Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Che cos'è Step Functions?
Gestione dello stato e trasformazione dei dati
Scopri come passare dati tra stati con variabili e Trasformare dati con. JSONata
Con AWS Step Functions, puoi creare flussi di lavoro, chiamati anche, per creare applicazioni distribuiteMacchine a stati, automatizzare processi, orchestrare microservizi e creare pipeline di dati e apprendimento automatico.
Step Functions si basa su macchine e attività a stati. In Step Functions, le macchine a stati sono chiamate flussi di lavoro, che sono una serie di passaggi guidati dagli eventi. Ogni fase di un flusso di lavoro è denominata stato. Ad esempio, uno stato Task rappresenta un'unità di lavoro svolta da un altro AWS servizio, ad esempio chiamarne un altro Servizio AWS o un'API. Le istanze di flussi di lavoro in esecuzione che eseguono attività sono chiamate esecuzioni in Step Functions.
Il lavoro nelle attività della macchina a stati può essere svolto anche utilizzando lavoratori Attività che esistono al di fuori di Step Functions.
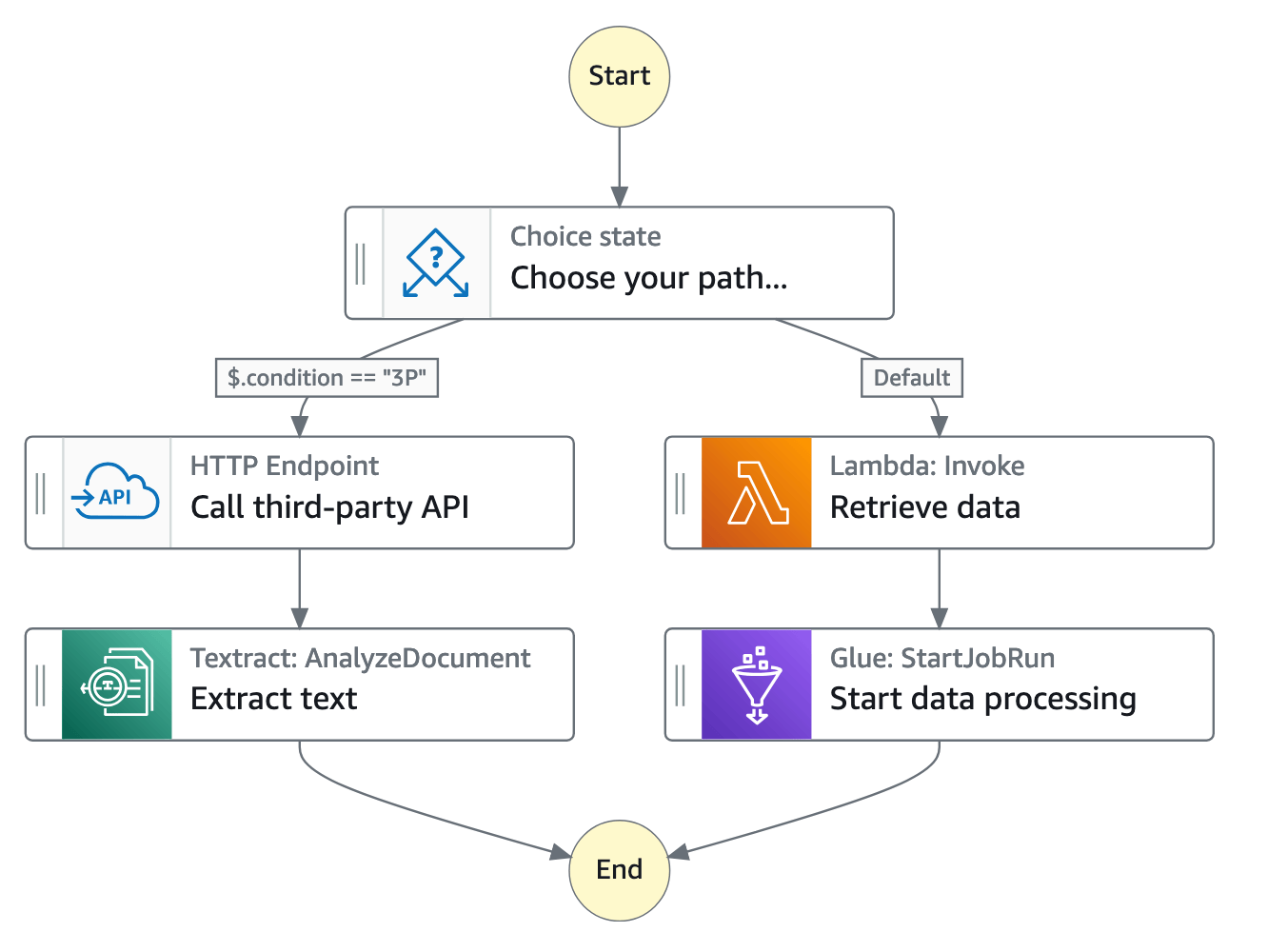
Nella console di Step Functions, puoi visualizzare, modificare ed eseguire il debug del flusso di lavoro della tua applicazione. Puoi esaminare lo stato di ogni fase del flusso di lavoro per assicurarti che l'applicazione funzioni nell'ordine e come previsto.
A seconda del caso d'uso, è possibile disporre di AWS servizi di chiamata Step Functions, come Lambda, per eseguire attività. È possibile disporre di AWS servizi di controllo Step Functions AWS Glue, ad esempio per creare flussi di lavoro di estrazione, trasformazione e caricamento. È possibile anche creare flussi di lavoro automatizzati e di lunga durata per applicazioni che richiedono l'interazione umana.
Per un elenco completo delle AWS regioni in cui è disponibile Step Functions, consulta la Tabella delle AWS
regioni
Scopri come usare Step Functions
Inizia con le Tutorial sulle nozioni di base in questa guida. Per argomenti e casi d'uso avanzati, consulta i moduli di The Step Functions Workshop
Tipi di flussi di lavoro Standard ed Express
Step Functions ha due tipi di flussi di lavoro:
-
I flussi di lavoro standard sono ideali per flussi di lavoro di lunga durata e verificabili, in quanto mostrano la cronologia di esecuzione e il debug visivo.
I flussi di lavoro standard prevedono l'esecuzione del flusso di lavoro esattamente una volta e possono durare fino a un anno. Ciò significa che ogni fase di un flusso di lavoro Standard verrà eseguita esattamente una volta.
-
I flussi di lavoro Express sono ideali per high-event-rate carichi di lavoro, come l'elaborazione di dati in streaming e l'ingestione di dati IoT.
I flussi di lavoro Express prevedono l'esecuzione at-least-oncedel flusso di lavoro e possono durare fino a cinque minuti. Ciò significa che uno o più passaggi in un Express Workflow possono potenzialmente essere eseguiti più di una volta, mentre ogni passaggio del flusso di lavoro viene eseguito almeno una volta.
| Flussi di lavoro standard | Flussi di lavoro rapidi |
|---|---|
| Velocità di esecuzione di 2.000 al secondo | Frequenza di esecuzione di 100.000 al secondo |
| Tasso di transizione tra stati di 4.000 al secondo | Tasso di transizione statale quasi illimitato |
| Prezzo per transizione statale | Prezzo in base al numero e alla durata delle esecuzioni |
| Mostra la cronologia delle esecuzioni e il debug visivo | Mostra la cronologia di esecuzione e il debug visivo in base al livello di registro |
| Vedi la cronologia delle esecuzioni in Step Functions |
Invia la cronologia delle esecuzioni a CloudWatch |
| Supporta le integrazioni con tutti i servizi. Supporta integrazioni ottimizzate con alcuni servizi. |
Supporta le integrazioni con tutti i servizi. |
| Modello Support Request Response per tutti i servizi Supporta i modelli Run a Job e/o Wait for Callback in servizi specifici (vedi la sezione seguente per i dettagli) |
Modello Support Request Response per tutti i servizi |
Per ulteriori informazioni sui prezzi di Step Functions e sulla scelta del tipo di flusso di lavoro, consulta quanto segue:
Integrazione con altri servizi
Step Functions si integra con più AWS servizi. Per chiamare altri AWS servizi, puoi utilizzare due tipi di integrazione:
-
AWS Le integrazioni SDK offrono un modo per chiamare qualsiasi AWS servizio direttamente dalla tua macchina a stati, dandoti accesso a migliaia di azioni API.
-
Le integrazioni ottimizzate offrono opzioni personalizzate per l'utilizzo di tali servizi nelle vostre macchine a stati.
Per combinare Step Functions con altri servizi, esistono tre modelli di integrazione dei servizi:
-
Richiesta di risposta (impostazione predefinita)
Chiama un servizio e lascia che Step Functions passi allo stato successivo dopo aver ricevuto una risposta HTTP.
-
Chiama un servizio e chiedi a Step Functions di attendere il completamento di un lavoro.
-
Attendi una richiamata con un task token (. waitForTaskToken)
Chiama un servizio con un task token e fai in modo che Step Functions attenda che il task token ritorni con una callback.
I flussi di lavoro standard e i flussi di lavoro Express supportano le stesse integrazioni ma non gli stessi modelli di integrazione.
-
I flussi di lavoro standard supportano le integrazioni Request Response. Alcuni servizi supportano Run a Job (.sync) o Wait for Callback (. waitForTaskToken) ed entrambi in alcuni casi. Consulta la seguente tabella di integrazioni ottimizzate per i dettagli.
-
Express Workflows supporta solo le integrazioni Request Response.
Per aiutarti a decidere tra i due tipi, vedi. Scelta del tipo di flusso di lavoro in Step Functions
AWS Integrazioni SDK in Step Functions
| Servizio integrato | Richiesta e risposta | Esegui un Job - .sync | Attendi la richiamata -. waitForTaskToken |
|---|---|---|---|
| Oltre duecento servizi | Standard ed Express | Non supportato | Standard |
Integrazioni ottimizzate in Step Functions
| Servizio integrato | Richiesta e risposta | Esegui un Job - .sync | Attendi la richiamata -. waitForTaskToken |
|---|---|---|---|
| Amazon API Gateway | Standard ed Express | Non supportato | Standard |
| Amazon Athena | Standard ed Express | Standard | Non supportato |
| AWS Batch | Standard ed Express | Standard | Non supportato |
| Amazon Bedrock | Standard ed Express | Standard | Standard |
| AWS CodeBuild | Standard ed Express | Standard | Non supportato |
| Amazon DynamoDB | Standard ed Express | Non supportato | Non supportato |
| Amazon ECS/Fargate | Standard ed Express | Standard | Standard |
| Amazon EKS | Standard ed Express | Standard | Standard |
| Amazon EMR | Standard ed Express | Standard | Non supportato |
| Amazon EMR on EKS | Standard ed Express | Standard | Non supportato |
| Amazon EMR Serverless | Standard ed Express | Standard | Non supportato |
| Amazon EventBridge | Standard ed Express | Non supportato | Standard |
| AWS Glue | Standard ed Express | Standard | Non supportato |
| AWS Glue DataBrew | Standard ed Express | Standard | Non supportato |
| AWS Lambda | Standard ed Express | Non supportato | Standard |
| AWS Elemental MediaConvert | Standard ed Express | Standard | Non supportato |
| Amazon SageMaker AI | Standard ed Express | Standard | Non supportato |
| Amazon SNS | Standard ed Express | Non supportato | Standard |
| Amazon SQS | Standard ed Express | Non supportato | Standard |
| AWS Step Functions | Standard ed Express | Standard | Standard |
Esempi di casi d'uso per i flussi di lavoro
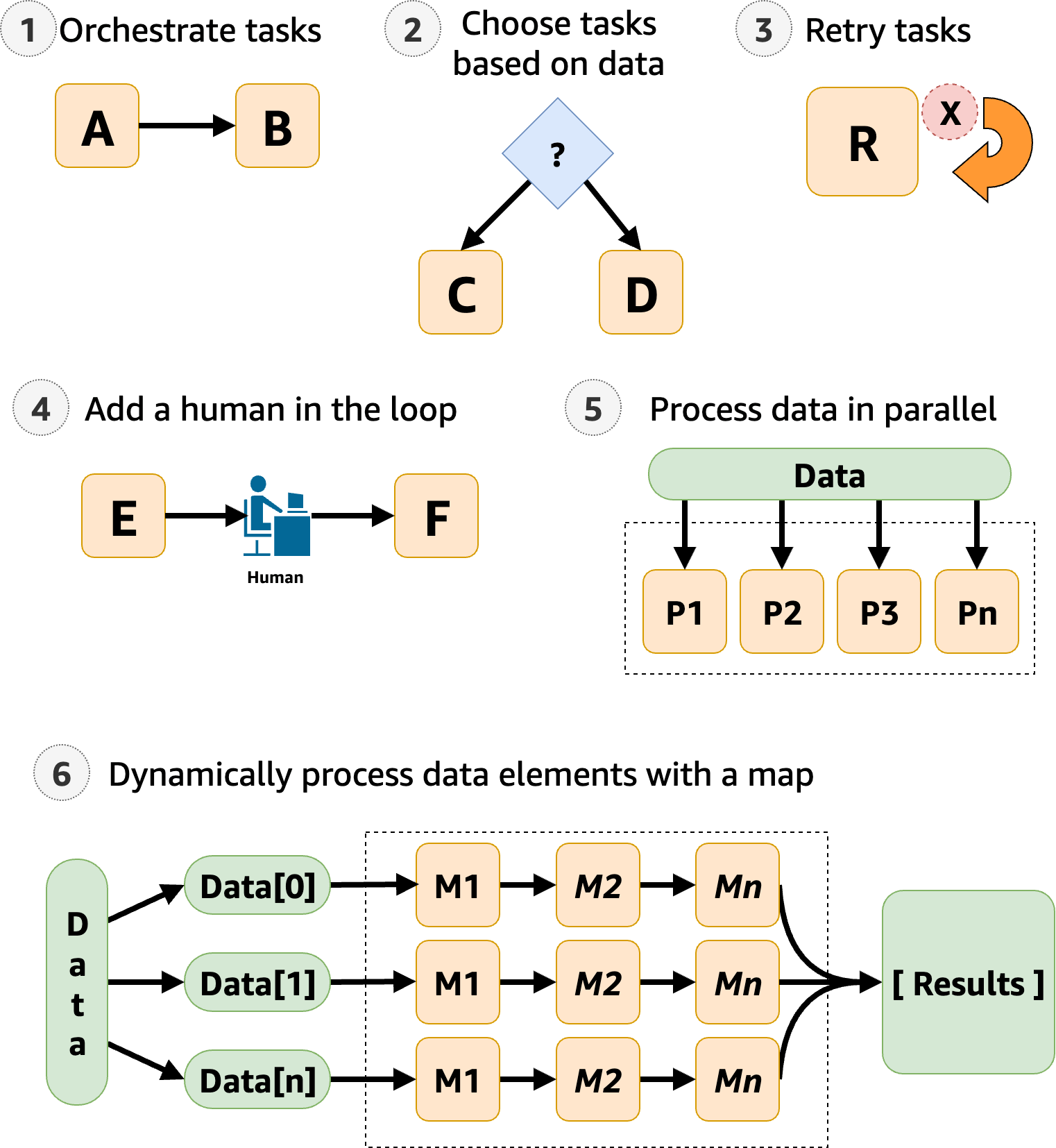
Step Functions gestisce i componenti e la logica dell'applicazione, così puoi scrivere meno codice e concentrarti sulla creazione e sull'aggiornamento rapido dell'applicazione. L'immagine seguente mostra sei casi d'uso per i flussi di lavoro Step Functions.
-
Orchestrazione delle attività: è possibile creare flussi di lavoro che orchestrano una serie di attività, o passaggi, in un ordine specifico. Ad esempio, l'Attività A potrebbe essere una funzione Lambda che fornisce input per un'altra funzione Lambda nel Task B. L'ultimo passaggio del flusso di lavoro fornisce il risultato finale.
-
Scegli le attività in base ai dati: utilizzando uno
Choicestato, puoi fare in modo che Step Functions prenda decisioni in base all'input dello stato. Ad esempio, immaginate che un cliente richieda un aumento del limite di credito. Se la richiesta supera il limite di credito preapprovato dal cliente, puoi fare in modo che Step Functions invii la richiesta del cliente a un responsabile per l'approvazione. Se la richiesta è inferiore al limite di credito preapprovato dal cliente, puoi fare in modo che Step Functions approvi la richiesta automaticamente. -
Gestione degli errori (
Retry/Catch): puoi riprovare le attività non riuscite o catturare le attività fallite ed eseguire automaticamente passaggi alternativi.Ad esempio, dopo che un cliente ha richiesto un nome utente, forse la prima chiamata al servizio di convalida non riesce, quindi il flusso di lavoro potrebbe ritentare la richiesta. Quando la seconda richiesta ha esito positivo, il flusso di lavoro può continuare.
Oppure, se il cliente ha richiesto un nome utente non valido o non disponibile, un'
Catchistruzione potrebbe portare a una fase del flusso di lavoro di Step Functions che suggerisce un nome utente alternativo.Per esempi di
RetryeCatch, vediGestione degli errori nei flussi di lavoro di Step Functions. -
Human in the loop — Step Functions può includere fasi di approvazione umana nel flusso di lavoro. Ad esempio, immagina che un cliente bancario tenti di inviare fondi a un amico. Con un callback e un task token, puoi fare in modo che Step Functions attenda fino alla conferma del trasferimento da parte dell'amico del cliente, dopodiché Step Functions continuerà il flusso di lavoro per notificare al cliente bancario che il trasferimento è stato completato.
Per vedere un esempio, consulta Crea un esempio di pattern di callback con Amazon SQS, Amazon SNS e Lambda.
-
Elaborazione dei dati in fasi parallele: utilizzando uno
Parallelstato, Step Functions può elaborare i dati di input in fasi parallele. Ad esempio, un cliente potrebbe aver bisogno di convertire un file video in diverse risoluzioni di visualizzazione, in modo che gli spettatori possano guardare il video su più dispositivi. Il flusso di lavoro potrebbe inviare il file video originale a diverse funzioni Lambda o utilizzare l' AWS Elemental MediaConvert integrazione ottimizzata per elaborare un video con più risoluzioni di visualizzazione contemporaneamente. -
Elabora dinamicamente gli elementi dei dati: utilizzando uno
Mapstato, Step Functions può eseguire una serie di passaggi del flusso di lavoro su ciascun elemento di un set di dati. Le iterazioni vengono eseguite in parallelo, il che rende possibile elaborare rapidamente un set di dati. Ad esempio, quando il cliente ordina trenta articoli, il sistema deve applicare lo stesso flusso di lavoro per preparare ogni articolo per la consegna. Dopo che tutti gli articoli sono stati raccolti e imballati per la consegna, il passaggio successivo potrebbe consistere nell'inviare rapidamente al cliente un'e-mail di conferma con le informazioni di tracciamento.Per un esempio di modello iniziale, vedi. Elabora i dati con una mappa
