翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルトレーニング
機械学習 (ML) ライフサイクル全体のトレーニングステージは、トレーニングデータセットへのアクセスから最終モデルの生成、デプロイに最適なパフォーマンスを備えたモデルの選択まで多岐にわたります。以下のセクションで、利用可能な SageMaker のトレーニングの機能とリソースの概要と、それぞれの詳細な技術情報を学習できます。
SageMaker トレーニングの基本アーキテクチャ
SageMaker AI を初めて使用し、データセットでモデルをトレーニングするためのクイック機械学習ソリューションを探している場合は、SageMaker Canvas、SageMaker Studio Classic 内の JumpStart、SageMaker Autopilot などのノーコードまたはローコードのソリューションを使用することをご検討ください。
中級レベルのコーディング経験がある場合は、SageMaker Studio Classic ノートブックまたは SageMaker ノートブックインスタンスの使用をご検討ください。開始するには、SageMaker AI 入門ガイドの「モデルをトレーニングします」の手順に従ってください。これは、機械学習フレームワークを使用して独自のモデルとトレーニングスクリプトを作成するユースケースに推奨されます。
SageMaker AI ジョブの中核は、ML ワークロードのコンテナ化とコンピューティングリソースを管理する機能です。SageMaker Training プラットフォームは、ML トレーニングワークロードのインフラストラクチャのセットアップと管理に関連する負荷の大きい作業に対応します。SageMaker Training を使用すると、モデルの開発、トレーニング、ファインチューニングに集中できます。
以下のアーキテクチャ図は、SageMaker AI が機械学習トレーニングジョブを管理し、SageMaker AI ユーザーに代わって Amazon EC2 インスタンスをプロビジョニングする方法を示しています。SageMaker AI ユーザーは、独自のトレーニングデータセットを取り入れ、Amazon S3 に保存できます。SageMaker AI の組み込みアルゴリズムから機械学習モデルトレーニングを選択することも、一般的な機械学習フレームワークで構築されたモデルを使用して独自のトレーニングスクリプトを取り入れることもできます。
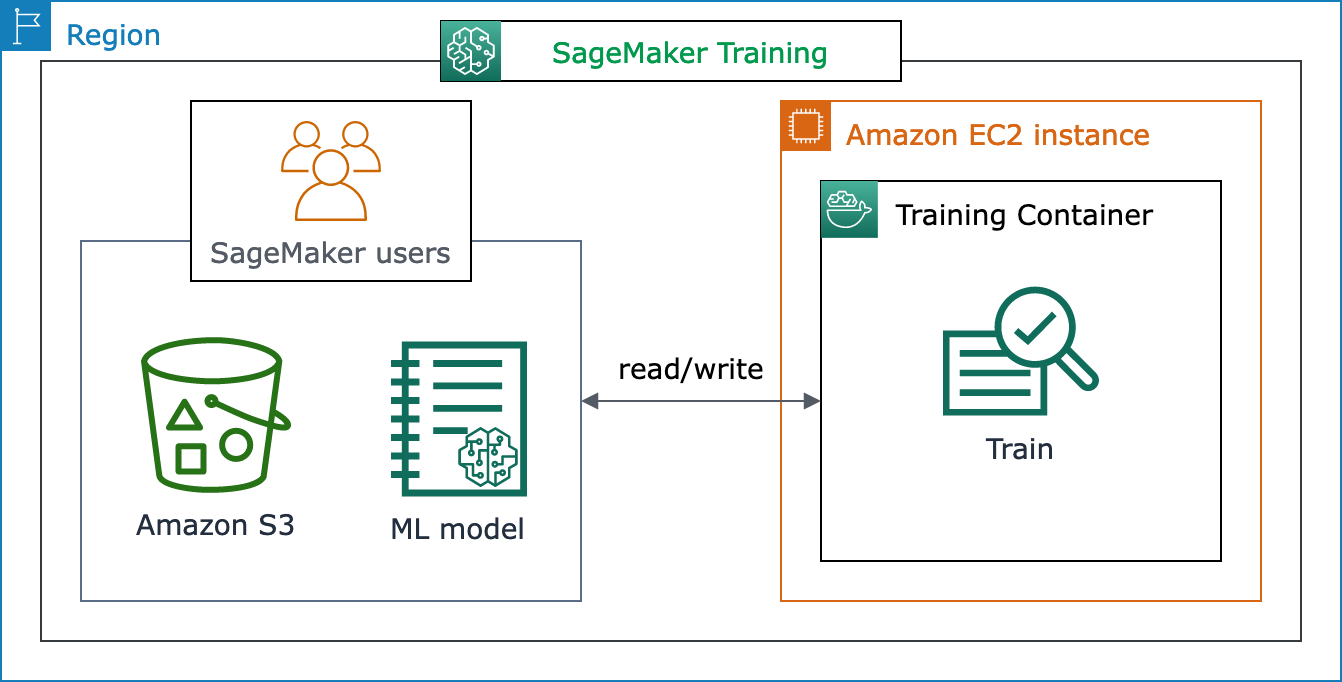
SageMaker トレーニングのワークフローと機能の全容
機械学習トレーニングの全行程には、機械学習モデルへのデータインジェスト、コンピュートインスタンスでのモデルのトレーニング、モデルのアーティファクトと出力の取得以外のタスクも含まれます。トレーニング前、トレーニング中、トレーニング後のあらゆる段階を評価して、モデルが目標とする精度を満たすように適切なトレーニングが実行されていることを確認する必要があります。
次のフローチャートは、機械学習ライフサイクルのトレーニングフェーズ全体におけるアクションの概要 (青いボックス) と利用可能な SageMaker トレーニングの機能 (水色のボックス) の概要を示しています。
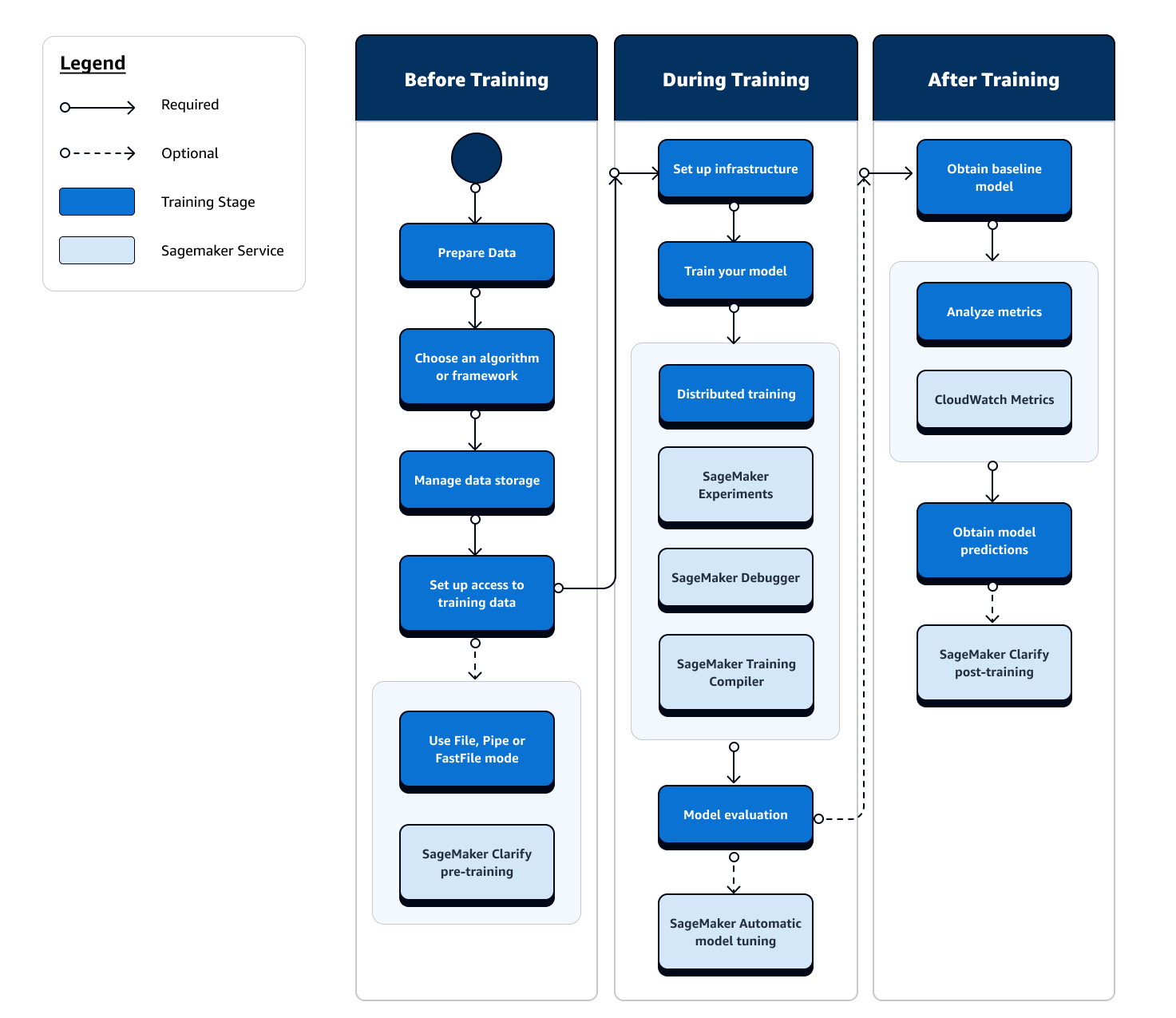
以下のセクションでは、前のフローチャートに示されているトレーニングの各フェーズと、機械学習トレーニングの 3 つのサブステージで SageMaker AI により提供される便利な機能について説明します。
トレーニング前
データリソースとアクセスを設定するシナリオはいくつかあり、トレーニングの前に検討する必要があります。次の図とトレーニング前の各段階の詳細な説明を参照して、どのような決定を下す必要があるかを把握してください。
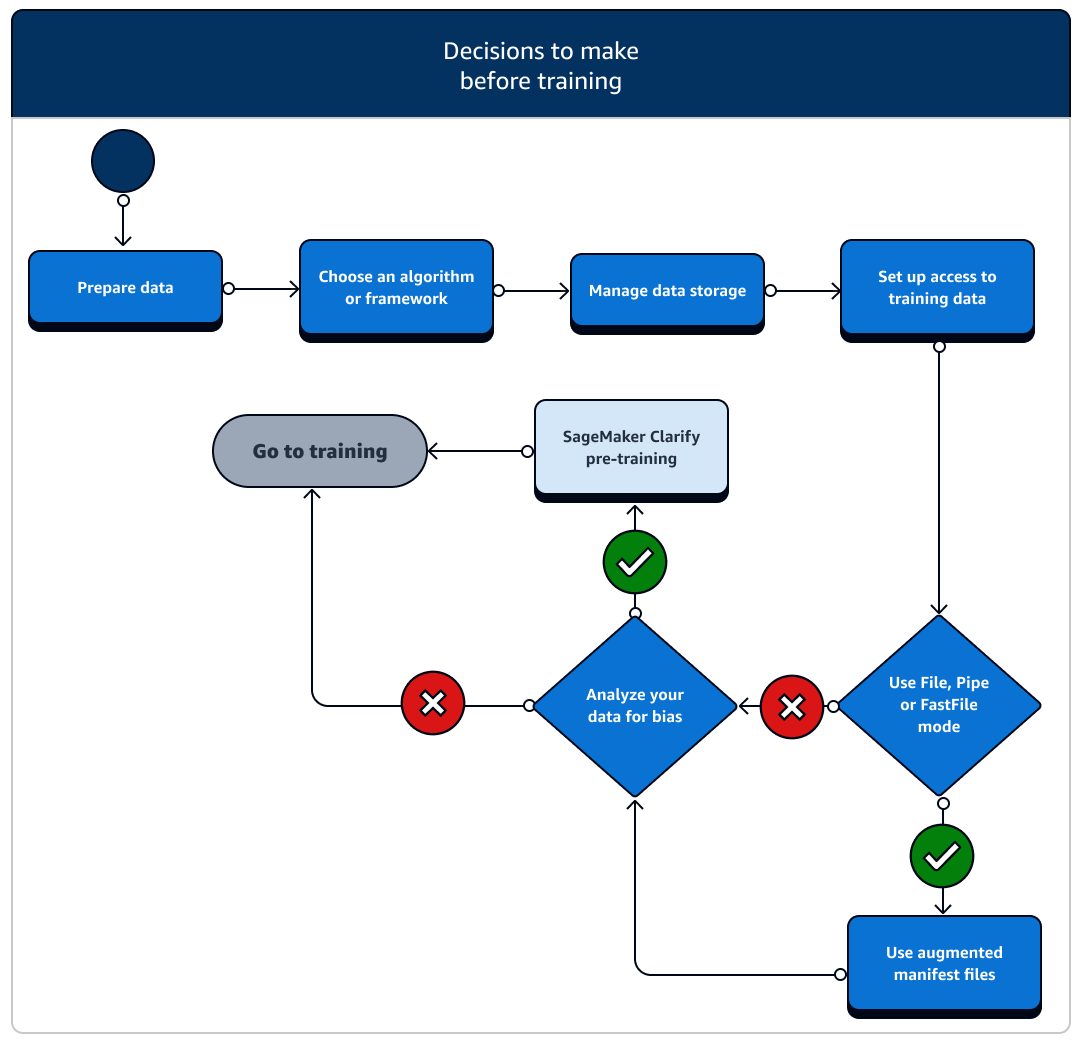
-
データを準備する: トレーニングの前に、データ準備段階でデータクリーニングと特徴量エンジニアリングを完了しておく必要があります。SageMaker AI には、役立つラベル作成ツールと特徴量エンジニアリングツールがいくつか用意されています。詳細については、「データにラベルを付ける」、「データセットを準備して分析する」、「データを処理する」、「特徴を作成、保存、共有する」を参照してください。
-
アルゴリズムまたはフレームワークを選択する: 必要なカスタマイズの程度に応じて、アルゴリズムとフレームワークのオプションは異なります。
-
構築済みアルゴリズムをローコードで実装する場合は、SageMaker AI によって提供される組み込みアルゴリズムのいずれかを使用します。詳細については、「アルゴリズムを選択する」を参照してください。
-
より柔軟にモデルをカスタマイズする場合は、SageMaker AI 内の任意のフレームワークとツールキットを使用してトレーニングスクリプトを実行します。詳細については、「機械学習フレームワークとツールキット」を参照してください。
-
構築済みの SageMaker AI Docker イメージを独自のコンテナのベースイメージとして拡張するには、「Use Pre-built SageMaker AI Docker images」を参照してください。
-
カスタム Docker コンテナを SageMaker AI に取り入れるには、「Adapting your own Docker container to work with SageMaker AI」を参照してください。sagemaker-training-toolkit
をコンテナにインストールする必要があります。
-
-
データストレージを管理する: データストレージ (Amazon S3、Amazon EFS、Amazon FSx など) と Amazon EC2 コンピュートインスタンスで実行されるトレーニングコンテナとの間のマッピングについて理解します。SageMaker AI は、トレーニングコンテナにストレージパスとローカルパスをマッピングするのに役立ちます。手動で指定することもできます。マッピングが完了したら、ファイル、パイプ、FastFile モードうち、どのデータ転送モードを使用するかを検討します。SageMaker AI がストレージパスをマッピングする方法については、「Mapping of training storage paths managed by Amazon SageMaker AI」を参照してください。
-
トレーニングデータへのアクセスを設定する: Amazon SageMaker AI ドメイン、ドメインユーザープロファイル、IAM、Amazon VPC、 AWS KMS を使用して、セキュリティを最も重視する組織の要件を満たします。
-
アカウント管理については、「Amazon SageMaker AI domain」を参照してください。
-
IAM ポリシーとセキュリティに関する詳細なリファレンスについては、「Security in Amazon SageMaker AI」を参照してください。
-
-
入力データをストリーミングする: SageMaker AI には、ファイル、パイプ、FastFile の 3 つのデータ入力モードがあります。デフォルトの入力モードはファイルモードで、トレーニングジョブの初期化中にデータセット全体が読み込まれます。データストレージからトレーニングコンテナにデータをストリーミングする一般的なベストプラクティスについては、「トレーニングデータにアクセスする」を参照してください。
パイプモードの場合は、拡張マニフェストファイルを使用して Amazon Simple Storage Service (Amazon S3) から直接データをストリーミングし、モデルをトレーニングすることもできます。パイプモードを使用すると、Amazon Elastic Block Store では最終的なモデルアーティファクトのみが保存され、トレーニングデータセット全体を保存する必要はないため、ディスク容量を削減できます。詳細については、「拡張マニフェストファイルを使用してトレーニングジョブにデータセットメタデータを提供する」を参照してください。
-
データのバイアスを分析する: トレーニングの前に、不利なグループに対するデータセットとモデルのバイアスを分析できます。これにより、SageMaker Clarify を使用してモデルが偏りのないデータセットを学習していることを確認できます。
-
使用する SageMaker SDK を選択する: SageMaker AI でトレーニングジョブを起動するには、高レベル SageMaker AI Python SDK を使用する方法と、SDK for Python (Boto3) または AWS CLI用の低レベル SageMaker API を使用する方法の 2 つの方法があります。SageMaker Python SDK では、低レベル SageMaker API を抽象化して便利なツールを提供します。SageMaker トレーニングの基本アーキテクチャ で前述のように、SageMaker Canvas、SageMaker Studio Classic 内の SageMaker JumpStart、または SageMaker AI Autopilot を使用して、ノーコードオプションまたは最小限のコードオプションを検討することもできます。
トレーニング中
トレーニング中は、コンピューティングリソース、コストの最適化、そして最も重要なモデルのパフォーマンスをスケーリングしながら、トレーニングの安定性、トレーニング速度、トレーニング効率を継続的に改善する必要があります。トレーニング中の各段階と関連する SageMaker トレーニングの機能の詳細については、以下を参照してください。
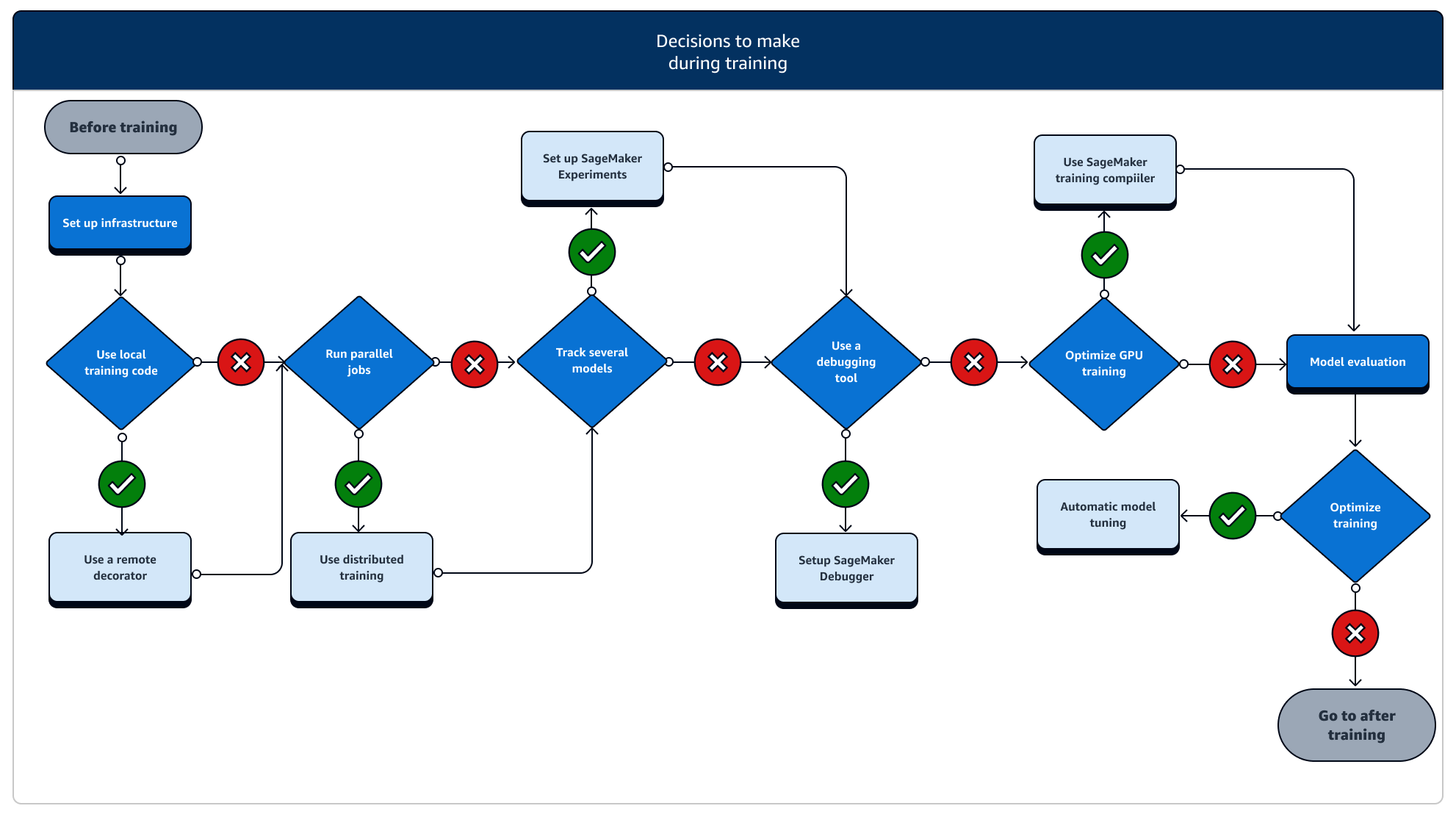
-
インフラストラクチャの設定: ユースケースに適したインスタンスタイプとインフラストラクチャ管理ツールを選択します。小規模なインスタンスから始めて、ワークロードに応じてスケールアップできます。表形式のデータセットでモデルをトレーニングする場合は、C4 または C5 インスタンスファミリーで最小の CPU インスタンスから開始します。コンピュータビジョンまたは自然言語処理のために大規模なモデルをトレーニングする場合は、P2、P3、G4dn、または G5 インスタンスファミリーでの最小の GPU インスタンスから開始します。また、SageMaker AI によって提供される以下のインスタンス管理ツールを使用して、1 つのクラスターにさまざまなインスタンスタイプを混在させたり、インスタンスをウォームプールに保持したりすることもできます。さらに、永続キャッシュを使用すると、ウォームプールのみによるレイテンシーの削減よりも、反復的なトレーニングジョブのレイテンシーと課金対象時間を削減できます。詳細については、以下のトピックを参照してください。
トレーニングジョブを実行するには十分なクォータが必要です。クォータが不足しているインスタンスでトレーニングジョブを実行すると、
ResourceLimitExceededエラーが表示されます。アカウントで現在利用可能なクォータを確認するには、Service Quotas コンソールを使用します。クォータの増加を要求する方法については、「サポートされているリージョンおよびクォータ」を参照してください。また、 に応じて料金情報と使用可能なインスタンスタイプを確認するには AWS リージョン、Amazon SageMaker の料金 ページでテーブルを検索します。 -
ローカルコードからトレーニングジョブを実行する: リモートデコレータでローカルコードに注釈を付けると、Amazon SageMaker Studio Classic 内、Amazon SageMaker ノートブック、またはローカルの統合開発環境から SageMaker トレーニングジョブとしてコードを実行できます。詳細については、「ローカルコードを SageMaker トレーニングジョブとして実行する」を参照してください。
-
トレーニングジョブを追跡する: SageMaker Experiments、SageMaker Debugger、または Amazon CloudWatch を使用してトレーニングジョブを監視および追跡します。SageMaker AI Experiments を使用すると、モデルのパフォーマンスを精度と収束の観点から確認し、複数のトレーニングジョブ間のメトリクスの比較分析を実行できます。SageMaker Debugger のプロファイリングツールまたは Amazon CloudWatch を使用すると、コンピュートリソースの使用率を確認できます。詳細については、以下のトピックを参照してください。
さらに、深層学習タスクでは、Amazon SageMaker Debugger モデルデバッグツールと組み込みルールを使用して、モデルの収束とウェイト更新プロセスにおけるより複雑な問題を特定します。
-
分散型トレーニング: トレーニングインフラストラクチャの設定ミスやメモリ不足の問題によってトレーニングジョブが中断されることなく安定した段階に移行している場合、ジョブをスケーリングして、数日、場合によっては数か月に及ぶ長期間にわたって実行するためのオプションが必要になる場合があります。スケールアップできる場合、分散型トレーニングを検討します。SageMaker AI には、軽い機械学習ワークロードから重い深層学習ワークロードまで、分散計算のためのさまざまなオプションが用意されています。
非常に大規模なデータセットで非常に大規模なモデルをトレーニングする深層学習タスクでは、SageMaker AI 分散トレーニング戦略のいずれかを利用してスケールアップし、データ並列処理、モデル並列処理、またはこの 2 つ組み合わせた処理を実行することを検討します。GPU インスタンスのモデルグラフをコンパイルおよび最適化するには、SageMaker Training Compiler を使用することもできます。これらの SageMaker AI 機能は、PyTorch、TensorFlow、Hugging Face Transformer などの深層学習フレームワークをサポートしています。
-
モデルのハイパーパラメータ調整: SageMaker AI の自動モデルチューニングを使用してモデルのハイパーパラメータを調整します。SageMaker AI は、グリッド検索やベイズ検索などのハイパーパラメータチューニング方法を備えており、ハイパーパラメータチューニングジョブが改善されていない場合でも、早期停止機能を使用して並列ハイパーパラメータチューニングジョブを起動できます。
-
スポットインスタンスによるチェックポイントとコスト削減: トレーニング時間がそれほど大きな懸念事項でない場合は、マネージドスポットインスタンスによるモデルトレーニングコストの最適化を検討します。スポットインスタンスの交換による断続的なジョブの休止からの復元を継続するには、スポットトレーニングのチェックポイントを有効にする必要があることに注意してください。また、トレーニングジョブが予期せず終了した場合に備えて、チェックポイント機能を使用してモデルをバックアップすることもできます。詳細については、以下のトピックを参照してください。
トレーニング後
トレーニング後は、最終的なモデルアーティファクトを取得して、モデルのデプロイと推論に使用します。次の図に示すように、トレーニング後のフェーズに関連する追加のアクションがあります。
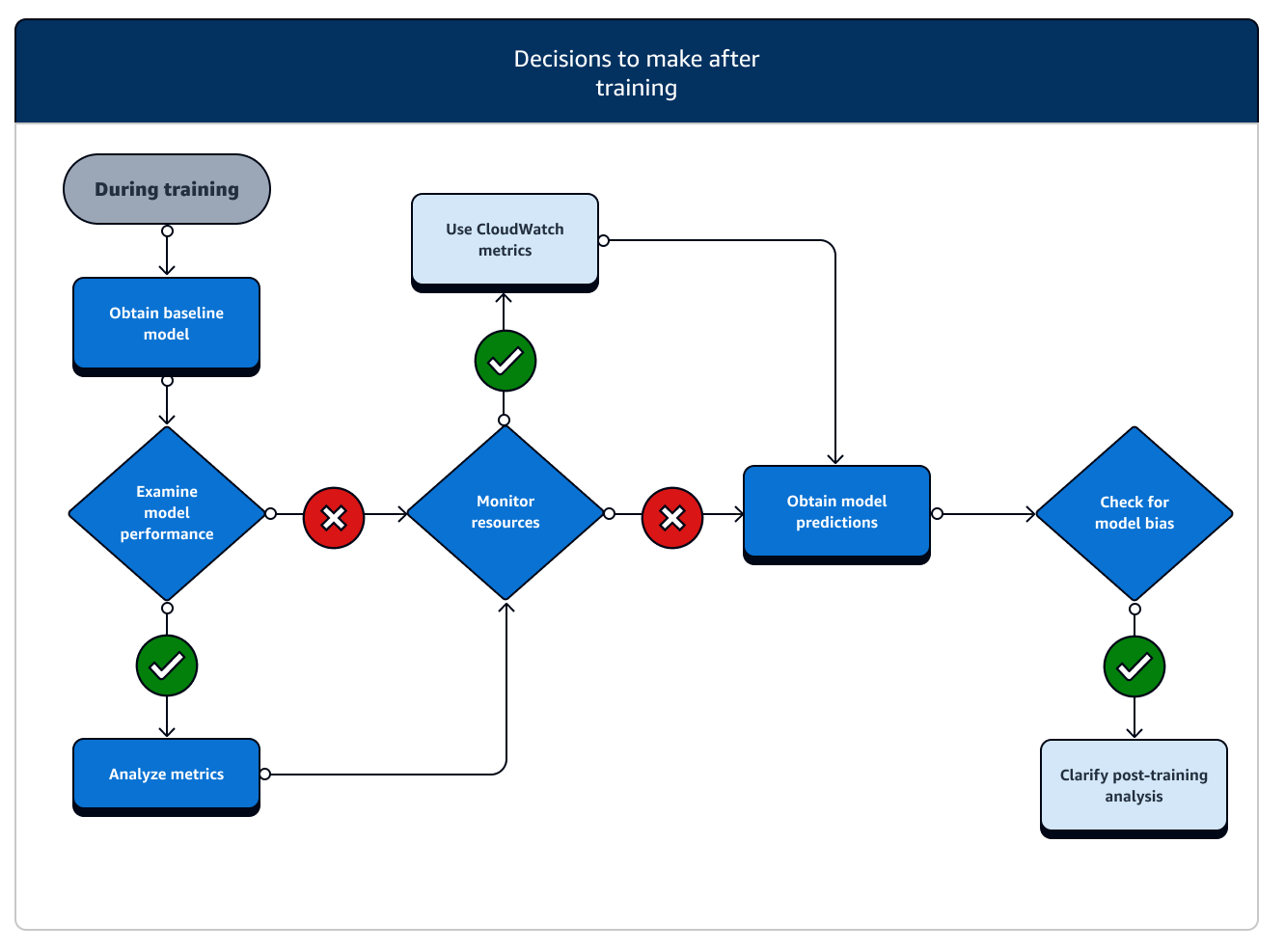
-
ベースラインモデルを取得する: モデルアーティファクトを取得したら、それをベースラインモデルとして設定できます。モデルの実稼働環境へのデプロイに進む前に、以下のトレーニング後のアクションと SageMaker AI 機能の使用を検討します。
-
モデルのパフォーマンスを調べ、バイアスを確認する: トレーニング後のバイアスに Amazon CloudWatch Metrics と SageMaker Clarify を使用して、ベースラインに対する受信データとモデルのバイアスを経時的に検出します。新しいデータを評価し、定期的またはリアルタイムで新しいデータに対してモデル予測を評価する必要があります。これらの機能を使用すると、データやモデルの急激な変化や異常のほか、漸進的な変化またはドリフトに関するアラートを受け取ることができます。
-
SageMaker AI の段階的トレーニング機能を使用し、モデルをロードして拡張データセットで更新 (またはファインチューニング) することもできます。
-
モデルトレーニングを SageMaker AI パイプライン のステップとして登録するか、SageMaker AI によって提供される他のワークフロー機能の一部として登録して、機械学習ライフサイクル全体を調整することもできます。
