翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
事後対応型異常を表示する
インサイト内で Amazon RDS リソースの異常を確認できます。事後対応型インサイトのページの [集計メトリクス] セクションでは、異常のリストと対応するタイムラインを表示できます。異常に関連するロググループやイベントに関する情報を表示するセクションもあります。事後対応型インサイトの因果異常にはそれぞれ、異常に関する詳細が記載された対応するページがあります。
RDS 事後対応型異常の詳細な分析を表示する
この段階では、異常をドリルダウンして Amazon RDS DB インスタンスの詳細な分析とレコメンデーションを取得します。
詳細分析は、Performance Insights がオンになっている Amazon RDS DB インスタンスでのみ使用できます。
異常の詳細ページにドリルダウンするには
-
インサイトページで、AWS/RDS リソースタイプの集計メトリクスを検索します。
-
[詳細を表示] を選択します。
異常の詳細ページが表示されます。タイトルは [データベースパフォーマンスの異常] で始まり、名前はリソースを示します。コンソールでは、異常が発生した時期に関係なく、重要性が最も高い異常がデフォルトで設定されます。
-
(オプション) 影響を受けるリソースが複数ある場合は、ページ上部にあるリストから別のリソースを選択します。
以下は、詳細ページのコンポーネントの説明を示しています。
リソースの概要
詳細ページの上部セクションは [Resource overview] (リソースの概要) です。このセクションは、Amazon RDS DB インスタンスで発生するパフォーマンスの異常をまとめたものです。
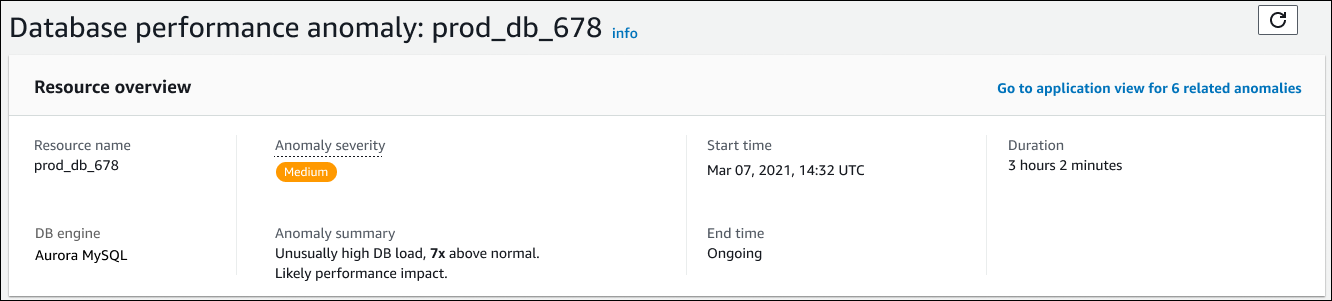
このセクションには、次のフィールドが含まれます。
-
Resource name (リソース名) — 異常が発生している DB インスタンスの名前。この例では、リソース名は prod_db_678 です。
-
DB engine (DB エンジン) — 異常が発生している DB インスタンスの名前。この例では、エンジンは Aurora MySQL です。
-
Anomaly severity (異常の重要性) — インスタンスに対する異常による悪影響の尺度。重要度は、高、中, および低です。
-
Anomaly summary (異常の概要) — 問題の簡単な概要。一般的な概要は、Unusually high DB load (異常に高い DB 負荷) です。
-
Start time (開始時間) と End time (終了時間) – 異常が開始および終了したとき。終了時間が [Ongoing] (進行中) の場合、異常が引き続き発生しています。
-
Duration (期間) — 異常動作の持続時間。この例では、異常は進行中であり、3 時間 2 分間発生しています。
プライマリメトリクス
プライマリメトリクスセクションは、インサイト内の最上位レベルの異常である因果異常の概要が表示されます。因果異常は、DB インスタンスが経験する一般的な問題と考えることができます。
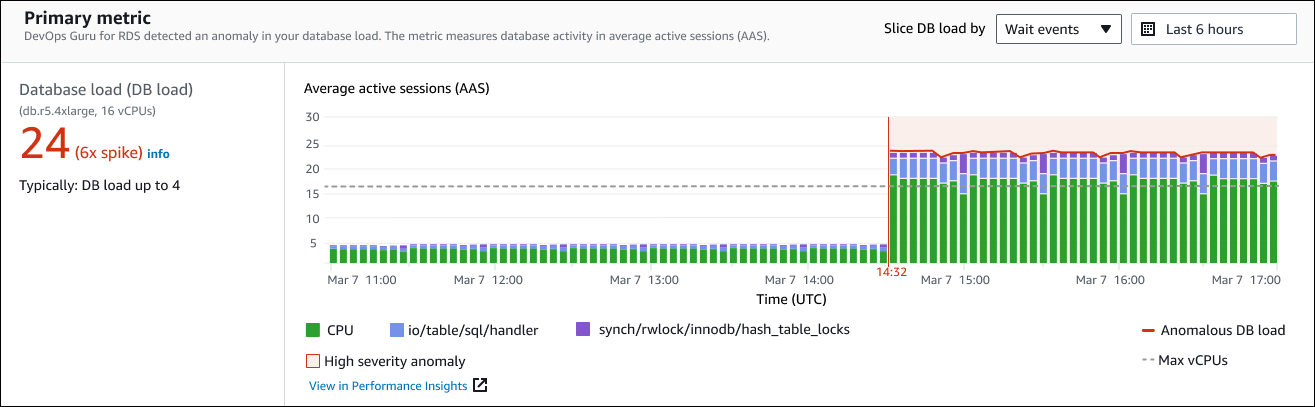
左側のパネルには、問題の詳細が表示されます。この例では、概要には次の情報が含まれます。
-
データベース負荷 (DB 負荷) — データベース負荷の問題としての異常の分類。Performance Insights の対応するメトリクスは
DBLoadです。このメトリクスは、Amazon CloudWatch にも発行されます。 -
db.r5.4xlarge — DB インスタンスクラス。vCPUs の数 (この例では 16) は、平均アクティブセッション (AAS) チャートの点線に対応します。
-
24 (6x スパイク) — インサイトで報告された時間間隔中の平均アクティブセッション (AAS) で測定された DB 負荷。したがって、異常期間中の任意の時点で、データベースで平均 24 のセッションがアクティブだったことがわかります。DB 負荷は、このインスタンスの通常の DB 負荷の 6 倍です。
-
一般的に最大 4 の DB 負荷 — 一般的なワークロードにおける AAS 単位で測定された DB 負荷のベースライン。4 の値は、通常の操作中に、データベース上で任意の時点で平均 4 以下のセッションがアクティブであることを意味します。
デフォルトでは、負荷チャートは待機イベントによってスライスされます。つまり、チャート内の各バーについて、最大の色付き領域は、総 DB 負荷に最も寄与している待機イベントを表します。グラフには、課題が開始された時刻 (赤色) が表示されます。バー内で最も多くのスペースを占める待機イベントに注目します。
-
CPU -
IO:wait/io/sql/table/handler
上記の待機イベントは、この Aurora MySQL データベースでは通常よりも多く表示されます。Amazon Aurora の待機イベントを使用してパフォーマンスをチューニングする方法については、Amazon Aurora ユーザーガイドの「Aurora MySQL の待機イベントを使用したチューニング」および「Aurora PostgreSQL の待機イベントを使用したチューニング」を参照してください。RDS for PostgreSQL の待機イベントを使用してパフォーマンスを調整する方法については、Amazon RDS ユーザーガイドの「RDS for PostgreSQL の待機イベントを使用したチューニング」を参照してください。
関連メトリクス
[Related metrics] (関連メトリクス) セクションには、因果異常内の特定の検出内容であるコンテキスト異常がリストされます。これらの検出結果は、パフォーマンスの問題に関する追加情報を提供します。
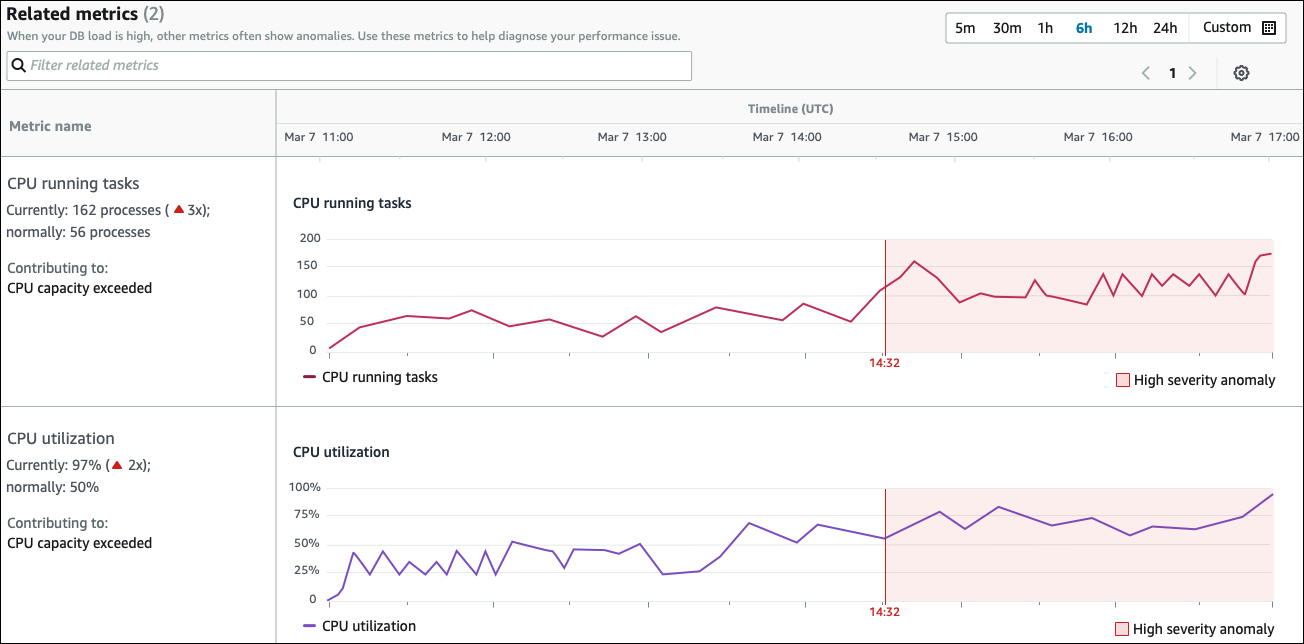
[Related metrics] (関連メトリクス) テーブルには 2 つの列 (メトリクス名およびタイムライン (UTC)) があります。テーブルの個々の行は、特定のメトリクスに対応します。
各行の最初の列には、次の情報が含まれます。
-
名前– メトリクスの名前。最初の行は、タスクを実行している CPU としてメトリクスを識別します。 -
Currently (現在) — メトリクスの現在の値。最初の行では、現在の値は 162 プロセス (3x) です。
-
Normally (通常) — 通常通り機能している際のこのメトリクスのベースライン。DevOps Guru for RDS は、ベースラインを 1 週間の履歴 95 パーセンタイル値として計算します。最初の行は、通常 56 のプロセスが CPU で実行されていることを示します。
-
Contributing to (寄与) — このメトリクスに関連付けられている検出結果。最初の行では、タスクを実行中の CPU メトリクスは、CPU 容量超過異常に関連付けられています。
Timeline (タイムライン) 列には、メトリクスの折れ線グラフが表示されます。網掛け領域は、DevOps Guru for RDS が検出を重要度が高いと指定した時間間隔を示します。
分析とレコメンデーション
因果異常が全体的な問題を説明するのに対し、コンテキスト異常は調査を必要とする特定の検出結果を示します。各結果は、関連するメトリクスのセットに対応します。
次の例の [Analysis and recommendations] (分析とレコメンデーション) セクションには、高 DB 負荷異常に 2 つの検出結果があります。
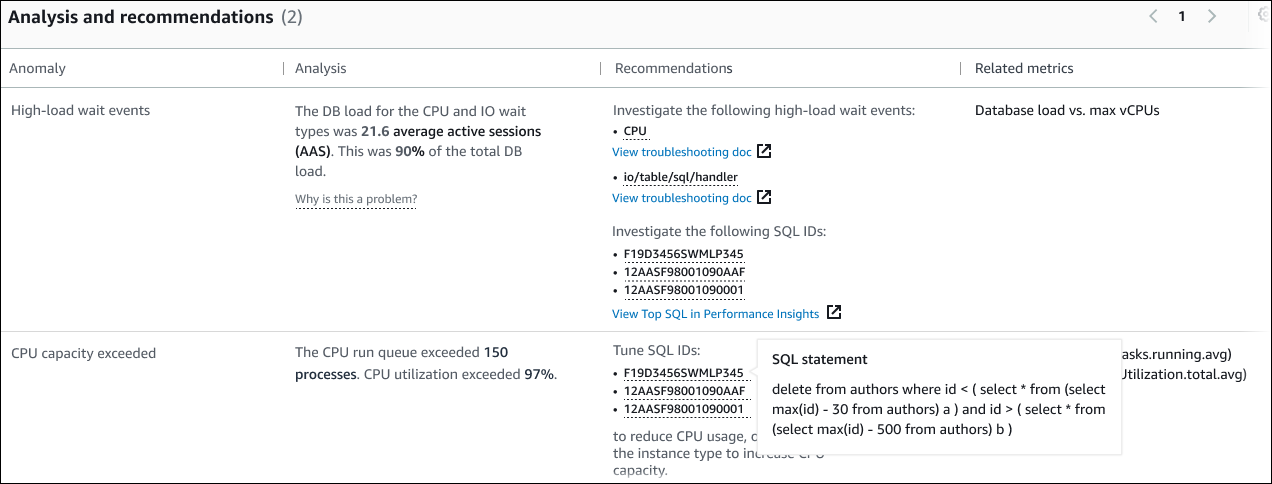
このテーブルには、次の列があります。
-
Anomaly (異常) — このコンテキスト異常の全般的な説明。この例では、最初の異常は高負荷待機イベントで、2 番目の異常は CPU 容量超過です。
-
Analysis (分析) — 異常の詳細な説明。
最初の異常では、3 つの待機タイプが DB 負荷の 90% に寄与しています。2 番目の異常では、CPU 実行キューが 150 を超えています。これは、任意の時点で 150 を超えるセッションが CPU 時間を待っていたことを意味します。CPU 使用率は 97% を超えています。つまり、問題が発生している間、CPU は 97% のビジー状態でした。したがって、CPU はほぼ継続的に占有され、平均 150 のセッションが CPU で実行されるのを待機していました。
-
Recommendations (レコメンデーション) — 異常に対して提案されたユーザー対応。
最初の異常では、DevOps Guru for RDS では、待機イベント(
cpuとio/table/sql/handler) を調査することが推奨されています。これらのイベントに基づいてデータベースのパフォーマンスを調整する方法については、Amazon Aurora ユーザーガイドの「cpu」と「io/table/sql/handler」を参照してください。2 番目の異常では、DevOps Guru for RDS は 3 つの SQL ステートメントを調整して CPU 消費量を減らすことを推奨しています。リンクにカーソルを合わせると、SQL テキストが表示されます。
-
Related metrics (関連メトリクス) — 異常の特定の測定値を示すメトリクス。これらのメトリクスの詳細については、Amazon Aurora ユーザーガイドの「Amazon Aurora のメトリクスのリファレンス」またはAmazon RDS ユーザーガイドの「Amazon RDS のメトリクスのリファレンス」を参照してください。
最初の異常では、DevOps Guru for RDS は、DB 負荷をインスタンスの最大 CPU と比較することを推奨しています。2 番目の異常では、レコメンデーションは、CPU 実行キュー、CPU 使用率、および SQL 実行率を確認することです。
