Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Categorizza il testo con la classificazione del testo () Multi-label
Per classificare articoli e testo in più categorie predefinite, utilizza il tipo di attività di classificazione del testo multi-etichetta. Ad esempio, con questo tipo di attività puoi identificare più di un'emozione trasmessa nel testo. Le seguenti sezioni forniscono informazioni su come creare un’attività di classificazione del testo multi-etichetta dalla console e dall’API.
Quando si utilizza a un'attività di classificazione del testo multi-etichetta, i worker scelgono tutte le etichette applicabili e devono selezionarne almeno una. Quando si crea un processo utilizzando questo tipo di attività, è possibile fornire fino a 50 categorie di etichette.
Amazon SageMaker Ground Truth non fornisce una categoria «nessuna» per i casi in cui nessuna delle etichette è applicabile. Per fornire questa opzione ai worker, includi un'etichetta simile a "nessuna" o "altro" quando crei un processo di classificazione del testo multi-etichetta.
Per limitare la scelta dei worker a una singola etichetta per ogni selezione di testo o documento, utilizza il tipo di attività Categorizzare il testo con la classificazione (etichetta singola).
Importante
Se crei manualmente un file manifest di input, usa "source" per identificare il testo che desiderate etichettare. Per ulteriori informazioni, consulta Dati di input.
Creazione di un processo di etichettatura di classificazione del Multi-Label testo (console)
Puoi seguire le istruzioni Creare un processo di etichettatura (console) per imparare a creare un processo di etichettatura con classificazione del testo multietichetta nella console Amazon SageMaker AI. Nel passaggio 10, scegli Testo dal menu a discesa della categoria Attività e scegli Classificazione del testo (Multi-label) come tipo di attività.
Ground Truth fornisce un'interfaccia utente di lavoro simile alla seguente per le attività di etichettatura. Quando si crea il processo di etichettatura con la console, si specificano le istruzioni per consentire ai worker di completare il processo e le etichette tra cui i worker possono scegliere.
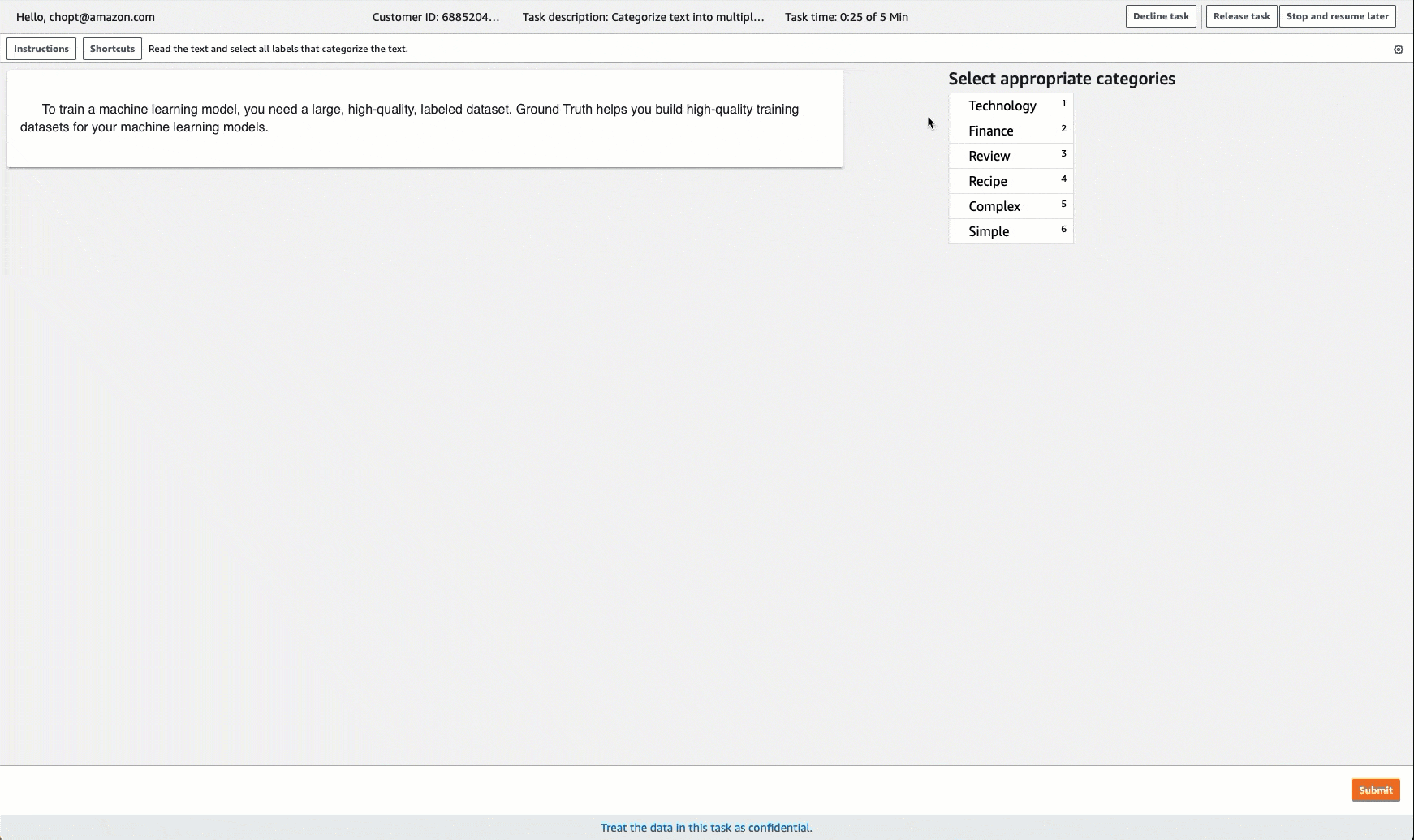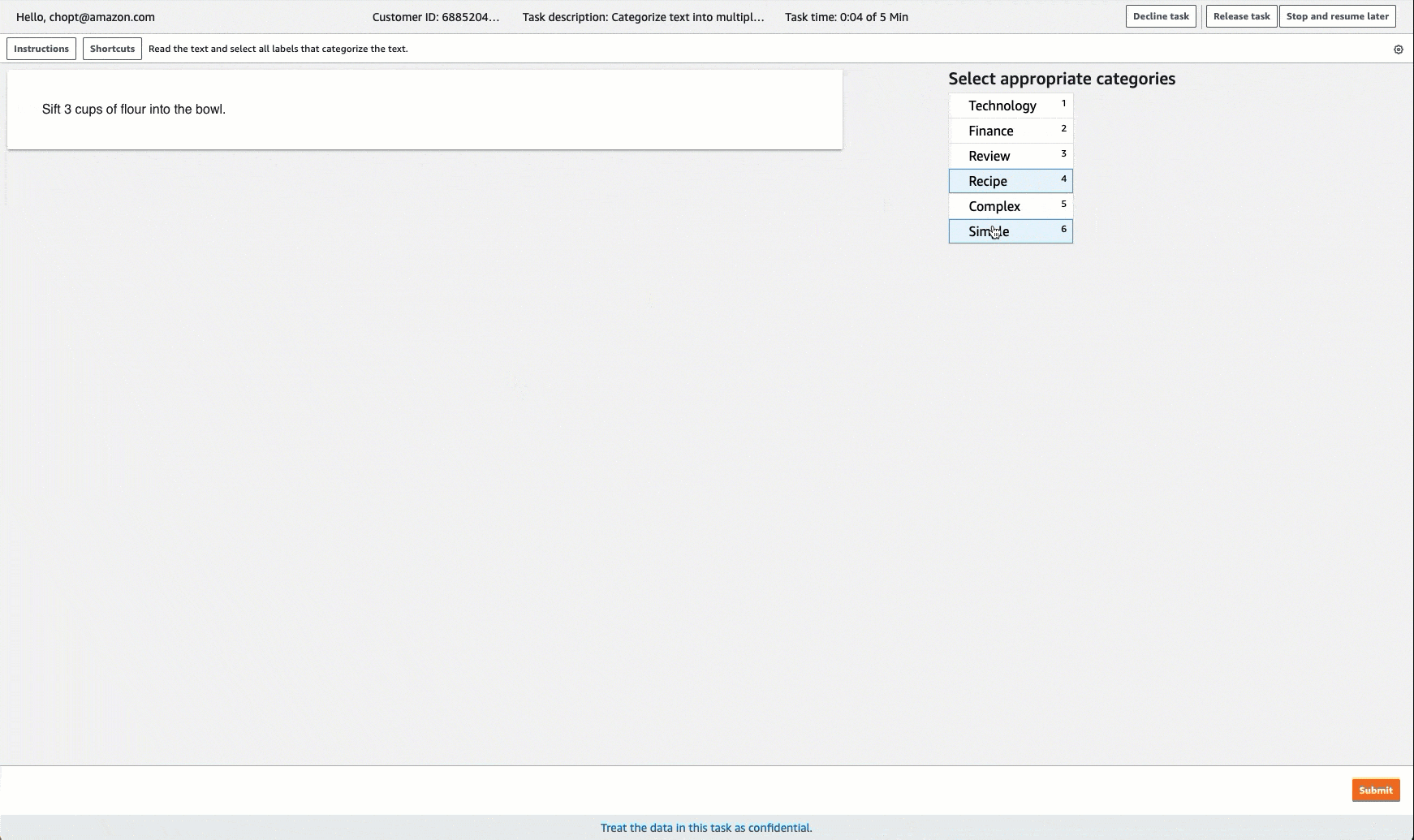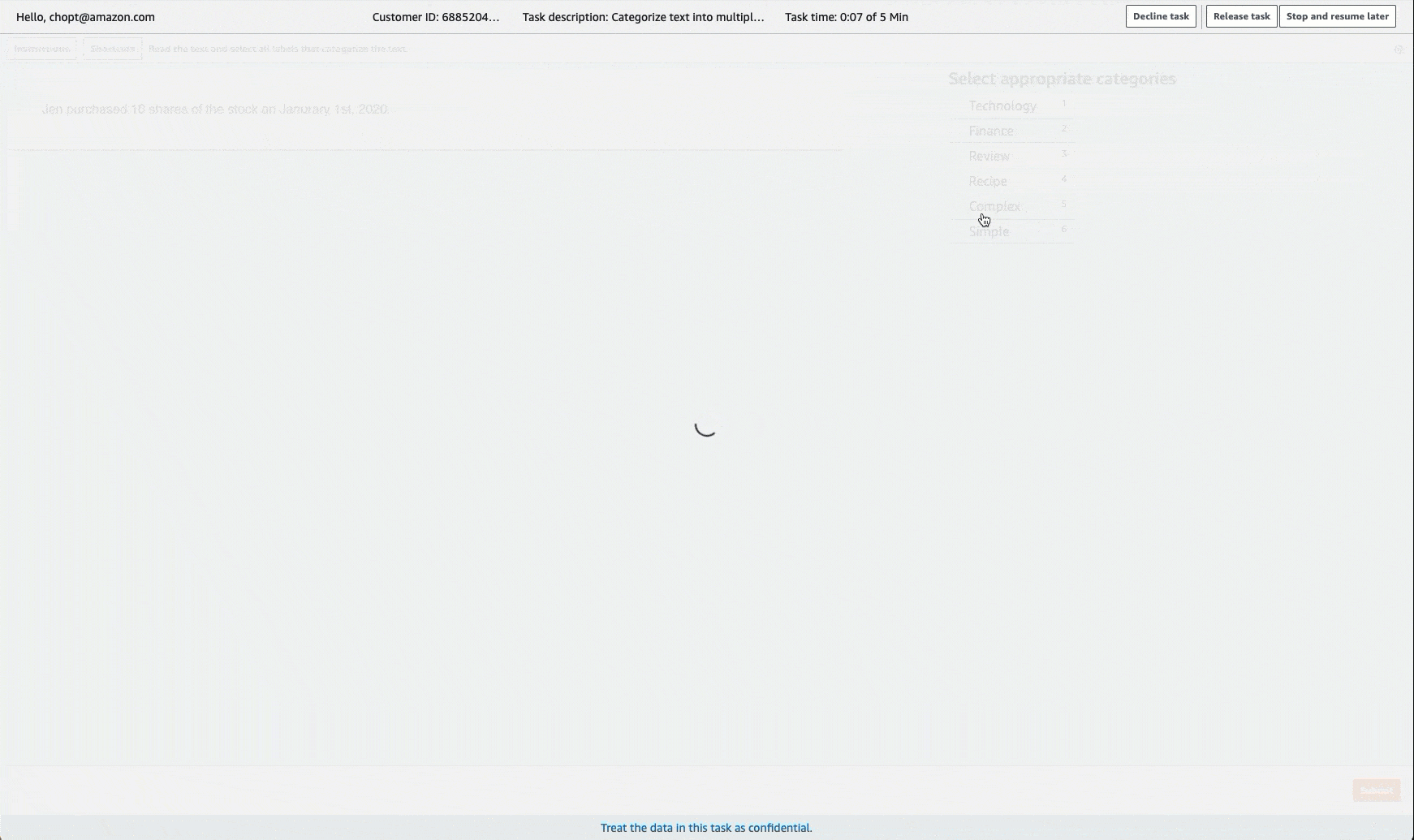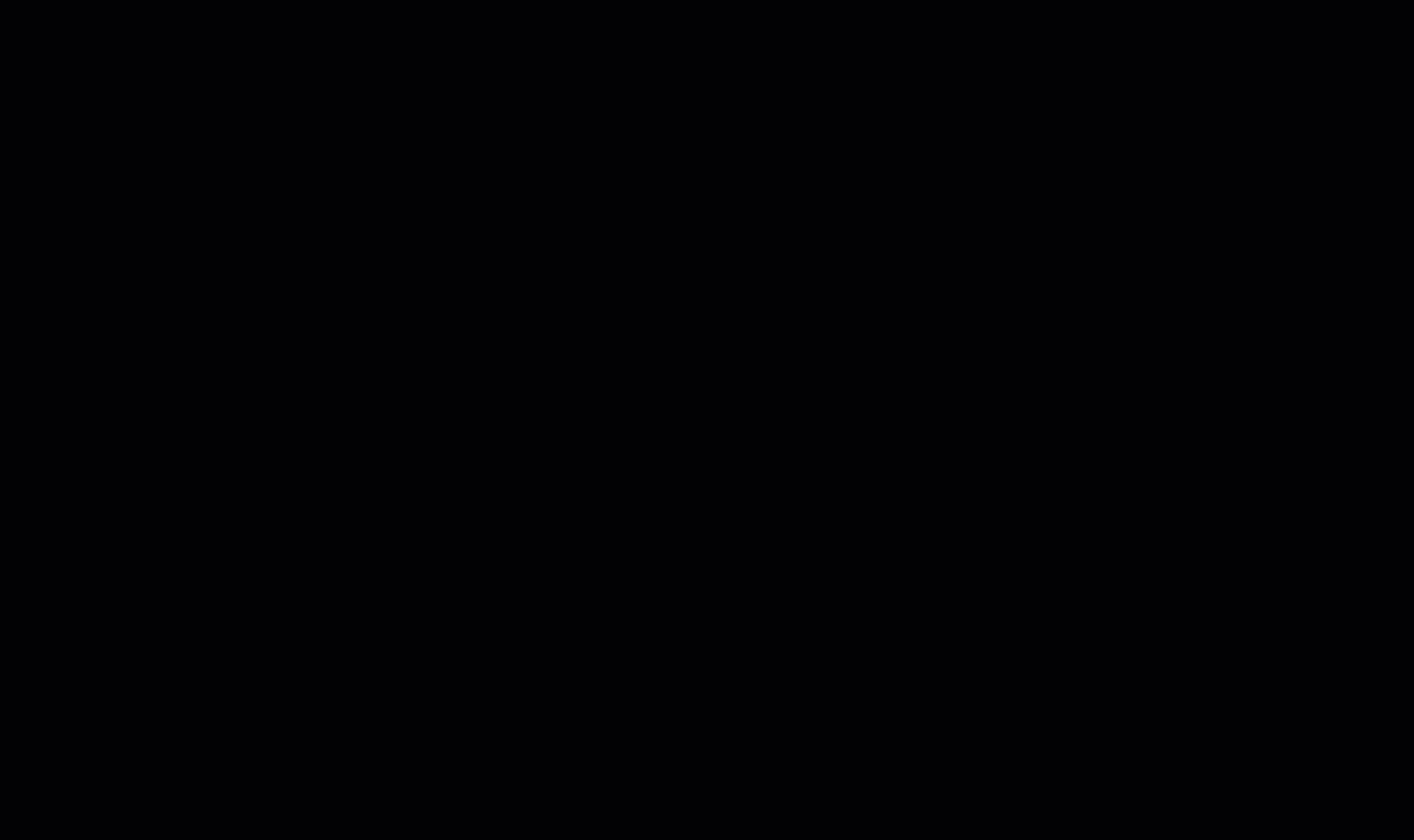
Creazione di un processo di etichettatura per la classificazione del Multi-Label testo (API)
Per creare un processo di etichettatura con classificazione del testo multietichetta, utilizza l' SageMaker operazione API. CreateLabelingJob Questa API definisce questa operazione per tutti gli AWS SDK. Per visualizzare l'elenco degli SDK specifici del linguaggio supportati per questa operazione, consulta la sezione See Also di CreateLabelingJob.
Segui queste istruzioni su Creare un processo di etichettatura (API) ed effettua le seguenti operazioni durante la configurazione della richiesta:
-
Pre-annotation Le funzioni Lambda per questo tipo di attività terminano con.
PRE-TextMultiClassMultiLabelPer trovare l'ARN Lambda di pre-annotazione per la tua regione, consulta. PreHumanTaskLambdaArn -
Annotation-consolidation Le funzioni Lambda per questo tipo di attività terminano con.
ACS-TextMultiClassMultiLabelPer trovare l'ARN Lambda di consolidamento delle annotazioni per la tua regione, consulta. AnnotationConsolidationLambdaArn
Di seguito è riportato un esempio di richiesta AWS Python SDK (Boto3)
response = client.create_labeling_job( LabelingJobName='example-multi-label-text-classification-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://bucket/path/manifest-with-input-data.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://bucket/path/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/path/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:region:*:workteam/private-crowd/*', 'UiConfig': { 'UiTemplateS3Uri':'s3://bucket/path/custom-worker-task-template.html'}, 'PreHumanTaskLambdaArn': 'arn:aws:lambda::function:PRE-TextMultiClassMultiLabel, 'TaskKeywords': ['Text Classification', ], 'TaskTitle':'Multi-label text classification task', 'TaskDescription':'Select all labels that apply to the text shown', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-TextMultiClassMultiLabel' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
Crea un modello per la classificazione del testo Multi-label
Se stai creando un'attività di etichettatura utilizzando l'API, devi fornire un modello di attività del worker in UiTemplateS3Uri. Copia e modifica il modello seguente. Modifica solo short-instructions, full-instructions e header.
Carica questo modello in S3 e fornisci l'URI S3 per questo file in UiTemplateS3Uri.
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier-multi-select name="crowd-classifier-multi-select" categories="{{ task.input.labels | to_json | escape }}" header="Please identify all classes in the below text" > <classification-target style="white-space: pre-wrap"> {{ task.input.taskObject }} </classification-target> <full-instructions header="Classifier instructions"> <ol><li><strong>Read</strong> the text carefully.</li> <li><strong>Read</strong> the examples to understand more about the options.</li> <li><strong>Choose</strong> the appropriate labels that best suit the text.</li></ol> </full-instructions> <short-instructions> <p>Enter description of the labels that workers have to choose from</p> <p><br></p> <p><br></p><p>Add examples to help workers understand the label</p> <p><br></p><p><br></p><p><br></p><p><br></p><p><br></p> </short-instructions> </crowd-classifier-multi-select> </crowd-form>
Per informazioni su come creare un modello personalizzato, consulta Flussi di lavoro di etichettatura personalizzati.
Multi-label Dati di output per la classificazione del testo
Dopo aver creato un processo di etichettatura di classificazione del testo multi-etichetta, i dati di output si troveranno nel bucket Amazon S3 specificato nel parametro S3OutputPath quando si utilizza l'API o nel campo Posizione del set di dati di output della sezione Panoramica processo della console.
Per ulteriori informazioni sul file manifest di output generato da Ground Truth e sulla struttura di file utilizzata da Ground Truth per archiviare i dati di output, consulta Etichettatura dei dati di output di un processo.
Per vedere un esempio di file manifest di output per il processo di etichettatura di classificazione del testo multi-etichetta, consulta Multi-label classificazione, lavoro, output.
