Aurora PostgreSQL のメモリパラメータの調整
Amazon Aurora PostgreSQL では、さまざまな処理タスクに使用されるメモリ量を制御する複数のパラメータを使用できます。タスクが特定のパラメータに設定されている量よりも多くのメモリを消費する場合、Aurora PostgreSQL ではディスクへの書き込みなどの処理に他のリソースを使用します。このため、Aurora PostgreSQL DB クラスターが遅くなったり、メモリ不足エラーが発生して停止したりする可能性があります。
各メモリパラメータのデフォルト設定によって、通常は目的の処理タスクを処理できます。ただし、Aurora PostgreSQL DB クラスターの のメモリ関連のパラメータをチューニングすることもできます。このチューニングを行うと、特定のワークロードの処理に十分なメモリが割り当てられるようになります。
メモリ管理を制御するパラメータについての情報は、以下を参照してください。メモリ使用率を評価する方法も説明しています。
パラメータ値の確認と設定
メモリを管理し、Aurora PostgreSQL DB クラスターのメモリ使用量を評価するために設定できるパラメータには以下のものがあります。
work_mem— Aurora PostgreSQL DB クラスターが一時ディスクファイルに書き込む前に、内部ソート操作とハッシュテーブルで使用するメモリ量を指定します。log_temp_files— 一時ファイルの作成、ファイル名、サイズをログに記録します。このパラメータをオンにすると、作成される一時ファイルごとにログエントリが保存されます。これをオンにすると、Aurora PostgreSQL DB クラスターがディスクに書き込む必要がある頻度を確認できます。過剰なログの記録を避けるため、Aurora PostgreSQL DB クラスターの一時ファイル生成に関する情報を収集したら、再度オフにしてください。logical_decoding_work_mem– ディスクに書き込む前に、各内部リオーダバッファで使用されるメモリの量 (キロバイト単位) を指定します。このメモリは、レプリカの作成に使用するプロセスである論理デコードに使用されます。これは、ログ先行書き込み (WAL) ファイルのデータをターゲットが必要とする論理ストリーミング出力に変換することによって行われます。このパラメータ値により、各レプリケーション接続に指定されたサイズの単一のバッファが作成されます。デフォルトでは 65536 KB です。このバッファがいっぱいになると、超過分はファイルとしてディスクに書き込まれます。ディスクのアクティビティを最小化するため、このパラメータ値を
work_memより非常に高い値に設定ができます。
これらはすべて動的パラメータなので、現在のセッションで変更できます。これを実行するには、次に示すように psql で Aurora PostgreSQL DB クラスター に接続し、SET ステートメントを使用します。
SET parameter_name TO parameter_value;セッション設定は、そのセッションの有効期間中のみ有効です。セッションが終了すると、パラメータは DB クラスターのパラメータグループの設定に戻ります。パラメータを変更する前に、次のように最初に pg_settings テーブルをクエリして現在の値を確認します。
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
例えば、work_mem パラメータの値を検索するには、Aurora PostgreSQL DB クラスターのライターインスタンスに接続し、次のクエリを実行します。
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
パラメータ設定を変更して設定を永続化させるには、カスタム DB クラスターのパラメータグループを使用する必要があります。SET ステートメントを使用して、これらのバラメータに異なる値を Aurora PostgreSQL DB クラスター に付与した後、カスタムパラメータグループを作成し、Aurora PostgreSQL DB クラスターに適用できます。詳細については、「Amazon Aurora のパラメータグループ」を参照してください。
ワーキングメモリパラメータの概要
ワーキングメモリパラメータ (work_mem) には、Aurora PostgreSQL が複雑なクエリを処理するために使用可能な最大メモリ量を指定します。複雑なクエリには、ソートやグループ化の操作、つまり次のような句を使用するものが含まれます。
ORDER BY
DISTINCT
グループ化の条件
JOIN (MERGE および HASH)
クエリプランナーは、Aurora PostgreSQL DB クラスターがどのようにワーキングメモリを使用するかについて間接的に影響を与えます。クエリプランナーは、SQL ステートメントを処理するための実行計画を生成します。特定の計画では、複雑なクエリを複数の作業単位に分割し、並行して実行できます。Aurora PostgreSQL では、各並列プロセスでディスクへの書き込み前に、各セッションの work_mem パラメータで指定されたメモリ量を使用します。
複数のデータベースユーザーが複数の操作を同時に実行し、複数の作業単位を並行して生成すると、Aurora PostgreSQL DB クラスターに割り当てられた作業メモリを使い果たしてしまう可能性があります。このため一時ファイルの作成やディスク I/O が過剰になり、最悪の場合はメモリ不足でエラーが発生する可能性があります。
一時ファイルの使用状況の確認
クエリの処理に必要なメモリが、work_mem で指定された値を超えた場合は、作業データは一時ファイルのディスクにオフロードされます。その発生頻度を確認するには、log_temp_files パラメータをオンにします。デフォルトでは、このパラメータはオフ (-1 に設定) に設定されています。すべての一時ファイル情報をキャプチャするには、このパラメータを 0 に設定します。log_temp_files に他の正の整数を設定すると、そのデータ量 (キロバイト単位) 以上のファイルの一時ファイル情報をキャプチャできます。次のイメージでは、AWS マネジメントコンソール からの例を示します。
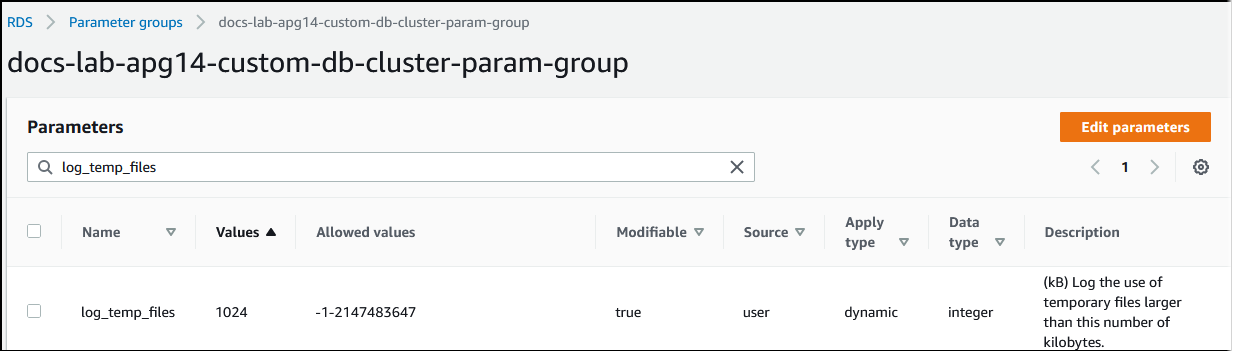
一時ファイルのログの記録を設定したら、自身のワークロードでテストして、ワーキングメモリの設定が十分かどうかを確認できます。また、PostgreSQL コミュニティのシンプルなベンチマークアプリケーションである pgbench を使用して、ワークロードをシミュレーションすることができます。
次の例では、テストを実行するために必要なテーブルと行を作成して、(-i) pgbench を初期化します。この例では、スケーリング係数 (-s 50) により、labdb データベースの pgbench_branches テーブルに 50行、pgbench_tellers テーブルに 500 行、pgbench_accounts テーブルに 5,000,000 行が作成されます。
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)環境を初期化したら、時間 (-T) とクライアント数 (-c) を指定してベンチマークを実行できます。この例では、-d オプションを使用して Aurora PostgreSQL DB クラスターによってトランザクションが処理される際にデバッグ情報も出力します。
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
pgbench の詳細については、PostgreSQL のドキュメントの「pgbench
psql メタコマンド (\d) を使用して、pgbench が作成したテーブル、ビュー、インデックスなどのリレーションを一覧表示できます。
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
出力に示されているように、pgbench_accounts テーブルは aid 列にインデックス表示されています。この次のクエリがワーキングメモリを使用することを確認するには、次の例に示すように、インデックスが設定されていない列をすべてクエリします。
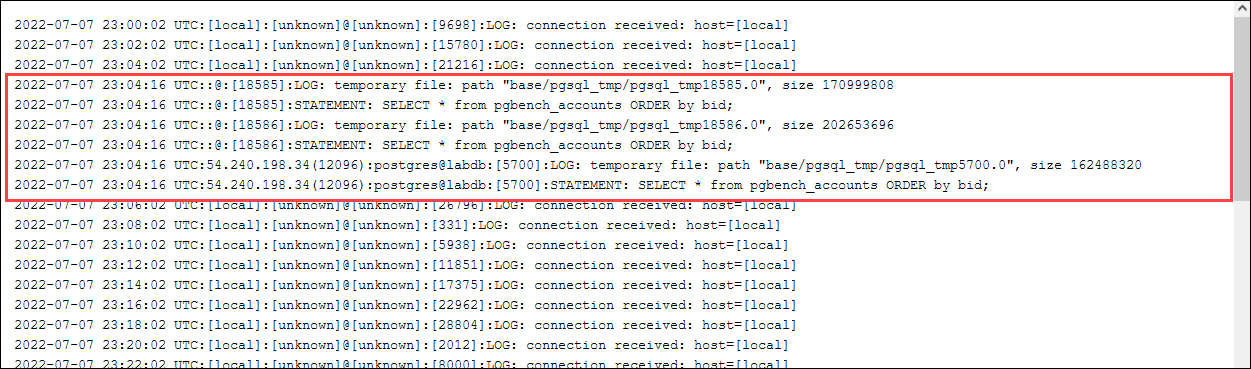
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
一時ファイルのログを確認してください。これで実行するには、AWS マネジメントコンソール を開き、Aurora PostgreSQL DB クラスターのライターインスタンスを選択し、[Logs & Events] (ログとイベント) タブをクリックします。コンソールでこのログを表示するか、ダウンロードして詳細を分析します。次のイメージに示すように、クエリの処理に必要な一時ファイルのサイズから、work_mem パラメータに指定する量を増やす検討も必要なことがわかります。
このパラメータは運用する上で、必要に応じて個人やグループごとに異なる設定をすることができます。例えば、dev_team という名前のロールに対し、work_mem パラメータを 8 GB に設定できます。
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
work_mem に対するこの設定では、dev_team ロールのメンバーであるすべてのロールに最大 8 GB のワーキングメモリが割り当てられます。
インデックスの使用による応答時間の短縮
クエリの結果が返されるまでに時間がかかりすぎる場合は、インデックスが想定どおりに使用されているかどうかを確認できます。まず、次のように psql メタコマンドの \timing をオンにします。
postgres=>\timing on
timing をオンにしたら、シンプルな SELECT ステートメントを使用します。
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
出力に示されているように、このクエリは完了するのに 3 秒以上かかりました。応答時間を改善するには、次のように pgbench_accounts にインデックスを作成します。
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
クエリを再実行すると、応答時間が短くなったことがわかります。この例では、クエリは約 5 倍速く、約 0.5 秒で完了しました。
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
論理デコード用のワーキングメモリの調整
論理レプリケーションは、PostgreSQL バージョン 10 で導入された以降、Aurora PostgreSQL のすべてのバージョンで使用できます。また、論理レプリケーションを設定する場合、logical_decoding_work_mem パラメータを使用して、論理デコードプロセスがデコードおよびストリーミングプロセスに使用できるメモリ量を指定できます。
論理デコード中に、ログ先行書き込み (WAL) レコードは SQL ステートメントに変換され、論理レプリケーションまたは別のタスクのために別のターゲットに送信されます。トランザクションを WAL に書き込んで変換する場合、トランザクション全体が logical_decoding_work_mem で指定された値の範囲に収まる必要があります。デフォルトでは、このパラメータは 65536 KB に設定されています。オーバーフローはすべてディスクに書き込まれます。つまり、送信先に送信する前にディスクからの再読み取りが必要なため、プロセス全体が遅くなります。
次の例に示すように、aurora_stat_file 関数を使用することで、特定の時点における現在のワークロードのトランザクションオーバーフローの量を評価できます。
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
このクエリは、クエリが呼び出された際に Aurora PostgreSQL DB クラスター上のスピルファイルの数とサイズを返します。長時間実行されるワークロードでは、ディスク上にスピルファイルがまだ存在しない可能性があります。長時間実行されるワークロードをプロファイリングするには、ワークロードの実行中にオーバーフローファイル情報をキャプチャするテーブルを作成することをお勧めします。次に示すようにテーブルを作成できます。
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
論理レプリケーション中にスピルファイルがどのように使用されるかを確認するには、パブリッシャーとサブスクライバを設定し、シンプルなレプリケーションを開始します。詳細については、「Aurora PostgreSQL DB クラスターの論理レプリケーションの設定」を参照してください。レプリケーションが進行中であれば、次のように aurora_stat_file() スピルファイル関数から結果セットをキャプチャするジョブを作成できます。
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
次の psql コマンドを使用して、ジョブを 1 秒に 1 回実行します。
\watch 0.5
ジョブの実行中に、別の psql セッションからライターインスタンスに接続します。次の一連のステートメントを使用すると、メモリ設定を超えるワークロードを実行し、Aurora PostgreSQL ではスピルファイルを作成します。
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
このステートメントには完了するのに数分かかります。終了したら、Ctrl キーと C キーを同時に押して、モニタリング機能を停止します。次に、次のコマンドを使用して、Aurora PostgreSQL DB クラスターのスピルファイルの使用状況に関する情報を保存するテーブルを作成します。
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
この例を実行すると、出力には 5 つのスピルファイルが作成され、611 MB のメモリを使用したことが示されています。ディスクへの書き込みを避けるには、logical_decoding_work_mem パラメータを次の最大メモリサイズの 1,024 に設定することをお勧めします。
