Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Modelli di test con varianti di produzione
I data scientist e i tecnici spesso cercano di migliorare le prestazioni nei flussi di lavoro di ML di produzione utilizzando vari modi, ad esempio Ottimizzazione automatica dei modelli con AI SageMaker, eseguendo l’addestramento con dati aggiuntivi o più recenti, migliorando la selezione delle funzionalità, utilizzando istanze meglio aggiornate e container di distribuzione. Puoi utilizzare le varianti di produzione per confrontare modelli, istanze e container e scegliere il candidato con le migliori prestazioni per rispondere alle richieste di inferenza.
Con gli endpoint multivarianti di SageMaker intelligenza artificiale puoi distribuire le richieste di invocazione degli endpoint su più varianti di produzione fornendo la distribuzione del traffico per ciascuna variante, oppure puoi richiamare una variante specifica direttamente per ogni richiesta. In questo argomento esaminiamo entrambi i metodi di test dei modelli ML.
Argomenti
Test dei modelli con la distribuzione del traffico
Per testare più modelli con la distribuzione del traffico, occorre specificare la percentuale di traffico che viene instradato a ciascun modello, indicando il peso per ogni variante di produzione nella configurazione dell'endpoint. Per informazioni, consulta CreateEndpointConfig. Il diagramma seguente ne mostra il funzionamento in modo più dettagliato.
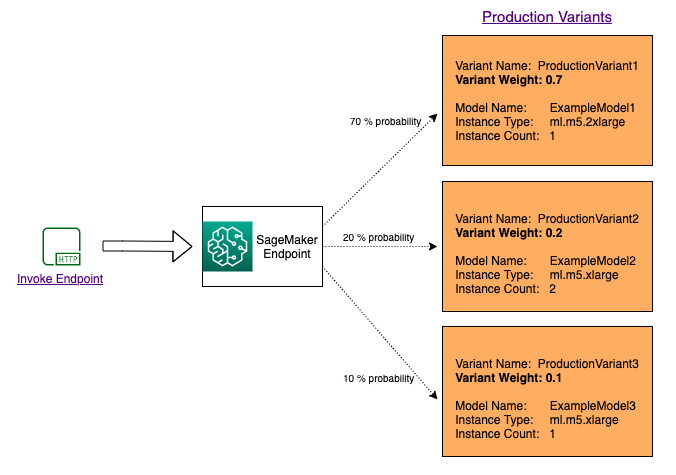
Test dei modelli con l'invocazione di varianti specifiche
Per testare più modelli richiamando modelli specifici per ogni richiesta, specifica la versione specifica del modello che desideri richiamare fornendo un valore per il TargetVariant parametro quando chiami. InvokeEndpoint SageMaker L'intelligenza artificiale garantisce che la richiesta venga elaborata dalla variante di produzione specificata. Se con la distribuzione del traffico già applicata specifichi un valore per il parametro TargetVariant, il routing di destinazione sostituisce la distribuzione casuale del traffico. Il diagramma seguente ne mostra il funzionamento in modo più dettagliato.
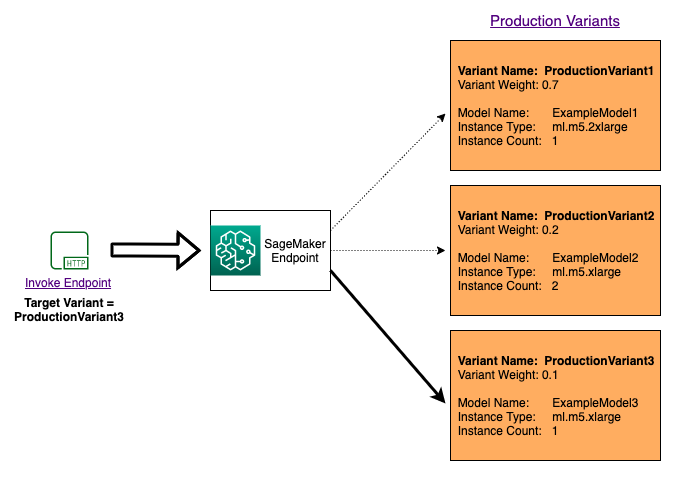
Esempio di A/B test del modello
L'esecuzione di A/B test tra un nuovo modello e un vecchio modello con traffico di produzione può essere una fase finale efficace del processo di convalida di un nuovo modello. Durante i A/B test, si testano diverse varianti dei modelli e si confrontano le prestazioni di ciascuna variante. Se la versione più recente del modello offre prestazioni migliori rispetto alla versione già esistente, sostituisci la versione precedente del modello con la nuova versione in produzione.
L'esempio seguente mostra come eseguire il test dei A/B modelli. Per un notebook di esempio che implementa questo esempio, vedi "A/B Test di modelli ML in produzione
Fase 1: creazione e distribuzione di modelli
Definisci innanzitutto dove si trovano i modelli Amazon S3. Queste posizioni verranno utilizzate quando implementi i modelli nelle fasi successive:
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
Quindi, crei gli oggetti del modello con i dati dell'immagine e del modello. Questi oggetti del modello vengono utilizzati per distribuire le varianti di produzione in un endpoint. I modelli sono sviluppati tramite l’addestramento dei modelli ML con diversi set di dati, algoritmi o framework ML e diversi iperparametri:
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
Ora crei due varianti di produzione, ognuna con propri requisiti di modello e risorse (tipo di istanza e conteggi). In tal modo puoi testare anche i modelli in diversi tipi di istanza.
Imposta un peso iniziale pari a 1 per entrambe le varianti. Ciò significa che il 50% delle richieste va a Variant1 e il restante 50% delle richieste va a Variant2. La somma dei pesi di entrambe le varianti è 2 e ogni variante ha un'assegnazione di peso pari a 1. Ciò significa che ogni variante riceve 1/2, o il 50%, del traffico totale.
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
Finalmente siamo pronti a implementare queste varianti di produzione su un endpoint di SageMaker intelligenza artificiale.
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
Fase 2: invocazione dei modelli distribuiti
A questo punto puoi inviare le richieste all'endpoint per ottenere le inferenze in tempo reale. Utilizzi sia la distribuzione del traffico che l'indirizzamento diretto.
Per prima cosa usi la distribuzione del traffico configurata nella fase precedente. Ogni risposta di inferenza contiene il nome della variante di produzione che elabora la richiesta e pertanto puoi osservare che il traffico verso le due varianti di produzione è approssimativamente uguale.
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker L'intelligenza artificiale emette metriche come Latency e Invocations per ogni variante in Amazon. CloudWatch Per un elenco completo delle metriche emesse dall' SageMaker IA, consulta. Metriche di Amazon SageMaker AI in Amazon CloudWatch Facciamo una query CloudWatch per ottenere il numero di invocazioni per variante, per mostrare come le invocazioni sono suddivise tra le varianti per impostazione predefinita:
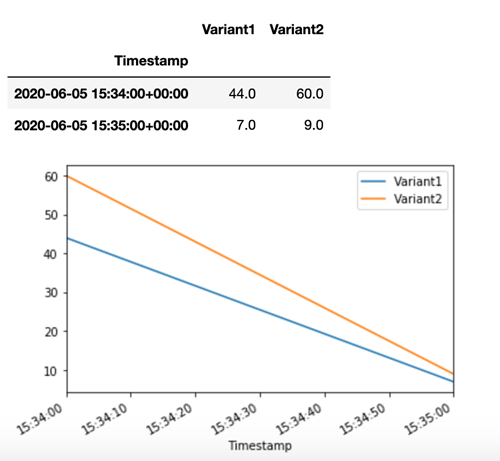
Ora invochi una versione specifica del modello definendo Variant1 come TargetVariant nella chiamata a invoke_endpoint.
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
Per confermare che tutte le nuove chiamate sono state elaborate daVariant1, possiamo eseguire una query CloudWatch per ottenere il numero di invocazioni per variante. Puoi notare che per le invocazioni più recenti (con l'ultimo timestamp), tutte le richieste sono state elaborate da Variant1, come avevi specificato. Non sono presenti invocazioni eseguite per Variant2.
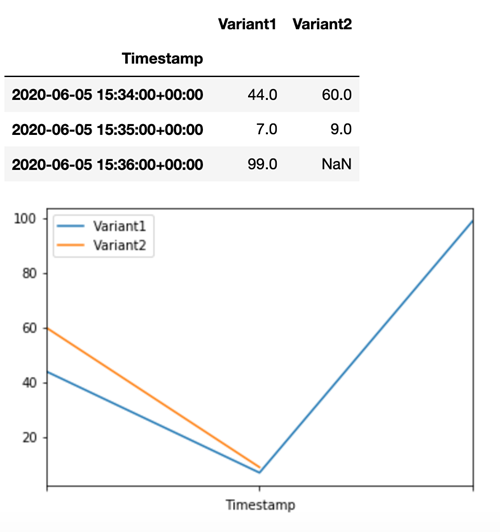
Fase 3: valutazione delle prestazioni del modello
Per vedere quale versione del modello offre prestazioni migliori, valutiamo l'accuratezza, la precisione, il richiamo, il punteggio F1 e il ricevitore che opera charactersistic/Area sotto la curva per ciascuna variante. Per prima cosa, osserva i parametri per Variant1:
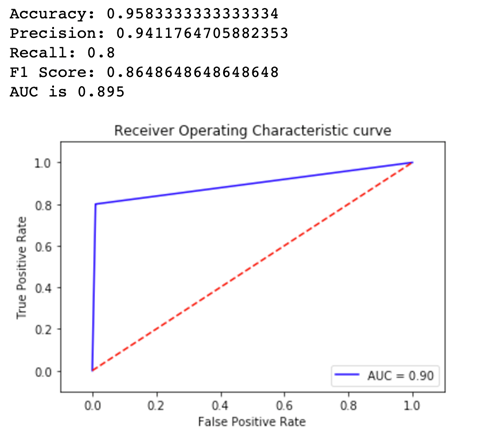
Ora osserva i parametri per Variant2:
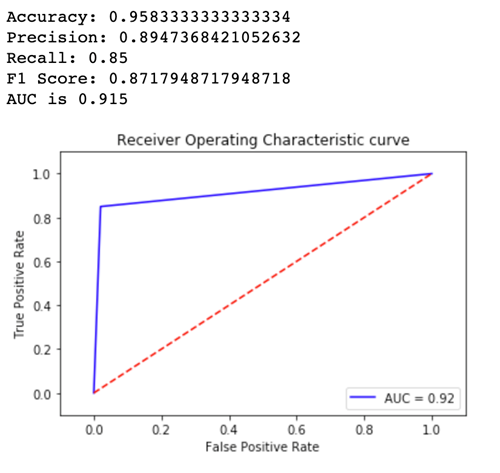
Per la maggior parte dei parametri definiti, Variant2 ha le prestazioni migliori e pertanto è la versione ottimale da utilizzare in produzione.
Fase 4: incremento del traffico verso il modello migliore
Ora che hai determinato che Variant2 funziona meglio di Variant1, puoi indirizzarvi più traffico. Possiamo continuare a utilizzare per TargetVariant richiamare una variante di modello specifica, ma un approccio più semplice consiste nell'aggiornare i pesi assegnati a ciascuna variante chiamando. UpdateEndpointWeightsAndCapacities In questo modo la distribuzione del traffico alle varianti di produzione viene modificata senza richiedere aggiornamenti per l'endpoint. Ricordiamo dalla sezione di configurazione che abbiamo impostato i pesi delle varianti per dividere il traffico. 50/50 Le CloudWatch metriche per le chiamate totali per ciascuna variante riportate di seguito ci mostrano i modelli di invocazione per ciascuna variante:
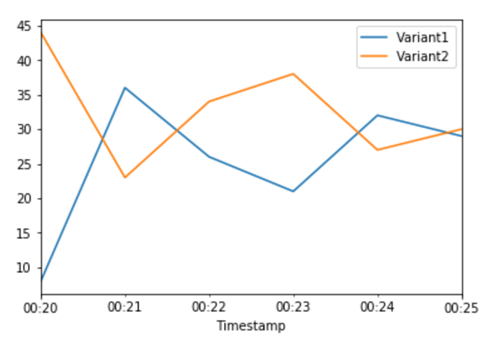
Ora spostiamo il 75% del traffico Variant2 assegnando nuovi pesi a ciascuna variante che utilizza. UpdateEndpointWeightsAndCapacities SageMaker L'intelligenza artificiale ora invia il 75% delle richieste di inferenza Variant2 e il restante 25% delle richieste a. Variant1
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
Le CloudWatch metriche relative alle invocazioni totali per ciascuna variante mostrano un numero maggiore di invocazioni per: Variant2 Variant1
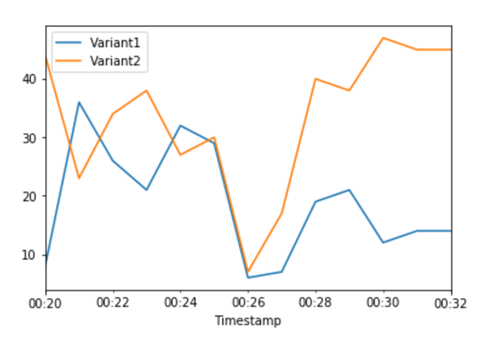
Continua a monitorare i parametri e quando ritieni che le prestazioni di una variante siano soddisfacenti, instrada il 100% del traffico verso quella variante. Puoi utilizzare UpdateEndpointWeightsAndCapacities per aggiornare le assegnazioni del traffico alle varianti. Il peso per Variant1 è impostato su 0 e il peso per Variant2 è impostato su 1. SageMaker L'IA ora invia il 100% di tutte le richieste di inferenza aVariant2.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
Le CloudWatch metriche per le chiamate totali per ciascuna variante mostrano che tutte le richieste di inferenza vengono elaborate da Variant2 e che non vi sono richieste di inferenza elaborate da. Variant1
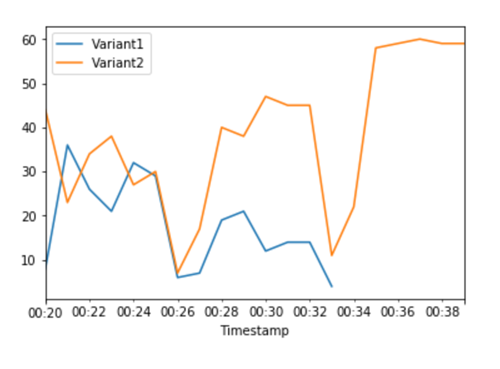
A questo punto puoi aggiornare in modo sicuro l'endpoint ed eliminare Variant1 dall'endpoint. Inoltre puoi continuare a testare i nuovi modelli in produzione aggiungendo nuove varianti all'endpoint e ripetendo le fasi da 2 a 4.
