Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione e utilizzo di un flusso di Data Wrangler
Usa un flusso Amazon SageMaker Data Wrangler o un flusso di dati per creare e modificare una pipeline di preparazione dei dati. Il flusso di dati collega i set di dati, le trasformazioni e le analisi, o fasi, che crei e può essere utilizzato per definire la pipeline.
Istanze
Quando crei un flusso Data Wrangler in Amazon SageMaker Studio Classic, Data Wrangler utilizza un'istanza Amazon EC2 per eseguire le analisi e le trasformazioni nel flusso. Per impostazione predefinita, Data Wrangler utilizza l'istanza m5.4xlarge. Le istanze m5 sono istanze generiche che forniscono un equilibrio tra elaborazione e memoria. È possibile utilizzare le istanze m5 per una varietà di carichi di lavoro di calcolo.
Data Wrangler ti offre anche la possibilità di utilizzare istanze r5. Le istanze r5 sono progettate per offrire prestazioni veloci nell'elaborazione di set di dati di grandi dimensioni in memoria.
Ti consigliamo di scegliere un'istanza che sia ottimizzata al meglio in base ai tuoi carichi di lavoro. Ad esempio, la r5.8xlarge potrebbe avere un prezzo più elevato rispetto alla m5.4xlarge, ma la r5.8xlarge potrebbe essere ottimizzata meglio per i tuoi carichi di lavoro. Con istanze meglio ottimizzate, puoi eseguire i flussi di dati in meno tempo a costi inferiori.
Nella tabella seguente vengono visualizzate le istanze che è possibile utilizzare per eseguire il flusso flusso di Data Wrangler.
| Istanza | VPCU | Memoria |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.8xlarge | 32 | 128 GiB |
| ml.m5.16xlarge | 64 |
256 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
| r5.4xlarge | 16 | 128 GiB |
| r5.8xlarge | 32 | 256 GiB |
| r5.24xlarge | 96 | 768 GiB |
Per ulteriori informazioni sulle istanze r5, consultare la sezione relativa alle Istanze Amazon EC2 R5
A ogni flusso di Data Wrangler è associata un'istanza Amazon EC2. Potresti avere più flussi associati a una singola istanza.
Per ogni file di flusso, puoi cambiare facilmente il tipo di istanza. Se cambi il tipo di istanza, l'istanza che hai usato per eseguire il flusso continua a funzionare.
Per cambiare il tipo di istanza del flusso, procedi come segue.
-
Scegli l’icona Terminali e kernel in esecuzione (
 ).
). -
Passa all'istanza che stai utilizzando e selezionala.
-
Sceglie il tipo di istanza da utilizzare.
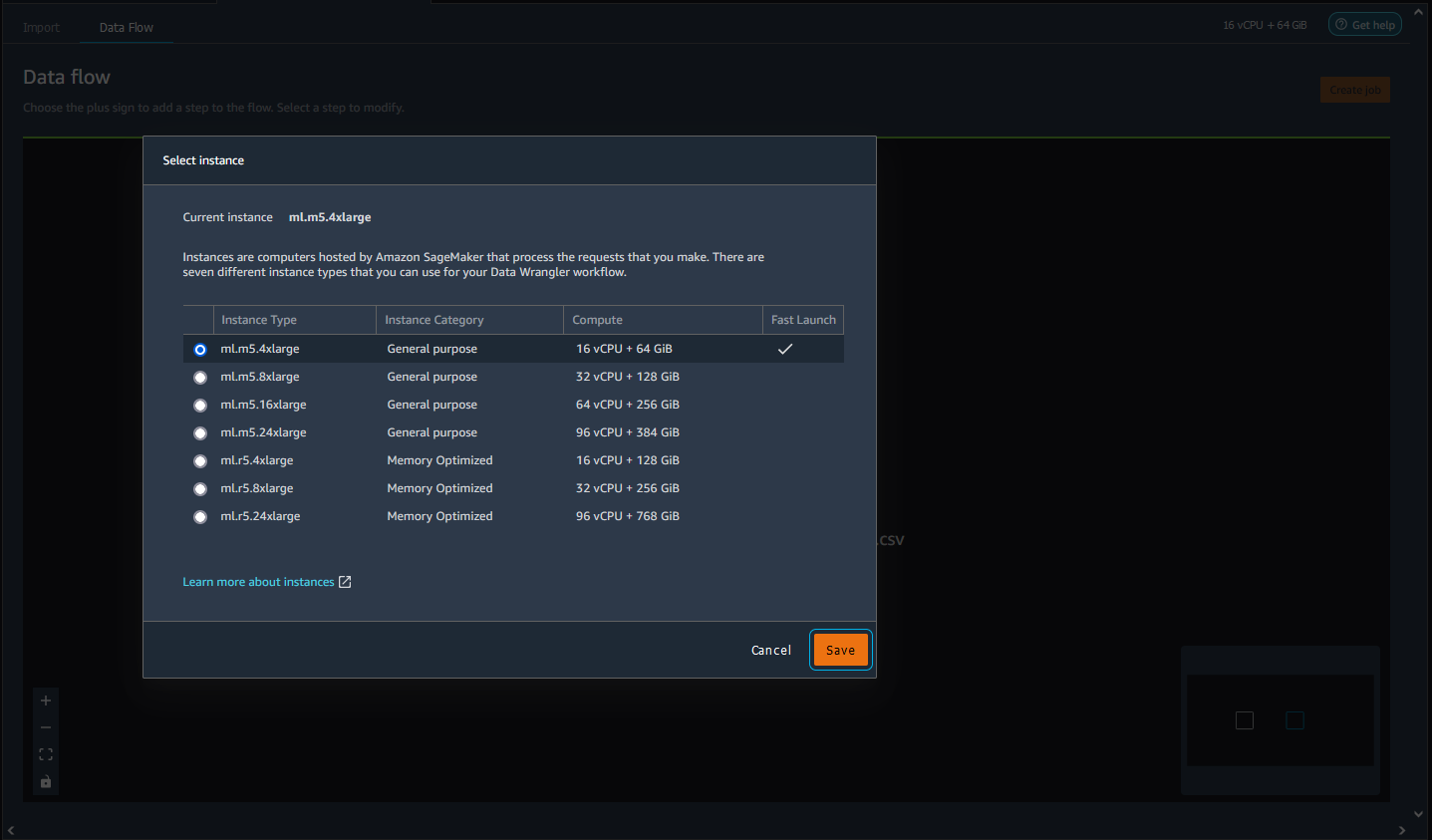
-
Scegli Save (Salva).
Saranno addebitati i costi per tutte le istanze in esecuzione. Per evitare di incorrere in costi aggiuntivi, chiudi manualmente le istanze che non utilizzi. Per chiudere un'istanza in esecuzione, utilizza la procedura seguente.
Per chiudere un'istanza in esecuzione.
-
Scegli l'icona dell'istanza. L'immagine seguente mostra dove selezionare l'icona ISTANZE IN ESECUZIONE.
-
Scegli Chiudi sessione accanto all'istanza che desideri chiudere.
Se chiudi un'istanza utilizzata per eseguire un flusso, temporaneamente non puoi accedere al flusso. Se ricevi un errore durante il tentativo di aprire il flusso che esegue un'istanza che hai chiuso in precedenza, attendi 5 minuti e prova ad aprirla di nuovo.
Quando esporti il flusso di dati in una posizione come Amazon Simple Storage Service o Amazon SageMaker Feature Store, Data Wrangler esegue un processo di SageMaker elaborazione Amazon. Puoi utilizzare una delle seguenti istanze per il processo di elaborazione. Per ulteriori informazioni sull'esportazione dei dati, consulta Esportazione.
| Istanza | VPCU | Memoria |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.12xlarge | 48 |
192 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
Interfaccia flusso di dati
Quando importi un set di dati, il set di dati originale viene visualizzato nel flusso di dati e viene denominato Origine. Se hai attivato il campionamento quando hai importato i dati, questo set di dati è denominato Origine - campionata. Data Wrangler deduce automaticamente i tipi di ogni colonna del set di dati e crea un nuovo dataframe denominato Tipi di dati. Puoi selezionare questo frame per aggiornare i tipi di dati dedotti. Dopo aver caricato un singolo set di dati, vengono visualizzati risultati simili a quelli mostrati nell'immagine seguente:
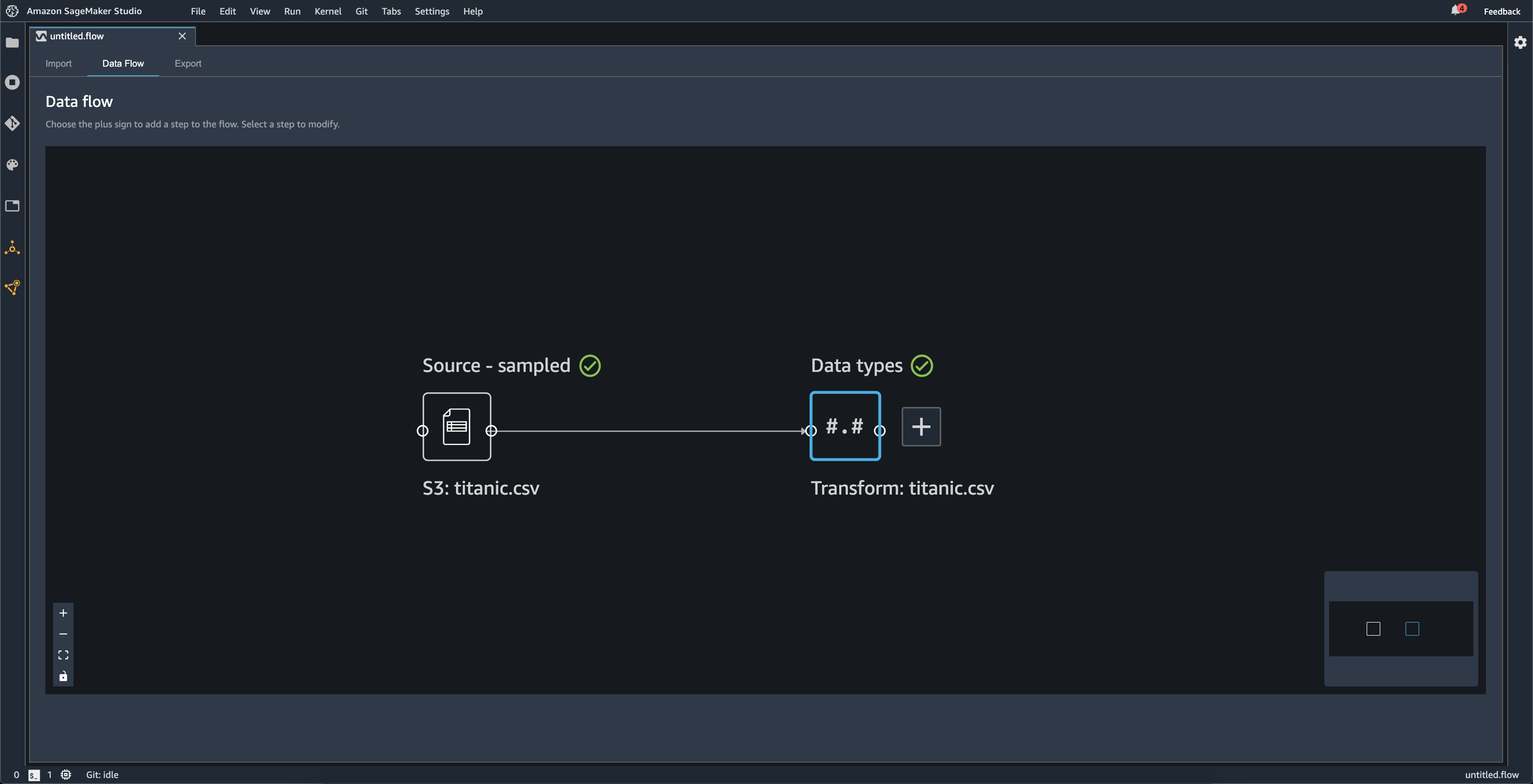
Ogni volta che aggiungi una fase di trasformazione, crei un nuovo dataframe. Quando più fasi di trasformazione (diverse da Unisci o Concatena) vengono aggiunte allo stesso set di dati, vengono impilate.
Unisci e Concatena creano fasi autonome che contengono il nuovo set di dati unito o concatenato.
Il diagramma seguente mostra un flusso di dati con un'unione tra due set di dati e due stack di fasi. Il primo stack (Fasi (2)) aggiunge due trasformazioni al tipo dedotto nel set di dati Tipi di dati. Lo stack downstream, o lo stack a destra, aggiunge trasformazioni al set di dati risultanti da un'unione denominata demo-join.
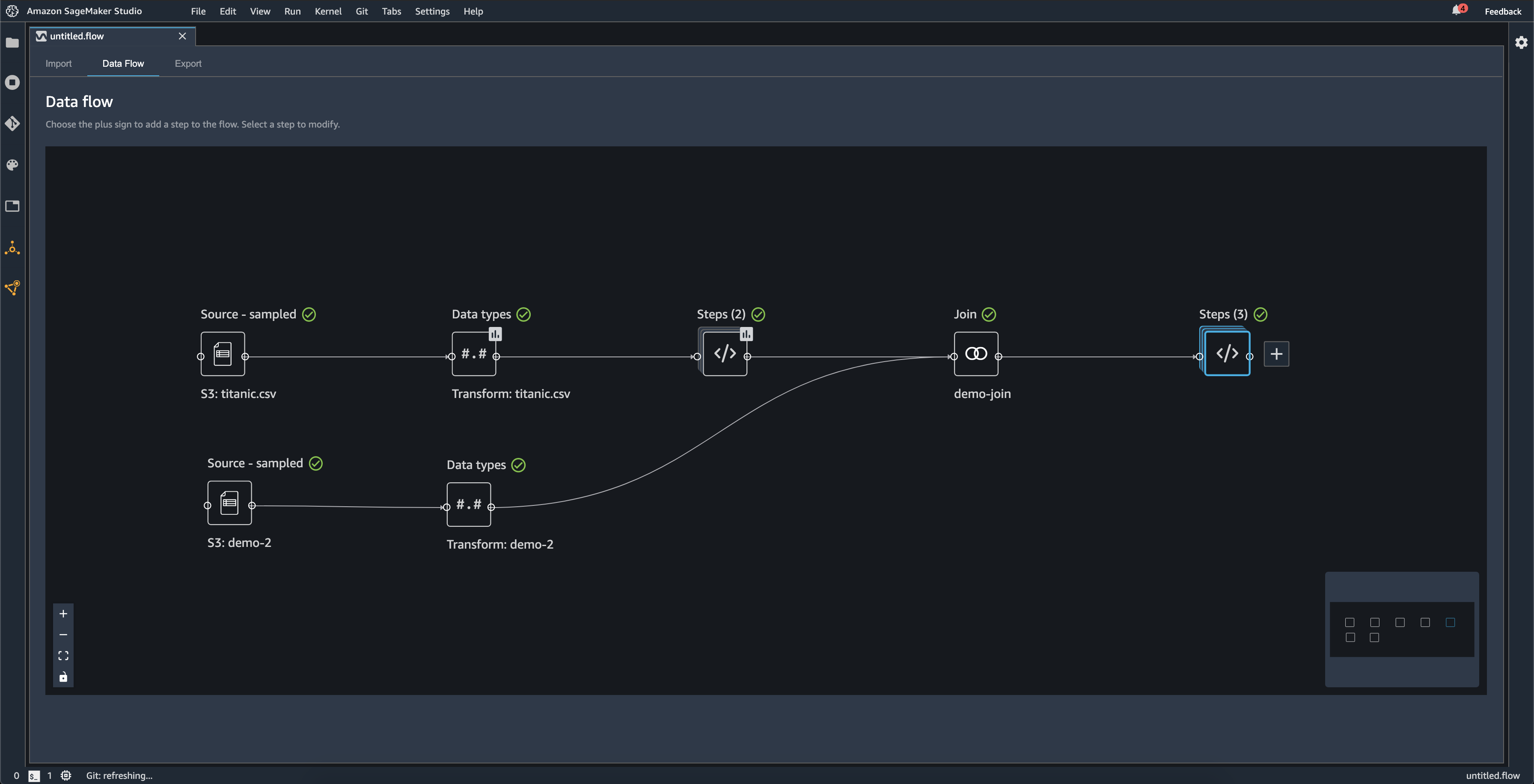
La piccola casella grigia nell'angolo in basso a destra del flusso di dati fornisce una panoramica del numero di stack e fasi del flusso e del layout del flusso. Il riquadro più chiaro all'interno del riquadro grigio indica le fasi incluse nella visualizzazione dell'interfaccia utente. Puoi utilizzare questa casella per visualizzare le sezioni del flusso di dati che non rientrano nella visualizzazione dell'interfaccia utente. Usa l'icona Adatta allo schermo (
 ) per adattare tutte le fasi e i set di dati alla visualizzazione dell'interfaccia utente.
) per adattare tutte le fasi e i set di dati alla visualizzazione dell'interfaccia utente.
La barra di navigazione in basso a sinistra include icone che puoi utilizzare per ingrandire (
 ) e rimpicciolire (
) e rimpicciolire (
 ) il flusso di dati e ridimensionarlo per adattarlo allo schermo (
). Usa l'icona del lucchetto (
) il flusso di dati e ridimensionarlo per adattarlo allo schermo (
). Usa l'icona del lucchetto (
 ) per bloccare e sbloccare la posizione di ogni fase sullo schermo.
) per bloccare e sbloccare la posizione di ogni fase sullo schermo.
Aggiungere una fase al flusso di dati
Seleziona + accanto a qualsiasi set di dati o fase aggiunti in precedenza, quindi seleziona una delle seguenti opzioni:
-
Modifica i tipi di dati (solo per una fase Tipi di dati): se non hai aggiunto alcuna trasformazione a una fase sui Tipi di dati, puoi selezionare Modifica tipi di dati per aggiornare i tipi di dati dedotti da Data Wrangler durante l'importazione del set di dati.
-
Aggiungi trasformazione: aggiunge una nuova fase di trasformazione. Consulta Trasformazione dei dati per saperne di più sulle trasformazioni dei dati che puoi aggiungere.
-
Aggiungi analisi: aggiunge un'analisi. Puoi utilizzare questa opzione per analizzare i dati in qualsiasi momento del flusso di dati. Quando aggiungi una o più analisi a una fase, in quella fase viene visualizzata un'icona di analisi (
 ). Consulta Analisi e visualizzazione per saperne di più sulle analisi che puoi aggiungere.
). Consulta Analisi e visualizzazione per saperne di più sulle analisi che puoi aggiungere. -
Unisci: unisce due set di dati e aggiunge il set di dati risultante al flusso di dati. Per ulteriori informazioni, consulta Unire i set di dati.
-
Concatena: concatena due set di dati e aggiunge il set di dati risultante al flusso di dati. Per ulteriori informazioni, consulta Concatena i set di dati.
Eliminare una fase dal flusso di dati
Per eliminare una fase, seleziona la fase e scegli Elimina. Se il nodo è un nodo con un solo input, si elimina solo la fase selezionata. L'eliminazione di una fase con un solo input non elimina le fasi successive. Se stai eliminando una fase per un nodo di origine, join o concatenazione, vengono eliminata anche tutte le fasi successive.
Per eliminare una fase da uno stack di fasi, seleziona lo stack e quindi seleziona la fase che desideri eliminare.
Puoi utilizzare una delle procedure seguenti per eliminare una fase senza eliminare le fasi a valle.
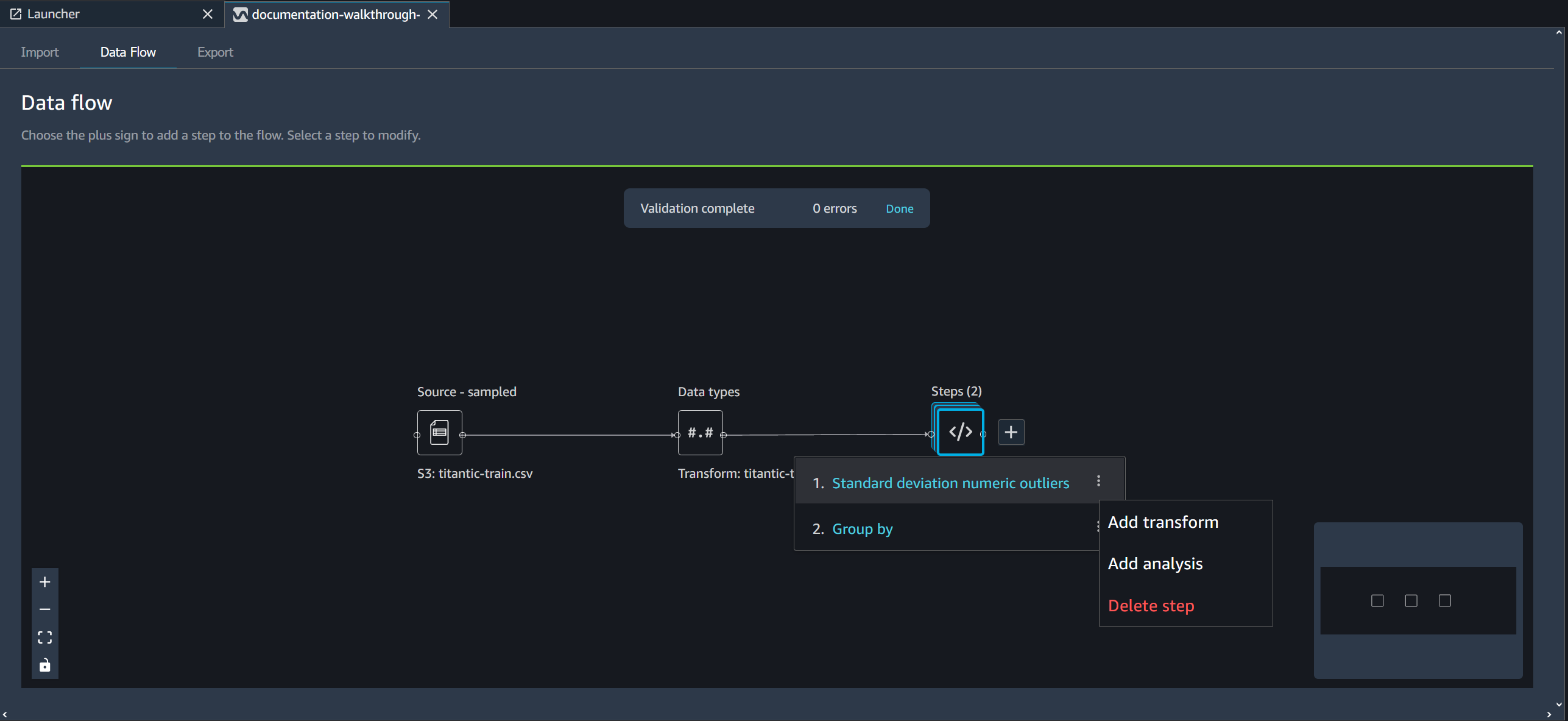

Modificare una fase del flusso di Data Wrangler
Puoi modificare ogni fase che hai aggiunto al flusso di Data Wrangler. Modificando le fasi, puoi modificare le trasformazioni o i tipi di dati delle colonne. Puoi modificare le fasi per apportare modifiche con cui eseguire analisi migliori.
Esistono molti modi per modificare una fase. Alcuni esempi includono la modifica del metodo di imputazione o la modifica della soglia per considerare un valore come un valore anomalo.
Per modificare una fase, utilizza la procedura seguente.
Per modificare una fase, esegui le operazioni descritte di seguito.
-
Scegli una fase nel flusso di Data Wrangler per aprire la visualizzazione della tabella.
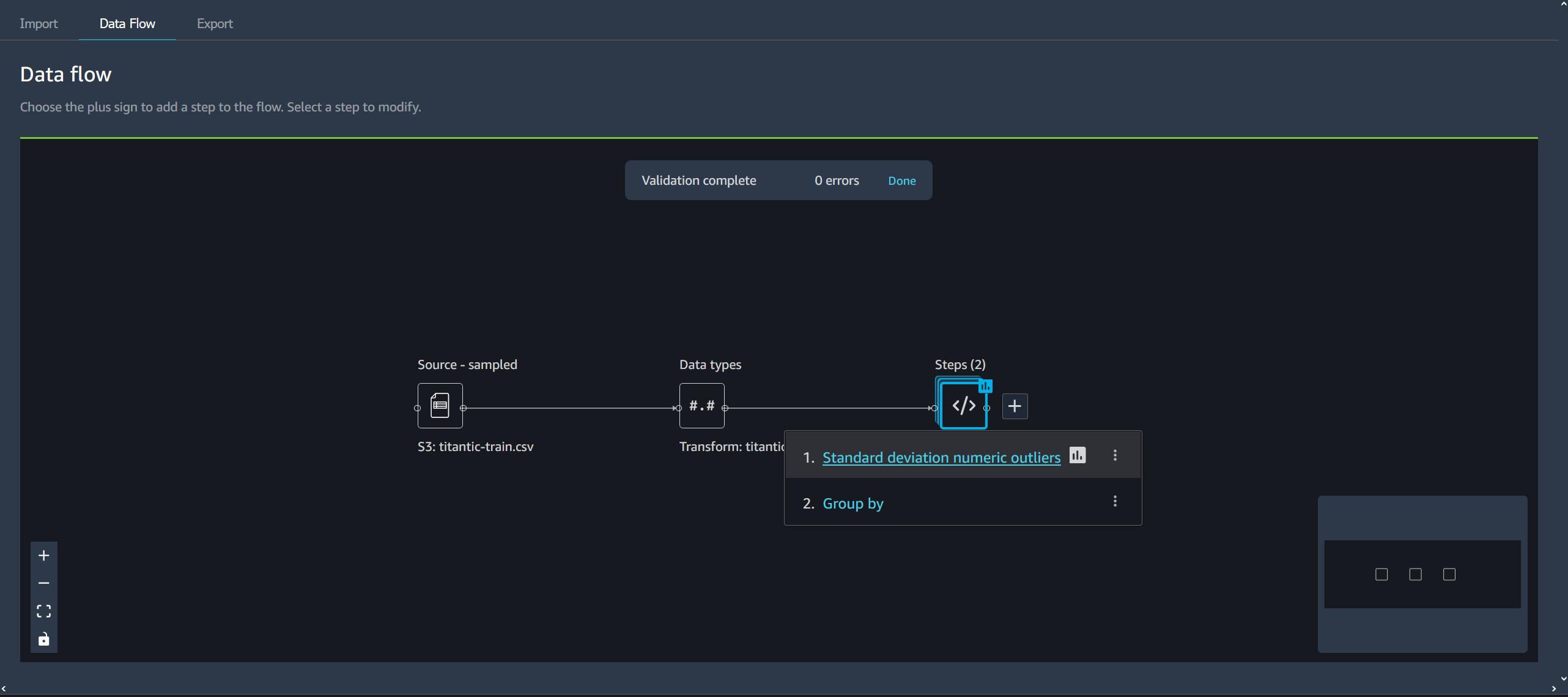
-
Scegli una fase del flusso di dati.
-
Modifica la fase.
La seguente immagina mostra un esempio di modifica di una fase.
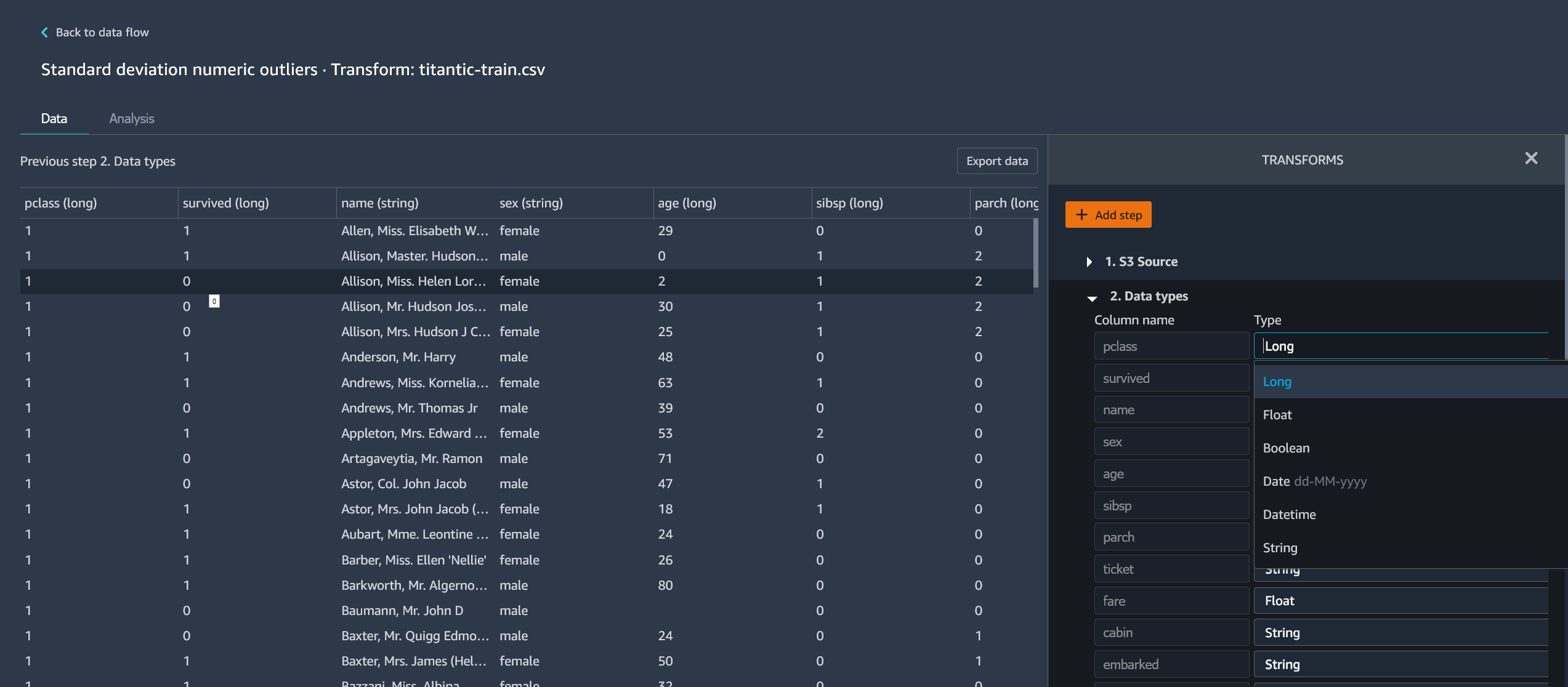
Nota
Puoi utilizzare gli spazi condivisi all'interno del tuo dominio Amazon SageMaker AI per lavorare in modo collaborativo sui flussi Data Wrangler. All'interno di uno spazio condiviso, tu e i tuoi collaboratori potete modificare un file di flusso in tempo reale. Tuttavia, né tu né i tuoi collaboratori potete vedere le modifiche in tempo reale. Quando qualcuno apporta una modifica al flusso di Data Wrangler, deve salvarla immediatamente. Quando qualcuno salva un file, un collaboratore non sarà in grado di vederlo a meno che non chiuda il file e lo riapra. Tutte le modifiche che non vengono salvate da una persona vengono sovrascritte dalla persona che le ha salvate.
