翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
SageMaker Clarify を使用してバイアスを説明および検出する
このトピックでは、公平性とモデルの説明可能性を理解する方法、および Amazon SageMaker Clarify を使用してバイアスを説明および検出する方法について説明します。 SageMaker Clarify 処理ジョブを設定してバイアスメトリクスと特徴量属性を計算し、モデルの説明可能性に関するレポートを生成できます。 SageMaker Clarify 処理ジョブは、専用の SageMaker Clarify コンテナイメージを使用して実装されます。次の手順は、 SageMaker Clarify 処理ジョブを設定、実行、トラブルシューティングする方法と、分析を設定する方法を示しています。
機械学習予測の公平性とモデルの説明可能性とは
機械学習 (ML) モデルは、金融サービス、医療、教育、人事などの分野で意思決定を行うのに役立ちます。政治家、規制当局、支持者は、ML やデータ駆動型システムがもたらす倫理やポリシーの課題に対する認識を高めています。Amazon SageMaker Clarify は、機械学習モデルが特定の予測を行った理由と、トレーニングまたは推論中にこのバイアスがこの予測に影響を与えるかどうかを理解するのに役立ちます。 SageMaker Clarify には、バイアスが少なく、理解しやすい機械学習モデルの構築に役立つツールも用意されています。 SageMaker Clarify は、リスクおよびコンプライアンスチームや外部の規制当局に提供できるモデルガバナンスレポートを生成することもできます。 SageMaker Clarify では、次のことを実行できます。
-
でバイアスを検出し、モデル予測の説明に役立ちます。
-
トレーニング前のデータのバイアスのタイプを特定します。
-
トレーニング中またはモデルが本番環境にあるときに発生する可能性のあるトレーニング後のデータのバイアスのタイプを特定します。
SageMaker Clarify は、モデルが特徴量属性を使用して予測を行う方法を説明するのに役立ちます。また、本番環境にある推論モデルにバイアスと特徴量属性の両方のドリフトをモニタリングすることもできます。この情報は、以下の領域で役立ちます。
-
規制 – ポリシー作成者やその他の規制当局は、ML モデルからの出力を使用する決定が差別的に与える影響について懸念する可能性があります。例えば、ML モデルはバイアスをエンコードし、自動決定に影響を与える可能性があります。
-
ビジネス — 規制対象ドメインでは、ML モデルが予測を行う方法について信頼性の高い説明が必要になる場合があります。モデルの説明可能性は、信頼性、安全性、コンプライアンスに依存する業界にとって特に重要です。これには、金融サービス、人事、医療、自動輸送などが含まれます。例えば、ローン申請では、ML モデルがローン担当者、予測担当者、顧客に特定の予測をどのように行ったかについての説明が必要になる場合があります。
-
データサイエンス — データサイエンティストや ML エンジニアは、モデルがノイズの多い特徴量や無関係な特徴量に基づいて推論を行っているかどうかを判断できるときに、ML モデルをデバッグして改善できます。また、モデルの制限や、モデルが遭遇する可能性のある障害モードを理解することもできます。
SageMaker Clarify を SageMaker パイプラインに統合する不正自動車クレームの完全な機械学習モデルを設計および構築する方法を示すブログ記事については、「Architect」を参照し、 AWS: Amazon end-to-endデモで完全な機械学習ライフサイクルを構築 SageMaker
ML ライフサイクルにおける公平性と説明可能性を評価するためのベストプラクティス
プロセスとしての公平性 — バイアスと公平性の概念は、その適用によって異なります。バイアスの測定とバイアスメトリクスの選択は、社会的、法的、その他の非技術的な考慮事項によって導かれる場合があります。公平性を考慮した ML アプローチの導入を成功させるには、コンセンサスを構築し、主要な利害関係者間でのコラボレーションの達成が含まれます。これには、製品、ポリシー、法律、エンジニアリング、AI/ML チーム、エンドユーザー、コミュニティなどが含まれます。
ML ライフサイクルにおける設計による公平性と説明可能性 — ML ライフサイクルの各段階で公平性と説明可能性を考慮します。これらの段階には、問題形成、データセット構築、アルゴリズム選択、モデルトレーニングプロセス、テストプロセス、デプロイ、モニタリングとフィードバックが含まれます。この分析を行うには適切なツールを用意することが重要です。ML ライフサイクル中は、次の質問をすることをお勧めします。
-
モデルは、ますます不公平な結果をもたらすフィードバックループを奨励していますか?
-
アルゴリズムは問題の道徳的解決策ですか?
-
トレーニングデータは異なるグループの代表的なものですか?
-
ラベルや特徴にバイアスはありますか?
-
バイアスを軽減するためにデータを変更する必要がありますか?
-
公平性の制約を目標関数に含める必要がありますか?
-
モデルは関連する公平性メトリクスを使用して評価されていますか?
-
ユーザー間で不均等な影響はありますか?
-
モデルは、トレーニングまたは評価されていない母集団にデプロイされていますか?
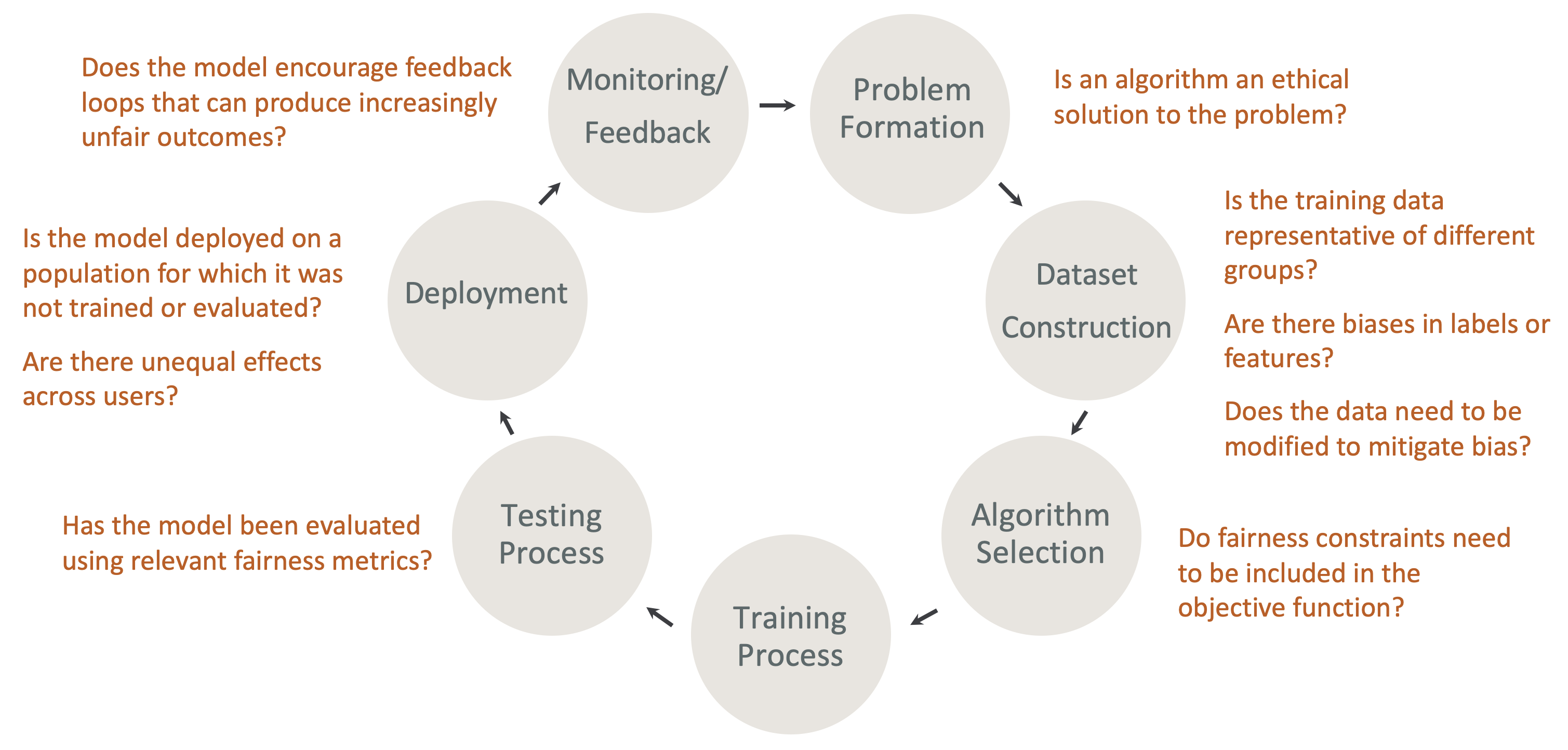
SageMaker 説明とバイアスドキュメントのガイド
バイアスは、モデルのトレーニング前とトレーニング後の両方のデータで発生し、測定できます。 SageMaker Clarify は、トレーニング後のモデル予測と本番環境にデプロイされたモデルの説明を提供できます。 SageMaker Clarify は、ベースラインの説明属性のドリフトについて本番環境のモデルをモニタリングし、必要に応じてベースラインを計算することもできます。 SageMaker Clarify を使用したバイアスの説明と検出に関するドキュメントは、次のように構造化されています。
-
バイアスと説明可能性の処理ジョブの設定については、「」を参照してください SageMaker Clarify 処理ジョブを設定する。
-
モデルのトレーニングに使用される前に前処理データのバイアスを検出する方法については、「」を参照してくださいトレーニング前のデータのバイアスを検出する。
-
トレーニング後のデータとモデルバイアスの検出については、「」を参照してくださいトレーニング後のデータとモデルのバイアスを検出する。
-
トレーニング後にモデル予測を説明するためのモデルに依存しない特徴属性アプローチについては、「」を参照してくださいモデルの説明可能性。
-
モデルトレーニング中に確立されたベースラインからの特徴量寄与ドリフトのモニタリングについては、「」を参照してください本番稼働中のモデルの特徴属性ドリフトをモニタリングする。
-
ベースラインドリフトの本番環境にあるモデルのモニタリングについては、「」を参照してください本番稼働中のモデルのバイアスドリフトをモニタリングする。
-
エンドポイントからリアルタイムで説明を取得する方法については、 SageMaker「」を参照してください SageMaker Clarify によるオンライン説明可能性。
SageMaker Clarify 処理ジョブの仕組み
SageMaker Clarify を使用して、説明可能性とバイアスについてデータセットとモデルを分析できます。 SageMaker Clarify 処理ジョブは、 SageMaker Clarify 処理コンテナを使用して、入力データセットを含む Amazon S3 バケットとやり取りします。 SageMaker Clarify を使用して、 SageMaker 推論エンドポイントにデプロイされた顧客モデルを分析することもできます。
次の図は、 SageMaker Clarify 処理ジョブが入力データとやり取りする方法、およびオプションでカスタマーモデルとやり取りする方法を示しています。このやり取りは、実行される分析の種類によって異なります。 SageMaker Clarify 処理コンテナは、S3 バケットから分析用の入力データセットと設定を取得します。特徴分析を含む特定の分析タイプでは、 SageMaker Clarify 処理コンテナはモデルコンテナにリクエストを送信する必要があります。次に、モデルコンテナが送信する応答からモデル予測を取得します。その後、 SageMaker Clarify 処理コンテナは分析結果を計算して S3 バケットに保存します。
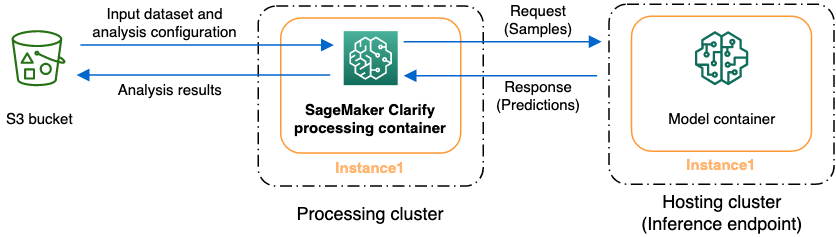
SageMaker Clarify 処理ジョブは、機械学習ワークフローのライフサイクルの複数の段階で実行できます。 SageMaker Clarify は、次の分析タイプを計算するのに役立ちます。
-
トレーニング前のバイアスメトリクス。これらのメトリクスは、データ内のバイアスを理解し、それに対処し、より公平なデータセットでモデルをトレーニングするのに役立ちます。トレーニング前のバイアスメトリクスについては、トレーニング前のバイアスを測定する「」を参照してください。トレーニング前のバイアスメトリクスを分析するジョブを実行するには、データセットとJSON分析設定ファイルを に提供する必要があります分析を設定する。
-
トレーニング後のバイアスメトリクス。これらのメトリクスは、アルゴリズム、ハイパーパラメータの選択、またはフローの前半では明らかではなかったバイアスを理解するのに役立ちます。トレーニング後のバイアスメトリクスの詳細については、「」を参照してくださいトレーニング後のデータとモデルのバイアスを測定する。 SageMaker Clarify はデータとラベルに加えてモデル予測を使用してバイアスを識別します。トレーニング後のバイアスメトリクスを分析するジョブを実行するには、データセットとJSON分析設定ファイルを提供する必要があります。設定にはモデル名またはエンドポイント名を含める必要があります。
-
シェイプされた値。特徴量がモデルの予測に与える影響を理解するのに役立ちます。Shapely 値の詳細については、「」を参照してくださいShapley 値を使用する特徴属性。この特徴量にはトレーニング済みのモデルが必要です。
-
部分依存プロット (PDPs)。1 つの特徴量の値を変更した場合に予測されるターゲット変数がどの程度変化するかを理解するのに役立ちます。の詳細についてはPDPs、部分依存プロット (PDPs) 分析「この機能にはトレーニング済みのモデルが必要です」を参照してください。
SageMaker Clarify では、トレーニング後のバイアスメトリクスと特徴量属性を計算するためにモデル予測が必要です。エンドポイントを指定するか、 SageMaker Clarify はモデル名を使用してエフェメラルエンドポイントを作成します。これはシャドウエンドポイント とも呼ばれます。 SageMaker Clarify コンテナは、計算が完了した後にシャドウエンドポイントを削除します。大まかに言うと、 SageMaker Clarify コンテナは次のステップを完了します。
-
入力とパラメータを検証します。
-
シャドウエンドポイントを作成します (モデル名が提供されている場合)。
-
入力データセットをデータフレームに読み込みます。
-
必要に応じて、エンドポイントからモデル予測を取得します。
-
バイアスメトリクスと特徴量属性を計算します。
-
シャドウエンドポイントを削除します。
-
分析結果を生成します。
SageMaker Clarify 処理ジョブが完了すると、分析結果はジョブの処理出力パラメータで指定した出力場所に保存されます。これらの結果には、バイアスメトリクスとグローバル特徴属性を含むJSONファイル、ビジュアルレポート、ローカル特徴属性の追加ファイルが含まれます。結果は出力場所からダウンロードして表示できます。
バイアスメトリクス、説明可能性、およびそれらの解釈方法の詳細については、「Amazon SageMaker Clarify がバイアスの検出にどのように役立つか
サンプルノートブック
以下のセクションには、 SageMaker Clarify の使用を開始するのに役立つノートブック、分散ジョブ内のタスクを含む特別なタスクやコンピュータビジョンに使用するノートブックが含まれています。
使用開始
次のサンプルノートブックは、 SageMaker Clarify を使用して説明可能性タスクとモデルバイアスタスクを開始する方法を示しています。これらのタスクには、処理ジョブの作成、機械学習 (ML) モデルのトレーニング、モデル予測のモニタリングが含まれます。
-
Amazon SageMaker Clarify による説明可能性とバイアスの検出
— SageMaker Clarify を使用して処理ジョブを作成し、バイアスを検出してモデル予測を説明します。 -
バイアスドリフトと特徴量属性ドリフトのモニタリング Amazon SageMaker Clarify
– Amazon SageMaker Model Monitor を使用して、バイアスドリフトと特徴量属性ドリフトを経時的にモニタリングします。 -
JSON Lines 形式のデータセットを Clarify 処理ジョブに読み
込む方法。 SageMaker -
バイアスを軽減し、別のバイアスのないモデルをトレーニングしてモデルレジストリに配置する
– Synthetic Minority Over-sampling Technique (SMOTE) と SageMaker Clarify を使用してバイアスを軽減し、別のモデルをトレーニングしてから、新しいモデルをモデルレジストリに配置します。このサンプルノートブックでは、データ、コード、モデルメタデータなどの新しいモデルアーティファクトをモデルレジストリに配置する方法も示しています。このノートブックは、Architect で説明されている SageMaker パイプラインに SageMaker Clarify を統合し、ブログ記事で完全な機械学習ライフサイクルを構築する AWS 方法を示すシリーズの一部です。
特殊なケース
次のノートブックでは、独自のコンテナ内や自然言語処理タスクなどの特殊なケースに SageMaker Clarify を使用する方法を示します。
-
SageMaker Clarify による公平性と説明可能性 (独自のコンテナを使用)
— SageMaker Clarify と統合してバイアスを測定し、説明可能性分析レポートを生成できる独自のモデルとコンテナを構築します。このサンプルノートブックでは、主要な用語を紹介し、 SageMaker Studio Classic からレポートにアクセスする方法も示しています。 -
SageMaker Clarify Spark 分散処理による公平性と説明可能性
— 分散処理を使用して、データセットのトレーニング前バイアスとモデルのトレーニング後バイアスを測定する SageMaker Clarify ジョブを実行します。このサンプルノートブックでは、モデル出力の入力機能の重要性に関する説明を取得し、 SageMaker Studio Classic から説明可能性分析レポートにアクセスする方法も示しています。 -
SageMaker Clarify による説明可能性 - 部分依存プロット (PDP)
– SageMaker Clarify を使用してモデル説明可能性レポートを生成PDPsし、アクセスします。 -
SageMaker Clarify Natural Language Processing (NLP) の説明可能性を使用したテキスト感情分析の説明
– テキスト感情分析に SageMaker Clarify を使用します。
これらのノートブックは Amazon SageMaker Studio Classic で実行することが検証されています。Studio Classic でノートブックを開く方法の手順が必要な場合は、「」を参照してくださいAmazon SageMaker Studio Classic ノートブックを作成または開く。カーネルの選択を求めるメッセージが表示されたら、[Python 3 (Data Science)] (Python 3 (データサイエンス)) を選択します。
