翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
概要
解釈可能なモデルとは何か、モデルの解釈としてどの情報が適切かについて、広く受け入れられている定義はありません。このガイドでは、一般的に使用される特徴量の重要度という概念に焦点を当て、各入力特徴量の重要度スコアを使用して、それがモデルの出力にどのように影響するかを解釈します。この方法では洞察が得られますが、注意も必要です。特徴量の重要度スコアは誤解を招く可能性があるため、可能であれば対象分野の専門家による検証を含め、慎重に分析する必要があります。具体的には、特徴量の重要度スコアを検証せずに信頼しないことをお勧めします。誤解があると、不適切なビジネス上の意思決定につながる可能性があるためです。
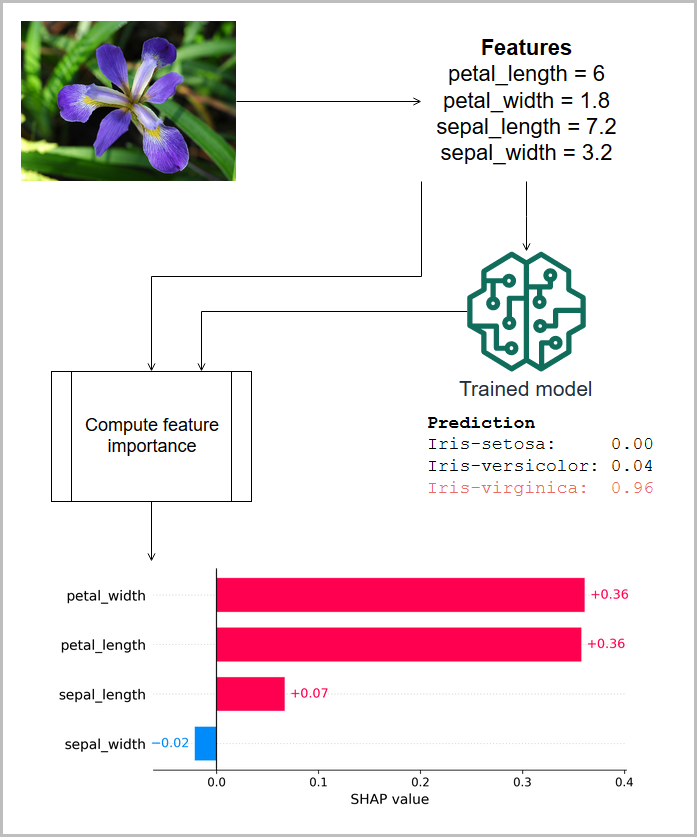
以下の図では、測定された虹彩の特徴が植物の種類を予測するモデルに渡され、この予測に関連する特徴のインポート (SHAP帰属) が表示されています。この場合、花弁の長さ、花弁の幅、がく片の長さはすべてアイリス・バージニカの分類にプラスに寄与しますが、がく片の幅は負の寄与をしています。(この情報は [4] の虹彩データセットに基づいています。)
特徴量の重要度スコアは、そのスコアがすべての入力にわたってモデルに有効であることを示すグローバルでも、スコアが単一のモデル出力に適用されることを示すローカルでもかまいません。局所的な特徴量の重要度スコアは、モデルの出力値を算出するためにスケーリングおよび合計されることが多く、これをアトリビューションと呼びます。入力特徴がモデル出力に及ぼす影響を理解しやすいため、単純なモデルの方が解釈しやすいと考えられます。たとえば、線形回帰モデルでは、係数の大きさによって全体的な特徴量の重要度スコアが得られ、特定の予測では、局所的な特徴の属性はその係数と特徴値の積になります。予測に対する直接的なローカル特徴の重要度スコアがない場合、ベースライン入力特徴のセットから重要度スコアを計算し、ある特徴がベースラインに対してどのように貢献するかを理解することができます。
