker Model Dashboard offre un monitoraggio unificato di tutti i modelli fornendo avvisi automatici sulle deviazioni dal comportamento previsto e risoluzione dei problemi per ispezionare i modelli e analizzare i fattori che influiscono sulle prestazioni del modello nel tempo.
