翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS クリーンルーム ML
AWS Clean Rooms ML では、2 人以上の関係者がデータで機械学習モデルを実行でき、相互にデータを共有する必要はありません。このサービスは、データ所有者がデータとモデル IP を保護できるようにするプライバシー強化コントロールを提供します。 AWS オーサリングされたモデルを使用するか、独自のカスタムモデルを取り込むことができます。
この動作の詳細な説明については、「クロスアカウントジョブ」を参照してください。
Clean Rooms ML モデルの機能の詳細については、以下のトピックを参照してください。
トピック
AWS Clean Rooms ML の用語
Clean Rooms ML を使用する場合は、次の用語を理解することが重要です。
-
トレーニングデータプロバイダー – トレーニングデータを提供し、類似モデルを作成および設定し、その類似モデルをコラボレーションに関連付ける関係者。
-
シードデータプロバイダー – シードデータを提供し、類似セグメントを生成し、その類似セグメントをエクスポートする関係者。
-
トレーニングデータ – 類似モデルの生成に使用されるトレーニングデータプロバイダーのデータ。トレーニングデータは、ユーザーの行動の類似性を測定するために使用されます。
トレーニングデータには、ユーザー ID、項目 ID、タイムスタンプ列が含まれている必要があります。オプションで、トレーニングデータには数値特徴量またはカテゴリ別特徴量として他のインタラクションを含めることができます。インタラクションの例としては、視聴した動画のリスト、購入したアイテム、読んだ記事などがあります。
-
シードデータ – 類似セグメントの作成に使用されるシードデータプロバイダーのデータ。シードデータは直接提供することも、 AWS Clean Rooms クエリの結果から取得することもできます。類似セグメントの出力は、トレーニングデータに含まれるシードユーザーに最も近いユーザーの集合です。
-
類似モデル – 他のデータセット内の類似ユーザーを見つけるために使用されるトレーニングデータの機械学習モデル。
API を使用する場合、オーディエンスモデルという用語は類似モデルと同じ意味で使用されます。例えば、CreateAudienceModel API を使用して類似モデルを作成します。
-
類似セグメント – シードデータに最も近いトレーニングデータのサブセット。
API を使用するときは、StartAudienceGenerationJob API を使用して類似セグメントを作成します。
トレーニングデータプロバイダーのデータがシードデータプロバイダーと共有されることはなく、シードデータプロバイダーのデータがトレーニングデータプロバイダーと共有されることもありません。類似セグメントの出力はトレーニングデータプロバイダーと共有されますが、シードデータプロバイダーと共有されることはありません。
AWS Clean Rooms ML が AWS モデルと連携する方法
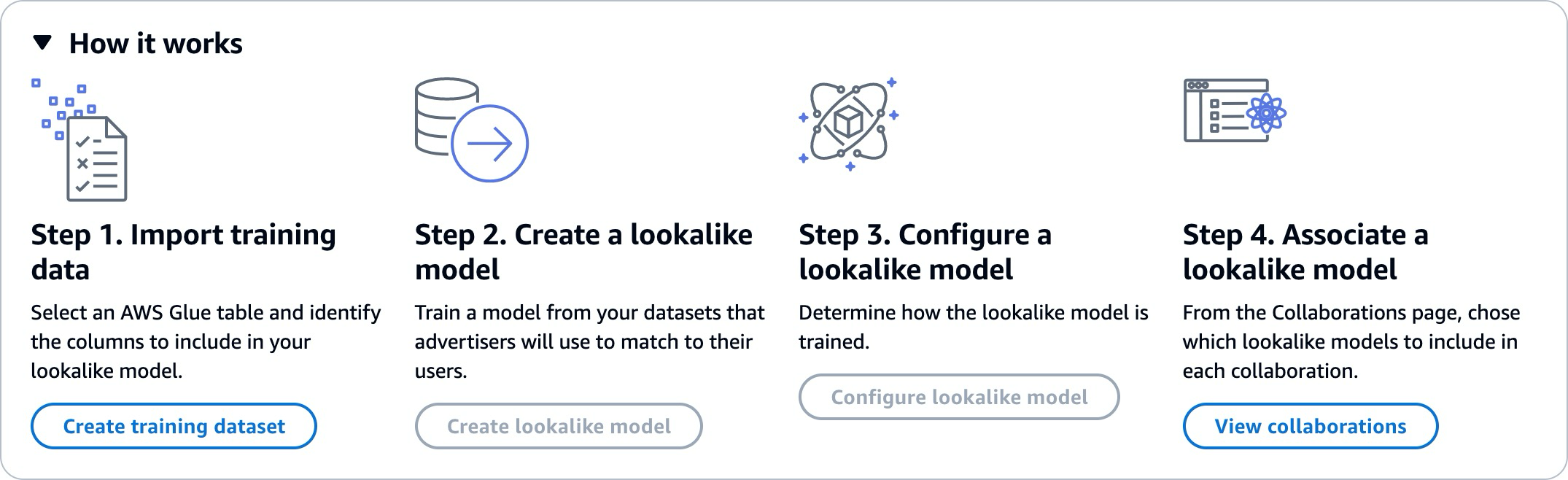
類似モデルを使用するには、トレーニングデータプロバイダーとシードデータプロバイダーの 2 つの関係者が、データをコラボレーションに取り込む AWS Clean Rooms ために順番に で作業する必要があります。トレーニングデータプロバイダーが最初に完了しなければならないワークフローは次のとおりです。
-
トレーニングデータプロバイダーのデータは、ユーザーとアイテムのインタラクション AWS Glue のデータカタログテーブルに保存する必要があります。少なくとも、トレーニングデータにはユーザー ID 列、インタラクション ID 列、およびタイムスタンプ列が含まれている必要があります。
-
トレーニングデータプロバイダーは、トレーニングデータを に登録します AWS Clean Rooms。
-
トレーニングデータプロバイダーは、複数のシードデータプロバイダーと共有できる類似モデルを作成します。類似モデルはディープニューラルネットワークであり、トレーニングに最大 24 時間かかることがあります。このモデルは自動的に再トレーニングされないため、毎週再トレーニングすることをお勧めします。
-
トレーニングデータプロバイダーは、関連メトリクスを共有するかどうかや、出力セグメントの Amazon S3 ロケーションなど、類似モデルの設定を行います。トレーニングデータプロバイダーは、1 つの類似モデルから複数の設定済み類似モデルを作成できます。
-
トレーニングデータプロバイダーは、設定したオーディエンスモデルをシードデータプロバイダーと共有されているコラボレーションに関連付けます。
シードデータプロバイダーが次に完了しなければならないワークフローは次のとおりです。
-
シードデータプロバイダーのデータは Amazon S3 バケットに保存することも、クエリの結果から取得することもできます。
-
シードデータプロバイダーは、トレーニングデータプロバイダーと共有するコラボレーションを開きます。
-
シードデータプロバイダーは、コラボレーションページの [Clean Rooms ML] タブから類似セグメントを作成します。
-
シードデータプロバイダーは、関連性メトリクスが共有されていれば、それを評価し、 AWS Clean Roomsの外部で使用するために類似セグメントをエクスポートできます。
AWS Clean Rooms ML がカスタムモデルと連携する方法
Clean Rooms ML を使用すると、コラボレーションのメンバーは Amazon ECR に保存されているドッカー化されたカスタムモデルアルゴリズムを使用して、データを共同で分析できます。これを行うには、モデルプロバイダーがイメージを作成し、Amazon ECR に保存する必要があります。Amazon Elastic Container Registry ユーザーガイドの手順に従って、カスタム ML モデルを含むプライベートリポジトリを作成します。
コラボレーションのメンバーは、適切なアクセス許可があれば、モデルプロバイダーになることができます。コラボレーションのすべてのメンバーは、トレーニングデータ、推論データ、またはその両方をモデルに提供できます。このガイドでは、データを提供するメンバーをデータプロバイダーと呼びます。コラボレーションを作成するメンバーはコラボレーション作成者であり、このメンバーはモデルプロバイダー、データプロバイダーの 1 つ、またはその両方です。
最も高いレベルでは、カスタム ML モデリングを実行するために完了する必要がある手順は次のとおりです。
-
コラボレーション作成者はコラボレーションを作成し、各メンバーに適切なメンバー機能と支払い設定を割り当てます。コラボレーションクリエーターは、コラボレーションの作成後に更新できないため、モデル出力を受信するか、推論結果を受信する機能をこのステップの適切なメンバーに割り当てる必要があります。詳細については、「AWS Clean Rooms ML でのコラボレーションの作成と参加」を参照してください。
-
モデルプロバイダーは、コンテナ化された ML モデルを設定してコラボレーションに関連付け、エクスポートされたデータにプライバシー制約が設定されていることを確認します。詳細については、「AWS Clean Rooms ML でのモデルアルゴリズムの設定」を参照してください。
-
データプロバイダーは、コラボレーションにデータを提供し、プライバシーのニーズを確実に指定します。データプロバイダーは、モデルがデータにアクセスすることを許可する必要があります。詳細については、「AWS Clean Rooms ML でのトレーニングデータの提供」および「AWS Clean Rooms ML で設定されたモデルアルゴリズムの関連付け」を参照してください。
-
コラボレーションメンバーは、モデルアーティファクトまたは推論結果がエクスポートされる場所を定義する ML 設定を作成します。
-
コラボレーションメンバーは、トレーニングコンテナまたは推論コンテナに入力を提供する ML 入力チャネルを作成します。ML 入力チャネルは、モデルアルゴリズムのコンテキストで使用されるデータを定義するクエリです。
-
コラボレーションメンバーは、ML 入力チャネルと設定されたモデルアルゴリズムを使用してモデルトレーニングを呼び出します。詳細については、「AWS Clean Rooms ML でのトレーニング済みモデルの作成」を参照してください。
-
(オプション) モデルトレーナーはモデルエクスポートジョブを呼び出し、モデルアーティファクトがモデル結果レシーバーに送信されます。有効な ML 設定を持ち、モデル出力を受け取ることができるメンバーのみがモデルアーティファクトを受け取ることができます。詳細については、「AWS Clean Rooms ML からのモデルアーティファクトのエクスポート」を参照してください。
-
(オプション) コラボレーションメンバーは、ML 入力チャネル、トレーニング済みモデル ARN、推論設定済みモデルアルゴリズムを使用してモデル推論を呼び出します。推論結果は推論出力レシーバーに送信されます。有効な ML 設定を持ち、推論出力を受け取ることができるメンバーのみが推論結果を受け取ることができます。
モデルプロバイダーが完了する必要があるステップは次のとおりです。
-
SageMaker AI 互換 Amazon ECR Docker イメージを作成します。Clean Rooms ML は、SageMaker AI 互換のドッカーイメージのみをサポートしています。
-
SageMaker AI 互換の Docker イメージを作成したら、そのイメージを Amazon ECR にプッシュします。Amazon Elastic Container Registry ユーザーガイドの指示に従って、コンテナトレーニングイメージを作成します。
-
Clean Rooms ML で使用するモデルアルゴリズムを設定します。
-
Amazon ECR リポジトリリンクと、モデルアルゴリズムの設定に必要な引数を指定します。
-
Clean Rooms ML が Amazon ECR リポジトリにアクセスできるようにするサービスアクセスロールを提供します。
-
設定されたモデルアルゴリズムをコラボレーションに関連付けます。これには、コンテナログ、障害ログ、CloudWatch メトリクスのコントロール、およびコンテナ結果からエクスポートできるデータ量に関する制限を定義するプライバシーポリシーの提供が含まれます。
-
カスタム ML モデルとコラボレーションするためにデータプロバイダーが完了する必要がある手順は次のとおりです。
-
カスタム分析ルールを使用して既存の AWS Glue テーブルを設定します。これにより、特定の一連の事前承認されたクエリまたは事前承認されたアカウントでデータを使用できます。
-
設定済みテーブルをコラボレーションに関連付け、 AWS Glue テーブルにアクセスできるサービスアクセスロールを提供します。
-
設定されたモデルアルゴリズムの関連付けが設定されたテーブルにアクセスできるようにするコラボレーション分析ルールをテーブルに追加します。
-
モデルとデータを Clean Rooms ML で関連付けて設定すると、クエリを実行できるメンバーは SQL クエリを提供し、使用するモデルアルゴリズムを選択します。
モデルトレーニングが完了すると、そのメンバーはモデルトレーニングアーティファクトまたは推論結果のエクスポートを開始します。これらのアーティファクトまたは結果は、トレーニングされたモデル出力を受信できるメンバーに送信されます。結果レシーバーは、モデル出力を受け取るMachineLearningConfiguration前に を設定する必要があります。
