CloudWatch 異常検出の使用
メトリクスの異常検出を有効にすると、CloudWatch は統計アルゴリズムと機械学習アルゴリズムを適用します。これらのアルゴリズムは、システムやアプリケーションのメトリクスを継続的に分析し、正常なベースラインを決定して、ユーザーの最小限の介入で異常を検出します。
これらのアルゴリズムは、異常検出モデルを生成します。モデルは、メトリクスの正常な動作を表す想定値の範囲を生成します。
異常検出は、AWS Management Console、AWS CLI、CloudFormation または AWS SDK を使用して有効にすることができます。異常検出は、AWS から提供されるメトリクスおよびカスタムメトリクスに対して有効にすることができます。CloudWatch クロスアカウントオブザーバビリティのモニタリングアカウントとして設定されたアカウントでは、モニタリングアカウントのメトリクスに加え、ソースアカウントのメトリクスに対しても異常ディテクタを作成できます。
想定値のモデルは、次の 2 つの方法で使用できます。
メトリクスの想定値に基づいて異常検出アラームを作成します。このタイプのアラームには、アラーム状態を決定するための静的なしきい値はありません。代わりに、異常検出モデルに基づいて、メトリクスの値と想定値を比較します。
メトリクス値が想定値の範囲を上回った場合、下回った場合、または両方の場合にアラームをトリガーすることを選択できます。
詳細については、「異常検出に基づいて CloudWatch アラームを作成する」を参照してください。
メトリクスデータのグラフを表示するときに、想定値をバンドとしてグラフ上に重ねます。これにより、グラフで正常な範囲から外れている値を目で確認できます。詳細については、「グラフの作成」を参照してください。
GetMetricDataメトリクス数学関数でANOMALY_DETECTION_BANDAPI リクエストを使用して、モデルの帯の上限と下限の値を取得することもできます。詳細については、「GetMetricData」を参照してください。
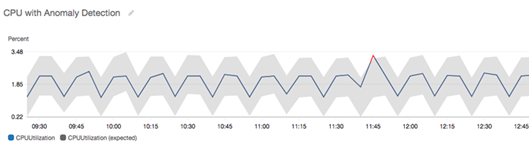
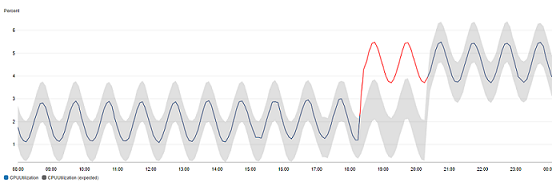
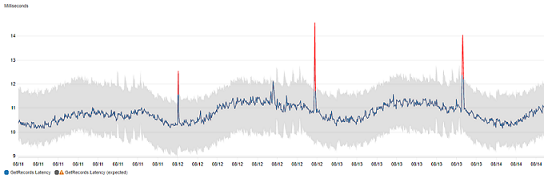
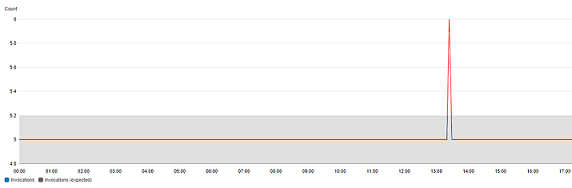
異常検出を行うグラフでは、想定値の範囲がグレーの帯で表示されます。メトリクスの実際の値がこの帯を超えると、その期間は赤で表示されます。
異常検出アルゴリズムは、メトリクスの季節的な変化と傾向の変化を考慮します。季節的な変化は、次の例に示すように、時間単位、日単位、週単位のいずれかになります。
より長い範囲の傾向は、下向きまたは上向きになる場合があります。
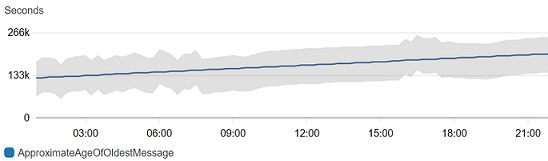
異常検出は、フラットなパターンを示すメトリクスにも適しています。
CloudWatch 異常検出の仕組み
メトリクスの異常検出を有効にすると、CloudWatch は、メトリクスの過去のデータに機械学習アルゴリズムを適用して、メトリクスの想定値のモデルを作成します。このモデルでは、メトリクスの傾向と、時間/日/週単位のパターンの両方を評価します。アルゴリズムは最大 2 週間分のメトリクスデータをトレーニングしますが、メトリクスに 2 週間分のデータが揃っていなくても、メトリクスの異常検出を有効にすることができます。
CloudWatch がモデルで使用する異常検出のしきい値を指定し、メトリクスの「正常」な値の範囲を決定します。異常検出のしきい値を高くするほど、「正常」な値の範囲が広くなります。
機械学習モデルは、メトリクスと統計に固有です。たとえば、AVG 統計を使用してメトリクスの異常検出を有効にした場合、モデルは、AVG 統計に固有になります。
CloudWatch が AWS サービスから多くの一般的なメトリクスのモデルを作成する場合、バンドが論理値の外に拡張されないようにします。例えば、EC2 インスタンスの MemoryUtilization のバンドは 0 から 100 の間で維持され、負にならない CloudFront Requests は、追跡するバンドはゼロを下回ることはありません。
モデルを作成した後、CloudWatch の異常検出はモデルを継続的に評価し、調整を行って、可能な限り正確であることを確認します。これには、メトリクス値が時間の経過とともに変化するか、突然変化するかを調整するためのモデルの再トレーニングが含まれます。また、季節的、スパイク、スパースなメトリクスのモデルを改善するための予測変数も含まれます。
メトリクスの異常検出を有効にした後は、必要に応じて、メトリクスの特定の期間を除外してモデルのトレーニングに使用されないように指定できます。この方法により、モデルのトレーニングにデプロイまたは他の異常なイベントが使用されないように除外でき、最も正確なモデルが作成されます。
アラームに異常検出モデルを使用すると、AWS アカウントで料金が発生します。詳細については、Amazon CloudWatch 料金表
Metric Math での異常検出
Metric Math での異常検出は、メトリクスの数式の出力で異常検出アラームの作成に使用できる機能です。これらの式を使用して、異常検出バンドを可視化するグラフを作成できます。この機能では、基本的な算術関数、比較演算子、論理演算子、そしてその他のほとんどの関数がサポートされています。サポートされていない関数の詳細については、Amazon CloudWatch ユーザーガイドの「Metric Math を使用する」を参照してください。
異常検出モデルの作成方法と同様に、メトリクスの数式に基づく異常検出モデルを作成できます。CloudWatch コンソールから、メトリクスの数式に異常検出を適用し、これらの式のしきい値のタイプとして異常検出を選択できます。
注記
Metric Math の異常検出は、最新バージョンのメトリクスユーザーインターフェイスでのみ有効化および編集できます。新しいバージョンのインターフェイスでメトリクスの数式に基づき異常ディテクターを作成すると、古いバージョンでは表示できますが、編集できません。
Metric Math と異常検出のアラームおよびモデルの作成、編集、削除の方法については、次のセクションを参照してください。
また、PutAnomalyDetector、DeleteAnomalyDetector、および DescribeAnomalyDetectors と CloudWatch API を使用すると、メトリクスの数式に基づく異常検出モデルを作成、削除、検出できます。これらの API アクションについては、Amazon CloudWatch API リファレンスの次のセクションを参照してください。
異常検出アラームの価格設定については、「Amazon CloudWatch の料金
PromQL を使用した異常検出
quantile_over_time、stddev_over_time、avg_over_time などの標準の PromQL 関数を使用して、Prometheus 互換メトリクスの異常検出バンドを構築できます。このアプローチはベースラインを計算し、スケーリングされた標準偏差を加算または減算して、メトリクスの自然パターンに適応する上限と下限を定義します。
これは、CPU 使用率、リクエストレイテンシー、エラー数など、浮動小数点値を返すすべてのメトリクスで機能します。OpenTelemetry を使用したメトリクスの取り込みについては、「OpenTelemetry」を参照してください。
上限と下限の定義
メトリクスの予想される範囲を定義するには、時間枠の中央値または平均を使用してベースラインを計算し、標準偏差の倍数を加算および減算します。乗数は感度を制御します。値が大きいほど、誤検出が少なく幅の広いバンドが生成され、値が小さいほど偏差が小さくなります。
次の例では、60 分の枠と乗数の 3 を使用して、広告リクエストメトリクスの上限を作成します。
quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) + 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m)
次の例では、対応する下限を作成します。clamp_min 関数は、負の値を持つことができないメトリクスの下限が負にならないようにします:
clamp_min( quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) - 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m), 0)
CloudWatch Query Studio で両方の境界をグラフ化して、メトリクスの予想される範囲を視覚化できます。詳細については、「Query Studio での PromQL クエリの実行」を参照してください。
違反の検出
メトリクスが予想される範囲外であるタイミングを検出するには、両方の境界を 1 つのクエリに結合します。次の式は、メトリクス値が上限を超えるか、下限を下回るデータポイントのみを返します。
1 * {"app.ads.ad_requests"} > quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) + 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m) or 1 * {"app.ads.ad_requests"} < clamp_min( quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) - 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m), 0)
このクエリは複数のラベル値全体で動作するため、1 つのクエリでフリート全体の異常を検出できます。この式を使用して、時系列が予想される範囲を超えたときにトリガーする PromQL アラームを作成できます。詳細については、「異常検出のための PromQL を使用した CloudWatch アラームの作成」を参照してください。
