AWS Systems Manager Incident Manager は新規顧客に公開されなくなりました。既存のお客様は、通常どおりサービスを引き続き使用できます。詳細については、「AWS Systems Manager Incident Manager 可用性の変更」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Incident Manager のインシデントライフサイクル
AWS Systems Manager Incident Manager は、サービスの停止やセキュリティの脅威などのインシデントを特定して対応するためのベストプラクティスに基づくstep-by-stepフレームワークを提供します。Incident Manager の主な目的は、完全なインシデントライフサイクル管理ソリューションを通じて、影響を受けたサービスやアプリケーションをできるだけ早く正常に戻すことです。
次の図に示すように、Incident Manager はインシデントライフサイクルのすべてのフェーズでツールとベストプラクティスを提供します。
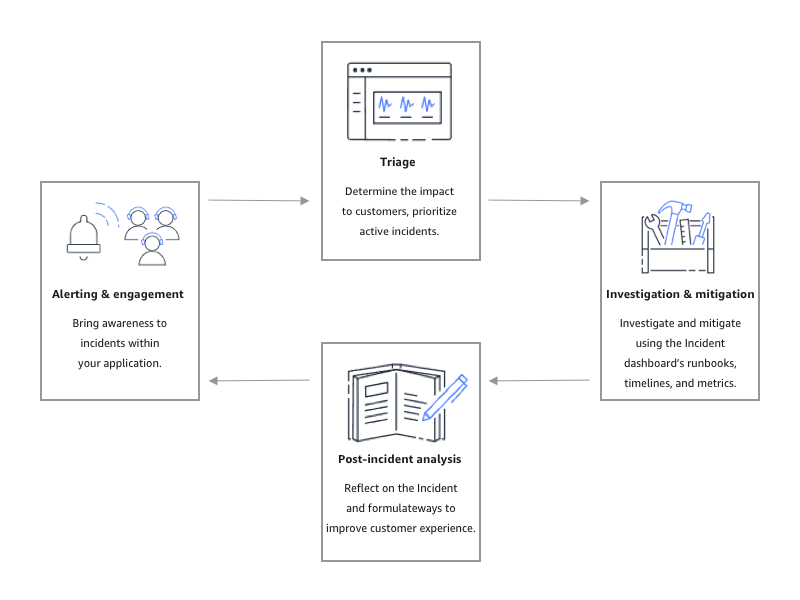
アラートとエンゲージメント
インシデントライフサイクルのアラートとエンゲージメントフェーズでは、アプリケーションおよびサービス内のインシデントに対する認識の提供に重点を置いています。このフェーズは、インシデントが検出される前に開始され、アプリケーションを深く理解する必要があります。Amazon CloudWatch メトリクスを使用してアプリケーションのパフォーマンスに関するデータをモニタリングしたり、Amazon EventBridge を使用してさまざまなソース、アプリケーション、サービスからのアラートを集計したりできます。アプリケーションのモニタリングを設定したら、履歴基準外のメトリクスに関するアラートを開始できます。モニタリングのベストプラクティスについては、「モニタリング」を参照してください。
応答者のインシデント診断をサポートするために、Incident Manager の検出結果機能を有効にできます。検出結果は、インシデントの発生前後に発生した AWS CodeDeploy デプロイと AWS CloudFormation スタックの更新に関する情報です。この情報があると、潜在的な原因の評価に必要な時間が短縮され、インシデントからの平均回復時間 (MTTR) を短縮できます。
アプリケーションのインシデントをモニタリングしているので、インシデントの際に使用するインシデント 対応計画 を定義できます。対応計画の作成の詳細については、「Incident Manager での対応計画の作成と設定」を参照してください。Amazon EventBridge イベントまたは CloudWatch アラームは、テンプレートとして対応計画を使用してインシデントを自動的に作成できます。インシデントの作成の詳細については、「Incident Manager でインシデントを自動または手動で作成する」を参照してください。
対応計画では、関連する エスカレーション計画 および最初の応答者をインシデントに参加させるための エンゲージメント計画 を開始します。エスカレーションプランの設定の詳細については、エスカレーション計画を作成する を参照してください。同時に、チャットアプリケーションの Amazon Q Developer は、インシデントの詳細ページに誘導するチャットチャネルを使用して応答者に通知します。チャットチャネルと インシデントの詳細を使用すると、チームはインシデントを通信し、トリアージすることができます。Incident Manager でのチャットチャネルのセットアップの詳細については、「タスク 2: チャットアプリケーションで Amazon Q Developer にチャットチャネルを作成する」を参照してください。
トリアージ
トリアージとは、最初の応答者が顧客への影響を判断しようとする場合です。Incident Manager コンソールのインシデント詳細ビューには、応答者がインシデントを評価するのに役立つタイムラインとメトリクスが表示されます。インシデントの影響を評価することは、インシデントの対応時間、解決、コミュニケーションの基盤にもなります。応答者は、1 (重大) から 5 (影響なし) までの影響度評価を使用してインシデントに優先順位を付けます。
組織は、各影響度評価の正確な範囲を自由に定義できます。次の表に、各影響レベルの一般的な定義の例を示します。
| 影響コード | 影響名 | サンプルの定義スコープ |
|---|---|---|
1 |
Critical |
ほとんどのお客様に影響するアプリケーション全体の障害。 |
2 |
High |
一部のお客様に影響するアプリケーション全体の障害。 |
3 |
Medium |
お客様に影響する部分的なアプリケーション障害。 |
4 |
Low |
お客様への影響は限定的な断続的な障害。 |
5 |
No Impact |
お客様は現在影響を受けていないものの、影響を回避するための緊急のアクションが必要。 |
調査と緩和
インシデント 詳細ビューでは、チームに Runbook、タイムライン、およびメトリクスが提供されます。インシデントの取り扱い方法については、「コンソールでのインシデントの詳細の表示」を参照してください。
Runbooks 一般的に調査ステップを提供し、データを自動的に取得したり、一般的に使用されるソリューションを試すことができます。Runbooks は、チームがインシデントの緩和に役立つと判断した、明確で反復可能なステップも提供します。Runbook タブは現在の Runbook ステップに焦点を当て、過去と将来のステップを表示します。
Incident Manager は、Systems Manager 自動化と統合して Runbook を構築します。Runbook を使用して、以下のいずれかを実行します。
-
インスタンスと AWS リソースを管理する
-
スクリプトの自動実行
-
CloudFormation リソースを管理する
サポートされるアクションタイプの詳細については、「AWS Systems Manager ユーザーガイド」の「Systems Manager Automation アクションのリファレンス」を参照してください。
[タイムライン] タブには、実行されたアクションが表示されます。タイムラインには、タイムスタンプと自動的に作成された詳細が記録されます。タイムラインにカスタムイベントを追加するには、このユーザーガイドの インシデントの詳細 ページの タイムライン セクションを 参照してください。
[診断] タブには、自動的に入力されたメトリクスと手動で追加されたメトリクスが表示されます。このビューは、インシデント中のアプリケーションのアクティビティに関する貴重な情報を提供します。
[エンゲージメント] タブでは、インシデントに連絡先を追加することができ、インシデントに関与したエンゲージメント中の連絡先に、対応を迅速化するためのリソースを提供するのに役立ちます。連絡先は、定義済みのエスカレーション計画、または個人のエンゲージメント計画に従ってエンゲージします。
チャットチャネルを使用すると、直接インシデントを操作したりチームの他の応答者と対話したりできます。チャットアプリケーションで Amazon Q Developer を使用すると、、Slack、Microsoft Teamsおよび Amazon Chime でチャットチャネルを設定できます。Slack および Microsoft Teams チャネルでは、応答者は、多くの ssm-incidents コマンドを使用して、チャットチャネルから直接インシデントを操作できます。詳細については、「チャットチャネルを通じた対話」を参照してください。
インシデント後分析
Incident Manager は、インシデントを検証し、インシデントの今後の再発を防止するために必要な措置を講じ、インシデント対応活動全体を改善するためのフレームワークを提供します。改善には以下が含まれます。
-
インシデントに関連したアプリケーションの変更。チームはこの時間を使用してシステムを改善し、耐障害性を高めることができます。
-
インシデント対応計画への変更。時間をかけて学んだ教訓を取り入れます。
-
ランブックの変更。チームは、解決に必要なステップと、自動化できるステップについて深く掘り下げることができます。
-
アラートの変更。インシデント後、チームはインシデントについてより早くチームに警告するために使用できるメトリクスのクリティカルポイントに気づくことができます。
Incident Manager は、インシデントタイムラインと並んでインシデント後分析の質問とアクション項目を使用して、これらの潜在的な改善を容易にします。分析による改善の詳細については、「Incident Manager でのインシデント後分析の実行」を参照してください。
