翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
でのマルチサーバー評価レポートの作成 AWS Schema Conversion Tool
環境全体にとって最適なターゲットの方向性を決定するには、マルチサーバー評価レポートを作成します。
マルチサーバー評価レポートは、評価する各スキーマの定義に対して指定した入力に基づいて、複数のサーバーを評価します。スキーマ定義には、データベースサーバーの接続パラメータと各スキーマのフルネームが含まれています。各スキーマを評価した後、 は、複数のサーバー間のデータベース移行に関する集計された概要評価レポート AWS SCT を生成します。このレポートには、移行ターゲットごとに推定される複雑さが表示されます。
AWS SCT を使用して、次のソースデータベースとターゲットデータベースのマルチサーバー評価レポートを作成できます。
| ソースデータベース | ターゲットデータベース |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Azure SQL データベース |
Aurora MySQL、Aurora PostgreSQL、MySQL、PostgreSQL |
|
Azure Synapse Analytics |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 for z/OS |
Amazon Aurora MySQL 互換エディション (Aurora MySQL)、Amazon Aurora PostgreSQL 互換エディション (Aurora PostgreSQL)、MySQL, PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL、Aurora PostgreSQL、Amazon Redshift、Babelfish for Aurora PostgreSQL、MariaDB、Microsoft SQL Server、MySQL、PostgreSQL |
|
MySQL |
Aurora PostgreSQL、MySQL、PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL、Aurora PostgreSQL、Amazon Redshift、MariaDB、MySQL、Oracle、PostgreSQL |
|
[PostgreSQL] |
Aurora MySQL、Aurora PostgreSQL、MySQL、PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
マルチサーバー評価を実行する
次の手順を使用して、 でマルチサーバー評価を実行します AWS SCT。マルチサーバー評価 AWS SCT を実行するために で新しいプロジェクトを作成する必要はありません。開始する前に、データベース接続パラメータを含むカンマ区切り値 (CSV) ファイルを準備していることを確認してください。また、必要なデータベースドライバーがすべてインストールされていることを確認し、 AWS SCT の設定でドライバーの場所を設定してください。詳細については、「用の JDBC ドライバーのインストール AWS Schema Conversion Tool」を参照してください。
マルチサーバー評価を実行し、集約されたサマリーレポートを作成するには
-
で AWS SCT、ファイル、新しいマルチサーバー評価を選択します。[New multiserver assessment] (新しいマルチサーバー評価) ダイアログボックスが開きます。
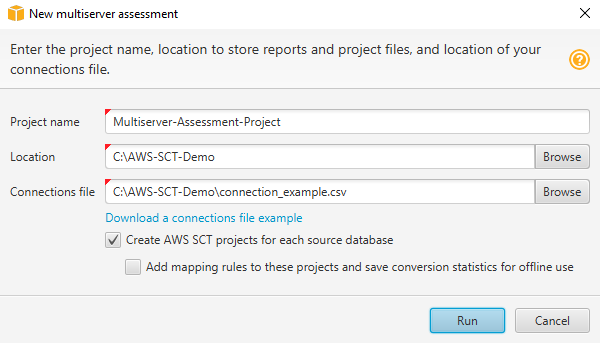
-
データベース接続パラメーターを含む CSV ファイルの空のテンプレートをダウンロードするには、「接続ファイルの例をダウンロード」を選択します。
-
[プロジェクト名]、[ロケーション] (レポートの保存先)、および [接続ファイル] (.csv ファイル) の値を入力します。
-
評価レポートの生成後に移行 AWS SCT プロジェクトを自動的に作成するには、ソースデータベースごとにプロジェクトを作成するを選択します。
-
各ソースデータベースの AWS SCT プロジェクトの作成をオンにすると、これらのプロジェクトにマッピングルールを追加し、オフライン用に変換統計を保存できます。この場合、 AWS SCT は各プロジェクトにマッピングルールを追加し、ソースデータベースメタデータをプロジェクトに保存します。詳細については、「でのオフラインモードの使用 AWS Schema Conversion Tool」を参照してください。
-
[実行] を選択します。
データベース評価のペースを示す進行状況バーが表示されます。ターゲットエンジンの数は、評価のランタイムに影響を与える可能性があります。
-
「すべてのデータベースサーバーの完全な分析には時間がかかる場合があります」というメッセージが表示された場合は、[はい] を選択します。続行しますか?
マルチサーバー評価レポートが完了すると、そのことを示す画面が表示されます。
-
[レポートを開く] を選択して、集約されたサマリー評価レポートを表示します。
デフォルトでは、 はすべてのソースデータベースの集計レポートと、ソースデータベース内の各スキーマ名の詳細評価レポート AWS SCT を生成します。詳細については、「レポートを検索して表示する」を参照してください。
ソースデータベースごとに AWS SCT プロジェクトを作成するオプションをオンにすると、 はソースデータベースごとに空のプロジェクト AWS SCT を作成します。 AWS SCT また、 は前述のように評価レポートを作成します。これらの評価レポートを分析し、ソースデータベースごとに移行先を選択したら、これらの空のプロジェクトにターゲットデータベースを追加します。
これらのプロジェクトにマッピングルールを追加し、オフライン使用の変換統計を保存するオプションをオンにすると、 はソースデータベースごとにプロジェクト AWS SCT を作成します。これらのプロジェクトには、次の情報が含まれます。
ソースデータベースと仮想ターゲットデータベースプラットフォーム。詳細については、「AWS Schema Conversion Tool の仮想ターゲットへのマッピング」を参照してください。
このソースとターゲットのペアのマッピングルール。詳細については、「データ型のマッピング」を参照してください。
このソースとターゲットのペアのデータベース移行評価レポート。
ソーススキーマメタデータ。オフラインモードでこの AWS SCT プロジェクトを使用できます。詳細については、「でのオフラインモードの使用 AWS Schema Conversion Tool」を参照してください。
入力 CSV ファイルの準備
接続パラメータをマルチサーバー評価レポートの入力として指定するには、次の例に示すように、CSV ファイルを使用します。
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
前の例では、セミコロンを使用して Sales データベースの 2 つのスキーマ名を区切っています。また、セミコロンを使用して Sales データベースの 2 つのターゲットデータベース移行プラットフォームを区切っています。
また、前の例では、 AWS Secrets Manager を使用してCustomersデータベースに接続し、Windows 認証を使用してHRデータベースに接続します。
新しい CSV ファイルを作成するか、 AWS SCT から CSV ファイルのテンプレートをダウンロードして、必要な情報を入力できます。CSV ファイルの最初の行に、前の例に示したのと同じ列名が含まれていることを確認してください。
入力 CSV ファイルのテンプレートをダウンロードするには
開始 AWS SCTします。
[ファイル]、[新しいマルチサーバー評価] の順に選択します。
[接続ファイルのサンプルをダウンロード] を選択します。
CSV ファイルに、テンプレートで指定された次の値が含まれていることを確認してください。
-
[名前] — データベースの識別に役立つテキストラベル。 AWS SCT は、このテキストラベルを評価レポートに表示します。
-
[説明] — オプションの値で、データベースに関する追加情報を入力できます。
-
[シークレットマネージャーキー] — データベースの認証情報を AWS Secrets Managerに保存するシークレットの名前。Secrets Manager を使用するには、必ず AWS プロファイルを保存してください AWS SCT。詳細については、「AWS Secrets Manager の の設定 AWS Schema Conversion Tool」を参照してください。
重要
AWS SCT 入力ファイルにサーバー IP、ポート、ログイン、パスワードパラメータを含めると、 は Secret Manager Key パラメータを無視します。
-
[サーバー IP] – ソースデータベースサーバーのドメインネームサービス (DNS) 名または IP アドレスを入力します。
-
[ポート]: ソースデータベースサーバーへの接続に使用するポート。
-
[サービス名] — サービス名を使用して Oracle データベースに接続する場合、接続する Oracle サービスの名前です。
-
[データベース名] — データベース名。Oracle データベースの場合は、Oracle システム ID (SID) を使用します。
-
[BigQuery パス] — ソース BigQuery データベースのサービスアカウントキーファイルへのパス。このファイルの作成の詳細については、「BigQuery をソースとする場合の権限」を参照してください。
-
[ソースエンジン] — ソースデータベースのタイプ。次のいずれかの値を使用します。
Azure SQL データベース用の [AZURE_MSSQL]。
Azure Synapse Analytics データベース用の [AZURE_SYNAPSE]。
BigQuery データベース用の [GOOGLE_BIGQUERY]。
IBM Db2 for z/OS データベース用の [DB2ZOS]。
IBM Db2 LUW データベース用の [DB2LUW]。
Greenplum データベース用の [GREENPLUM]。
Microsoft SQL Server データベース用の [MSSQL]。
MySQL データベース用の [MYSQL]。
Netezza データベース用の [NETEZZA]。
Oracle データベース用の [ORACLE]。
PostgreSQL データベース用の [POSTGRESQL]。
Amazon Redshift データベースの [REDSHIFT]。
Snowflake データベース用の [SNOWFLAKE]。
SAP ASE データベース用の [SYBASE_ASE]。
Teradata データベース用の [TERADATA]。
VERTICA はVertica データベース用の [VERTICA]。
-
[スキーマ名] — 評価レポートに含めるデータベーススキーマの名前。
Azure SQL Database、Azure Synapse Analytics、BigQuery、Netezza、SAP ASE、Snowflake、SQL Server では、次の形式のスキーマ名を使用してください。
db_name.schema_namedb_nameschema_nameドットを含むデータベース名またはスキーマ名は、次に示すように二重引用符で囲みます:
"database.name"."schema.name"。次に示すように、複数のスキーマ名をセミコロンで区切ります:
Schema1;Schema2。データベース名とスキーマ名では大文字が区別されます。
パーセント (
%) をワイルドカードとして使用すると、データベース名またはスキーマ名に含まれる任意の数のシンボルを置き換えることができます。前の例では、パーセント (%) をワイルドカードとして使用して、employeesデータベースのすべてのスキーマを評価レポートに含めています。 -
[Windows 認証を使用する] — Windows 認証を使用して Microsoft SQL Server データベースに接続する場合は、[true] と入力します。詳細については、「Microsoft SQL Server をソースとして使用するときの Windows 認証の使用」を参照してください。
-
[ログイン] – ソース データベース サーバーに接続するためのユーザー名。
-
[パスワード] – パスワードを入力して、ソースデータベースサーバーに接続します。
-
[SSL を使用する] — ソースデータベースへの接続に Secure Sockets Layer (SSL) を使用する場合は、true を入力します。
-
[信頼ストア] — SSL 接続に使用する信頼ストア。
-
[キーストア] — SSL 接続に使用するキーストア。
-
[SSL 認証] — 証明書による SSL 認証を使用する場合は、true を入力します。
-
[ターゲットエンジン] — ターゲットデータベースプラットフォーム。以下の値を使用して、評価レポートで 1 つ以上のターゲットを指定します。
Aurora MySQL 互換データベース用の [AURORA_MYSQL] 。
Aurora PostgreSQL 互換データベース用の [AURORA_POSTGRESQL]。
Babelfish for Aurora PostgreSQL データベース用の [BABELFISH ]。
MariaDB データベース用の [MARIA_DB]。
Microsoft SQL Server データベース用の [MSSQL]。
MySQL データベース用の [MYSQL]。
Oracle データベース用の [ORACLE]。
PostgreSQL データベース用の [POSTGRESQL]。
Amazon Redshift データベースの [REDSHIFT]。
複数のターゲットは、次のようにセミコロンを使用して区切ります:
MYSQL;MARIA_DBターゲットの数は、評価の実行にかかる時間に影響します。
レポートを検索して表示する
マルチサーバー評価では、2 種類のレポートが生成されます。
-
すべてのソースデータベースの集約レポート。
-
ソースデータベースの各スキーマ名ごとの、ターゲットデータベースに関する詳細な評価レポート。
レポートは、[新しいマルチサーバー評価] ダイアログボックス内の [ロケーション] で選択したディレクトリに保存されます。
詳細レポートにアクセスするには、ソースデータベース、スキーマ名、ターゲットのデータベースエンジン別に編成されたサブディレクトリをナビゲートします。
集約されたレポートでは、ターゲットデータベースの変換の複雑さに関する情報が 4 列にわたり表示されます。列には、コードオブジェクトの変換、ストレージオブジェクト、構文要素、および変換の複雑さに関する情報が含まれます。
次の例は、2 つの Oracle データベーススキーマを Amazon RDS for PostgreSQL に変換するための情報を示しています。

指定した追加のターゲットデータベースエンジンごとに、同じ 4 つの列がレポートに追加されます。
この情報の読み方の詳細については、次を参照してください。
集約評価レポートを出力する
の集約マルチサーバーデータベース移行評価レポートは、次の列を含む CSV ファイル AWS Schema Conversion Tool です。
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
情報を収集するために、 は完全な評価レポート AWS SCT を実行し、スキーマ別にレポートを集計します。
レポートでは、次の 3 つのフィールドに、評価に基づいて可能な自動コンバージョンの割合が表示されます。
- コードオブジェクトの変換率
-
自動または最小限の変更で変換 AWS SCT できるスキーマ内のコードオブジェクトの割合。コードオブジェクトには、プロシージャ、関数、ビューなどが含まれます。
- ストレージオブジェクトの変換率
-
SCT が自動的に、または最小限の変更で変換できるストレージオブジェクトの割合を示します。ストレージオブジェクトには、テーブル、インデックス、制約などが含まれます。
- 構文要素の変換率
-
SCT が自動的に変換できる構文要素の割合を示します。構文要素には
SELECT、FROM、DELETE、JOIN句などが含まれます。
変換の複雑さの計算は、アクション項目の概念に基づいています。アクション項目は、特定のターゲットへの移行中に手動で修正する必要があるソースコード内の問題のタイプを反映しています。アクション項目には複数のオカレンスがある場合があります。
加重スケールは、移行を実行する際の複雑さのレベルを示します。数字の 1 は最低レベルの複雑さを表し、10 は最高レベルの複雑さを表します。
