翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS DeepRacer コンソールを使用した AWS DeepRacer モデルのトレーニングと評価
強化学習モデルをトレーニングするには AWS DeepRacer コンソールを使用できます。コンソールで、トレーニングジョブを作成し、サポートされているフレームワークと利用可能なアルゴリズムを選択し、報酬関数を追加して、トレーニング設定を設定します。シミュレーターでトレーニングの進捗状況を確認することもできます。詳細な手順については、「最初の AWS DeepRacer モデルのトレーニング 」を参照してください。
このセクションでは、AWS DeepRacer モデルの学習方法と評価方法について説明します また、報酬関数の作成方法と改善方法、アクションスペースがモデルのパフォーマンスに与える影響、ハイパーパラメータがトレーニングのパフォーマンスに与える影響についても説明します。また、トレーニングモデルのクローンを作成してトレーニングセッションを延長する方法、シミュレーターを使用してトレーニングのパフォーマンスを評価する方法、およびシミュレーションの一部を実世界の課題に対処させる方法についても学習できます。
トピック
報酬関数を作成する
報酬関数とは、AWS DeepRacer の車両がトラック上のある位置から新しい位置に移動したときの、即座のフィードバック (報酬またはペナルティスコアとして) を表します。この関数の目的は、事故や違反なく、目的の場所にすばやく到着するために車両をトラックに沿って移動させることです。望ましい動きはそのアクションまたはその目標状態に対してより高い得点を得ることができます。違法な動きまたは無駄な動きをするとより低いスコアになります。AWS DeepRacer モデルをトレーニングする場合、報酬関数は唯一のアプリケーション固有の部分になります。
一般的に、報酬関数はインセンティブプランのように機能するように設計します。インセンティブ戦略が異なると、車両の動作が異なる可能性があります。車両をより速く走らせるために、この関数が車両がトラックに沿って走行することに対して報酬を与える必要があります。この関数は、車両がラップを終了するのに時間がかかりすぎたり、トラックから外れたときにペナルティを課す必要があります。ジグザグな運転パターンを避けるために、トラックのまっすぐな部分ではあまりステアリングを使用しない車両に報酬を与える場合があります。によって測定されるように、車両が特定のマイルストーンを通過すると、報酬関数はプラスのスコアを与える場合があります。waypointsこれは待機や間違った方向への運転を軽減する可能性があります。また、トラックのコンディションを考慮して報酬関数を変更する場合もあります。ただし、報酬関数が環境固有の情報を考慮に入れるほど、トレーニングされたモデルが過適合となり、汎用性が失われます。モデルをより一般的に適用可能にするために、アクションスペースを探索することができます。
インセンティブプランは慎重に考慮されない場合、意図しない反対の結果
報酬関数を作成する際は、基本的なシナリオをカバーした簡単なものから始めることをお勧めします。より多くのアクションを処理するように関数を拡張することができます。それでは、いくつかの簡単な報酬関数を見てみましょう。
報酬関数の簡単な例
最も基本的な状況を最初に検討することによって、報酬関数の構築を開始することができます。トラックから外れることなく最初から最後まで直線的なトラックを運転しているという状況です。このシナリオでは、報酬関数ロジックは on_track と progress のみに依存します。トライアルとして、次のロジックから始めることができます。
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
このロジックでは、エージェントがトラックから外れるとエージェントにペナルティが課されます。エージェントが終了地点に到達すると報酬が与えられます。指定された目標を達成するために合理的です。ただし、エージェントは、トラックを逆方向に進むことも含め、開始地点と終了地点の間を自由に移動します。トレーニングを完了するのに長い時間がかかるだけでなく、トレーニングされたモデルでも、実世界の車両にデプロイした場合に運転効率が低下する可能性があります。
実際には、エージェントは、トレーニングのコースを通して少しずつ学習できれば、より効果的に学習します。これは、報酬関数がトラックに沿って段階的に小さい報酬を与える必要があることを意味します。エージェントが直線的なトラックを走るためには、次のように報酬関数を改善することができます。
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
この関数では、エージェントはフィニッシュラインに近づくほど報酬が増えます。これによっては非生産的な逆方向への運転の試行を減らすか排除するはずです。一般的に、私たちは報酬関数がアクション空間により均一に報酬を分配することを望みます。効果的な報酬関数を作成することは、困難な仕事です。簡単な関数から始めて、徐々に強化または改善してください。体系的な実験により、関数はより堅牢で効率的になります。
自分の報酬関数を強化する
AWS DeepRacer モデルをシンプルな直線的なトラック用に正常にトレーニングすると、AWS DeepRacer 車両 (仮想または物理的) がトラックから外れることなく走行できるようになります。ループされたトラック車両で走らせると、トラック上にとどまりません。報酬関数はトラックをたどるためにターンをするアクションを無視しました。
車両にこれらのアクションに対応させるためには、報酬関数を強化する必要があります。エージェントが許容されるターンを行った場合にはその関数は報酬を与え、エージェントが違法なターンを行った場合にはペナルティを課す必要があります。別のラウンドのトレーニングを開始する準備が整いました。以前のトレーニングを活用するには、以前にトレーニングされたモデルをクローンして、以前に学習した知識を引き継いで新しいトレーニングを開始できます。このパターンに従って、ますます複雑な環境で運転する AWS DeepRacer 車両をトレーニングするために、報酬関数にさらに機能を追加することができるようになります。
より高度な報酬関数については、以下の例を参照してください。
堅牢なモデルをトレーニングするためのアクションスペースを探す
原則として、できるだけ多くの環境に適用できるように、モデルをできる限り堅牢になるようにトレーニングしてください。堅牢なモデルは、広範囲のトラックの形状や条件に適用できるものです。一般的に、堅牢なモデルはその報酬関数が明示的な環境特有の知識を含む能力を持っていないので「スマート」ではありません。そうでなければ、モデルはトレーニングされた環境に似た環境にのみ適用可能である可能性があります。
環境固有の情報を報酬関数に明示的に組み込むことは、特徴量エンジニアリングに相当します。特徴量エンジニアリングはトレーニング時間を短縮するのに役立ち、特定の環境に合わせて作られたソリューションに役立ちます。ただし、一般的な適用性のモデルをトレーニングするには、多くの特徴量エンジニアリングを試みることを控える必要があります。
たとえば、循環トラックでモデルをトレーニングする場合、そのような幾何学的プロパティを明示的に報酬関数に組み込んでいる場合は、循環以外のトラックに適用可能なトレーニング済みモデルを入手することは期待できません。
報酬関数を可能な限りシンプルに保ちながら、モデルをできる限り頑健にトレーニングする方法について教えてください。1 つの方法はエージェントが取ることができるアクションにまたがるアクションスペースを探すことです。もう 1 つの方法は、基礎となるトレーニングアルゴリズムのハイパーパラメータで実験することです。多くの場合、両方を使用します。ここでは、アクションスペースを探索して、AWS DeepRacer 車両の堅牢なモデルをトレーニングする方法に焦点を当てます。
AWS DeepRacer モデルのトレーニングでは、アクション (a)は 速度 (t メートル/秒) とステアリング角度 (s 度) の組み合わせになります。エージェントのアクションスペースは、エージェントが取り得る速度とステアリングの範囲を定義します。速度の m 数、(v1, .., vn) およびステアリングの n 数、(s1, ..,
sm) の個別のアクションスペースの場合、アクションスペースには m*n の可能なアクションがあります。
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
(vi,
sj) の実際の値は vmax と |smax| の範囲によって異なり、均一に分布しているわけではありません。
お客様の AWS DeepRacer モデルのトレーニングを開始するかまたは反復するたびに、まずn、m、vmax、および |smax| を指定するか、それらのデフォルト値を使用することに同意する必要があります。選択に基づいて、AWS DeepRacer サービスはエージェントがトレーニングで選択できる利用可能なアクションを生成します。生成されたアクションは、アクションスペース全体に均一に分布しているわけではありません。
一般的に、より多くのアクションとより大きなアクション範囲は、不規則な回転角や方向を持つ曲線トラックなど、より多様なトラック条件に対応するためのより多くのスペースまたはオプションをエージェントに提供します。エージェントが利用できるオプションが多ければ多いほど、トラックのバリエーションをより簡単に処理できます。その結果、単純な報酬関数を使用している場合でも、トレーニング済みモデルがより広く適用可能になることが期待できます。
たとえば、エージェントは、わずかな速度とステアリング角で荒削りなアクションスペースを使用した直線トラックに対応することを素早く学習することができます。曲線トラックでは、この荒削りなアクションスペースのために、エージェントは行き過ぎて、ターンする際にトラックから外れる可能性があります。これは、速度やステアリングを調整するためのオプションが十分にないためです。速度またはステアリングの数、あるいはその両方を増やすことにより、エージェントは、トラックに沿いながらカーブに対応できるようになります。同様に、エージェントがジグザグに動く場合は、任意のステップでステアリング範囲の数を増やすことを試みることで急激なターンを減らすことができます。
アクションスペースが大きすぎると、アクションスペースを探索するのにより長い時間がかかるため、トレーニングのパフォーマンスが低下する可能性があります。モデルの一般的な適用性のメリットとトレーニングのパフォーマンス要件とのバランスをとるようにしてください。この最適化には体系的な実験が含まれています。
ハイパーパラメータを体系的に調整する
モデルのパフォーマンスを向上させる 1 つの方法は、より優れた、またはより効果的なトレーニングプロセスを実行することです。たとえば、堅牢なモデルを取得するには、トレーニングによって、エージェントのアクションスペース全体にわたって、エージェントが多かれ少なかれ均等に分散したサンプリングを提供する必要があります。これには、探査と搾取の十分な組み合わせが必要です。これに影響を与える変数には、使用されるトレーニングデータの量 (number of episodes between each
training および batch size)、エージェントがどれだけ早く学習できるか (learning rate)、探索の一部 (entropy) が含まれます。実用的なトレーニングを行うには、学習プロセスを高速化する必要があります。これに影響を与える変数には、learning rate、batch size、number of
epochs、discount factor があります。
トレーニングプロセスに影響を与える変数は、トレーニングのハイパーパラメータとして知られています。これらのアルゴリズムの属性は、基盤となるモデルのプロパティではありません。残念ながら、ハイパーパラメータは本質的に経験的なものです。これらの最適値は、すべての実用的な目的に対して知られているわけではなく、導き出すために体系的な実験を必要とします。
AWS DeepRacer モデルのトレーニングのパフォーマンスを調整するために調整できるハイパーパラメータについて説明する前に、次の用語を定義しましょう。
- データポイント
-
データポイントは、経験としても知られており、(s,a,r,s’) の連符です。ここで、s はカメラによってキャプチャされた模様 (または状態)、a は車両によって実行されたアクションを表します。rは、その行動によってもたらされる予想される報酬のためのものであり、そして s’ はその行動がとられた後の新しい模様のためのものです。
- エピソード
-
エピソードとは、車両が任意の出発点から出発し、最終的にトラックを完走するかまたはトラックから外れるまでの期間です。これにより一連のエクスペリエンスが具体化されます。エピソードごとに長さが異なる場合があります。
- エクスペリエンスバッファ
-
エクスペリエンスバッファは、トレーニング中にさまざまな長さの一定数のエピソードにわたって収集された多数の順序付けられたデータ点から構成されています。AWS DeepRacer の場合、それは AWS DeepRacer 車両に搭載されたカメラによって捉えられた画像と車両によって取られたアクションに対応し、基盤となる (ポリシーと値) ニューラルネットワークを更新するための入力が引き出される情報源として機能します。
- バッチ
-
バッチは、ポリシーネットワークの重みを更新するために使用される、一定期間にわたるシミュレーションの一部を表すエクスペリエンスの順序付きリストです。これはエクスペリエンスバッファのサブセットです。
- トレーニングデータ
-
トレーニングデータは、エクスペリエンスバッファからランダムにサンプリングされ、ポリシーネットワークの重みをトレーニングするために使用されるバッチのセットです。
| ハイパーパラメータ | 説明 |
|---|---|
|
勾配降下のバッチサイズ |
最近の車両エクスペリエンスの数はエクスペリエンスバッファから無作為に抽出され、基盤となる深層学習ニューラルネットワークの重みを更新するために使用されます。無作為抽出は、入力データに内在する相関関係を低減するのに役立ちます。より大きなバッチサイズを使用して、ニューラルネットワークの重みをより安定してスムーズに更新するようにしますが、トレーニングが長くなったり遅くなったりする可能性があるので注意してください。
|
|
[エポック数] |
勾配降下中にニューラルネットワークの重みを更新するためにトレーニングデータを通過する回数。トレーニングデータはエクスペリエンスバッファからの無作為抽出に対応します。より安定した更新を促進するために多数のエポックを使用しますが、トレーニングが遅くなることが予想されます。バッチサイズが小さい場合は、少数のエポックを使用できます。
|
|
[学習レート] |
各更新中に、新しい重みの一部は勾配降下 (または上昇) の寄与から得られ、残りは既存の重みの値から得られます。学習レートは、勾配降下 (または上昇) の更新がネットワークの重みにどれだけ寄与するかを制御します。より高い学習レートを使用してより速いトレーニングのための勾配降下寄与をより多く含めますが、学習レートが大きすぎると予想される報酬が収束しない可能性があることに注意してください。
|
Entropy |
ポリシー配布に無作為性を追加するタイミングを決定するために使用されるある程度の不確実性。不確実性が増したことで、AWS DeepRacer 車両はアクションスペースをより広く探索することができます。エントロピー値が大きいほど、車両はアクションスペースをより徹底的に探索します。
|
| [割引係数] |
係数は、将来の報酬が期待される報酬にどのくらい寄与するかを指定します。割引係数の値が大きいほど、車両がアクションを実行するとみなしている寄与の範囲が広くなり、トレーニングが遅くなります 割引係数が 0.9 の場合、移動のために将来の 10 ステップのオーダーからの報酬が含まれます。0.999 の割引係数で、車両は移動をするために将来の 1000 ステップのオーダーからの報酬を考慮します。推奨される割引係数値は、0.99、0.999 および 0.9999 です。
|
| [損失タイプ] |
ネットワークの重みを更新するために使用される目標関数のタイプ。優れたトレーニングアルゴリズムは、エージェントの戦略を徐々に変化させて、ランダムなアクションをとることから、報酬を増やすための戦略的なアクションをとることへと徐々に移行するべきです。しかし、それがあまりにも大きな変化をするならば、トレーニングは不安定になりエージェントは学習しません。[Huber 損失
|
| [各ポリシー更新反復間のエクスペリエンスエピソードの数] | ポリシーネットワークの重み付けを学習するためのトレーニングデータを取得するために使用されるエクスペリエンスバッファのサイズ。エピソードとは、エージェントが任意の出発点から出発し、最終的にトラックを完走するかまたはトラックから外れるまでの期間です。一連のエクスペリエンスで構成されます。エピソードごとに長さが異なる場合があります。単純な強化学習問題では、エクスペリエンスバッファが少なくて済み、学習は速いです。より多くのローカル最大値のあるより複雑な問題では、より多くの相関性のないデータポイントを提供するためにより大きなエクスペリエンスバッファが必要です。この場合、トレーニングは遅くなりますが、安定しています。推奨される値は 10、20 および 40 です。
|
AWS DeepRacer Trainingトレーニングジョブの進行状況を調べる
トレーニングジョブを開始した後、エピソードごとの報酬とトラック完走状況のトレーニングメトリクスを調べ、モデルのトレーニングジョブのパフォーマンスを確認できます。AWS DeepRacer コンソールでは、メトリクスは以下の図に示すように [報酬グラフ」に表示されます。
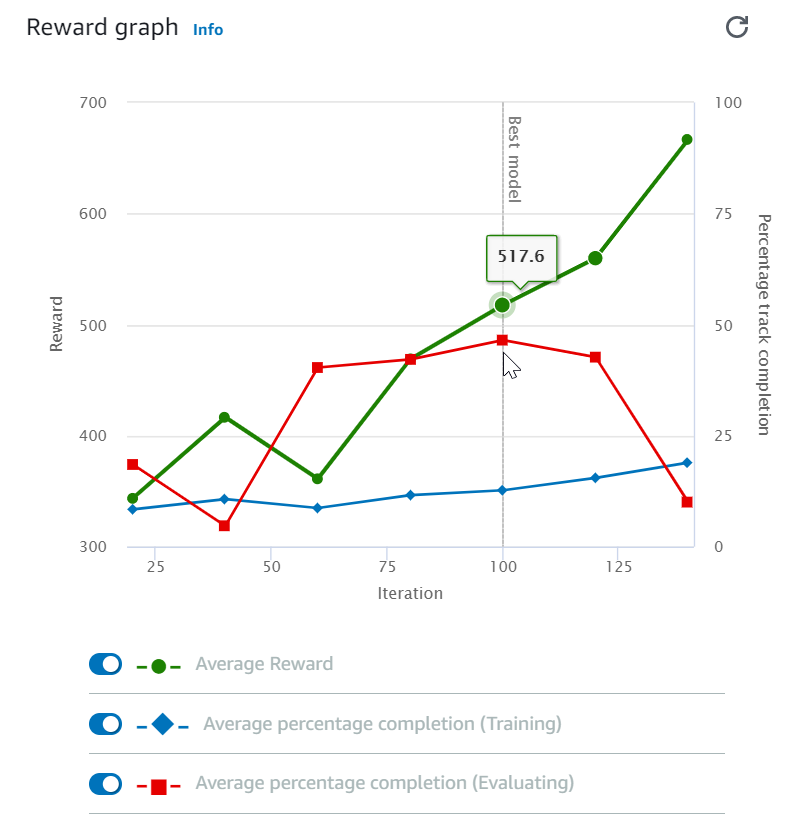
エピソードごとに獲得した報酬、反復ごとの平均報酬、エピソードごとの進行状況、反復ごとの平均進行状況、またはそれらの任意の組み合わせを表示することを選択できます。これを行うには、[報酬(エピソード、平均)] または [報酬グラフ] の最下部にある [進行状況 (エピソード、平均)] スイッチを切り替えます。エピソードごとの報酬と進行状況は、異なる色の散布図として表示されます。平均の報酬とトラック完走状況は、ラインプロットで表示され、最初の反復後に開始されます。
報酬の範囲はグラフの左側に表示され、進行状況の範囲 (0 〜 100) は右側に表示されます。トレーニングメトリクスの正確な値を読み取るには、グラフ上のデータポイントの近くまでマウスを移動します。
トレーニングの進行中、グラフは 10 秒ごとに自動的に更新されます。更新ボタンを選択して、メトリクス表示を手動で更新できます。
トレーニングジョブは、平均の報酬とトラック完走状況が収束する傾向を示している場合に適しています。特に、エピソードごとの進行状況が継続的に 100% に達し、報酬レベルが横ばいになる場合、モデルが収束している可能性があります。それ以外の場合は、モデルを複製して再トレーニングします。
トレーニングモデルを複製して新しいトレーニングパスを開始する
トレーニングの新しいラウンドの開始点として、以前にトレーニングしたモデルを複製すると、トレーニングの効率を向上させることができます。これを行うには、すでに学んだ知識を利用するようにハイパーパラメータを変更します。
このセクションでは、AWS DeepRacer コンソールを使用してトレーニング済みモデルを複製する方法を学びます。
AWS DeepRacer コンソールを使用して強化学習モデルのトレーニングを繰り返すには
-
まだサインインしていない場合は、AWS DeepRacer コンソールにサインインします。
-
[モデル] ページで、トレーニングされたモデルを選択し、次に [アクション] ドロップダウンメニューリストから [クローン] を選択します。
-
[モデルの詳細] で、以下の操作を行います。
-
クローンモデルに対して名前を生成したくない場合は、[モデル名] に
RL_model_1をタイプします。 -
必要に応じて、[モデルの説明 - オプション] に複製したモデルの説明を入力します。
-
-
環境シミュレーションのために、別のトラックのオプションを選択します。
-
[報酬関数] で、利用可能な報酬関数の例の 1 つを選択してください。報酬関数を変更します。たとえば、ステアリングを検討してください。
-
[アルゴリズム設定] を展開し、さまざまなオプションを試してください。たとえば、[勾配降下バッチサイズ] の値を 32 から 64 に変更するか、[学習レート] を上げてトレーニングをスピードアップします。
-
[条件の停止] のさまざまな選択を試してください。
-
[トレーニングの開始] を選択して、新しいトレーニングを開始します。
一般的な堅牢な機械学習モデルのトレーニングと同様に、最良の解決策を見つけるために体系的な実験を行うことが重要です。
シミュレーションでの AWS DeepRacer モデルを評価します
モデルを評価するには、トレーニング済みのモデルのパフォーマンスをテストします。AWS DeepRacer では、標準的なパフォーマンスメトリクスは、3 回の連続ラップを終えた平均時間になります。任意の 2 つのモデルについて、このメトリクスを使用すると、エージェントが同じトラックで他のモデルより速く走行できる場合、一方のモデルが優れています。
一般的に、モデルの評価には次の作業が含まれます。
-
評価ジョブを設定し、起動します。
-
ジョブの実行中に進行中の評価を確認してください。AWS DeepRacer シミュレーターでこれを行うことができます。
-
評価ジョブが完了したら、評価の概要を確認してください。進行中の評価ジョブはいつでも終了できます。
注記
評価時間は、選択した基準によって異なります。モデルが評価基準を満たさない場合、評価は 20 分の上限に達するまで継続されます。
-
必要に応じて、評価結果を適格な AWS DeepRacer リーダーボードに送信してください。リーダーボードでのランキングによって、自分のモデルが他の参加者に対してどの程度うまく機能しているかがわかります。
物理的なトラックで走行している AWS DeepRacer 車両で AWS DeepRacer モデルをテストしてください。「AWS DeepRacer 車両を運転する 」を参照してください。
実環境に合わせた AWS DeepRacer モデルのトレーニングを最適化する
アクションスペースの選択、報酬関数、トレーニングで使用されるハイパーパラメータ、車両のキャリブレーション、さらには実際のトラック状態を含め、トレーニングされたモデルの実世界でのパフォーマンスには多くの要因が影響します。また、シミュレーションは実世界の (しばしば未処理の) 近似にすぎません。課題となるのは、シミュレーションでモデルをトレーニングし、それを実世界に適用し、そして満足のいく性能を達成することです。
実世界での堅実なパフォーマンスを得るためにモデルをトレーニングするには、多くの場合、報酬関数、アクションスペース、ハイパーパラメータ、およびシミュレーションでの評価および実環境でのテストという反復作業が多数必要になります。最後のステップは、いわゆるシミュレーションから実社会への移行 (sim2real) であり、扱いにくいと感じることがあります。
sim2real の課題に取り組むためには、次の考慮事項に注意してください。
-
車両が適切にキャリブレートされていることを確認します。
シミュレーション環境は実環境を部分的に表現したものであるため、これは重要です。また、エージェントは、各ステップで、カメラのイメージによってキャプチャされた現在のトラック状態に基づいてアクションを実行します。高速ではルートを計画するのに十分遠くまで見ることができません。これに対応するために、シミュレーションは速度とステアリングに制限を課します。トレーニングされたモデルが実世界で機能するために、車両はこれと他のシミュレーション設定に合うように適切にキャリブレートされなければなりません。車体のキャリブレーションの詳細については、「AWS DeepRacer 車両をキャリブレートする」を参照してください。
-
最初にデフォルトのモデルで車両をテストします。
お客様の AWS DeepRacer 車両には、その推理エンジンにロードされたトレーニング済みモデルが付属しています。実世界で自身のモデルをテストする前に、車両がデフォルトのモデルで合理的にうまく機能することを確認してください。そうでない場合は、物理的なトラックセットアップを確認します。正しく構築されていない物理トラックでモデルをテストすると、パフォーマンスが低下する可能性があります。このような場合は、テストを開始または再開する前にトラックを再設定または修復します。
注記
AWS DeepRacer 車両を走行させる際、報酬機能を呼び出すことなくトレーニングされたポリシーネットワークに従ってアクションが推論されます。
-
モデルがシミュレーションで機能することを確認します。
モデルが実世界でうまく機能しない場合は、モデルかトラックのどちらかに欠陥がある可能性があります。根本原因を整理するには、まずシミュレーションでモデルを評価して、シミュレーションされたエージェントがトラックから外れることなく少なくとも 1 回のループを終了できるかどうかを確認する必要があります。シミュレーターでエージェントの軌跡を観察しながら、報酬の集約を調べることでこれを実行できます。シミュレーションされたエージェントが失敗することなくループを完了したときに報酬が最大に達する場合、そのモデルが適切である可能性があります。
-
モデルを過剰にトレーニングしないでください。
モデルが一貫してシミュレーションでトラックを完了した後でトレーニングを続けると、モデルに過剰適合が発生します。シミュレーションされたトラックと実環境との間のわずかな違いでさえも処理できないため、過剰にトレーニングされたモデルは実世界ではうまく機能しません。
-
さまざまな反復から複数のモデルを使用します。
一般的なトレーニングセッションでは、過小適合と過剰適合の間にあるさまざまなモデルが作成されます。正しいモデルを決定するための先験的な基準がないため、エージェントがシミュレーターで 1 回のループを完走してからループを一貫して実行されるまでの間に、いくつかのモデル候補を選択する必要があります。
-
テストではゆっくりと走り始め、徐々に走行速度を上げます。
車両にデプロイされたモデルをテストする場合は、小さい最大速度値から開始します。たとえば、テストの制限速度をトレーニングの制限速度の 10% 未満に設定できます。その後、車両が動き始めるまで、テストの制限速度を徐々に上げます。装置制御コンソールを使用して車両をキャリブレーションするときに、テストの制限速度を設定します。車両の速度が速すぎる場合、たとえば、速度がシミュレーターでのトレーニング中に見られる速度を超える場合、モデルは実際のトラックでうまく機能する可能性は低くなります。
-
さまざまな開始位置で車両をテストします。
モデルはシミュレーションで特定の経路をたどることを学習し、トラック内の位置に敏感に反応できるようになります。モデルが特定の位置からうまく機能するかどうかを確認するには、トラック境界内のさまざまな位置 (左から中央、右) から車両テストを開始する必要があります。ほとんどのモデルは、車両を白線のどちらかの側に近づける傾向があります。車両の経路を分析するために、シミュレーションからステップごとに車両の位置 (x、y) をプロットして、実環境で車両がたどる可能性のある経路を特定します。
-
直線トラックでテストを開始します。
直線トラックは、曲線トラックに比べて移動がはるかに簡単です。まっすぐなトラックでテストを開始すると、パフォーマンスの低いモデルをすばやく取り除くことができます。ほとんどの場合、車両が直線トラックに沿って走行できない場合、そのモデルは曲線トラックでもうまく機能しません。
-
車両が 1 種類のアクションしかとらない行動に注意します。
車両が 1 種類のアクションのみを実行できる場合、たとえば、車両を左方向にのみハンドルを切る場合、モデルは過剰適合か過小適合の可能性があります。指定されたモデルパラメータでは、トレーニングの反復が多すぎるとモデルが過剰適合になる可能性があります。反復回数が少なすぎると、過小適合になる可能性があります。
-
トラックの境界線に沿って進路を修正する車両の能力に注意します。
良いモデルは、トラックの境界に近づいたときに車両が自身を修正するします。適切にトレーニングされたモデルのほとんどが、この機能を備えています。車両がトラックと境界の両方で適切な動作をする場合は、モデルはより頑強でより高品質であると見なされます。
-
車両が示す矛盾した行動に注意します。
ポリシーモデルは、任意の状態で行動をとる確率分布を表します。トレーニングされたモデルが推論エンジンにロードされると、車両はモデルの処方に従って、最も可能性の高い行動を 1 ステップずつ選択します。行動確率が均等に分布している場合、車両は等しいまたは非常に類似した確率の行動のいずれかをとる可能性があります。これは不安定な運転行動につながります。たとえば、車両が時々は (たとえば、しばしば) 直線経路をたどり、他の時には不必要な方向転換をする場合は、モデルは過小適合又は過剰適合のいずれかです。
-
車両によって行われる 1 種類のターン (左または右) のみに注意してください。
車両が左には非常にうまく曲がるが、右へのステアリングを管理できない場合、または同様に、右にはうまく曲がれるが左にはうまく曲がれない場合は、車両のステアリングをキャリブレートするか、再キャリブレートします。あるいは、テスト中の物理的設定に近い設定でトレーニングされたモデルを使用してみることもできます。
-
急なターンを行ってトラックから外れる車両に注意します。
車両がほとんどの場合正しい経路をたどるが、突然トラックから外れる場合は、おそらく環境にある集中力をそらすものが原因の可能性がありあます。集中力をそらすものの多くには、予期しないまたは意図しないライトの反射が含まれます。そのような場合は、トラックのまわりに障壁を使用するかその他の方法でまぶしい光を低減します。
