Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
REL10-BP01 Implementazione del carico di lavoro in diversi luoghi
Distribuisci i dati e le risorse del carico di lavoro su più zone di disponibilità o, se necessario, in tutte le Regioni AWS.
Un principio fondamentale per la progettazione dei servizi in AWS è quello di evitare singoli punti di errore, inclusa l'infrastruttura fisica sottostante. AWS fornisce risorse e servizi di cloud computing a livello globale in più posizioni geografiche chiamate Regioni. Ogni Regione è fisicamente e logicamente indipendente ed è costituita da tre o più zone di disponibilità (AZ). Le zone di disponibilità sono geograficamente vicine ma fisicamente separate e isolate. Distribuendo i carichi di lavoro tra le zone di disponibilità e le Regioni, si riducono i rischi legati a minacce quali incendi, inondazioni, disastri meteorologici, terremoti ed errori umani.
Crea una strategia di localizzazione per fornire un'alta disponibilità adeguata ai carichi di lavoro.
Risultato desiderato: i carichi di lavoro di produzione sono distribuiti tra più zone di disponibilità (AZ) o Regioni per ottenere tolleranza ai guasti e alta disponibilità.
Anti-pattern comuni:
-
Il carico di lavoro di produzione esiste solo in una singola zona di disponibilità.
-
Viene implementata un'architettura multiregionale quando invece un'architettura multi-AZ è in grado di soddisfare i requisiti aziendali.
-
Le implementazioni o i dati vengono desincronizzati, con conseguenti deviazioni di configurazione o dati sottoreplicati.
-
Non tieni conto delle dipendenze tra i componenti dell'applicazione se i requisiti di resilienza e multi-posizione differiscono tra tali componenti.
Vantaggi dell'adozione di questa best practice:
-
Il carico di lavoro è più resiliente in caso di incidenti, come interruzioni di corrente, problemi con i controlli ambientali, disastri naturali, errori dei servizi upstream o problemi di rete che hanno un impatto su un'AZ o su un'intera Regione.
-
È possibile accedere a un inventario più ampio di istanze Amazon EC2 e ridurre le probabilità che si verifichino eccezioni InsufficientCapacityException (ICE) quando si avviano tipi specifici di istanze EC2.
Livello di rischio associato se questa best practice non fosse adottata: elevato
Guida all'implementazione
Implementa e gestisci tutti i carichi di lavoro di produzione in almeno due zone di disponibilità (AZ) in una Regione.
Utilizzo di più zone di disponibilità
Le zone di disponibilità sono posizioni di hosting delle risorse fisicamente separate l'una dall'altra per evitare guasti correlati dovuti a rischi quali incendi, inondazioni e trombe d'aria. Ogni zona di disponibilità ha un'infrastruttura fisica indipendente, che include le connessioni alla rete elettrica, le fonti di alimentazione di backup, i servizi meccanici e la connettività di rete. Questa disposizione limita i guasti di uno qualsiasi di questi componenti alla sola zona di disponibilità interessata. Ad esempio, se un incidente a livello di AZ rende non disponibili le istanze EC2 nella zona di disponibilità interessata, è comunque possibile utilizzare le istanze in altre zone di disponibilità.
Nonostante siano fisicamente separate, le zone di disponibilità nella stessa Regione AWS sono sufficientemente vicine da garantire una rete a elevato throughput e bassa latenza (inferiore ai 10 millisecondi). Puoi replicare i dati in modo sincrono tra le zone di disponibilità per la maggior parte dei carichi di lavoro senza influire in modo significativo sull'esperienza dell'utente. Ciò significa che puoi utilizzare le zone di disponibilità in una Regione in una configurazione attiva/attiva o attiva/in standby.
Tutta l'elaborazione associata al carico di lavoro deve essere distribuita tra più zone di disponibilità. Sono incluse le istanze Amazon EC2
È inoltre necessario replicare i dati per il carico di lavoro e renderli disponibili in più zone di disponibilità. Alcuni servizi di dati gestiti da AWS, come Amazon S3
Se utilizzi un'archiviazione autogestita, come i volumi Amazon Elastic Block Store (EBS)
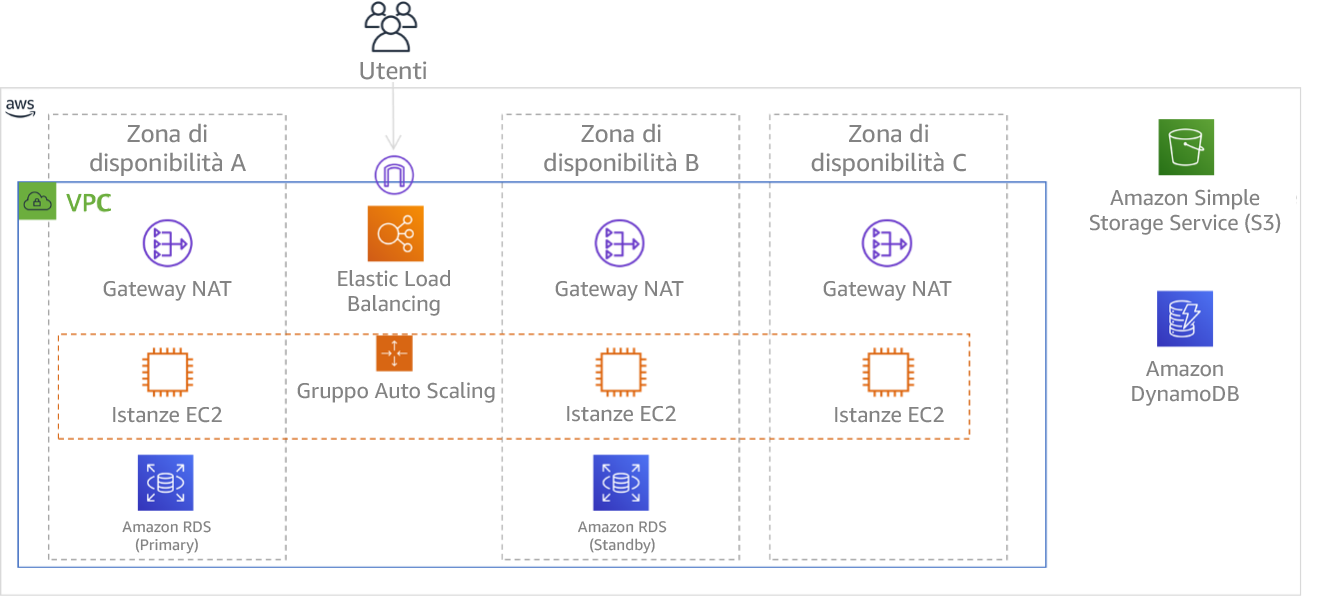
Figura 9: architettura multi-livello distribuita su tre zone di disponibilità. Nota: Amazon S3 e Amazon DynamoDB sono sempre ad AZ multiple automaticamente. L'ELB viene inoltre distribuito in tutte e tre le zone.
Utilizzo di più Regioni AWS
In presenza di carichi di lavoro che richiedono una resilienza estrema (come infrastrutture critiche, applicazioni sanitarie o servizi con requisiti di disponibilità stringenti da parte dei clienti o imposti), potrebbe essere richiesta disponibilità aggiuntiva rispetto a quella che può fornire una singola Regione AWS. In questo caso, è necessario implementare e gestire il carico di lavoro su almeno due Regioni AWS (supponendo che ciò sia consentito dai requisiti di residenza dei dati).
Le Regioni AWS sono situate in diverse aree geografiche del mondo e in più continenti. Le Regioni AWS hanno una separazione fisica e un isolamento ancora maggiori rispetto alle sole zone di disponibilità. I servizi AWS, con poche eccezioni, sfruttano questa struttura per operare in modo completamente indipendente tra le diverse Regioni (noti anche come servizi regionali). Un guasto di un servizio in una Regione AWS, non vi è alcun impatto sul servizio in un'altra Regione.
Quando il carico di lavoro viene gestito in più Regioni, è necessario considerare ulteriori requisiti. Poiché le risorse in Regioni diverse sono separate e indipendenti l'una dall'altra, è necessario duplicare i componenti del carico di lavoro in ciascuna Regione. Questo include l'infrastruttura di base, come i VPC, oltre ai servizi dati e di elaborazione.
NOTA: se prendi in considerazione una progettazione multiregionale, verifica che sia possibile eseguire il carico di lavoro in una singola Regione. Se crei dipendenze tra le Regioni, in cui un componente di una Regione si affida a servizi o componenti di una Regione diversa, il rischio di errore potrebbe aumentare, indebolendo in maniera significativa la propria postura di affidabilità.
Per facilitare le implementazioni multiregionali e mantenere la coerenza, AWS CloudFormation StackSets può replicare l'intera infrastruttura AWS in più Regioni. AWS CloudFormation
È inoltre necessario replicare i dati in ciascuna delle Regioni scelte. Molti servizi dati gestiti da AWS offrono funzionalità di replica multiregionale, tra cui Amazon S3, Amazon DynamoDB, Amazon RDS, Amazon Aurora, Amazon Redshift, Amazon Elasticache e Amazon EFS. Le tabelle globali di Amazon DynamoDB
AWS offre anche la possibilità di instradare il traffico delle richieste verso le implementazioni regionali con grande flessibilità. Ad esempio, puoi configurare i record DNS utilizzando Amazon Route 53
Anche se scegli di non operare in più Regioni per l'alta disponibilità, considera più Regioni come parte della propria strategia di disaster recovery (DR). Se possibile, replica i componenti e i dati dell'infrastruttura del carico di lavoro in una configurazione warm standby o fiamma pilota in una Regione secondaria. In questa progettazione, si replica l'infrastruttura di base dalla Regione primaria come VPC, gruppi Auto Scaling, orchestratori di container e altri componenti, ma si configurano i componenti di dimensioni variabili nella Regione di standby (come il numero di istanze EC2 e le repliche di database) in modo che siano di dimensioni minimamente utilizzabili. Puoi anche organizzare la replica continua dei dati dalla Regione primaria alla Regione di standby. Se si verifica un incidente, puoi aumentare orizzontalmente, o incrementare, le risorse nella Regione di standby e quindi promuoverla a Regione primaria.
Passaggi dell'implementazione
-
Collabora con le parti interessate aziendali e gli esperti in materia di residenza dei dati per determinare quali Regioni AWS possono essere utilizzate per ospitare le risorse e i dati.
-
Collabora con le parti interessate aziendali e tecniche per valutare il carico di lavoro e determinare se le esigenze di resilienza possono essere soddisfatte da un approccio multi-AZ (Regione AWS singola) o se richiedono un approccio multiregionale (se sono consentite più Regioni). L'uso di più Regioni può garantire maggiore disponibilità, ma può comportare complessità e costi aggiuntivi. Nella valutazione, considera i seguenti fattori:
-
Obiettivi aziendali e requisiti dei clienti: quanto tempo di inattività è consentito nel caso in cui si verifichi un incidente che impatta sul carico di lavoro in una zona di disponibilità o in una Regione? Valuta gli obiettivi dei punti di ripristino come descritto in REL13-BP01 Definizione degli obiettivi di ripristino in caso di downtime e perdita di dati.
-
Requisiti per il disaster recovery (DR): contro quale tipo di potenziale disastro desideri assicurarti? Considera la possibilità di perdita di dati o di indisponibilità a lungo termine a livello di diversi ambiti di impatto, da una singola zona di disponibilità a un'intera Regione. Se si replicano i dati e le risorse tra le zone di disponibilità e in una singola zona di disponibilità si verifica un guasto prolungato, il servizio può essere ripristinato in un'altra zona di disponibilità. Se si replicano i dati e le risorse tra Regioni, puoi ripristinare il servizio in un'altra Regione.
-
-
Distribuisci le risorse di elaborazione in più zone di disponibilità.
-
Nel VPC, crea più sottoreti in diverse zone di disponibilità. Configura ciascuna di esse in modo che siano sufficientemente grandi da ospitare le risorse necessarie per servire il carico di lavoro, anche durante un incidente. Per ulteriori informazioni consulta REL02-BP03 Verifica che l'allocazione delle sottoreti IP consenta l'espansione e la disponibilità.
-
Se utilizzi istanze Amazon EC2, utilizza EC2 Auto Scaling
per gestire le istanze. Specifica le sottoreti scelte nel passaggio precedente durante la creazione di gruppi Auto Scaling. -
Se utilizzi l'elaborazione AWS Fargate per Amazon ECS o Amazon EKS, seleziona le sottoreti che hai scelto nel primo passaggio durante l'operazione di creazione di un servizio ECS, l'avvio di un'attività ECS o la creazione di un profilo Fargate per EKS.
-
Se utilizzi funzioni AWS Lambda che devono essere eseguite nel VPC, seleziona le sottoreti che hai scelto nel primo passaggio dell'operazione di creazione della funzione Lambda. Per tutte le funzioni che non dispongono di una configurazione VPC, AWS Lambda gestisce automaticamente la disponibilità.
-
Colloca i direttori del traffico, come i bilanciatori del carico, davanti alle risorse di elaborazione. Se il bilanciamento del carico tra zone è abilitato, AWS Application Load Balancer e Network Load Balancer rilevano quando destinazioni come istanze e container EC2 non sono raggiungibili a causa della compromissione della zona di disponibilità e reinstradano il traffico verso destinazioni in zone di disponibilità integre. Se il bilanciamento del carico tra zone è disabilitato, utilizza Amazon Application Recovery Controller (ARC) per fornire funzionalità di spostamento zonale. Se utilizzi un bilanciatore del carico di terze parti o hai implementato bilanciatori del carico personalizzati, configurali con più front-end in diverse zone di disponibilità.
-
-
Replica i dati del carico di lavoro in più zone di disponibilità.
-
Se utilizzi un servizio dati gestito da AWS come Amazon RDS, Amazon ElastiCache o Amazon FSx, consulta la relativa guida per l'utente per comprendere le relative funzionalità di replica dei dati e di resilienza. Se necessario, abilita la replica e il failover tra AZ.
-
Se utilizzi servizi di archiviazione gestiti da AWS come Amazon S3, Amazon EFS e Amazon FSx, evita di utilizzare configurazioni Single-AZ o One Zone per i dati che richiedono un'elevata durabilità. Utilizza una configurazione multi-AZ per questi servizi. Consulta la guida per l'utente del rispettivo servizio per determinare se la replica multi-AZ è abilitata per impostazione predefinita o se è necessario abilitarla.
-
Se esegui un database, una coda o un altro servizio di archiviazione autogestito, organizza la replica multi-AZ in base alle istruzioni o alle best practice dell'applicazione. Informati sulle procedure di failover della tua applicazione.
-
-
Configura il servizio DNS per rilevare compromissione dell'AZ e reinstrada il traffico verso una zona di disponibilità integra. Se utilizzato in combinazione con Elastic Load Balancer, Amazon Route 53 può eseguire questa operazione automaticamente. Route 53 può anche essere configurato con record di failover che utilizzano i controlli dell'integrità per rispondere alle query con soli indirizzi IP integri. Per tutti i record DNS utilizzati per il failover, specifica un valore TTL (time to live) breve (ad esempio, 60 secondi o meno) per evitare che la memorizzazione nella cache dei record impedisca il ripristino (i record alias di Route 53 forniscono i TTL appropriati).
Passaggi aggiuntivi quando si utilizzano più Regioni AWS
-
Replica tutto il sistema operativo (OS) e il codice dell'applicazione utilizzati dal carico di lavoro nelle Regioni selezionate. Se necessario, replica le Amazon Machine Image (AMI) utilizzate dalle istanze EC2 utilizzando soluzioni come Amazon EC2 Image Builder. Replica le immagini di container archiviate nei registri utilizzando soluzioni come la replica tra Regioni di Amazon ECR. Abilita la replica regionale per tutti i bucket Amazon S3 utilizzati per archiviare le risorse dell'applicazione.
-
Distribuisci le risorse di elaborazione e i metadati di configurazione (come i parametri archiviati in AWS Systems Manager Parameter Store) in più Regioni. Utilizza le stesse procedure descritte nei passaggi precedenti, ma replica la configurazione per ogni Regione utilizzata per il carico di lavoro. Utilizza soluzioni infrastructure as code, ad esempio AWS CloudFormation, per riprodurre in modo uniforme le configurazioni tra le Regioni. Se utilizzi una Regione secondaria in una configurazione fiamma pilota per il disaster recovery, puoi ridurre il numero di risorse di elaborazione a un valore minimo per risparmiare sui costi, con un corrispondente aumento del tempo di ripristino.
-
Replica i dati dalla Regione primaria alle Regioni secondarie.
-
Le tabelle globali di Amazon DynamoDB forniscono repliche globali dei dati in cui è possibile scrivere da qualsiasi Regione supportata. Con altri servizi dati gestiti da AWS, come Amazon RDS, Amazon Aurora e Amazon Elasticache, si designano una Regione primaria (lettura/scrittura) e Regioni di replica (sola lettura). Per informazioni dettagliate sulla replica regionale, consulta le guide per l'utente e per gli sviluppatori dei rispettivi servizi.
-
Se esegui un database autogestito, organizza la replica in più Regioni in base alle istruzioni o alle best practice dell'applicazione. Informati sulle procedure di failover della tua applicazione.
-
Se il carico di lavoro utilizza AWS EventBridge, potrebbe essere necessario inoltrare eventi selezionati dalla Regione primaria alle Regioni secondarie. A tal fine, specifica i bus di eventi nelle Regioni secondarie come destinazioni per gli eventi corrispondenti nella Regione primaria.
-
-
Considera se e in che misura usare chiavi di crittografia identiche tra le varie Regioni. Un approccio tipico, che consente di bilanciare sicurezza e facilità d'uso, consiste nell'utilizzare chiavi con ambito di Regione per i dati e l'autenticazione a livello di Regione e utilizzare chiavi con ambito globale per la crittografia dei dati replicati tra le diverse Regioni. AWS Key Management Service (KMS)
supporta chiavi multiregionali per distribuire e proteggere in modo sicuro le chiavi condivise tra le Regioni. -
Prendi in considerazione AWS Global Accelerator per migliorare la disponibilità dell'applicazione indirizzando il traffico verso Regioni che contengono endpoint integri.
Risorse
Best practice correlate:
Documenti correlati:
-
Amazon EC2 Auto Scaling: Example: Distribute instances across Availability Zones
-
How Amazon ECS places tasks on container instances (includes Fargate)
-
Amazon Elasticache for Redis OSS: Replication across Regioni AWS using global datastores
-
Amazon Application Recovery Controller (ARC) Developer Guide
-
Sending and receiving Amazon EventBridge events between Regioni AWS
-
Creating a Multi-Region Application with AWS Services blog series
-
Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud
-
Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
Video correlati:
