翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon OpenSearch Service の運用上のベストプラクティス
この章では、Amazon OpenSearch Service ドメインを運用する際のベストプラクティスと、多くのユースケースに適用される一般的なガイドラインを提供します。各ワークロードは一意で、固有の特性があるため、すべてのユースケースに完全に適した一般的な推奨事項はありません。最も重要なベストプラクティスは、ドメインを連続的なサイクルでデプロイ、テスト、調整して、ワークロードに最適な設定、安定性、およびコストを見つけることです。
トピック
モニタリングとアラート
次のベストプラクティスは、OpenSearch Service ドメインのモニタリングに適用されます。
CloudWatch アラームを設定する
OpenSearch Service は Amazon CloudWatch にパフォーマンスメトリクスを発行します クラスターとインスタンスのメトリクスを定期的に確認し、ワークロードのパフォーマンスに基づいて推奨される CloudWatch アラームを設定します。
ログの発行を有効にする
OpenSearch Service は、OpenSearch エラーログ、検索スローログ、インデックス作成スローログ、および監査ログを Amazon CloudWatch Logs に発行します。検索スローログ、インデックス作成スローログ、およびエラーログは、パフォーマンスと安定性の問題のトラブルシューティングに役立ちます。きめ細かいアクセスコントロールを有効にした場合にのみ使用できる監査ログは、ユーザーアクティビティを追跡します。詳細については、OpenSearch ドキュメントの「ログ
検索スローログとインデックス作成スローログは、検索およびインデックス作成オペレーションのパフォーマンスを理解し、トラブルシューティングするための重要なツールです。すべての本番ドメインのために、検索およびインデックスの低速ログ配信を有効にします。ログ記録のしきい値も設定する必要があります。設定しない場合、CloudWatch はログをキャプチャしません。
シャード戦略
シャードは、OpenSearch Service ドメイン内のデータノード全体でワークロードを分散します。インデックスを適切に設定すると、ドメイン全体のパフォーマンスを向上させるのに役立ちます。
OpenSearch Service にデータを送信すると、そのデータをインデックスに送信することになります。インデックスはデータベーステーブルに似ています。ドキュメントが行、フィールドが列に相当します。インデックスを作成する際に、作成するプライマリシャードの数を OpenSearch に指示します。プライマリシャードは、完全なデータセットの独立したパーティションです。OpenSearch Service は、インデックスのプライマリシャード全体でデータを自動的に分散します。インデックスのレプリカを設定することもできます。各レプリカシャードは、そのインデックスのプライマリシャードのコピーの完全なセットで構成されます。
OpenSearch Service は、クラスター内のデータノード全体で各インデックスのシャードをマッピングします。これにより、インデックスのプライマリシャードとレプリカシャードが別々のデータノードに確実に存在するようになります。最初のレプリカは、インデックスにデータのコピーが確実に 2 個あるようにします。常に少なくとも 1 個のレプリカを使用する必要があります。追加のレプリカは、さらなる冗長性と読み取りキャパシティーを提供します。
OpenSearch は、インデックス作成のリクエストを、インデックスに属するシャードを含むすべてのデータノードに送信します。インデックス作成リクエストは、まずプライマリシャードを含むデータノードに送信され、その後にレプリカシャードを含むデータノードに送信されます。検索リクエストは、コーディネーターノードによって、インデックスに属するすべてのシャードのプライマリシャードまたはレプリカシャードにルーティングされます。
たとえば、プライマリシャードごとに 5 つのプライマリシャードと 1 つのレプリカを持つインデックスの場合、各インデックス作成リクエストは 10 個のシャードに触れます。一方、検索リクエストは n 個のシャードに送信されます。n はプライマリシャードの数です。5 個のプライマリシャードと 1 個のレプリカがあるインデックスの場合、各検索クエリは、そのインデックスの 5 個のシャード (プライマリまたはレプリカ) にタッチします。
シャードとデータノード数を決定する
次のベストプラクティスを使用して、ドメインのシャードとデータノード数を決定します。
シャードのサイズ — ディスク上のデータのサイズは、ソースデータのサイズの直接的な結果であり、インデックスを作成するデータが増えるにつれて変化します。ソースとインデックスの比率は 1:10 から 10:1 またはそれ以上に大きく変動する可能性がありますが、通常は 1:1.10 前後です。この比率を使用して、ディスク上のインデックスサイズを予測できます。また、一部のデータにインデックスを付け、実際のインデックスサイズを取得して、ワークロードの比率を判断することもできます。インデックスのサイズを予測したら、各シャードが 10~30 GiB (検索ワークロードの場合) または 30~50 GiB (ログワークロードの場合) になるようにシャード数を設定します。50 GiB が最大になるはずです。増量に備えて準備しておいてください。
シャード数 — データノードへのシャードの分散は、ドメインのパフォーマンスに大きな影響を与えます。複数のシャードを持つインデックスがある場合は、できるかぎりシャード数がデータノード数の倍数になるようにしてください。これは、シャードがデータノード全体に均等に分散されるようにするのに役立ち、ノードがホットになるのを防ぎます。例えば、プライマリシャードが 12 個ある場合、データノード数は 2、3、4、6、または 12 になります。ただし、シャード数よりもシャードサイズの方が重要です。5 GiB のデータがある場合、1 個のシャードを使用するべきです。
データノードあたりのシャード — ノードが保持できるシャードの総数は、ノードの Java 仮想マシン (JVM) ヒープメモリに比例します。ヒープメモリの GiB あたりのシャード数が 25 個以下になるように試みます。例えば、32 GiB のヒープメモリを持つノードのシャード数は 800 個以下である必要があります。シャード配分はワークロードパターンによって異なりますが、Elasticsearch および OpenSearch 1.1~2.15 では 1 ノードあたり 1,000 シャード、OpenSearch 2.17 以降では同 4,000 シャードに制限されています。cat/allocation
シャードと CPU の比率 — シャードがインデックス作成または検索リクエストに関わっている場合、vCPU を使用してリクエストを処理します。ベストプラクティスとして、シャードあたり 1.5 vCPU の初期スケールポイントを使用します。インスタンスタイプに 8 個の vCPUs がある場合は、各ノードのシャード数が 6 個以下になるようにデータノード数を設定します。これは近似値であることに注意してください。必ずワークロードをテストし、それに応じてクラスターをスケールしてください。
ストレージボリューム、シャードサイズ、インスタンスタイプに関する推奨事項については、次のリソースを参照してください。
ストレージスキューを回避する
ストレージスキューは、クラスター内の 1 つ以上のノードが、1 つ以上のインデックスについて、他のノードよりも高い割合のストレージを保持している場合に発生します。不均等な CPU 使用率、断続的で不均等なレイテンシー、データノード全体での不均等なキューイングなどはストレージスキューを示します。スキューの問題があるかどうかを判断するには、次のトラブルシューティング セクションを参照してください。
安定性
次のベストプラクティスは、安定した正常な OpenSearch Service ドメインを維持するために適用されます。
OpenSearch で最新の状態に保つ
サービスソフトウェア更新
OpenSearch Service では、機能追加やドメイン強化を行うソフトウェア更新を定期的にリリースしています。更新では、OpenSearch または Elasticsearch のエンジンバージョンは変更されません。DescribeDomain API オペレーションを定期的に実行するようにスケジュールを設定し、UpdateStatus が ELIGIBLE の場合にサービスソフトウェアの更新を開始することをお勧めします。特定の期間 (通常は 2 週間) 内にドメインを更新しない場合、OpenSearch Service は自動的に更新を実行します。
OpenSearch のバージョンアップグレード
OpenSearch Service は、コミュニティが維持するバージョンの OpenSearch のサポートを定期的に追加します。最新の OpenSearch バージョンが利用可能になったら、必ずアップグレードしてください。
OpenSearch Service は、OpenSearch と OpenSearch Dashboards (ドメインが従来のエンジンを実行している場合は Elasticsearch と Kibana) の両方を同時にアップグレードします。クラスターに専用マスターノードがある場合、アップグレードはダウンタイムなしで完了します。ない場合、クラスターがマスターノードを選択している間、アップグレード後数秒間応答しなくなることがあります。OpenSearch Dashboards は、アップグレードの一部または全期間で使用できなくなる場合があります。
ドメインをアップグレードするには 2 つの方法があります。
-
インプレースアップグレード — 同じクラスターを維持するため、このオプションの方が簡単です。
-
スナップショット/リストアアップグレード — このオプションは、新しいクラスターで新しいバージョンをテストしたり、クラスター間で移行したりするのに適しています。
使用するアップグレードプロセスにかかわらず、開発とテスト専用のドメインを維持し、本番ドメインをアップグレードする前に新しいバージョンにアップグレードすることをお勧めします。テストドメインを作成するときに、デプロイタイプのために [Development and testing] (開発とテスト) を選択します。ドメインのアップグレードの直後に、必ずすべてのクライアントを互換性のあるバージョンにアップグレードしてください。
スナップショットパフォーマンスの向上
スナップショットの処理が停止するのを防ぐには、専用マスターノードのインスタンスタイプがシャードカウントに一致する必要があります。詳細については、「専用マスターノードのインスタンスタイプの選択」を参照してください。また、各ノードの Java ヒープメモリの GiB あたりのシャード数は、推奨される 25 シャードよりも少なくしてください。詳細については、「シャード数の選択」を参照してください。
専用マスターノードを有効にする
専用のマスターノードにより、クラスターの安定性が向上します。専用マスターノードではクラスター管理タスクを実行しますが、インデックスデータは保持せず、クライアントリクエストにも応答しません。このクラスター管理タスクのオフロードにより、ドメインの安定性が向上し、一部の設定変更をダウンタイムなしで行うことができます。
3 つのアベイラビリティーゾーンにまたがるドメインの安定性を最適化するために、3 個の専用マスターノードを有効にして使用します。スタンバイが有効のマルチ AZ でデプロイすると、3 つの専用マスターノードが設定されます。インスタンスタイプの推奨事項については、「専用マスターノードのインスタンスタイプの選択」を参照してください。
複数のアベイラビリティゾーンにデプロイする
サービス中断が発生した場合にデータの損失を防ぎ、クラスターのダウンタイムを最小限に抑えるため、同じ AWS リージョン内の 2 つまたは 3 つのアベイラビリティーゾーン間にノードを分散できます。ベストプラクティスは、スタンバイが有効のマルチ AZ を使用してデプロイすることです。これにより、3 つのアベイラビリティーゾーンが設定され、2 つのゾーンがアクティブ、1 つのゾーンがスタンバイとして機能し、インデックスごとに 2 つのレプリカシャードが割り当てられます。この設定では、OpenSearch Service が対応するプライマリシャードとは異なる AZ にレプリカシャードを分散できます。アベイラビリティーゾーン間のクラスター通信には、AZ 間のデータ転送料金はかかりません。
アベイラビリティーゾーンは、各 リージョン内の独立した場所です。2 つの AZ 設定では、1 つのアベイラビリティーゾーンを失うことは、すべてのドメインキャパシティーの半分を失うことを意味します。3 つのアベイラビリティゾーンに移行すると、1 つのアベイラビリティゾーンを失うことによる影響が軽減されます。
取り込みフローとバッファリングを制御する
_bulk_bulk リクエストを送信する方が効率的です。
最適な運用安定性のために、インデックス作成リクエストのアップストリームフローを制限したり、一時停止したりする必要がある場合があります。インデックス作成リクエストのレートを制限することは、対処しなければクラスターで過負荷となる可能性のある、予期しないまたは時折のリクエストの急増に対処するための重要なメカニズムです。アップストリームアーキテクチャにフロー制御メカニズムを構築することを検討してください。
次の図は、ログ取り込みアーキテクチャの複数のコンポーネントオプションを示しています。急激なトラフィックの急増や短時間のドメインメンテナンスのために受信データをバッファリングするのに十分なスペースを確保できるように、集約レイヤーを設定します。
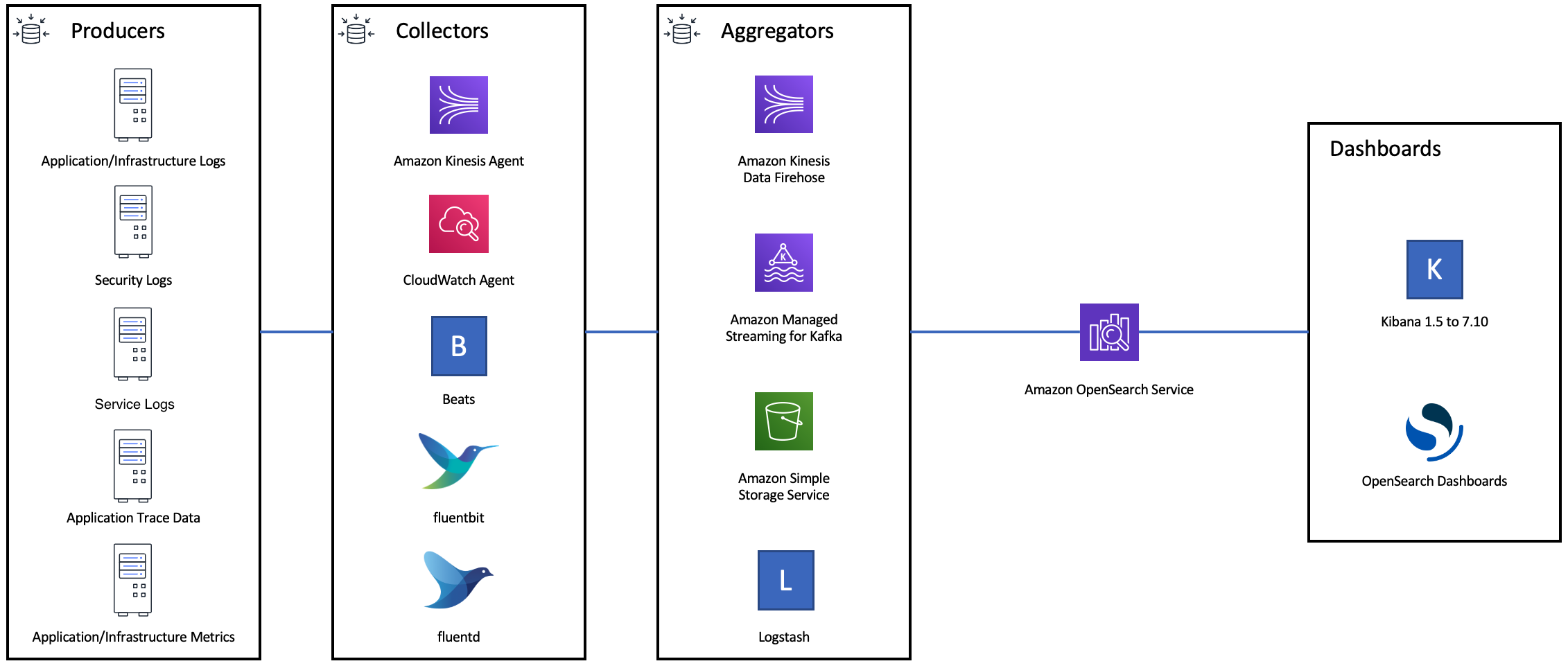
検索ワークロードのマッピングを作成する
検索ワークロードでは、OpenSearch がドキュメントとそのフィールドを格納し、それらのインデックスを作成する方法を定義するマッピングdynamic を strict に設定します。
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
インデックステンプレートを使用する
インデックスの作成時にインデックスを設定する方法を OpenSearch に伝えるために、インデックステンプレート
次の設定は、テンプレートでの設定に役立ちます。
-
プライマリシャードとレプリカシャードの数
-
更新間隔 (インデックスを更新して最近の変更を検索できるようにする頻度)
-
動的マッピングコントロール
-
明示的なフィールドマッピング
次のテンプレート例には、これらの各設定が含まれています。
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
ほとんど変更されない場合でも、設定とマッピングを OpenSearch で一元的に定義することは、複数のアップストリームクライアントを更新するよりも管理が簡単です。
Index State Management でインデックスを管理する
ログや時系列データを管理している場合は、Index State Management (ISM) を使用することをお勧めします。ISM では、通常のインデックスライフサイクル管理タスクを自動化できます。ISM を使用すると、インデックスエイリアスのロールオーバーを呼び出すポリシーを作成し、インデックスのスナップショットを作成し、ストレージ階層間でインデックスを移動し、古いインデックスを削除できます。シャードスキューを回避するための代替データライフサイクル管理戦略として、ISM ロールオーバー
まず、ISM ポリシーを設定します。例については、「サンプルポリシー」を参照してください。その後、ポリシーを 1 つ以上のインデックスにアタッチします。ポリシーに ISM テンプレートフィールドを含めると、OpenSearch Service は、指定されたパターンに一致するすべてのインデックスにポリシーを自動的に適用します。
未使用インデックスの削除
クラスター内のインデックスを定期的に確認し、使用されていないインデックスを特定します。これらのインデックスが S3 に保存されるようにスナップショットを作成してから、削除します。未使用のインデックスを削除すると、シャード数が減り、ノード全体でよりバランスの取れたストレージの分散とリソースの使用が可能になります。アイドル状態であっても、インデックスは内部的なインデックスのメンテナンス作業中に一部のリソースを消費します。
未使用のインデックスを手動で削除する代わりに、ISM を使用して自動的にスナップショットを作成し、一定期間後にインデックスを削除することができます。
高可用性を実現するために複数のドメインを使用する
複数のリージョンで 99.9% のアップタイム
フェイルオーバーを念頭に置いて、アップストリームとダウンストリームのアプリケーションを設計します。フェイルオーバープロセスは、他のディザスタリカバリプロセスと一緒にテストしてください。
パフォーマンス
次のベストプラクティスは、最適なパフォーマンスを実現するために、ドメインの調整に適用されます。
一括リクエストのサイズと圧縮を最適化する
一括サイズ設定は、データ、分析、およびクラスター設定によって異なりますが、適切な開始点は一括リクエストあたり 3~5 MiB です。
gzip 圧縮を使用して OpenSearch ドメインからリクエストを送信し、レスポンスを受信して、リクエストとレスポンスのペイロードサイズを削減します。OpenSearch Python クライアントで、またはクライアント側から次のヘッダーを含めることによって、gzip 圧縮を使用できます。
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
一括リクエストのサイズを最適化するには、3 MiB の一括リクエストサイズから始めます。その後、インデックス作成のパフォーマンスが改善しなくなるまで、リクエストサイズを徐々に大きくします。
注記
Elasticsearch バージョン 6.x を実行しているドメインで gzip 圧縮を有効にするには、クラスターレベルで http_compression.enabled を設定する必要があります。この設定は、Elasticsearch バージョン 7.x および OpenSearch のすべてのバージョンではデフォルトで true です。
一括リクエストのレスポンスのサイズを小さくする
OpenSearch レスポンスのサイズを小さくするには、filter_path パラメータを使用して不要なフィールドを除外します。失敗したリクエストを識別または再試行するために必要なフィールドを除外しないようにしてください。詳細な説明と例については、レスポンスサイズの削減 を参照してください。
更新間隔を調整する
OpenSearch インデックスには、最終的な読み取り整合性があります。更新オペレーションにより、インデックスに対して実行されたすべての更新が検索可能になります。デフォルトの更新間隔は 1 秒です。つまり、OpenSearch は、インデックスが書き込まれている間、更新を毎秒実行します。
インデックスの更新頻度が低い (更新間隔が長い) ほど、インデックス作成の全体的なパフォーマンスが向上します。更新間隔を長くすることのトレードオフは、インデックスが更新されてから新しいデータが検索可能になるまでの時間が長くなることです。全体的なパフォーマンスを向上させるには、更新間隔を許容できる限り長く設定します。
すべてのインデックスの refresh_interval パラメータを 30 秒以上に設定することをお勧めします。
Auto-Tune を有効にする
Auto-Tune は、OpenSearch クラスターのパフォーマンスと使用状況のメトリクスを使用して、ノードのキューサイズ、キャッシュサイズ、および Java 仮想マシン (JVM) 設定の変更を提案します。これらのオプションの変更により、クラスターの速度と安定性が向上します。いつでもデフォルトの OpenSearch Service 設定に戻すことができます。Auto-Tune は、明示的に無効にしない限り、新しいドメインでデフォルトで有効になります。
すべてのドメインで Auto-Tune を有効にし、定期的なメンテナンスウィンドウを設定するか、定期的に推奨事項を確認することをお勧めします。
セキュリティ
ドメインのセキュリティ保護には、次のベストプラクティスが適用されます。
きめ細かなアクセスコントロールを有効にする
きめ細かなアクセスコントロールにより、OpenSearch Service ドメイン内の特定のデータにアクセスできるユーザーを制御できます。一般化されたアクセスコントロールと比較して、きめ細かいアクセスコントロールでは、各クラスター、インデックス、ドキュメント、およびフィールドに、独自の指定アクセスポリシーが設定されます。アクセス基準は、アクセスをリクエストする人の役割や、データに対して実行しようとしているアクションなど、さまざまな要因に基づくことができます。例えば、あるユーザーにはインデックスへの書き込みアクセスを許可し、別のユーザーには変更を加えずにインデックスのデータを読み取るためだけのアクセスを許可する場合があります。
きめ細かなアクセスコントロールは、セキュリティやコンプライアンスの問題を生じさせずに、アクセス要件の異なるデータが同じストレージスペースに存在できるようにします。
ドメインできめ細かいアクセスコントロールを有効にすることをお勧めします。
VPC 内にドメインをデプロイする
OpenSearch Service ドメインを仮想プライベートクラウド (VPC) に配置することは、インターネットゲートウェイ、NAT デバイス、VPN 接続なしで、VPC 内で OpenSearch Service と他のサービス間の安全な通信を実現するのに役立ちます。すべてのトラフィックは AWS クラウド内に安全に保持されます。論理的な隔離により、VPC 内に存在するドメインには、パブリックエンドポイントを使用するドメインに比較して、より拡張されたセキュリティレイヤーがあります。
VPC 内にドメインを作成することをお勧めします。
制限的なアクセスポリシーを適用する
ドメインが VPC 内にデプロイされている場合でも、セキュリティをレイヤーで実装するのがベストプラクティスです。現在のアクセスポリシーの設定を確認してください。
制限的なリソースベースのアクセスポリシーをドメインに適用し、設定 API と OpenSearch API オペレーションへのアクセス権を付与する際は最小特権の原則に従ってください。原則として、アクセスポリシーで匿名ユーザープリンシパル "Principal": {"AWS": "*" } を使用することは避けてください。
ただし、きめ細かなアクセスコントロールを有効にする場合など、オープンアクセスポリシーの使用が許容される状況もあります。オープンアクセスポリシーを使用すると、特定のクライアントやツールなど、リクエストの署名が困難または不可能な場合にもドメインにアクセスできます。
保管中の暗号化を有効にする
OpenSearch Service ドメインでは、データへの不正アクセスの防止に役立つ保管中のデータの暗号化が提供されます。保管時の暗号化では、暗号化キーの保存と管理に AWS Key Management Service (AWS KMS) を使用し、暗号化を実行するために 256 ビットキー (AES-256) を使用する Advanced Encryption Standard アルゴリズムを使用します。
ドメインに機密データが保存されている場合、保管中のデータの暗号化を有効にします。
ノード間の暗号化を有効にする
ノード間の暗号化では、OpenSearch Service 内でデフォルトのセキュリティ機能の上に追加のセキュリティレイヤーを提供します。OpenSearch 内でプロビジョニングされたノード間のすべての通信のために Transport Layer Security (TLS) を実装します。ノード間の暗号化により、HTTPS 経由で OpenSearch Service ドメインに送信されたデータは、ノード間で配布およびレプリケートされる間、転送中も暗号化されたままになります。
ドメインに機密データが保存されている場合は、ノード間の暗号化を有効にします。
によるモニタリング AWS Security Hub CSPM
AWS Security Hub CSPM を使用して、セキュリティのベストプラクティスに関連する OpenSearch Service の使用状況をモニタリングします。Security Hub CSPM によってセキュリティコントロールが使用されてリソース設定およびセキュリティ標準が評価され、さまざまなコンプライアンスフレームワークに準拠できるようにサポートします。Security Hub CSPM を使用して OpenSearch Service リソースを評価する方法の詳細については、AWS Security Hub 「 ユーザーガイド」の「 Amazon OpenSearch Service コントロール」を参照してください。
コスト最適化
次のベストプラクティスは、OpenSearch Service のコストを最適化および節約するために適用されます。
最新世代のインスタンスタイプを使用する
OpenSearch Service は、より低いコストでより優れたパフォーマンスを提供する新しい Amazon EC2 インスタンスタイプを常に採用しています。常に最新世代のインスタンスを使用することをお勧めします。
本番稼働用ドメインで T2 や t3.small インスタンスを使用しないようにしてください。それらは負荷の高い状態では不安定になることがあるためです。r6g.large インスタンスは、小規模な本番ワークロードのためのオプションです (データノードと専用マスターノードの両方として)。
最新の Amazon EBS gp3 ボリュームを使用する
OpenSearch データノードは、迅速なインデックス作成とクエリを提供するために、低レイテンシーかつ高スループットのストレージを必要とします。Amazon EBS gp3 ボリュームを使用することによって、以前提供されていた Amazon EBS gp2 ボリュームタイプよりも 9.6% 低いコストで、より優れたベースラインパフォーマンス (IOPS およびスループット) を得ることができます。gp3 を使用すると、ボリュームサイズにかかわらず、追加の IOPS とスループットをプロビジョニングできます。これらのボリュームはバーストクレジットを使用しないため、前世代のボリュームよりも安定性が優れています。gp3 ボリュームタイプでは、データノードあたりのボリュームサイズの上限も、gp2 ボリュームタイプの 2 倍に拡大されます。これらのより大きなボリュームを使用すると、データノードあたりのストレージ容量を増やすことによって、パッシブデータのコストを削減できます。
時系列のログデータのために UltraWarm とコールドストレージを使用する
ログ分析のために OpenSearch を使用している場合は、データを UltraWarm またはコールドストレージに移動してコストを削減します。Index State Management (ISM) を使用して、ストレージ階層間でデータを移行し、データ保持を管理します。
UltraWarm は、大量の読み取り専用データをコストパフォーマンスに優れた方法で OpenSearch Service に保存できます。UltraWarm はストレージのために Amazon S3 を使用します。つまり、データはイミュータブルであり、必要なコピーは 1 つだけです。インデックス内のプライマリシャードのサイズに相当するストレージの料金のみをお支払いいただきます。UltraWarm クエリのレイテンシーは、クエリの処理に必要な S3 データの量が増えると高くなります。データがノードにキャッシュされると、UltraWarm インデックスに対するクエリは、ホットインデックスに対するクエリと同様に実行されます。
コールドストレージも S3 を使用します。コールドデータをクエリする必要がある場合は、既存の UltraWarm ノードに選択的にアタッチできます。コールドデータは UltraWarm と同じマネージドストレージコストを発生させますが、コールドストレージ内のオブジェクトは UltraWarm ノードリソースを消費しません。そのため、コールドストレージは UltraWarm ノードのサイズや数に影響を及ぼすことなく、大量のストレージキャパシティを提供します。
ホットストレージから移行するデータが約 2.5 TiB になると、UltraWarm は費用対効果が高くなります。フィルレートをモニタリングし、そのデータ量に達する前にインデックスを UltraWarm に移動するように計画します。
リザーブドインスタンスの推奨事項を確認する
パフォーマンスとコンピューティング消費量の適切なベースラインを把握したら、リザーブドインスタンス (RI) の購入を検討してください。割引は、前払いなしの 1 年間の予約で約 30% から始まり、全額前払いの 3 年間の契約では最大 50% まで増加する可能性があります。
少なくとも 14 日間にわたって安定した稼働状態を確認できたら、「AWS Cost Management ユーザーガイド」の「Accessing reservation recommendations」を参照してください。Amazon OpenSearch Service の見出しには、特定の RI 購入の推奨事項と予測される節約額が表示されます。
