慎重に検討した結果、Amazon Kinesis Data Analytics for SQL アプリケーションを中止することにしました。
1. 2025 年 9 月 1 日以降、Amazon Kinesis Data Analytics for SQL アプリケーションのバグ修正は提供されません。これは、今後の廃止によりサポートが制限されるためです。
2. 2025 年 10 月 15 日以降、新しい Kinesis Data Analytics for SQL アプリケーションを作成することはできません。
3. 2026 年 1 月 27 日以降、アプリケーションは削除されます。Amazon Kinesis Data Analytics for SQL アプリケーションを起動することも操作することもできなくなります。これ以降、Amazon Kinesis Data Analytics for SQL のサポートは終了します。詳細については、「Amazon Kinesis Data Analytics for SQL アプリケーションのサポート終了」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
例: クエリから部分的な結果を集約する
Amazon Kinesis データストリームに、取り込み時刻と完全には一致しないイベント時間のレコードが含まれている場合、タンブリングウィンドウの結果の選択には、到達したレコードが含まれますが、必ずしもウィンドウ内に表示されるとは限りません。この場合、タンブリングウィンドウには、必要な結果の一部のみ含まれます。この問題の修正に使用できる方法がいくつかあります。
-
タンブリングウィンドウのみを使用します。この方法では、upserts を使用してデータベースまたはデータウェアハウスの後処理を行う部分的な結果を集約します。このアプローチは、アプリケーションを効率的に処理します。これは、集約演算子 (
sum、min、max、など) の遅延データを無限に処理します。このアプローチの欠点として、データベースレイヤーで追加のアプリケーションロジックを開発して管理する必要があります。 -
タンブリングウィンドウやスライディングウィンドウを使用します。これにより、部分的な結果が早期に生成されますが、スライディングウィンドウ期間において、完全な結果も得られます。このアプローチでは、データベースレイヤーに追加のアプリケーションロジックを追加する必要がないように、upsert ではなく、overwrite を使用して遅延データを処理します。このアプローチの欠点として、多くの Kinesis 処理ユニット (KPU) を使用することと、2 つの結果が生成される点があります。一部のユースケースでは動作しないことがあります。
タンブリングウィンドウおよびライディングウィンドウの詳細については、「ウィンドウクエリ」を参照してください。
以下の手順では、タンブリングウィンドウ集約によって 2 つの部分的な結果 (アプリケーション内ストリーム CALC_COUNT_SQL_STREAM に送信される) が生成されます。最後の結果を生成するには、この結果を結合する必要があります。アプリケーションは 2 つめの集約 (アプリケーション内ストリーム DESTINATION_SQL_STREAM に送信される) が生成されます。この集約は、2 つの部分的な結果が結合されています。
イベント時間を使用して部分的な結果を集計するアプリケーションを作成するには
にサインイン AWS マネジメントコンソール し、https://console.aws.amazon.com/kinesis
で Kinesis コンソールを開きます。 -
ナビゲーションペインで、[データ分析] を選択します。Amazon Kinesis Data Analytics for SQL Applications の開始方法 チュートリアルに従って、Kinesis Data Analytics アプリケーションを作成します。
-
SQL エディタで、アプリケーションコードを以下に置き換えます。
CREATE OR REPLACE STREAM "CALC_COUNT_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE PUMP "CALC_COUNT_SQL_PUMP_001" AS INSERT INTO "CALC_COUNT_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER_SYMBOL", STEP("SOURCE_SQL_STREAM_001"."ROWTIME" BY INTERVAL '1' MINUTE) as "TradeTime", COUNT(*) AS "TickerCount" FROM "SOURCE_SQL_STREAM_001" GROUP BY STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '1' MINUTE), STEP("SOURCE_SQL_STREAM_001"."APPROXIMATE_ARRIVAL_TIME" BY INTERVAL '1' MINUTE), TICKER_SYMBOL; CREATE PUMP "AGGREGATED_SQL_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER", "TRADETIME", SUM("TICKERCOUNT") OVER W1 AS "TICKERCOUNT" FROM "CALC_COUNT_SQL_STREAM" WINDOW W1 AS (PARTITION BY "TRADETIME" RANGE INTERVAL '10' MINUTE PRECEDING);アプリケーション内の
SELECTステートメントは、SOURCE_SQL_STREAM_001の行を、1 パーセントを超える株価の変動でフィルタリングして、ポンプを使用してそれらの行を別のアプリケーション内ストリームCHANGE_STREAMに挿入します。 -
[Save and run SQL] を選択します。
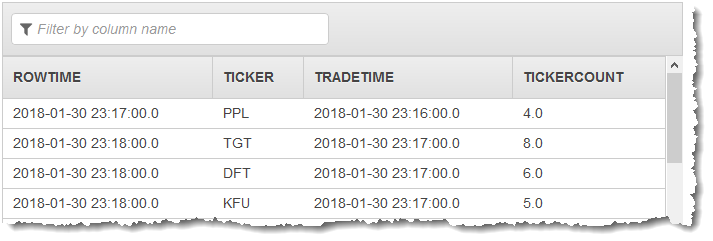
最初のポンプでは、次のようなストリームが CALC_COUNT_SQL_STREAM に出力されます。結果セットは未完成であることに注意してください。

続いて、2 番目のポンプで、完全な結果セットが含まれるストリームが DESTINATION_SQL_STREAM に出力されます。