翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Managed Grafana で Amazon EKS インフラストラクチャをモニタリングするためのソリューション
Amazon Elastic Kubernetes Service インフラストラクチャのモニタリングは、Amazon Managed Grafana を使用する最も一般的なシナリオの 1 つです。このページではこのシナリオのソリューションを提供するテンプレートについて説明します。ソリューションは [AWS Cloud Development Kit (AWS CDK)] または [Terraform]
このソリューションは以下を設定します。
-
Amazon Managed Service for Prometheus ワークスペースで Amazon EKS クラスターからのメトリクスを保存し、メトリクスをスクレイピングしてそのワークスペースにプッシュするマネージドコレクターを作成します。詳細については、AWS 「マネージドコレクターによるメトリクスの取り込み」を参照してください。
-
CloudWatch エージェントを使用して、Amazon EKS クラスターからログを収集します。ログは CloudWatch に格納され、Amazon Managed Grafana によってクエリされます。詳細については、「Amazon EKS のログ記録」を参照してください。
-
Amazon Managed Grafana ワークスペースでこれらのログとメトリクスをプルして、クラスターのモニタリングに役立つダッシュボードとアラートを作成します。
このソリューションを適用すると、以下のようなダッシュボードとアラートが作成されます。
-
Amazon EKS クラスターの全体的な健全性を評価します。
-
Amazon EKS コントロールプレーンの健全性とパフォーマンスを表示します。
-
Amazon EKS データプレーンの健全性とパフォーマンスを表示します。
-
Kubernetes 名前空間全体の Amazon EKS ワークロードのインサイトを表示します。
-
CPU、メモリ、ディスク、ネットワーク使用量などの、名前空間全体のリソース使用量を表示します。
このソリューションについて
このソリューションは、Amazon EKS クラスターのためにメトリクスを提供するように Amazon Managed Grafana ワークスペースを設定します。メトリクスはダッシュボードとアラートを生成するために使用されます。
このメトリクスは、Kubernetes コントロールとデータプレーンのヘルスとパフォーマンスに関するインサイトを提供するため、Amazon EKS クラスターをより効果的に運用するのに役立ちます。Amazon EKS クラスターに関して、リソース使用状況の詳細なモニタリングなど、ノードレベルからポッド、Kubernetes レベルまで把握できます。
このソリューションには予測機能と修正機能の両方が用意されています。
-
予測機能には以下が含まれます。
-
スケジューリングの決定を推進してリソース効率を管理します。例えば、Amazon EKS クラスターの内部ユーザーにパフォーマンスと信頼性の SLA を提供するには、過去の使用状況の追跡に基づいて、ワークロードに十分な CPU リソースとメモリリソースを割り当てることができます。
-
使用状況の予測: ノード、[Amazon EBS でサポートされる永続的ボリューム]、[Application Load Balancer] などの Amazon EKS クラスターリソースの現在の使用状況に基づいて、同様の需要を持つ新製品やプロジェクトなどを事前に計画できます。
-
潜在的な問題の早期検出: 例えば、Kubernetes 名前空間レベルでリソース消費の傾向を分析することで、ワークロードの使用状況の季節性を理解できます。
-
-
修正機能には以下が含まれます。
-
インフラストラクチャと Kubernetes ワークロードレベルでの問題の平均検出時間 (MTTD) が短縮されます。例えば、トラブルシューティングダッシュボードを見ると、何が問題だったかに関する仮説をすぐにテストして排除できます。
-
スタック内のどこで問題が発生しているか判断します。例えば、Amazon EKS コントロールプレーンは によって完全に管理 AWS されており、API サーバーが過負荷になったり、接続が影響を受けたりすると、Kubernetes デプロイの更新などの特定のオペレーションが失敗する可能性があります。
-
次の図はソリューションのダッシュボードフォルダのサンプルを示しています。
ダッシュボードを選択して詳細を表示できます。例えば、ワークロードのコンピューティングリソースの表示を選択すると、次のイメージに示すようなダッシュボードが表示されます。
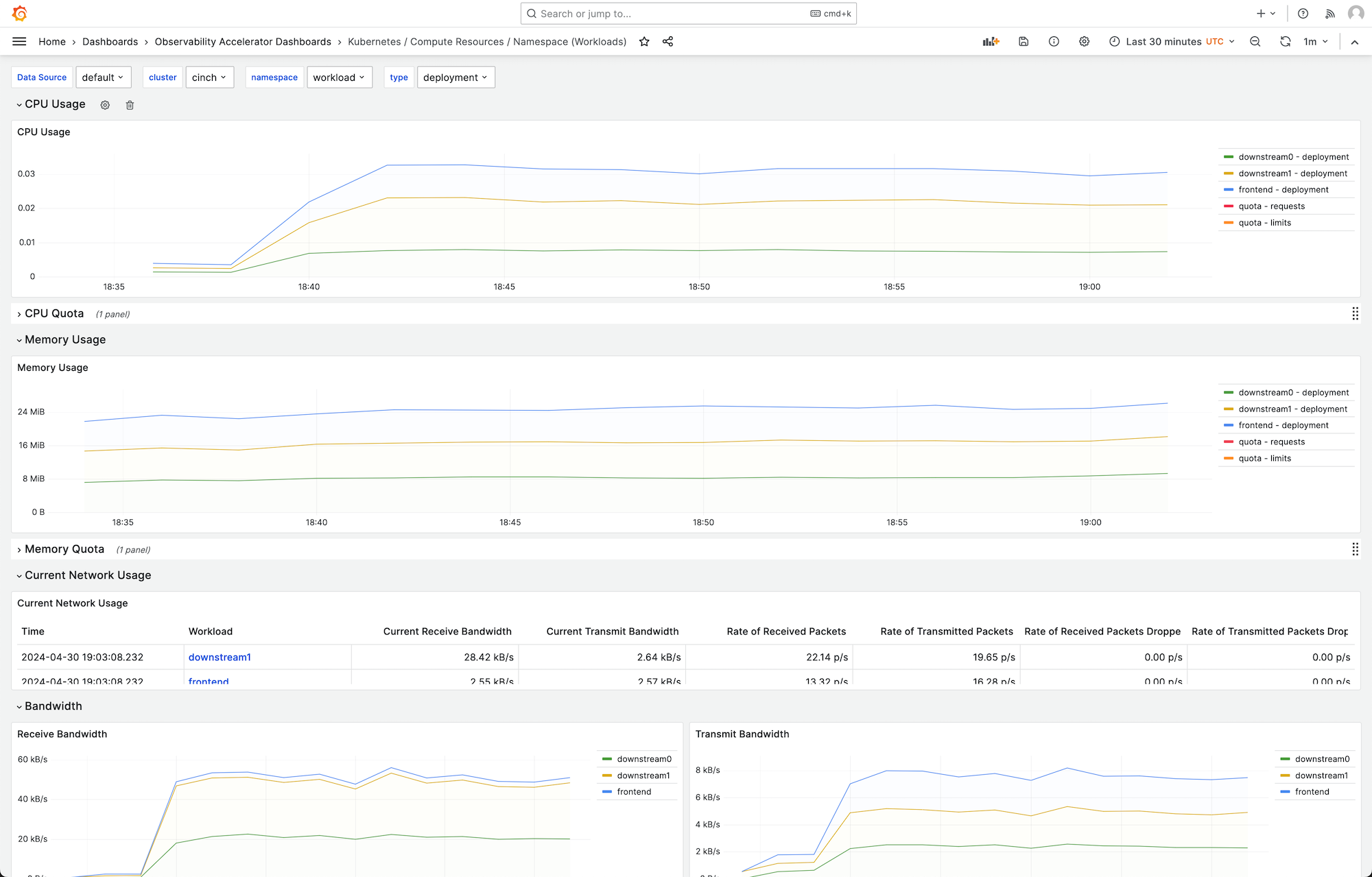
メトリクスは 1 分間のスクレイプ間隔でスクレイプされます。ダッシュボードには、特定のメトリクスに基づいて、1 分、5 分、またはそれ以上に集約されたメトリクスが表示されます。
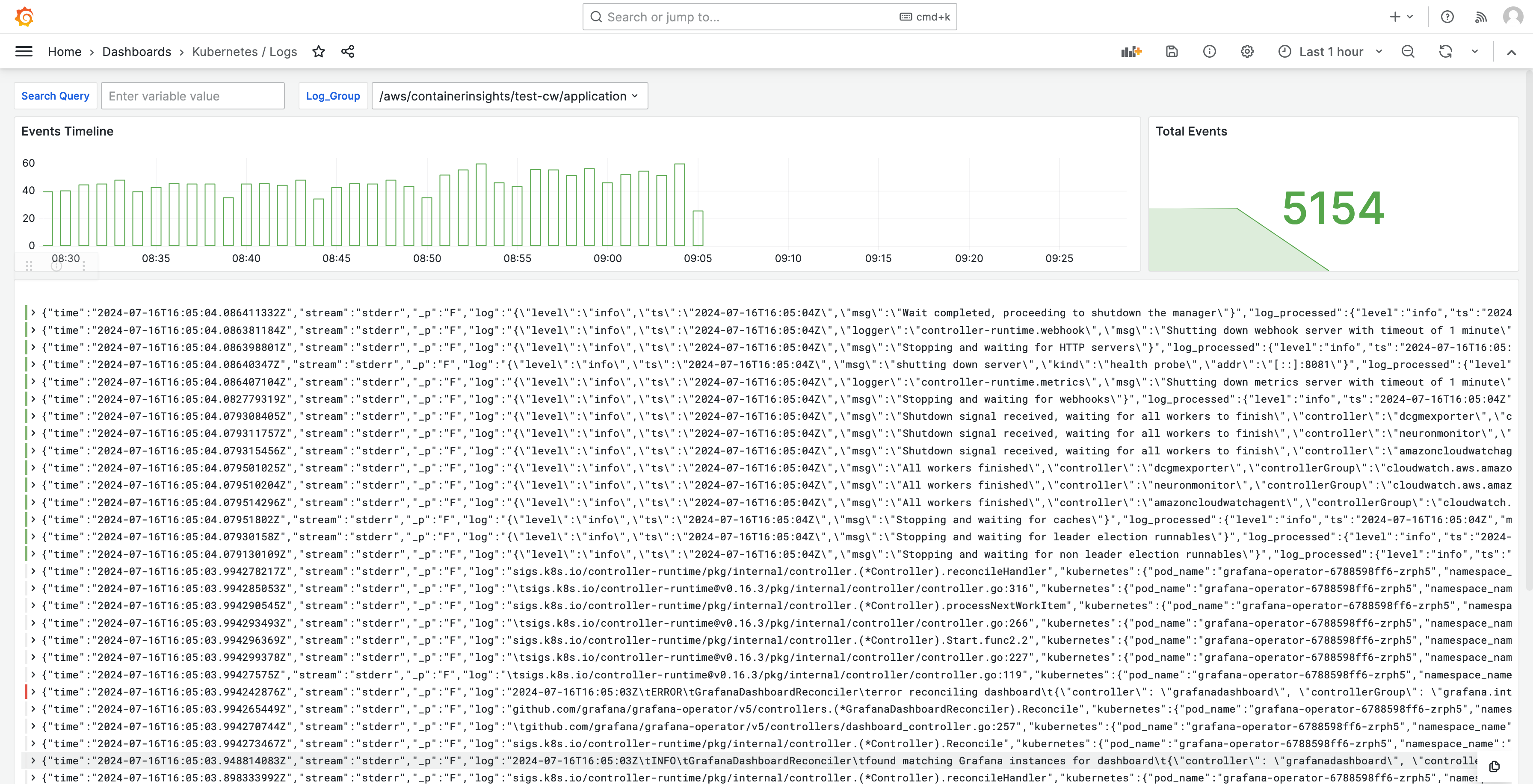
ログはダッシュボードにも表示されるため、ログをクエリおよび分析して、問題の根本原因を見つけることができます。次の画像は、ログダッシュボードの例を示しています。
このソリューションで追跡されるメトリクスのリストについては、「追跡されるメトリクスのリスト」を参照してください。
ソリューションによって作成されたアラートのリストについては、「作成済みアラートのリスト」を参照してください。
コスト
このソリューションは、ワークスペース内にリソースを作成して使用します。作成したリソースの標準使用量に対して課金されますが、これには以下が含まれます。
-
ユーザーによる Amazon Managed Grafana ワークスペースアクセス。料金に関する詳細については、「Amazon Managed Grafana の料金
」を参照してください。 -
Amazon Managed Service for Prometheus エージェントレスコレクターの使用、メトリクス分析 (クエリサンプル処理) などの、Amazon Managed Service for Prometheus メトリクスの取り込みとストレージ。このソリューションで使用されるメトリクス数は、Amazon EKS クラスターの設定と使用状況によって異なります。
CloudWatch を使用して、Amazon Managed Service for Prometheus で取り込みメトリクスとストレージメトリクスを表示できます。詳細については、Amazon Managed Service for Prometheus ユーザーガイドの [CloudWatch メトリクス] を参照してください。
Amazon Managed Service for Prometheus の料金
ページでは、料金計算ツールを使用してコストを見積もることができます。メトリクス数は、クラスター内のノード数と、アプリケーションが生成するメトリクスによって異なります。 -
CloudWatch Logs の取り込み、ストレージ、分析。デフォルトでは、ログ保持は有効期限が切れないように設定されています。これは CloudWatch 内で調整できます。料金の詳細については、「「Amazon CloudWatch 料金表
」を参照してください。 -
ネットワークコスト。クロスアベイラビリティーゾーン、リージョン、またはその他のトラフィックに対して標準 AWS ネットワーク料金が発生する場合があります。
各製品の料金ページから利用できる料金計算ツールは、ソリューションの潜在的コストを理解するのに役立ちます。以下の情報は、Amazon EKS クラスターと同じアベイラビリティーゾーンで実行されているソリューションの、基本コストを取得するのに役立ちます。
| 製品 | 計算メトリクス | 値 |
|---|---|---|
Amazon Managed Service for Prometheus |
アクティブなシリーズ |
8000 (ベース) 15,000 (ノードあたり) |
平均収集間隔 |
60 (秒) |
|
Amazon Managed Service for Prometheus (マネージドコレクター) |
コレクター数 |
1 |
サンプル数 |
15 (ベース) 150 (ノードあたり) |
|
ルールの数 |
161 |
|
平均ルール抽出間隔 |
60 (秒) |
|
Amazon Managed Grafana |
アクティブなエディタ/管理者の数 |
1 (またはユーザーに基づき、さらに多く) |
CloudWatch (Logs) |
標準 Logs: データインジェスト |
24.5 GB (ベース) 0.5 GB (ノードあたり) |
ログストレージ/アーカイブ (標準 Logs と Vended Logs) |
ログを保存する: 1 か月の保持を前提 |
|
スキャンされた予想ログデータ |
Grafana からの各ログインサイトクエリは、指定期間のグループからのすべてのログコンテンツをスキャンします。 |
これらの数値は、追加ソフトウェアなしで EKS を実行するソリューションのベース番号です。これにより基本コストの見積もりが得られます。また、ネットワーク使用コストも削減されます。これは、Amazon Managed Grafana ワークスペース、Amazon Managed Service for Prometheus ワークスペース、Amazon EKS クラスターが同じアベイラビリティーゾーン、 AWS リージョンおよび VPN にあるかどうかによって異なります。
注記
このテーブルの項目に (base) 値とリソースあたりの値 (例: (per node)) が含まれている場合は、ベース値にリソースあたりの値を加えて、そのリソースの数を乗じる必要があります。例えば、[平均アクティブ時系列] の場合、8000 + the number of nodes in your cluster * 15,000 の数値を入力します。ノードが 2 つある場合は、38,000 と入力し、これは 8000 + ( 2 * 15,000 ) です。
前提条件
このソリューションを使用する前に、次のことを行う必要があります。
-
モニタリングする [Amazon Elastic Kubernetes Service クラスターを作成する]、またはそのクラスターがあるいる必要があります。そのクラスターには少なくとも 1 つのノードが必要です。クラスターには、プライベートアクセスを含めるように設定された API サーバーエンドポイントアクセスが必要です (パブリックアクセスを許可することもできます)。
認証モードに API アクセスを含める必要があります (
APIまたはAPI_AND_CONFIG_MAPに設定)。これによりソリューションデプロイでアクセスエントリを使用できます。クラスターに以下をインストールする必要があります (コンソール経由でクラスターを作成する場合はデフォルトで true ですが、 AWS API または を使用してクラスターを作成する場合は追加する必要があります AWS CLI)。 AWS CNI、CoreDNS、Kube-proxy AddOns。
クラスター名を保存して後で指定します。これは Amazon EKS コンソールのクラスター詳細にあります。
注記
Amazon EKS クラスターの作成方法の詳細については、「Amazon EKS の使用方法」を参照してください。
-
Amazon EKS クラスター AWS アカウント と同じ に Amazon Managed Service for Prometheus ワークスペースを作成する必要があります。詳細については、[Amazon Managed Service for Prometheus ユーザーガイド] の [ワークスペースの作成] を参照してください。
Amazon Managed Service for Prometheus ワークスペース ARN を保存して後で指定します。
-
Grafana バージョン 9 以降の Amazon Managed Grafana ワークスペースは、Amazon EKS クラスターと同じ に作成する必要があります。 AWS リージョン 新しいワークスペースの作成の詳細については、「Amazon Managed Grafana ワークスペースを作成する」を参照してください。
ワークスペースロールには、Amazon Managed Service for Prometheus および Amazon CloudWatch API にアクセスするためのアクセス許可が必要です。この許可を付与する最も簡単な方法は、[サービス管理のアクセス許可]を使用して、Amazon Managed Service for Prometheus と CloudWatch を選択することです。AmazonPrometheusQueryAccess ポリシーと AmazonGrafanaCloudWatchAccess ポリシーをワークスペース IAM ロールに手動で追加することもできます。
Amazon Managed Grafana ワークスペース ID とエンドポイントを保存して後で指定します。ID は
g-123exampleの形式になります。ID とエンドポイントは Amazon Managed Grafana コンソールにあります。エンドポイントはワークスペースの URL で、ID が含まれます。例えば、https://g-123example.grafana-workspace.<region>.amazonaws.com/。 -
Terraform でソリューションをデプロイするには、アカウントからアクセスできる [Amazon S3 バケット] を作成する必要があります。これはデプロイの Terraform 状態ファイルを保存するために使用されます。
Amazon S3 バケット ID を保存して後で指定します。
-
Amazon Managed Service for Prometheus のアラートルールを表示するには、Amazon Managed Grafana ワークスペースの [Grafana アラート]を有効にする必要があります。
さらに、Amazon Managed Grafana には Prometheus リソースに対する次のアクセス許可が必要です。これらのアクセス許可は、AWS データソースの Amazon Managed Grafana アクセス許可とポリシー で説明されているサービス管理ポリシーとカスタマー管理ポリシーのいずれかに追加する必要があります。
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
注記
ソリューションのセットアップが必ず必要なわけではありませんが、作成されたダッシュボードにアクセスするには、Amazon Managed Grafana ワークスペースでユーザー認証を設定する必要があります。詳細については、「Amazon Managed Grafana ワークスペースでユーザーを認証する」を参照してください。
このソリューションの使用
このソリューションは、Amazon EKS クラスターからのメトリクスのレポートとモニタリングをサポートするように AWS インフラストラクチャを設定します。AWS Cloud Development Kit (AWS CDK) または Terraform
追跡されるメトリクスのリスト
このソリューションは Amazon EKS クラスターからメトリクスを収集するスクレイパーを作成します。これらのメトリクスは Amazon Managed Service for Prometheus に格納され、Amazon Managed Grafana ダッシュボードに表示されます。デフォルトでは、スクレイパーはクラスターが公開するすべての Prometheus 互換メトリクスを収集します。より多くのメトリクスを生成するクラスターにソフトウェアをインストールすると、収集されるメトリクスが増加します。必要に応じて、メトリクスをフィルタリングする設定でスクレイパーを更新して、メトリクス数を減らすことができます。
このソリューションでは、追加ソフトウェアをインストールしないベース Amazon EKS クラスター設定で、次のメトリクスを追跡します。
| メトリクス | 説明/目的 |
|---|---|
|
|
APIService 名で分類された、使用不可としてマークされた APIServices のゲージ。 |
|
|
名前で識別され、各オペレーションと API リソースとタイプ (検証または承認) ごとに分割された、秒単位のアドミッションウェブフックのレイテンシーヒストグラム。 |
|
|
過去 1 秒のリクエストタイプごとの、現在使用されているこの apiserver の保留リクエスト制限の最大数。 |
|
|
キャッシュされた DEK が現在占めているキャッシュスロットのパーセント。 |
|
|
API Priority and Fairness サブシステムの初期 (WATCH の場合) または任意の (WATCH 以外の場合) 実行ステージのリクエスト数。 |
|
|
拒否された API Priority and Fairness サブシステムの初期 (WATCH の場合) または任意の (WATCH 以外の場合) 実行ステージのリクエスト数。 |
|
|
各優先度レベルに設定されている、実行シートの公称数。 |
|
|
API Priority and Fairness サブシステムにおけるリクエスト実行の初期ステージ (WATCH の場合) または任意の (WATCH 以外の場合) ステージの持続期間の、バケット化ヒストグラム。 |
|
|
API Priority and Fairness サブシステムにおけるリクエスト実行の初期ステージ (WATCH の場合) または任意の (WATCH 以外の場合) ステージのカウント。 |
|
|
API サーバーリクエストを示します。 |
|
|
API グループ、バージョン、リソース、サブリソース、removed_release 別に分類された、リクエストされた非推奨 API のゲージ。 |
|
|
verb、dry run 値、グループ、バージョン、リソース、サブリソース、スコープ、コンポーネントごとの、秒単位の応答遅延分布。 |
|
|
verb、dry run 値、グループ、バージョン、リソース、サブリソース、スコープ、コンポーネントごとの、秒単位の応答遅延分布のバケット化ヒストグラム。 |
|
|
verb、dry run 値、グループ、バージョン、リソース、サブリソース、スコープ、コンポーネントごとの、サービスレベル目標 (SLO) の秒単位の応答遅延分布。 |
|
|
apiserver が自己防衛で終了したリクエスト数。 |
|
|
verb、dry run 値、グループ、バージョン、リソース、スコープ、コンポーネント、HTTP レスポンスコードごとに分割された apiserver リクエストのカウンター。 |
|
|
cpu 累積消費時間。 |
|
|
読み取られたバイトの累積カウント。 |
|
|
完了した読み取りの累積カウント。 |
|
|
書き込まれたバイトの累積カウント。 |
|
|
完了した書き込みの累積カウント。 |
|
|
ページキャッシュメモリの合計。 |
|
|
RSS のサイズ。 |
|
|
コンテナスワップの使用状況。 |
|
|
現在のワーキングセット。 |
|
|
受信したバイトの累積カウント。 |
|
|
受信中にドロップされたパケットの累積カウント。 |
|
|
受信したパケットの累積カウント。 |
|
|
送信されたバイトの累積カウント。 |
|
|
送信中にドロップされたパケットの累積カウント。 |
|
|
送信されたパケットの累積カウント。 |
|
|
オペレーションとオブジェクトタイプごとの、秒単位の etcd リクエストのレイテンシーのバケット化ヒストグラム。 |
|
|
現在存在する goroutine 数。 |
|
|
作成された OS スレッド数。 |
|
|
cgroup マネージャーオペレーションの、秒単位の持続期間のバケット化ヒストグラム。メソッドにより分類。 |
|
|
cgroup マネージャーオペレーションの秒単位の持続期間。メソッドにより分類。 |
|
|
ノードで設定関連のエラーが発生した場合はこのメトリクスが真 (1) となり、それ以外の場合は偽 (0) となります。 |
|
|
ノードの名前。カウントは常に 1 です。 |
|
|
PLEG でポッドを再び一覧表示するための、秒単位の持続時間のバケット化ヒストグラム。 |
|
|
PLEG でポッドを再び一覧表示するための、秒単位の持続時間のカウント。 |
|
|
PLEG で再び一覧表示するまでの間隔の、バケット化ヒストグラム。 |
|
|
kubelet がポッドを初めて確認したときからポッドの実行が開始されるまでの、秒単位の持続時間カウント。 |
|
|
1 つのポッドを同期するための、秒単位の持続時間のバケット化ヒストグラム。作成、更新、同期のオペレーションタイプにより分類。 |
|
|
1 つのポッドを同期する、秒単位の持続時間カウント。作成、更新、同期のオペレーションタイプにより分類。 |
|
|
現在実行中のコンテナ数。 |
|
|
実行中のポッドサンドボックスを持つポッド数。 |
|
|
ランタイムオペレーションの、秒単位の持続時間のバケット化ヒストグラム。オペレーションタイプにより分類。 |
|
|
オペレーションタイプごとのランタイムオペレーションエラーの累積数。 |
|
|
オペレーションタイプごとのランタイムオペレーションの累積数。 |
|
|
ポッドに割り当て可能なリソースの量 (システムデーモン用に一部を予約後)。 |
|
|
ノードで使用できるリソースの合計量。 |
|
|
コンテナがリクエストした制限リソース数。 |
|
|
コンテナがリクエストした制限リソース数。 |
|
|
コンテナがリクエストしたリクエストリソース数。 |
|
|
コンテナがリクエストしたリクエストリソース数。 |
|
|
ポッドの所有者に関する情報。 |
|
|
Kubernetes のリソースクォータでは、名前空間内の CPU、メモリ、ストレージなどのリソースに使用制限を適用します。 |
|
|
コアあたりの使用量と合計使用量を含む、ノードの CPU 使用量メトリクス。 |
|
|
各モードで消費された CPU の秒数。 |
|
|
ノードがディスクで I/O オペレーションを実行した累積合計時間。 |
|
|
ノードがディスクで I/O オペレーションを実行した合計時間。 |
|
|
ノードがディスクから読み込んだ合計バイト数。 |
|
|
ノードがディスクに書き込んだ合計バイト数。 |
|
|
Kubernetes クラスター内のノードのファイルシステムで使用可能なスペースのバイト量。 |
|
|
ノード上のファイルシステムの合計サイズ。 |
|
|
ノードの CPU 使用率の 1 分間の負荷平均。 |
|
|
ノードの CPU 使用率の 15 分間の負荷平均。 |
|
|
ノードの CPU 使用率の 5 分間の負荷平均。 |
|
|
ノードのオペレーティングシステムがバッファキャッシュに使用したメモリ量。 |
|
|
ノードのオペレーティングシステムがディスクキャッシュに使用したメモリ量。 |
|
|
アプリケーションとキャッシュで使用できるメモリ量。 |
|
|
ノードで使用可能な空きメモリ量。 |
|
|
ノードで使用可能な物理メモリ合計量。 |
|
|
ノードによって、ネットワーク経由で受信されている合計バイト数。 |
|
|
ノードによって、ネットワーク経由で送信されている合計バイト数。 |
|
|
ユーザー合計数および秒単位のシステム CPU 消費時間合計。 |
|
|
バイト単位の常駐メモリサイズ。 |
|
|
ステータスコード、メソッド、ホストでパーティション分割された、HTTP リクエスト数。 |
|
|
秒単位のリクエストレイテンシーのバケット化ヒストグラム。verb とホストで分類。 |
|
|
ストレージオペレーションの持続期間のバケット化ヒストグラム。 |
|
|
ストレージオペレーションの持続期間カウント。 |
|
|
ストレージオペレーション中の累積エラー数。 |
|
|
モニタリング対象のターゲット (ノードなど) が稼働しているかどうかを示すメトリクス。 |
|
|
ボリュームマネージャーにより管理されるボリューム合計数。 |
|
|
workqueue が処理する合計追加数。 |
|
|
現在の workqueue の深さ。 |
|
|
リクエストされるまでに項目が workqueue に留まる時間を秒単位で示す、バケット化ヒストグラム。 |
|
|
workqueue の項目の処理にかかる時間を秒単位で示す、バケット化ヒストグラム。 |
作成済みアラートのリスト
次の表はこのソリューションが作成するアラートの一覧です。Amazon Managed Service for Prometheus ではアラートがルールとして作成され、Amazon Managed Grafana ワークスペースに表示されます。
Amazon Managed Service for Prometheus ワークスペースで[ルール設定ファイルの編集]を実行すると、ルールを追加または削除してルールを変更できます。
これらの 2 つのアラートは、一般的なアラートとは少し異なる処理される特別なアラートです。問題を警告する代わりに、システムのモニタリングに使用する情報を提供します。説明にはこれらのアラートの使用方法に関する詳細が含まれています。
| アラート | 説明および使用状況 |
|---|---|
|
これはアラートパイプライン全体が機能することを保証するためのアラートです。このアラートは常に発せられるため、常にアラートマネージャーで発し、常に受信者に対して発する必要があります。これを通知メカニズムと統合して、このアラートが発していないときに通知を送信できます。例えば、PagerDuty では DeadMansSnitch 統合を使用できます。 |
|
これは情報アラートを抑制するために使用するアラートです。それ自体では、情報レベルのアラートはノイズが非常に多い場合がありますが、他のアラートと組み合わせると現実的になります。このアラートは |
次のアラートはシステムに関する情報または警告を提供します。
| アラート | 緊急度 | 説明 |
|---|---|---|
|
|
warning |
ネットワークインターフェイスが頻繁にステータスを変更しています。 |
|
|
warning |
ファイルシステムのスペースが今後 24 時間以内に不足すると予測されます。 |
|
|
critical |
ファイルシステムのスペースが今後 4 時間以内に不足すると予測されます。 |
|
|
warning |
ファイルシステムの残りのスペースが 5% 未満です。 |
|
|
critical |
ファイルシステムの残りのスペースが 3% 未満です。 |
|
|
warning |
ファイルシステムの inode が今後 24 時間以内に不足すると予測されます。 |
|
|
critical |
ファイルシステムの inode が今後 4 時間以内に不足すると予測されます。 |
|
|
warning |
ファイルシステムの残りの inode が 5% 未満です。 |
|
|
critical |
ファイルシステムの残りの inode が 3% 未満です。 |
|
|
warning |
ネットワークインターフェイスが多くの受信エラーを報告しています。 |
|
|
warning |
ネットワークインターフェイスが多くの送信エラーを報告しています。 |
|
|
warning |
conntrack エントリ数が制限に近づいています。 |
|
|
warning |
Node Exporter のテキストファイルコレクターがスクレイピングに失敗しました。 |
|
|
warning |
クロックスキューが検出されました。 |
|
|
warning |
クロックが同期していません。 |
|
|
critical |
RAID アレイが劣化 |
|
|
warning |
RAID アレイが失敗したデバイス |
|
|
warning |
カーネルはまもなくファイル記述子制限を使い果たすと予測されます。 |
|
|
critical |
カーネルはまもなくファイル記述子制限を使い果たすと予測されます。 |
|
|
warning |
ノードの準備ができていません。 |
|
|
warning |
ノードに到達できません。 |
|
|
info |
Kubelet は最大能力で実行されています。 |
|
|
warning |
ノードの準備状況ステータスがフラッピングしています。 |
|
|
warning |
Kubelet ポッドライフサイクルイベントジェネレータの再リストに時間がかかりすぎています。 |
|
|
warning |
Kubelet ポッドスタートアップレイテンシーが高すぎます。 |
|
|
warning |
Kubelet クライアント証明書の有効期限が近づいています。 |
|
|
critical |
Kubelet クライアント証明書の有効期限が近づいています。 |
|
|
warning |
Kubelet サーバー証明書の有効期限が近づいています。 |
|
|
critical |
Kubelet サーバー証明書の有効期限が近づいています。 |
|
|
warning |
Kubelet はクライアント証明書の更新に失敗しました。 |
|
|
warning |
Kubelet はサーバー証明書の更新に失敗しました。 |
|
|
critical |
Prometheus のターゲット検出からターゲットが消えました。 |
|
|
warning |
異なるセマンティックバージョンの Kubernetes コンポーネントが実行中です。 |
|
|
warning |
Kubernetes API サーバークライアントでエラーが発生しています。 |
|
|
warning |
クライアント証明書の有効期限が近づいています。 |
|
|
critical |
クライアント証明書の有効期限が近づいています。 |
|
|
warning |
Kubernetes 集計 API でエラーが報告されました。 |
|
|
warning |
Kubernetes 集計 API がダウンしています。 |
|
|
critical |
Prometheus のターゲット検出からターゲットが消えました。 |
|
|
warning |
kubernetes apiserver が受信リクエストの {{ $value | humanizePercentage }} を終了しました。 |
|
|
critical |
永続ボリュームがいっぱいです。 |
|
|
warning |
永続ボリュームがいっぱいです。 |
|
|
critical |
永続ボリュームの Inode がいっぱいです。 |
|
|
warning |
永続ボリュームの Inode がいっぱいです。 |
|
|
critical |
永続ボリュームのプロビジョニングに問題があります。 |
|
|
warning |
クラスターが CPU リソースリクエストをオーバーコミットしました。 |
|
|
warning |
クラスターがメモリリソースリクエストをオーバーコミットしました。 |
|
|
warning |
クラスターが CPU リソースリクエストをオーバーコミットしました。 |
|
|
warning |
クラスターがメモリリソースリクエストをオーバーコミットしました。 |
|
|
info |
名前空間のクォータがいっぱいになります。 |
|
|
info |
名前空間のクォータが完全に使用されています。 |
|
|
warning |
名前空間のクォータが制限を超えました。 |
|
|
info |
プロセスが昇格 CPU スロットリングを発見しました。 |
|
|
warning |
ポッドがクラッシュループです。 |
|
|
warning |
ポッドが 15 分以上準備状態になっていません。 |
|
|
warning |
ロールバックの可能性に起因するデプロイ生成不一致 |
|
|
warning |
デプロイが予想レプリカ数と一致しません。 |
|
|
warning |
StatefulSet が予想レプリカ数と一致していません。 |
|
|
warning |
ロールバックの可能性に起因する StatefulSet 生成不一致 |
|
|
warning |
StatefulSet 更新がロールアウトしません。 |
|
|
warning |
DaemonSet のロールアウトがスタックしています。 |
|
|
warning |
ポッドコンテナが 1 時間以上待機 |
|
|
warning |
DaemonSet ポッドがスケジュールされていません。 |
|
|
warning |
DaemonSet ポッドのスケジュールが間違っています。 |
|
|
warning |
ジョブが時間内に完了しませんでした |
|
|
warning |
ジョブの完了に失敗しました。 |
|
|
warning |
HPA が希望レプリカ数と一致しません。 |
|
|
warning |
HPA が最大レプリカで実行されています |
|
|
critical |
kube-state-metrics でリストオペレーションのエラーが発生しています。 |
|
|
critical |
kube-state-metrics で監視オペレーションのエラーが発生しています。 |
|
|
critical |
kube-state-metrics のシャード設定が間違っています。 |
|
|
critical |
kube-state-metrics のシャードがありません。 |
|
|
critical |
API サーバーで過剰なエラーバジェットを消費しています。 |
|
|
critical |
API サーバーで過剰なエラーバジェットを消費しています。 |
|
|
warning |
API サーバーで過剰なエラーバジェットを消費しています。 |
|
|
warning |
API サーバーで過剰なエラーバジェットを消費しています。 |
|
|
warning |
1 つ以上のターゲットがダウンしています。 |
|
|
critical |
Etcd クラスターのメンバーが不十分です。 |
|
|
warning |
Etcd クラスターでリーダーの変更数が多い。 |
|
|
critical |
Etcd クラスターにリーダーがありません。 |
|
|
warning |
Etcd クラスターで gRPC リクエストの失敗数が多い。 |
|
|
critical |
Etcd クラスターで gRPC リクエストが遅い。 |
|
|
warning |
Etcd クラスターメンバーの通信が遅い。 |
|
|
warning |
Etcd クラスターのプロポーザルの失敗数が多い。 |
|
|
warning |
Etcd クラスターの同期期間が長い。 |
|
|
warning |
Etcd クラスターが予想コミット期間より長い。 |
|
|
warning |
Etcd クラスターが HTTP リクエストに失敗しました。 |
|
|
critical |
Etcd クラスターで HTTP リクエストの失敗数が多い。 |
|
|
warning |
Etcd クラスターで HTTP リクエストが遅い。 |
|
|
warning |
ホストクロックが同期していません。 |
|
|
warning |
ホスト OOM 強制終了が検出されました。 |
トラブルシューティング
プロジェクトのセットアップが失敗する原因がいくつかあります。必ず以下の内容を確認してください。
-
ソリューションのインストール前にすべての [前提条件] を完了する必要があります。
-
ソリューションの作成やメトリクスへのアクセスを試みる前に、クラスターに少なくとも 1 つのノードを含める必要があります。
-
Amazon EKS クラスターには、
AWS CNI、CoreDNS、kube-proxyアドオンをインストールする必要があります。インストールしないとソリューションが正しく動作しません。これらは、コンソールを介してクラスターを作成するときにデフォルトでインストールされます。クラスターが AWS SDK を介して作成された場合は、インストールが必要になる場合があります。 -
Amazon EKS ポッドのインストールがタイムアウトしました。これは、使用可能なノード容量が十分でないときに発生する場合があります。これらの問題には、次のような複数の原因があります。
-
Amazon EKS クラスターが Amazon EC2 ではなく Fargate で初期化されました。このプロジェクトでは Amazon EC2 が必須です。
-
ノードが汚染されているため使用できません。
kubectl describe nodeを使用するとテイントを確認できます。次にNODENAME| grep Taintskubectl taint nodeでテイントを削除します。テイント名の後に必ずNODENAMETAINT_NAME--を含めてください。 -
ノードが容量制限に達しました。この場合は新しいノードを作成、または容量を増やすことができます。
-
-
Grafana にダッシュボードが表示されません: 間違った Grafana ワークスペース ID を使用しています。
以下のコマンドを実行して Grafana に関する情報を取得してください。
kubectl describe grafanas external-grafana -n grafana-operator正しいワークスペース URL の結果を確認できます。予想しているものでない場合は、正しいワークスペース ID で再デプロイします。
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
Grafana にダッシュボードが表示されません: 期限切れの API キーを使用しています。
この場合の検索では、grafana 演算子を取得して、ログにエラーがないことを確認する必要があります。次のコマンドを使用して Grafana 演算子の名前を取得します。
kubectl get pods -n grafana-operator次のような演算子名が返されます。
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2m次のコマンドで演算子名を使用します。
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operator次のようなエラーメッセージは、API キーの有効期限が切れたことを示しています。
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).Reconcileこの場合は、新しい API キーを作成してソリューションを再度デプロイします。問題が解決しない場合は、再びデプロイする前に次のコマンドを使用して強制的に同期できます。
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
CDK インストール — SSM パラメータが欠けています。次のようなエラーが表示される場合は、
cdk bootstrapを実行して再試行してください。Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
OIDC プロバイダーが既に存在する場合はデプロイが失敗する可能性があります。次のようなエラーが表示されます (この場合は、CDK インストール)。
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.この場合は、IAM ポータルに移動して OIDC プロバイダーを削除し、再試行してください。
-
[Terraform のインストール] —
cluster-secretstore-sm failed to create kubernetes rest client for update of resourceとfailed to create kubernetes rest client for update of resourceを含むエラーメッセージが表示されます。このエラーは通常、External Secrets Operator が Kubernetes クラスターに未インストールまたは有効化されていないことを示します。これはソリューションのデプロイ時にインストールされますが、ソリューションが必要なときに準備できていない場合があります。
以下のコマンドを使用すると、KFP SDK がインストールされたことを確認できます。
kubectl get deployments -n external-secretsインストールされている場合、オペレーターを完全に使用できるようになるまでに時間がかかることがあります。次のコマンドを実行すると、必要なカスタムリソース定義 (CRD) のステータスを確認できます。
kubectl get crds|grep external-secretsこのコマンドは、
clustersecretstores.external-secrets.ioやexternalsecrets.external-secrets.ioなど、外部シークレット演算子に関連する CRD を一覧表示するはずです。リストにない場合は、数分待ってからもう一度確認してください。CRD が登録されたら、
terraform applyを再度実行してソリューションをデプロイできます。
