Amazon Aurora Global Database でスイッチオーバーまたはフェイルオーバーを使用する
Aurora グローバルデータベースは、単一の AWS リージョン で Aurora DB クラスターによって提供される標準高可用性よりも、事業継続性とディザスタリカバリ (BCDR) 保護を強化します。Aurora グローバルデータベースを使用すれば、実際の地域災害に備えて計画を立てて復旧したり、サービスレベルの停止を迅速に完了したりできます。災害からの復旧は、通常、次の 2 つのビジネス目標によって推進されます。
-
目標復旧時間 (RTO) - 災害またはサービス障害後にシステムが稼働状態に戻るまでにかかる時間。つまり、RTO はダウンタイムを測定します。Aurora Global Database の場合、RTO は分単位で行えます。
目標復旧時点 (RPO) - 災害またはサービス障害後に損失する可能性があるデータの量 (時間単位)。このデータ損失は、通常、非同期レプリケーションの遅延が原因です。Aurora Global Database の場合、RPO (目標復旧時点) は通常、秒単位で測定されます。Aurora PostgreSQL - ベースのグローバルデータベースでは、
rds.global_db_rpoパラメータを使用して RPO の上限を設定および追跡できますが、そうすると、プライマリクラスターの読み取りノードでのトランザクション処理に影響を与える可能性があります。詳細については、「Aurora PostgreSQL- ベースのグローバルデータベースの RPO (目標復旧時点) 管理」を参照してください。
Aurora グローバルデータベースの切り替えまたはフェイルオーバーには、グローバルデータベースのセカンダリリージョンのいずれかにある DB クラスターをプライマリ DB クラスターに昇格させる必要があります。「リージョン障害」という用語は、さまざまな障害シナリオを表すためによく使用されます。最悪のシナリオとしては、数百平方マイルに及ぶ壊滅的な事象による広範囲にわたる停電が考えられます。しかし、ほとんどの停電ははるかに局所的で、影響を受けるのはクラウドサービスや顧客システムのごく一部に限られます。障害の全容を検討して、クロスリージョンフェイルオーバーが適切な解決策であることを確認し、状況に適したフェイルオーバー方法を選択してください。フェイルオーバーとスイッチオーバーのどちらを使用するかは、具体的な停止シナリオによって異なります。
フェイルオーバー — このアプローチを使用して、計画外のシステム停止から回復します。この方法では、Aurora グローバルデータベース内のセカンダリ DB クラスターの 1 つにクロスリージョンフェイルオーバーを実行します。このアプローチの RPO は、通常、秒単位で測定される 0 以外の値です。障害発生時のデータ損失の量は、AWS リージョン 全体の Aurora グローバルデータベースレプリケーションの遅延によって異なります。詳細については、「予期しない停止からの Amazon Aurora Global Database の復旧」を参照してください。
スイッチオーバー— この操作は、以前は「マネージドプランニングフェイルオーバー」と呼ばれていました。このアプローチは、運用メンテナンス、その他の計画された運用手順など、管理されたシナリオに使用してください。この機能は、他の変更を行う前にセカンダリ DB クラスターとプライマリクラスターを同期するため、RPO は 0 (データの損失なし) になります。詳細については、「Amazon Aurora Global Database に対するスイッチオーバーの実行」を参照してください。
注記
ヘッドレスセカンダリ Aurora DB クラスターへのスイッチオーバーまたはフェイルオーバーを行う場合は、まず DB インスタンスをそのクラスターに追加する必要があります。ヘッドレス DB クラスターの詳細については、「セカンダリリージョンでのヘッドレス Aurora DB クラスターの作成」を参照してください。
トピック
予期しない停止からの Amazon Aurora Global Database の復旧
ごくまれに、Aurora Global Database のプライマリ AWS リージョン で予期しない停止が発生することがあります。この場合、プライマリ Aurora DB クラスターとその読み取りノードを使用できなくなり、プライマリとセカンダリ DB クラスター間のレプリケーションが停止します。ダウンタイム (RTO) とデータ損失 (RPO) の両方を最小限に抑えるため、迅速に作業を行ってリージョン間のフェイルオーバーを実行できます。
ディザスタリカバリ時のフェイルオーバーには 2 つの方法があります。
マネージドフェイルオーバー — ディザスタリカバリにはこの方法が推奨されます。この方法を使用すると、Aurora は古いプライマリリージョンが再び使用可能になったときに、セカンダリリージョンとしてグローバルデータベースに自動的に追加します。これにより、グローバルクラスターの元のトポロジーが維持されます。この方法を使用する手順については、「Aurora Global Database のマネージドフェイルオーバーを実行する」を参照してください。
手動フェイルオーバー — この代替方法は、プライマリリージョンとセカンダリリージョンで互換性のないエンジンバージョンが稼働している場合など、マネージドフェイルオーバーを使用できない場合に使用できます。この方法を使用する手順については、「Aurora Global Database のマニュアルフェイルオーバーを実行する」を参照してください。
重要
どちらのフェイルオーバー方法でも、フェイルオーバーイベントが発生する前に選択したセカンダリにレプリケートされていなかった書き込みトランザクションデータが失われる可能性があります。ただし、選択したセカンダリ DB クラスター上の DB インスタンスをプライマリライター DB インスタンスに昇格させるリカバリプロセスにより、データがトランザクション的に一貫した状態になることが保証されます。
Aurora Global Database のマネージドフェイルオーバーを実行する
このアプローチは、真の地域災害やサービスレベルの全面的な停止が発生した場合でも事業を継続できるようにするためのものです。
マネージドフェイルオーバー中、プライマリクラスターは選択したセカンダリリージョンにフェイルオーバーされ、Aurora Global Database の既存のレプリケーショントポロジが維持されます。選択したセカンダリクラスターは、読み取り専用ノードの 1 つを完全な読み取り状態に昇格します。このステップにより、クラスターがプライマリクラスターのロールを引き受けることができます。クラスターが新しいロールを引き受ける間、データベースは短時間使用できなくなります。古いプライマリクラスターから選択したセカンダリクラスターにレプリケートされなかったデータは、このセカンダリクラスターが新しいプライマリクラスターになると失われます。
注記
プライマリ DB クラスターとセカンダリ DB クラスターが同じメジャー、マイナー、パッチレベルのエンジンバージョンである場合にのみ、Aurora グローバルデータベースでマネージドクロスリージョンデータベースフェイルオーバーを実行できます。ただし、パッチレベルはマイナーエンジンバージョンによって異なる場合があります。詳細については、「マネージドクロスリージョンスイッチオーバーまたはフェイルオーバーに対するパッチレベルの互換性」を参照してください。ご使用のエンジンバージョンに互換性がない場合は、Aurora Global Database のマニュアルフェイルオーバーを実行する の手順に従ってフェイルオーバーを手動で実行できます。
データの損失を最小限に抑えるため、この機能を使用する前に次のことを行うことをお勧めします。
アプリケーションをオフラインにして、Aurora Global Database のプライマリクラスターへの書き込みが送信されないようにします。
Aurora Global Database 内のすべてのセカンダリ Aurora DB クラスターのラグタイムを確認します。レプリケーションの遅延が最も少ないセカンダリリージョンを選択すると、現在障害が発生しているプライマリリージョンでのデータ損失を最小限に抑えることができます。すべての Aurora PostgreSQL ベースのグローバルデータベース、およびエンジンバージョン 3.04.0 以降、または 2.12.0 以降の Aurora MySQL ベースのグローバルデータベースについては、Amazon CloudWatch を使用してすべてのセカンダリ DB クラスターの
AuroraGlobalDBRPOLagメトリクスを確認します。Aurora MySQL ベースのグローバルデータベースの下位マイナーバージョンについては、代わりにAuroraGlobalDBReplicationLagメトリクスを確認します。これらのメトリクスは、セカンダリクラスターがプライマリ DB クラスターに対してどのくらい遅れているか (ミリ秒単位) を示します。Aurora 向け CloudWatch メトリクスの詳細については、「Amazon Aurora のクラスターレベルのメトリクス」を参照してください。
マネージドフェイルオーバー中、選択したセカンダリ DB クラスターは、プライマリとして新しいロールに昇格されます。ただし、プライマリ DB クラスターのさまざまな設定オプションは継承されません。構成の不一致は、パフォーマンスの問題、ワークロードの非互換性、およびその他の異常な動作につながる可能性があります。このような問題を回避するには、Aurora Global Database クラスター間の次の違いを解決することをお勧めします。
新しいプライマリの Aurora DB クラスターパラメータグループの構成 (必要な場合) - Aurora Global Database の Aurora クラスターごとに Aurora DB クラスターパラメータグループを個別に設定できます。そのため、セカンダリ DB クラスターを昇格してプライマリロールを引き継ぐ場合、セカンダリからのパラメータグループは、プライマリとは異なる設定になることがあります。その場合は、プロモートされたセカンダリ DB クラスターのパラメータグループを、プライマリクラスターの設定に適合するように変更します。この方法については、「Aurora Global Database のパラメータの修正」を参照してください。
モニタリングツールとオプション (Amazon CloudWatch Events やアラームなど) - グローバルデータベースに必要なログ機能、アラームなどを使用して、昇格された DB クラスターの設定を行います。パラメータグループと同様に、フェイルオーバープロセス中にこれらの機能の設定がプライマリから継承されることはありません。レプリケーションラグなどの一部の CloudWatch メトリクスは、セカンダリリージョンのみで使用できます。そのため、フェイルオーバーによってメトリクスの表示方法やアラームの設定方法が変わり、定義済みのダッシュボードを変更する必要が生じる場合があります。Aurora DB クラスターとモニタリングの詳細については、「Amazon Aurora のメトリクスのモニタリングの概要」を参照してください。
他の AWS サービスとの統合を設定する - Aurora Global Database を AWS サービス (AWS Secrets Manager、AWS Identity and Access Management、Amazon S3、AWS Lambda など) と統合する場合は、それぞれに応じた設定を行う必要があります。IAM、Amazon S3、Lambda との Aurora Global Database の統合の詳細については、「Amazon Aurora Global Database を他の AWS サービスと併用する」を参照してください。Secrets Manager の詳細については、「AWS リージョン 間で AWS Secrets Manager のシークレットのレプリケーションを自動化する方法
」を参照してください。
通常、選択したセカンダリクラスターが数分以内に主要な役割を引き継ぎます。新しいプライマリリージョンのライターノードが使用可能になり次第、アプリケーションをそのライターノードに接続してワークロードを再開できます。Aurora が新しい主クラスターをプロモートすると、追加のセカンダリリージョンクラスターはすべて自動的に再構築されます。
Aurora グローバルデータベースは非同期レプリケーションを使用するため、各セカンダリリージョンのレプリケーションラグは異なる場合があります。Aurora はこれらのセカンダリリージョンを新しいプライマリリージョンクラスターとまったく同じポイントインタイムデータを持つように再構築します。ストレージボリュームのサイズとリージョン間の距離によっては、再構築タスクが完了するまでに数分から数時間かかることがあります。セカンダリージョンのクラスターが新しいプライマリリージョンからの再構築を完了すると、読み取りアクセスが可能になります。
新しいプライマリライターが昇格して使用可能になると、新しいプライマリリージョンのクラスターは Aurora グローバルデータベースの読み取りおよび書き込み操作を処理できるようになります。アプリケーションのエンドポイントを変更して、新しいエンドポイントを使用してください。Aurora Global Database の作成時に指定された名前を受け入れた場合は、アプリケーションの昇格されたクラスターのエンドポイント文字列から -ro を削除することで、エンドポイントを変更できます。
例えば、セカンダリクラスターのエンドポイント my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com は、そのクラスターがプライマリに昇格したときに my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com になります。
RDS Proxy を使用する場合、アプリケーションの書き込みオペレーションを、新しいプライマリクラスターに関連付けられているプロキシの適切な読み取り/書き込みエンドポイントにリダイレクトします。このプロキシエンドポイントは、デフォルトのエンドポイントでも、カスタムの読み取り/書き込みエンドポイントでもかまいません。詳細については、「RDS Proxy エンドポイントとグローバルデータベースの連携について」を参照してください。
グローバルデータベースクラスターの元のトポロジを復元するために、Aurora は古いプライマリリージョンの可用性を監視します。そのリージョンが正常になり、再び使用可能になるとすぐに、Aurora はそのリージョンをセカンダリリージョンとしてグローバルクラスターに自動的に追加します。古いプライマリリージョンに新しいストレージボリュームを作成する前に、Aurora は障害発生時点で古いストレージボリュームのスナップショットを作成しようとします。これにより、欠落しているデータを回復することができます。この操作が成功すると、Aurora は「rds:unplanned-global-failover-name-of-old-primary-DB-cluster-timestamp」というこのスナップショットを AWS Management Console のスナップショットセクションに入れます。このスナップショットは、DescribeDBClusterSnapshots API オペレーションによって返される情報にも一覧表示されています。
注記
古いストレージボリュームのスナップショットは、古い主クラスターに設定されたバックアップ保持期間の対象となるシステムスナップショットです。このスナップショットを保存期間外に保存するには、スナップショットをコピーして手動スナップショットとして保存できます。価格などのスナップショットのコピーの詳細については、「DB クラスタースナップショットのコピー」を参照してください。
元のトポロジが復元されたら、ビジネスとワークロードにとって最も都合のよいときにスイッチオーバー操作を実行することで、グローバルデータベースを元のプライマリリージョンにフェイルバックできます。これを行うには、「Amazon Aurora Global Database に対するスイッチオーバーの実行」の手順を実行します。
Aurora Global Database をフェイルオーバーするには AWS Management Console、AWS CLI、または RDS API を使用します。
Aurora グローバルデータベースでマネージドフェイルオーバーを実行するには
AWS Management Console にサインインし、Amazon RDS コンソール https://console.aws.amazon.com/rds/
を開きます。 [Databases (データベース)] を選択し、フェイルオーバーしたい Aurora Global Database を見つけます。
[アクション] メニューから [グローバルデータベースのスイッチオーバーまたはフェイルオーバー] を選択します。
![グローバルデータベースが選択された状態で [データベース] リストが表示され、[アクション] メニューが開いて [グローバルデータベースのスイッチオーバーまたはフェイルオーバー] オプションが表示されます。](images/aurora-global-db-managed-failover-1.png)
[フェイルオーバー (データ損失を許可)] を選択します。
![[フェイルオーバー (データ損失を許可)] が選択された [グローバルデータベースのスイッチオーバーまたはフェイルオーバー] ダイアログ。](images/aurora-global-db-managed-failover-2.png)
新しいプライマリクラスタ の場合、セカンダリ AWS リージョン の 1 つで新しいプライマリクラスターになるアクティブなクラスターを選択してください。
confirmを入力して [確認] を選択します。
フェイルオーバーが完了すると、次の画像に示すように、[データベース] リストから Aurora DB クラスターとその現在の状態を確認できます。
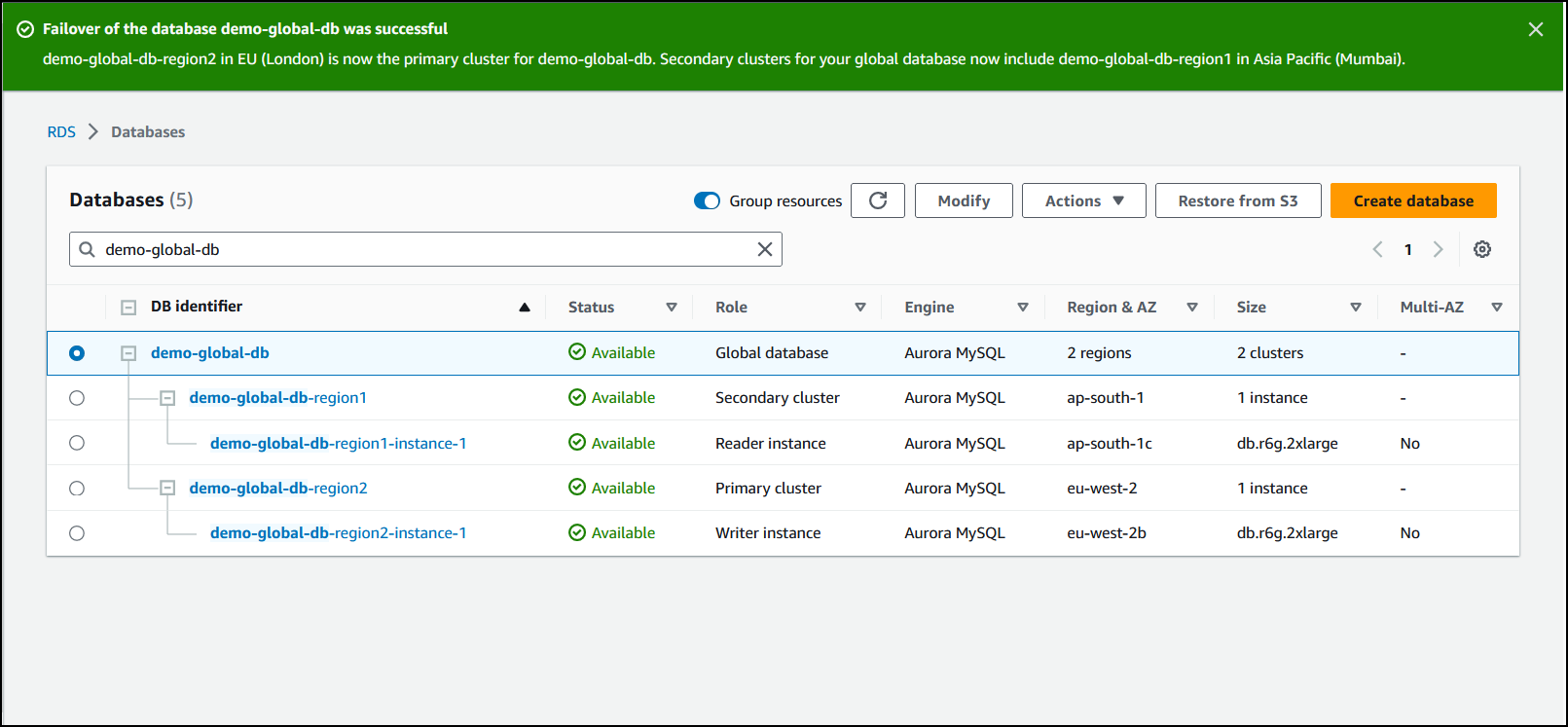
Aurora グローバルデータベースでマネージドフェイルオーバーを実行するには
failover-global-cluster CLI コマンドを使用して、Aurora Global Database をフェイルオーバーします。コマンドを使用して、次のパラメータ値を渡します。
-
--region— Aurora グローバルデータベースの新しいプライマリにしたいセカンダリ DB クラスターが DB クラスターで実行されている AWS リージョン を指定します。 --global-cluster-identifier- Aurora Global Database の名前を指定します。--target-db-cluster-identifier- Aurora Global Database の新しいプライマリに昇格する Aurora DB クラスターの Amazon リソースネーム (ARN) を指定します。--allow-data-loss— これをスイッチオーバー操作ではなくフェイルオーバー操作に明示的に設定します。非同期レプリケーションコンポーネントがレプリケートされたすべてのデータをセカンダリリージョンに送信していない場合、フェイルオーバー操作によってデータの一部が失われる可能性があります。
Linux、macOS、Unix の場合:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Windows の場合:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Aurora Global Database をフェイルオーバーするには、FailoverGlobalCluster API オペレーションを実行します。
Aurora Global Database のマニュアルフェイルオーバーを実行する
シナリオによっては、マネージドフェイルオーバープロセスを使用できない場合があります。一例として、プライマリ DB クラスターとセカンダリ DB クラスターで互換性のあるエンジンバージョンが稼働していない場合が挙げられます。この場合、このマニュアルプロセスに従って、グローバルデータベースをターゲットセカンダリリージョンにフェイルオーバーできます。
ヒント
このプロセスを理解してから使用することをお勧めします。リージョン全体にわたる問題の初期の兆候が見られたら、すぐに計画を進める準備をしてください。Amazon CloudWatch を定期的に使用してセカンダリクラスターのラグタイムを追跡することで、レプリケーションラグが最も少ないセカンダリリージョンを特定できます。実際に発生する前に計画をテストして、手順が完全かつ正確であることや、スタッフがディザスタリカバリフェイルオーバーの実行に習熟していることを確認します。
プライマリリージョンで予期しない停止が発生した後にセカンダリクラスターにマニュアルでフェイルオーバーするには
-
停止している AWS リージョン のプライマリ Aurora DB クラスターに対する、DML ステートメントおよびその他の書き込みオペレーションの発行を停止します。
-
新しいプライマリ DB クラスターとして使用するために、セカンダリ AWS リージョン の Aurora DB クラスターを指定します。Aurora Global Database に 2 つ以上のセカンダリ AWS リージョン がある場合は、レプリケーション遅延が最も少ないセカンダリクラスターを選択します。
選択したセカンダリ DB クラスターを Aurora Global Database からデタッチします。
Aurora Global Database からセカンダリ DB クラスターを削除すると、プライマリからこのセカンダリへのレプリケーションが直ちに停止され、完全な読み取り/書き込み機能を備えたスタンドアロンのプロビジョニングされた Aurora DB クラスターに昇格します。停止しているリージョン内のプライマリクラスターに関連付けられたその他のセカンダリ Aurora DB クラスターは引き続き利用可能で、アプリケーションからの呼び出しを受け付けることができます。また、リソースを使用することになります。Aurora Global Database を再作成しているので、次の手順で新しい Aurora Global Database を作成する前に、他のセカンダリ DB クラスターを削除します。これにより、Aurora Global Database 内の DB クラスター間のデータの不整合 (スプリットブレイン問題) が回避されます。
アタッチ解除の詳細なステップについては、Amazon Aurora Global Database からのクラスターの削除 を参照してください。
-
新しいエンドポイントを使用して、このスタンドアロン Aurora DB クラスターにすべての書き込み操作を送信するように、アプリケーションを再構成します。Aurora Global Database の作成時に指定された名前を受け入れた場合は、アプリケーション内のクラスターのエンドポイント文字列から
-roを削除することで、エンドポイントを変更できます。例えば、セカンダリクラスターのエンドポイント
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.comは、そのクラスターが Aurora Global Database からデタッチされたときにmy-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.comになります。この Aurora DB クラスターは、次のステップでリージョンを追加すると、新しい Aurora Global Database のプライマリクラスターになります。
RDS Proxy を使用する場合、アプリケーションの書き込みオペレーションを、新しいプライマリクラスターに関連付けられているプロキシの適切な読み取り/書き込みエンドポイントにリダイレクトします。このプロキシエンドポイントは、デフォルトのエンドポイントでも、カスタムの読み取り/書き込みエンドポイントでもかまいません。詳細については、「RDS Proxy エンドポイントとグローバルデータベースの連携について」を参照してください。
-
DB クラスターに AWS リージョン を追加します。これを行うと、プライマリからセカンダリへのレプリケーションプロセスがスタートされます。リージョンを追加する詳細なステップについては、AWS リージョン の Amazon Aurora Global Database への追加 を参照してください。
-
必要に応じて、AWS リージョン を追加して、アプリケーションのサポートに必要なトポロジを再作成します。
これらの変更を行う前、最中、および後に、アプリケーションの書き込みが正しい Aurora クラスターに送信されていることを確認してください。これにより、Aurora Global Database 内の DB クラスター間のデータの不整合 (スプリットブレイン問題) が回避されます。
AWS リージョン の停止に対して再設定を実行した場合、停止状態が解消された後に、AWS リージョン をプライマリに戻すことができます。このためには、古い AWS リージョン を新しいグローバルデータベースに追加し、スイッチオーバープロセスを使用してそのロールを切り替えます。Aurora Global Database では、スイッチオーバーをサポートする Aurora PostgreSQL または Aurora MySQL のバージョンを使用する必要があります。詳細については、「Amazon Aurora Global Database に対するスイッチオーバーの実行」を参照してください。
Amazon Aurora Global Database に対するスイッチオーバーの実行
注記
スイッチオーバーは、以前「管理型計画フェイルオーバー」と呼ばれていました。
スイッチオーバーを使用すると、プライマリクラスターのリージョンを定期的に変更できます。この機能は、運用メンテナンス、その他の計画された運用手順など、管理されたシナリオを対象としています。
スイッチオーバーを使用する一般的なユースケースは 3 つあります。
特定の業界に課せられる「リージョナルローテーション」要件向け。たとえば、金融サービス規制では、ディザスタリカバリ手順が定期的に実施されるように、Tier-0 システムを別の地域に数か月間切り替えることが求められる場合があります。
マルチリージョンの「follow-the-sun」アプリケーション向け。たとえば、ある企業が、さまざまなタイムゾーンの営業時間に基づいて、さまざまなリージョンで低レイテンシーの書き込みを提供したいとします。
データ損失ゼロの方法として、フェイルオーバー後に元のプライマリリージョンにフェイルバックします。
注記
スイッチオーバーは、正常な Aurora グローバルデータベースで使用するように設計されています。予期しないシステム停止から回復するには、予期しない停止からの Amazon Aurora Global Database の復旧 の該当する手順に従ってください。
スイッチオーバーを実行するには、エンジンのバージョンに応じて、パッチレベルを含め、ターゲットのセカンダリ DB クラスターがプライマリとまったく同じバージョンを実行している必要があります。詳細については、「マネージドクロスリージョンスイッチオーバーまたはフェイルオーバーに対するパッチレベルの互換性」を参照してください。スイッチオーバーを開始する前に、グローバルクラスター内のエンジンバージョンをチェックして、マネージドクロスリージョンスイッチオーバーをサポートしていることを確認し、必要に応じてアップグレードしてください。
スイッチオーバー中、グローバルデータベースの既存のレプリケーショントポロジを維持しながら、Aurora がプライマリクラスターを選択したセカンダリリージョンにスイッチオーバーします。スイッチオーバープロセスを開始する前に、Aurora はすべてのセカンダリリージョンクラスターがプライマリリージョンクラスターと完全に同期されるまで待ちます。次に、プライマリリージョンの DB クラスターは読み取り専用になり、選択したセカンダリ DB クラスターは、読み取り専用ノードの 1 つを、フルライターステータスに昇格させます。このノードをライターに昇格させると、そのセカンダリクラスターがプライマリクラスターの役割を引き受けることができます。プロセスのスタート時にすべてのセカンダリクラスターがプライマリと同期されているため、新しいプライマリは、データを失うことなく、Aurora Global Database の操作を続行します。プライマリクラスターと選択したセカンダリクラスターが新しいロールを引き受ける間、短時間データベースが使用できなくなります。
アプリケーションの可用性を最適化するには、この機能を使用する前に、次の操作を行うことをお勧めします。
-
この操作は、ピーク時以外に、またはプライマリ DB クラスターへの書き込みが最小限である別の時間に実行します。
アプリケーションをオフラインにして、Aurora Global Database のプライマリクラスターへの書き込みが送信されないようにします。
Aurora Global Database 内のすべてのセカンダリ Aurora DB クラスターのラグタイムを確認します。すべての Aurora PostgreSQL ベースのグローバルデータベース、およびエンジンバージョン 3.04.0 以降、または 2.12.0 以降の Aurora MySQL ベースのグローバルデータベースについては、Amazon CloudWatch を使用してすべてのセカンダリ DB クラスターの
AuroraGlobalDBRPOLagメトリクスを確認します。Aurora MySQL ベースのグローバルデータベースの下位マイナーバージョンについては、代わりにAuroraGlobalDBReplicationLagメトリクスを確認します。これらのメトリクスは、セカンダリクラスターがプライマリ DB クラスターに対してどのくらい遅れているか (ミリ秒単位) を示します。この値は、Aurora がスイッチオーバーを完了するまでにかかる時間に正比例します。したがって、遅延値が大きいほど、スイッチオーバーにかかる時間は長くなります。Aurora 向け CloudWatch メトリクスの詳細については、「Amazon Aurora のクラスターレベルのメトリクス」を参照してください。
スイッチオーバー中、選択したセカンダリ DB クラスターは、プライマリとして新しいロールに昇格されます。ただし、プライマリ DB クラスターのさまざまな設定オプションは継承されません。構成の不一致は、パフォーマンスの問題、ワークロードの非互換性、およびその他の異常な動作につながる可能性があります。このような問題を回避するには、Aurora Global Database クラスター間の次の違いを解決することをお勧めします。
新しいプライマリの Aurora DB クラスターパラメータグループの構成 (必要な場合) - Aurora Global Database の Aurora クラスターごとに Aurora DB クラスターパラメータグループを個別に設定できます。つまり、セカンダリ DB クラスターを昇格してプライマリロールを引き継ぐ場合、セカンダリからのパラメータグループは、プライマリとは異なる設定になることがあります。その場合は、プロモートされたセカンダリ DB クラスターのパラメータグループを、プライマリクラスターの設定に適合するように変更します。この方法については、「Aurora Global Database のパラメータの修正」を参照してください。
モニタリングツールとオプション (Amazon CloudWatch Events やアラームなど) - グローバルデータベースに必要なログ機能、アラームなどを使用して、昇格された DB クラスターの設定を行います。パラメータグループと同様に、スイッチオーバープロセス中にこれらの機能の設定がプライマリから継承されることはありません。レプリケーションラグなどの一部の CloudWatch メトリクスは、セカンダリリージョンのみで使用できます。そのため、スイッチオーバーによってメトリクスの表示方法やアラームの設定方法が変わり、定義済みのダッシュボードを変更する必要が生じる場合があります。Aurora DB クラスターとモニタリングの詳細については、「Amazon Aurora のメトリクスのモニタリングの概要」を参照してください。
他の AWS サービスとの統合を設定する - Aurora Global Database を AWS サービス (AWS Secrets Manager、AWS Identity and Access Management、Amazon S3、AWS Lambda など) と統合する場合は、必要に応じてこれらのサービスとの統合を必ず設定してください。IAM、Amazon S3、Lambda との Aurora Global Database の統合の詳細については、「Amazon Aurora Global Database を他の AWS サービスと併用する」を参照してください。Secrets Manager の詳細については、「AWS リージョン 間で AWS Secrets Manager のシークレットのレプリケーションを自動化する方法
」を参照してください。
注記
通常、ロールスイッチオーバーには数分かかることがあります。ただし、データベースのサイズとリージョン間の物理的な距離によって、追加のセカンダリクラスターの構築に数分から数時間かかる場合もあります。
スイッチオーバープロセスが完了すると、昇格された Aurora DB クラスターは Aurora Global Database の書き込み操作を処理できます。アプリケーションのエンドポイントを変更して、新しいエンドポイントを使用してください。Aurora Global Database の作成時に指定された名前を受け入れた場合は、アプリケーションの昇格されたクラスターのエンドポイント文字列から -ro を削除することで、エンドポイントを変更できます。
例えば、セカンダリクラスターのエンドポイント my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com は、そのクラスターがプライマリに昇格したときに my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com になります。
RDS Proxy を使用する場合、アプリケーションの書き込みオペレーションを、新しいプライマリクラスターに関連付けられているプロキシの適切な読み取り/書き込みエンドポイントにリダイレクトします。このプロキシエンドポイントは、デフォルトのエンドポイントでも、カスタムの読み取り/書き込みエンドポイントでもかまいません。詳細については、「RDS Proxy エンドポイントとグローバルデータベースの連携について」を参照してください。
Aurora Global Database をスイッチオーバーするには、AWS Management Console、AWS CLI、または RDS API を使用します。
Aurora グローバルデータベースでスイッチオーバーを実行するには
AWS Management Console にサインインし、Amazon RDS コンソール https://console.aws.amazon.com/rds/
を開きます。 [データベース] を選択し、フェイルオーバーしたい Aurora Global Database を見つけます。
[アクション] メニューから [グローバルデータベースのスイッチオーバーまたはフェイルオーバー] を選択します。
![グローバルデータベースが選択された状態で [データベース] リストが表示され、[アクション] メニューが開いて [グローバルデータベースのスイッチオーバーまたはフェイルオーバー] オプションが表示されます。](images/aurora-global-db-switchover-1.png)
[スイッチオーバー] を選択します。
![[フェイルオーバー (データ損失を許可)] が選択された [グローバルデータベースのスイッチオーバーまたはフェイルオーバー] ダイアログ。](images/aurora-global-db-switchover-2.png)
新しいプライマリクラスタ の場合、セカンダリ AWS リージョン の 1 つで新しいプライマリクラスターになるアクティブなクラスターを選択してください。
[確認] を選択します。
スイッチオーバーが完了すると、次の画像に示すように、[データベース] リストから Aurora DB クラスターとその現在のロールを確認できます。
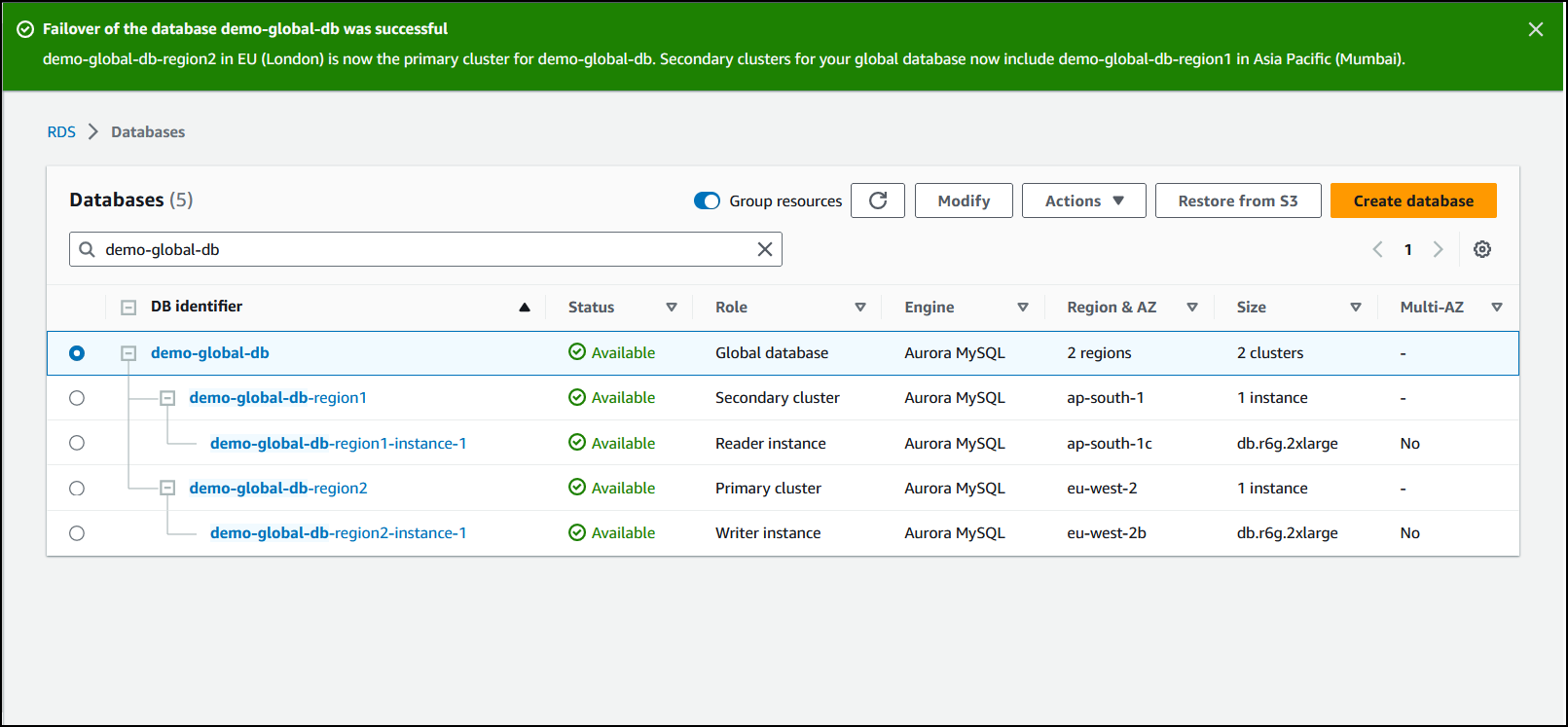
Aurora グローバルデータベースでスイッチオーバーを実行するには
switchover-global-cluster CLI コマンドを使用して、Aurora Global Database をスイッチオーバーします。コマンドを使用して、次のパラメータ値を渡します。
-
--region– Aurora Global Database のプライマリ DB クラスターが実行されている AWS リージョン を指定します。 --global-cluster-identifier- Aurora Global Database の名前を指定します。--target-db-cluster-identifier- Aurora Global Database のプライマリに昇格する Aurora DB クラスターの Amazon リソースネーム (ARN) を指定します。
Linux、macOS、Unix の場合:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Windows の場合:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Aurora グローバルデータベースをスイッチオーバーするには、SwitchoverGlobalCluster API オペレーションを実行します。
Aurora PostgreSQL- ベースのグローバルデータベースの RPO (目標復旧時点) 管理
Aurora PostgreSQL - ベースのグローバルデータベースでは、rds.global_db_rpo パラメータを使用して、目標復旧ポイント (RPO) を管理できます。RPO (目標復旧時点) は、停止時に失われる可能性があるデータの最大量を表します。
Aurora PostgreSQL - ベースのグローバルデータベースに RPO を設定する場合、Aurora はすべてのセカンダリクラスターの RPO ラグタイムをモニタリングし、少なくとも 1 つのセカンダリクラスターがターゲット RPO ウィンドウ内に留まることを確認します。RPO ラグタイムは、もう 1 つの時間ベースのメトリクスです。
RPO は、データベースが、フェイルオーバー後に新しい AWS リージョン でオペレーションを再開するときに使用されます。Aurora は、RPO と RPO ラグタイムを評価して、以下に示すように、プライマリでのトランザクションをコミット (またはブロック) します。
少なくとも 1 つのセカンダリ DB クラスターの RPO ラグタイムが RPO よりも短い場合に、トランザクションをコミットします。
すべてのセカンダリ DB クラスターの RPO ラグタイムが RPO よりも大きい場合、トランザクションをブロックします。また、イベントを PostgreSQL ログファイルに記録し、ブロックされたセッションを示す「待機」イベントも出力します。
つまり、すべてのセカンダリクラスターがターゲット RPO より遅れている場合、Aurora は、セカンダリクラスターの少なくとも 1 つが追いつくまでプライマリクラスターのトランザクションを一時停止します。1 つ以上のセカンダリ DB クラスターのラグタイムが RPO を下回るとすぐに、一時停止中のトランザクションが再開され、コミットされます。その結果、RPO (目標復旧時点) に達するまで、トランザクションはコミットできません。
rds.global_db_rpo パラメータは動的です。遅延が十分に減少するまですべての書き込みトランザクションを停止させたくない場合は、すぐにリセットできます。この場合、Aurora は少し遅れて変更を認識して実装します。
重要
グローバルデータベースが 2 つのリージョンにしかない場合、rds.global_db_rpo パラメータのデフォルト値をセカンダリージョンのパラメータグループに保持しておくことをお勧めします。そうしないと、プライマリリージョンが失われてこのリージョンにフェイルオーバーしたときに、Aurora はトランザクションを一時停止する可能性があります。代わりに、障害が発生した古いリージョンで Aurora がクラスターの再構築を完了するまで待ってから、このパラメータを変更して最大 RPO を適用してください。
このパラメータを以下に示すように設定すると、生成されたメトリクスをモニタリングすることもできます。これを行うには、psql または別のツールを使用して、Aurora Global Database のプライマリ DB クラスターをクエリし、Aurora PostgreSQL - ベースのグローバルデータベースの操作に関する詳細情報を取得できます。この方法については、「Aurora PostgreSQL ベースのグローバルデータベースのモニタリング」を参照してください。
目標復旧時点の設定
rds.global_db_rpo パラメータは、PostgreSQL データベースの RPO 設定を制御します。このパラメータは、Aurora PostgreSQL でサポートされています。有効な値の rds.global_db_rpo 範囲は 20 秒から 2,147,483,647 秒 (68 年) です。ビジネスニーズとユースケースに合わせて、現実的な価値をお選びください。例えば、RPO (目標復旧時点) に最大 10 分かかる場合があります。この場合、値を 600 に設定します。
この値は、AWS Management Console、AWS CLI、または RDS API を使用して、Aurora PostgreSQL ベースのグローバルデータベースに設定します。
RPO を設定するには
AWS Management Console にサインインし、Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 -
Aurora Global Database のプライマリクラスターを選択し、[Configuration (設定)] タブを開いて DB クラスターのパラメータグループを見つけます。例えば、Aurora PostgreSQL 11.7 を実行するプライマリ DB クラスターのデフォルトパラメータグループは
default.aurora-postgresql11です。パラメータグループは直接編集できません。代わりに、以下を実行できます。
適切なデフォルトパラメータグループをスタート点として使用して、カスタム DB クラスターのパラメータグループを作成します。例えば、
default.aurora-postgresql11に基づいてカスタム DB クラスターのパラメータグループを作成します。カスタム DB パラメータグループで、ユースケースに合わせて rds.global_db_rpo パラメータの値を設定します。有効な値の範囲は、20 秒から最大整数値 2,147,483,647 (68 年) までです。
変更した DB クラスターパラメータグループを Aurora DB クラスターに適用します。
詳細については、「Amazon Aurora の DB クラスターパラメータグループのパラメータの変更」を参照してください。
rds.global_db_rpo パラメータを設定するには、modify-db-cluster-parameter-group CLI コマンドを使用します。コマンドで、プライマリクラスターのパラメータグループの名前と RPO パラメータの値を指定します。
次の例では、my_custom_global_parameter_group という名前のプライマリ DB クラスターのパラメータグループの RPO を 600 秒 (10分) に設定します。
Linux、macOS、Unix の場合:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Windows の場合:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
rds.global_db_rpo パラメータを変更するには、Amazon RDS ModifyDBClusterParameterGroup API オペレーションを使用します。
目標復旧時点の表示
グローバルデータベースの目標復旧時点 (RPO) は、各 DB クラスターの rds.global_db_rpo パラメータに保存されます。表示するセカンダリクラスターのエンドポイントに接続し、この値についてインスタンスのクエリに psql を使用できます。
show rds.global_db_rpo;db-name=>
このパラメータが設定されていない場合、クエリは次の値を返します。
rds.global_db_rpo
-------------------
-1
(1 row)この次の応答は、1 分の RPO 設定を持つセカンダリ DB クラスターからのものです。
rds.global_db_rpo
-------------------
60
(1 row)CLI を使用して、クラスターのすべての rds.global_db_rpo パラメータ値を取得することで、Aurora DB クラスターのいずれかで user がアクティブかどうかを調べるための値を取得することもできます。
Linux、macOS、Unix の場合:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Windows の場合:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
このコマンドは、user または default-engine DB クラスターパラメータではないすべての system パラメータについて、次のような出力を返します。
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}クラスターパラメータグループのパラメータ表示の詳細については、Amazon Aurora の DB クラスターパラメータグループのパラメータ値の表示 を参照してください。
目標復旧時点の無効化
RPO を無効にするには、rds.global_db_rpo パラメータをリセットします。AWS Management Console、AWS CLI、または RDS API を使用してパラメータをリセットできます。
RPO を無効にするには
AWS Management Console にサインインし、Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 -
ナビゲーションペインで、[パラメータグループ] を選択します。
-
リストで、プライマリ DB クラスターパラメータグループを選択します。
-
[Edit parameters] を選択します。
-
[rds.global_db_rpo] パラメータの横にあるボックスを選択します。
-
[リセット] を選択します。
-
画面に [Reset parameters in DB parameter group (DB パラメータグループのパラメータのリセット)] が表示されたら、[Reset parameters (パラメータのリセット)] を選択します。
コンソールでパラメータをリセットする方法の詳細については、「Amazon Aurora の DB クラスターパラメータグループのパラメータの変更」を参照してください。
rds.global_db_rpo パラメータをリセットするには、reset-db-cluster-parameter-group コマンドを使用します。
Linux、macOS、Unix の場合:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Windows の場合:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
rds.global_db_rpo パラメータをリセットするには、Amazon RDS API ResetDBClusterParameterGroup オペレーションを使用します。
