翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
リアルタイム推論用のモデルをデプロイする
重要
Amazon SageMaker Studio または Amazon SageMaker Studio Classic に Amazon SageMaker リソースの作成を許可するカスタム IAM ポリシーでは、これらのリソースにタグを追加するアクセス許可も付与する必要があります。Studio と Studio Classic は、作成したリソースに自動的にタグ付けするため、リソースにタグを追加するアクセス許可が必要になります。IAM ポリシーで Studio と Studio Classic によるリソースの作成が許可されていても、タグ付けが許可されていない場合は、リソースを作成しようとしたときに「AccessDenied」エラーが発生する可能性があります。詳細については、「SageMaker AI リソースにタグ付けのアクセス許可を付与する」を参照してください。
SageMaker リソースを作成するためのアクセス許可を付与する AWS Amazon SageMaker AI の マネージドポリシー には、それらのリソースの作成中にタグを追加するためのアクセス許可もあらかじめ含まれています。
SageMaker AI ホスティングサービスを使用してモデルをデプロイするには、複数のオプションがあります。SageMaker Studio を使用してモデルをインタラクティブにデプロイできます。または、SageMaker Python AWS SDK や SDK for Python (Boto3) などの SDK を使用してプログラムでモデルをデプロイすることもできます。を使用してデプロイすることもできます AWS CLI。
[開始する前に]
SageMaker AI モデルをデプロイする前に、次を探して記録してください:
-
Amazon S3 バケット AWS リージョン がある 。
-
モデルアーティファクトが保存されている Amazon S3 URI パス
-
SageMaker AI の IAM ロール
-
推論コードを含むカスタムイメージの Docker Amazon ECR URI レジストリパス、または および でサポートされている組み込み Docker イメージのフレームワークとバージョン AWS
各 AWS のサービス で使用できる のリストについては AWS リージョン、「リージョンマップとエッジネットワーク
重要
モデルアーティファクトが保存されている Amazon S3 バケットは、作成するモデルと同じ AWS リージョン に存在している必要があります。
複数のモデルでリソース使用率を共有する
Amazon SageMaker AI を使用して、エンドポイントにモデルを 1 つまたは複数デプロイできます。複数のモデルがエンドポイントを共有する場合は、そこでホストされるリソース (ML 演算処理インスタンス、CPU、アクセラレーターなど) を共同で使用します。エンドポイントに複数のモデルを柔軟にデプロイするには、各モデルを推論コンポーネントとして定義するのが一番です。
推論コンポーネント
推論コンポーネントは、モデルをエンドポイントにデプロイするために使用できる SageMaker AI ホスティングオブジェクトです。推論コンポーネント設定では、モデル、エンドポイント、およびエンドポイントがホストするリソースをモデルがどのように使用するかを指定します。モデルを指定する際、SageMaker AI Model オブジェクトを指定することも、モデルアーティファクトとイメージを直接指定することもできます。
設定では、必要な CPU コア、アクセラレータ、メモリをモデルに割り当てる方法を調整することで、リソース使用率を最適化できます。エンドポイントに複数の推論コンポーネントをデプロイし、各推論コンポーネントに 1 つのモデルと、そのモデルのリソース使用率のニーズを含めることができます。
推論コンポーネントをデプロイした後、SageMaker API で InvokeEndpoint アクションを使用すると、関連付けられたモデルを直接呼び出すことができます。
推論コンポーネントには以下の利点があります。
- 柔軟性
-
推論コンポーネントでは、モデルのホスティングの詳細がエンドポイント自体から切り離されます。そのため、モデルをエンドポイントでどのようにホスティングおよび提供するかを柔軟にコントロールできます。同じインフラストラクチャで複数のモデルをホスティングし、必要に応じてエンドポイントにモデルを追加または削除できます。各モデルは個別にアップデートできます。
- スケーラビリティ
-
ホストする各モデルのコピー数を指定したり、モデルがリクエストを処理するために必要なコピーの最小数を設定したりできます。推論コンポーネントのコピーをゼロにスケールダウンすることで、別のコピーをスケールアップする余地を作成できます。
以下を使用してモデルをデプロイすると、SageMaker AI がモデルを推論コンポーネントとしてパッケージ化します。
-
SageMaker Studio Classic。
-
Model オブジェクトをデプロイする SageMaker Python SDK (エンドポイントタイプを
EndpointType.INFERENCE_COMPONENT_BASEDに設定した場合)。 -
エンドポイントにデプロイする
InferenceComponentオブジェクト AWS SDK for Python (Boto3) を定義する 。
SageMaker Studio を使用してモデルをデプロイする
SageMaker Studio を使用してモデルをインタラクティブに作成およびデプロイするには、次の手順を実行します。Studio の詳細については、Studio のドキュメントを参照してください。さまざまなデプロイシナリオの詳細なチュートリアルについては、ブログ「Package and deploy classical ML models and LLMs easily with Amazon SageMaker AI – Part 2」
アーティファクトとアクセス許可を準備する
SageMaker Studio でモデルを作成する前に、このセクションを完了してください。
アーティファクトを Studio に取り入れてモデルを作成する場合、次の 2 つのオプションがあります:
-
モデルアーティファクト、カスタム推論コード、
requirements.txtファイルに記載されている依存関係を含めてtar.gzアーカイブにあらかじめパッケージ化できます。 -
SageMaker AI からアーティファクトをパッケージ化できます。未加工のモデルアーティファクトと依存関係を
requirements.txtファイルに取り込むだけで、SageMaker AI によってデフォルトの推論コードが提供されます (または、デフォルトのコードを独自のカスタム推論コードで上書きすることもできます)。PyTorch、XGBoost のフレームワークであれば、SageMaker AI でこのオプションを使用できます。
モデル、 AWS Identity and Access Management (IAM) ロール、Docker コンテナ (または SageMaker AI に構築済みのコンテナがある目的のフレームワークとバージョン) を持ち込むだけでなく、SageMaker AI Studio を介してモデルを作成およびデプロイするアクセス許可も付与する必要があります。
AmazonSageMakerFullAccess ポリシーを IAM ロールにアタッチし、SageMaker AI と他のサービスへのアクセスを可能にする必要があります。Studio でインスタンスタイプの料金を確認するには、AWS PriceListServiceFullAccess ポリシーもアタッチする必要があります (または、ポリシー全体をアタッチしない場合は、pricing:GetProducts アクションを使用します)。
モデルの作成時にモデルアーティファクトをアップロードする場合 (または推論レコメンデーションのサンプルペイロードファイルをアップロードする場合)、Amazon S3 バケットを作成する必要があります。バケット名には、 SageMaker AIという単語のプレフィックスを付ける必要があります。SageMaker AI では大文字小文字 (Sagemaker または sagemaker) は区別されません。
バケット命名規則 sagemaker-{ を使用することをお勧めします。このバケットは、アップロードしたアーティファクトを保存するために使用されます。Region}-{accountID}
バケットを作成したら、次の CORS (クロスオリジンリソース共有) ポリシーをバケットにアタッチします。
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
次のいずれかの方法で、CORS ポリシーを Amazon S3 バケットにアタッチします。
-
Amazon S3 コンソールのクロスオリジンリソース共有 (CORS) の編集
ページに移動する -
Amazon S3 API の PutBucketCors を使用する。
-
put-bucket-cors AWS CLI コマンドを使用します。
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
デプロイモデルを作成する
この手順では、アーティファクトおよびその他の項目 (コンテナとフレームワーク、カスタム推論コード、ネットワーク設定など) を SageMaker AI で入力して、モデルのデプロイ可能なバージョンを作成します。
SageMaker Studio でデプロイ可能なモデルを作成するには、次の手順を実行します。
-
SageMaker Studio アプリケーションを開きます。
-
左のナビゲーションペインで [モデル] を選択します。
-
[デプロイ可能なモデル] タブを選択します。
-
デプロイ可能なモデルページで [作成] を選択します。
-
デプロイ可能なモデルの作成ページの [モデル名] フィールドに、モデルの名前を入力します。
デプロイ可能なモデルの作成ページで入力するセクションは、他にもいくつかあります。
[コンテナ定義] セクションは次のスクリーンショットのようになります。
![Studio でモデルを作成する際の [コンテナ定義] セクションのスクリーンショット。](images/inference/studio-container-definition.png)
[コンテナ定義] セクションで以下を実行します。
-
[コンテナタイプ] では、SageMaker AI マネージドコンテナを使用する場合は [構築済みコンテナ] を選択し、独自のコンテナを使用する場合は [独自のコンテナ] を選択します。
-
[構築済みコンテナ] を選択した場合、使用する [コンテナフレームワーク]、[フレームワークバージョン]、および [ハードウェアタイプ] を選択します。
-
[独自のコンテナ] を選択した場合は、[コンテナイメージへの ECR パス] にAmazon ECR パスを入力します。
次に、[アーティファクト]セクションを次のスクリーンショットのように入力します。
![Studio でモデルを作成する [アーティファクト] セクションのスクリーンショット。](images/inference/studio-artifacts-section.png)
[アーティファクト] セクションでは、以下を実行します。
-
SageMaker AI でモデルアーティファクト (PyTorch または XGBoost) をパッケージ化できるフレームワークを使用している場合は、[アーティファクト] で [アーティファクトをアップロード] オプションを選択します。このオプションを使用すると、未加工のモデルアーティファクト、カスタム推論コード、および requirements.txt ファイルを指定するだけで、SageMaker AI によってアーカイブのパッケージ化が処理されます。以下の操作を実行します。
-
[アーティファクト] で、[アーティファクトのアップロード] を選択して処理を続行します。または、
tar.gzアーカイブにモデルファイル、推論コード、requirements.txtファイルが含まれる場合は、[S3 の URI を事前パッケージ化アーティファクトに入力する] を選択します。 -
アーティファクトのアップロードを選択した場合は、[S3 バケット] に、SageMaker AI がアーティファクトをパッケージ化した後にそれを保存する Amazon S3 のバケットへのパスを入力します。以下の手順を実行します。
-
[モデルアーティファクトをアップロード] でモデルファイルをアップロードします。
-
SageMaker AI が推論のために提供するデフォルトコードを使用する場合は、[推論コード] で [デフォルトの推論コードを使用] を選択します。独自の推論コードを使用する場合は、[カスタマイズした推論コードをアップロード] を選択します。
-
[requirements.txt をアップロード] で、実行時にインストールする依存関係のリストが入力されたテキストファイルをアップロードします。
-
-
SageMaker AI でモデルアーティファクトをパッケージ化できるフレームワークを使用しない場合は、Studio に [事前パッケージ化アーティファクト] オプションが表示され、
tar.gzアーカイブにパッケージ化されたすべてのアーティファクトを入力する必要があります。以下の操作を実行します。-
[事前パッケージ化アーティファクト] で、
tar.gzアーカイブが Amazon S3 に既にアップロードされている場合は、[S3 の URI を事前パッケージ化モデルアーティファクトに入力する] を選択します。アーカイブを SageMaker AI に直接アップロードする場合は、[事前パッケージ化モデルアーティファクトをアップロード] を選択します。 -
[S3 の URI を事前パッケージ化モデルアーティファクトに入力する]を選択した場合は、Amazon S3 のアーカイブへのパスを S3 URI に入力します。または、ローカルマシンからアーカイブを選択してアップロードします。
-
次のセクションは [セキュリティ] です。次のスクリーンショットのように表示されます。
![Studio でモデルを作成する [セキュリティ] セクションのスクリーンショット。](images/inference/studio-security-section.png)
[セキュリティ] セクションで、以下の操作を行います。
-
[IAM ロール]に、IAM ロールの ARN を入力します。
-
(オプション) [仮想プライベートクラウド (VPC)] で、モデル設定とアーティファクトを保存する Amazon VPC を選択します。
-
(オプション) コンテナのインターネットアクセスを制限する場合は、[ネットワークの隔離] トグルをオンにします。
最後に、オプションで [詳細オプション] セクションに入力します。次のスクリーンショットのように表示されます。
![Studio でモデルを作成する [詳細オプション] セクションのスクリーンショット。](images/inference/studio-advanced-options.png)
(オプション) [詳細オプション] セクションで、以下の操作を行います:
-
作成されたモデルで Amazon SageMaker Inference Recommender ジョブを実行する場合は、[カスタマイズされたインスタンスのレコメンデーション] トグルをオンにします。Inference Recommender は、推論のパフォーマンスとコストを最適化できるインスタンスタイプを推奨するための機能です。これらのインスタンスのレコメンデーションは、モデルのデプロイを準備する際に表示されます。
-
[環境変数を追加] には、コンテナの環境変数をキーと値のペアで入力します。
-
[タグ] に任意のタグをキーと値のペアで入力します。
-
モデルとコンテナの設定が完了したら、[デプロイ可能なモデルを作成] を選択します。
これで、SageMaker Studio にデプロイ可能なモデルが完成しました。
モデルをデプロイする
最後に、前の手順で設定したモデルを HTTPS エンドポイントにデプロイします。エンドポイントに 1 つまたは複数のモデルをデプロイできます。
モデルとエンドポイントの互換性
モデルをエンドポイントにデプロイする前に、以下の設定がモデルとエンドポイント間で同じであり、互換性が保たれていることを確認してください。
-
IAM ロール
-
Amazon VPC (サブネットとセキュリティグループ)
-
ネットワークの隔離 (有効または無効)
互換性のないエンドポイントにモデルがデプロイされないよう、Studio で次の処理が行われます。
-
新しいエンドポイントにモデルをデプロイすると、SageMaker AI は互換性を維持するようにエンドポイントを設定します。この設定を変更して互換性が失われると、Studio はアラートを表示し、デプロイが失敗します。
-
既存のエンドポイントにデプロイすると、エンドポイントに互換性がない場合は Studio がアラートを表示し、デプロイが失敗します。
-
デプロイに複数のモデルを追加する場合、相互に互換性がなければ、Studio によってモデルのデプロイがエラーになります。
Studio にモデルとエンドポイントの非互換性に関するアラートが表示された場合、[詳細を表示] を選択して、どの設定で互換性が失われたかを確認できます。
モデルをデプロイするために、Studio で以下を実行する方法を選択できます。
-
SageMaker Studio アプリケーションを開きます。
-
左のナビゲーションペインで [モデル] を選択します。
-
[モデル] ページで、SageMaker AI モデルのリストから 1 つ以上のモデルを選択します。
-
[デプロイ] をクリックします。
-
[エンドポイント名] で、ドロップダウンメニューを開きます。既存のエンドポイントを選択するか、モデルをデプロイする新しいエンドポイントを作成します。
-
[インスタンスタイプ] で、エンドポイントに使用するインスタンスタイプを選択します。モデルに対して以前に Inference Recommender ジョブを実行している場合は、推奨されるインスタンスタイプが [推奨] というタイトルのリストに表示されます。実行していない場合は、モデルに適した [想定インスタンス] がいくつか表示されます。
JumpStart のインスタンスタイプの互換性
JumpStart モデルをデプロイする場合、Studio にはモデルがサポートするインスタンスタイプのみが表示されます。
-
[初期インスタンス数] には、エンドポイントにプロビジョニングするインスタンスの初期数を入力します。
-
[最大インスタンス数] には、トラフィックの増加に合わせてスケールアップする場合にエンドポイントにプロビジョニング可能なインスタンスの最大数を指定します。
-
デプロイするモデルがモデルハブで最も使用されている JumpStart LLM のいずれかである場合は、[代替設定] オプションが [インスタンスタイプ] と [インスタンス数] フィールドの後に表示されます。
最も一般的な JumpStart LLMs AWS の場合、 には、コストまたはパフォーマンスを最適化するために事前にベンチマークされたインスタンスタイプがあります。このデータを使用し、どのインスタンスタイプを LLM のデプロイに使用するかを判断できます。[代替設定] を選択して、ベンチマーク済みのデータを表示するダイアログボックスを開きます。パネルは次のスクリーンショットのようになります。
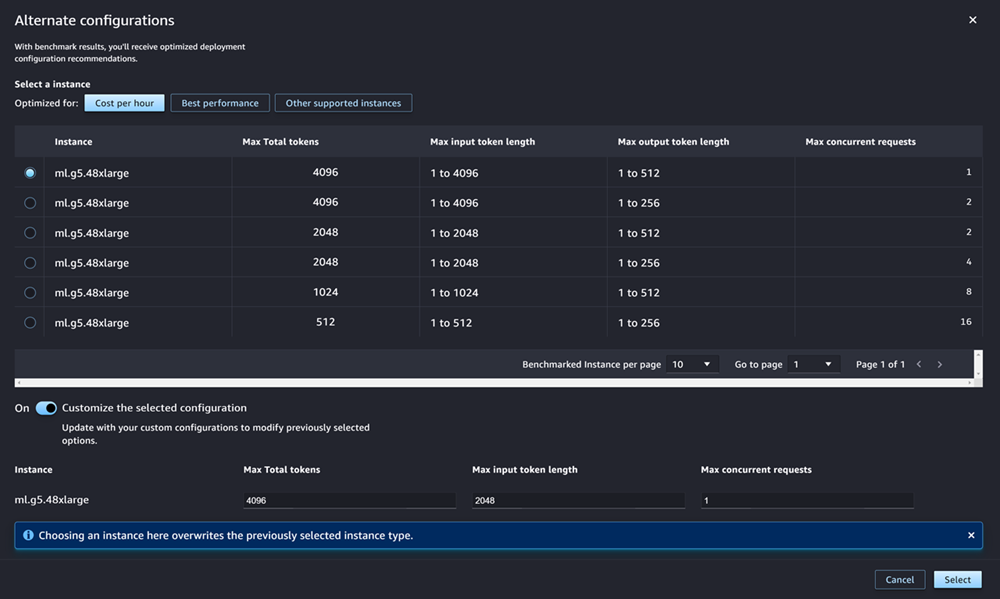
[代替設定] ボックスで以下の操作を行います。
-
インスタンスのタイプを選択します。[1 時間あたりのコスト] または [最高のパフォーマンス] を選択して、モデルのコストやパフォーマンスを最適化するインスタンスを表示します。[その他のサポートされているインスタンス] を選択して、JumpStart モデルと互換性のある他のインスタンスタイプのリストを表示することもできます。ここでインスタンスタイプを選択すると、手順 6 で指定したインスタンスが上書きされることに注意してください。
-
(任意) [選択した設定をカスタマイズ] トグルをオンにして、[トークン合計の最大数] (許可するトークンの最大数。入力トークンおよびモデルで生成されるトークンの合計)、[入力するトークンの最大長] (各リクエストで入力が許可されるトークンの最大数)、および [最大同時リクエスト] (モデルが一度に処理できるリクエストの最大数) を指定します。
-
[選択] を選択して、インスタンスタイプと設定を確認します。
-
-
[モデル] フィールドには、デプロイするモデルの名前がすでに入力されています。[モデルの追加] を選択して、デプロイにモデルを追加します。追加するモデルごとに、次のフィールドを入力します:
-
[CPU コアの数] に、モデルのみで使用される CPU コアを入力します。
-
[最小コピー数] には、任意の時点でエンドポイントでホストされるモデルコピーの最小数を入力します。
-
[最小 CPU メモリ (MB)] には、モデルに必要な最小メモリ量 (MB) を入力します。
-
[最大 CPU メモリ (MB)] には、モデルに使用を許可するメモリの最大量 (MB) を入力します。
-
-
(オプション) [詳細オプション] で、以下の操作を行います:
-
[IAM ロール] で、デフォルトの SageMaker AI IAM 実行ロールを使用するか、必要なアクセス許可を含む独自のロールを指定します。この IAM ロールは、デプロイ可能なモデルの作成時に指定したロールと同じである必要があります。
-
[仮想プライベートクラウド (VPC)] では、エンドポイントをホストする VPC を指定します。
-
Encryption KMS キーで、 AWS KMS キーを選択して、エンドポイントをホストする ML コンピューティングインスタンスにアタッチされたストレージボリューム上のデータを暗号化します。
-
[ネットワーク分離の有効化] トグルをオンにして、コンテナのインターネットアクセスを制限します。
-
[タイムアウト設定] で、[モデルデータのダウンロードタイムアウト (秒)] と [コンテナ起動のヘルスチェックタイムアウト (秒)] フィールドに値を入力します。これらの値によって、SageMaker AI がモデルをコンテナにダウンロードする最大時間と、コンテナを起動する最大時間が決まります。
-
[タグ] に任意のタグをキーと値のペアで入力します。
注記
SageMaker AI は、IAM ロール、VPC、およびネットワーク隔離の設定を、デプロイするモデルと互換性のある初期値を使用して設定します。この設定を変更して互換性が失われると、Studio はアラートを表示し、デプロイが失敗します。
-
オプションを設定すると、ページが次のスクリーンショットのように表示されます。
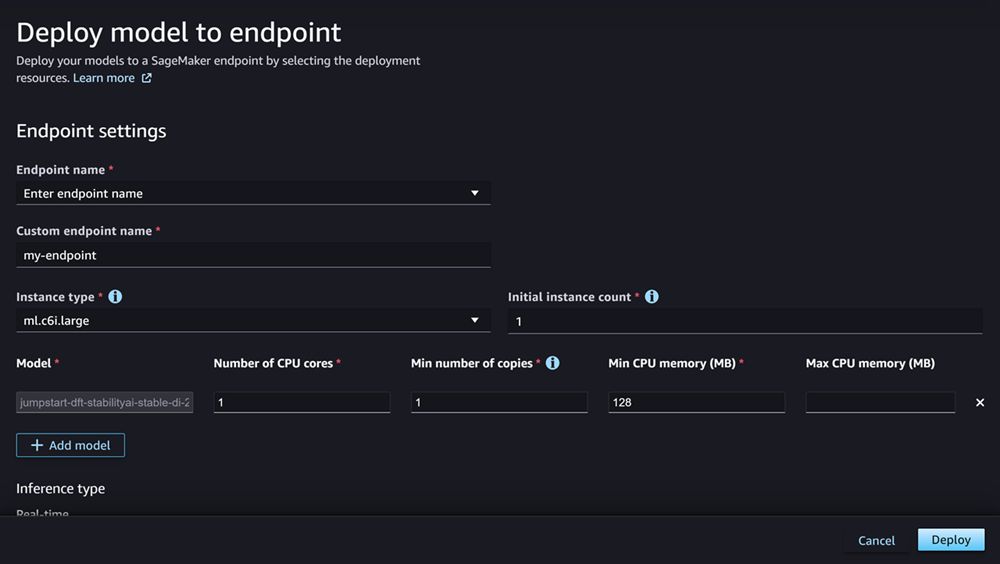
デプロイを設定したら、[デプロイ] を選択してエンドポイントを作成し、モデルをデプロイします。
Python SDK でモデルをデプロイする
SageMaker Python SDK を使用すると、2 つの方法でモデルを構築できます。1 つ目は、Model クラスまたは ModelBuilder クラスからモデルオブジェクトを作成する方法です。Model クラスを使用して Model オブジェクトを作成する場合は、モデルパッケージまたは推論コード (モデルサーバーによって異なります) を指定し、クライアントとサーバー間のデータのシリアル化と逆シリアル化を処理するスクリプトと、Amazon S3 にアップロードされる依存関係を指定する必要があります。2 つ目は、ModelBuilder を使用してモデルアーティファクトまたは推論コードを提供する方法です。ModelBuilder は依存関係を自動的に取得し、必要なシリアル化およびシリアル化解除関数を推論し、依存関係をパッケージ化して Model オブジェクトを作成します。ModelBuilder の詳細については、「ModelBuilder を使用して Amazon SageMaker AI でモデルを作成する」を参照してください。
次のセクションでは、モデルを作成する方法と、モデルオブジェクトをデプロイする方法を説明します。
セットアップする
以下に、モデルデプロイプロセスを準備する例を示します。必要なライブラリをインポートし、モデルアーティファクトを指す S3 URL を定義します。
例モデルアーティファクト URL
次のコードは、Amazon S3 URL を構築する例です。URL は、Amazon S3 バケット内の事前トレーニング済みモデルのモデルアーティファクトを指します。
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
完全な Amazon S3 URL が変数 model_url に保存され、次の例で使用されます。
概要
SageMaker Python SDK または SDK for Python (Boto3) を使用してモデルをデプロイする方法は複数あります。以下のセクションでは、いくつかのアプローチで実行する手順をまとめて説明します。それらの手順を、以下の例で示しています。
構成する
次の例では、モデルをエンドポイントにデプロイするために必要なリソースを設定します。
デプロイ
次の例は、モデルをエンドポイントにデプロイしています。
を使用してモデルをデプロイする AWS CLI
を使用して、モデルをエンドポイントにデプロイできます AWS CLI。
概要
を使用してモデルをデプロイする場合 AWS CLI、推論コンポーネントを使用して、または使用せずにデプロイできます。その両方のアプローチで実行するコマンドを、以下のセクションにまとめます。これらのコマンドは、以下の例で示されています。
構成する
次の例では、モデルをエンドポイントにデプロイするために必要なリソースを設定します。
デプロイ
次の例は、モデルをエンドポイントにデプロイしています。
