翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルをトレーニングします
このステップでは、トレーニングアルゴリズムを選択し、モデルのトレーニングジョブを実行します。Amazon SageMaker Python SDK
トレーニングアルゴリズムを選択する
通常、データセットに適切なアルゴリズムを選択するには、さまざまなモデルを評価して、データに最適なモデルを見つける必要があります。簡単に作業できるように、このチュートリアルでは、モデルの事前評価を行わずに SageMaker AI Amazon SageMaker AI の XGBoost アルゴリズム 組み込みアルゴリズムを使用します。
ヒント
使用する表形式データセットに適したモデルを SageMaker AI で探す場合は、機械学習ソリューションを自動化する Amazon SageMaker Autopilot を使用します。詳細については、「SageMaker Autopilot」を参照してください。
トレーニングジョブを作成して実行する
使用するモデルが見つかったら、トレーニング用の SageMaker AI 推定ツールを構築します。このチュートリアルでは、SageMaker 汎用推定ツールに XGBoost 組み込みアルゴリズムを使用します。
モデルトレーニングジョブを実行するには
-
Amazon SageMaker Python SDK
をインポートし、現在の SageMaker AI セッションから基本情報を取得して開始します。 import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))次のような情報が返されます。
-
region– SageMaker AI ノートブックインスタンスが実行されている現在の AWS リージョン。 -
role- ノートブックインスタンスで使用されている IAM ロール。
注記
sagemaker.__version__を実行して SageMaker Python SDK のバージョンを確認します。このチュートリアルはsagemaker>=2.20に基づいています。SDK が古い場合は、以下のコマンドを実行して最新バージョンをインストールします。! pip install -qU sagemakerこのインストールを既存の SageMaker Studio またはノートブックインスタンスで実行する場合は、カーネルを手動で更新して、バージョン更新の適用を完了させる必要があります。
-
-
sagemaker.estimator.Estimatorクラスを使用して XGBoost 推定器を作成します。次のサンプルコードでは、XGBoost 推定器の名前がxgb_modelになっています。from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )SageMaker AI 推定ツールを作成するには、次のパラメータを指定します。
-
image_uri- トレーニングコンテナイメージ URI を指定します。この例では、sagemaker.image_uris.retrieveを使用して SageMaker AI XGBoost トレーニングコンテナ URI を指定しています。 -
role– SageMaker AI がユーザーに代わってタスクを実行するために使用する AWS Identity and Access Management (IAM) ロール (トレーニング結果の読み取り、Amazon S3 からのモデルアーティファクトの呼び出し、Amazon S3 へのトレーニング結果の書き込みなど)。 -
instance_countとinstance_type- モデルのトレーニングに使用される Amazon EC2 機械学習コンピューティングインスタンスのタイプと数。このトレーニング演習では、単一のml.m4.xlargeインスタンスを使用します。このインスタンスは、4 つの CPU、16 GB のメモリ、Amazon Elastic Block Store (Amazon EBS) ストレージ、高いネットワークパフォーマンスを備えています。EC2 コンピューティングインスタンスのタイプの詳細については、「Amazon EC2 インスタンスタイプ」を参照してください。請求の詳細については、「Amazon SageMaker の料金 」を参照してください。 -
volume_size-トレーニングインスタンスにアタッチする EBS ストレージボリュームのサイズ (GB)。Fileモードを使用する場合は、トレーニングデータを保存するのに十分な大きさである必要があります (Fileモードはデフォルトで有効です)。このパラメータを指定しない場合は、値はデフォルトで 30 になります。 -
output_path- SageMaker がモデルアーティファクトとトレーニングの結果を保存する S3 バケットのパス -
sagemaker_session– トレーニングジョブが使用する SageMaker API オペレーションやその他の AWS サービスとのインタラクションを管理するセッションオブジェクト。 -
rules- SageMaker デバッガー組み込みルールのリストを指定します。この例では、create_xgboost_report()ルールはトレーニングの進行状況と結果に関するインサイトを提供する XGBoost レポートを作成し、ProfilerReport()ルールは EC2 コンピューティングリソースの使用状況に関するレポートを作成します。詳細については、「XGBoost の SageMaker Debugger インタラクティブレポート」を参照してください。
ヒント
畳み込みニューラルネットワーク (CNN) や自然言語処理 (NLP) モデルなどの大規模な深層学習モデルの分散トレーニングを実行する場合は、データ並列処理またはモデル並列処理に SageMaker AI Distributed を使用します。詳細については、「Amazon SageMaker AI による分散トレーニング」を参照してください。
-
-
推定器の
set_hyperparametersメソッドを呼び出して、XGBoost アルゴリズムのハイパーパラメータ値を設定します。XGBoost ハイパーパラメータの詳細なリストについては、「XGBoost のハイパーパラメータ」を参照してください。xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )ヒント
SageMaker AI ハイパーパラメータ最適化機能を使用してハイパーパラメータをチューニングすることもできます。詳細については、「SageMaker AI の自動モデルチューニング」を参照してください。
-
TrainingInputクラスを使用して、トレーニング用のデータ入力フローを設定します。次のサンプルコードは、「データセットをトレーニング、検証、テストデータセットに分割する」セクションで Amazon S3 にアップロードしたトレーニングデータセットと検証データセットを使用するためのTrainingInputオブジェクトの設定方法を示しています。from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
モデルトレーニングを開始するには、推定器の
fitメソッドをトレーニングデータセットと検証データセットで呼び出します。wait=Trueを設定すると、fitメソッドは、進捗状況ログを表示し、トレーニングが完了するまで待機状態になります。xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)モデルトレーニングの詳細については、「Amazon SageMaker でモデルをトレーニングする」を参照してください。このチュートリアルのトレーニングジョブには、最大で 10 分かかる場合があります。
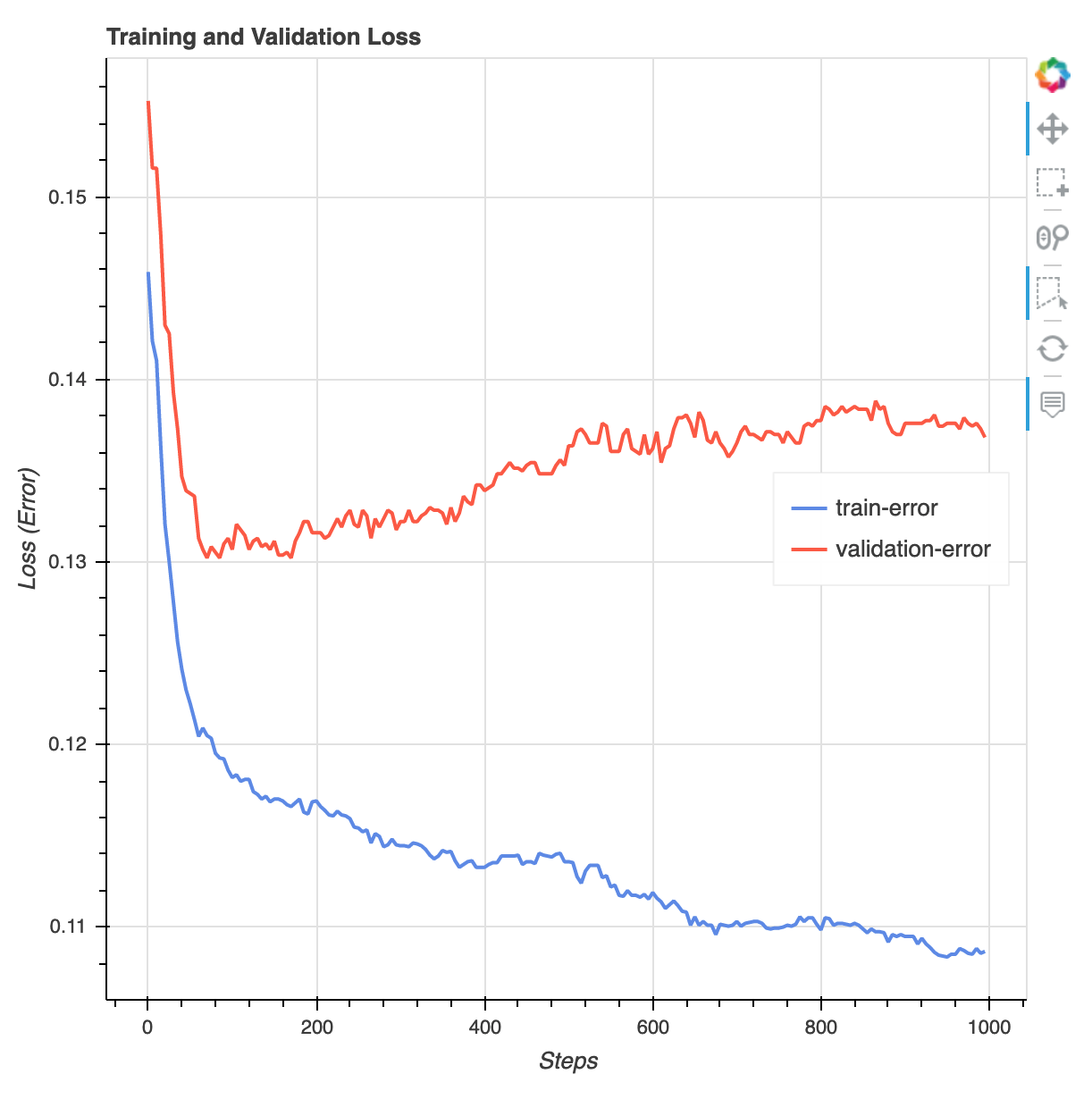
トレーニングジョブが終わったら、XGBoost トレーニングレポートと SageMaker デバッガーによって生成されたプロファイリングレポートをダウンロードできます。XGBoost トレーニングレポートでは、イテレーションに対する損失関数、特徴量の重要度、混同行列、精度曲線、トレーニングのその他の統計結果など、トレーニングの進行状況と結果に関するインサイトが提供されます。例えば、XGBoost トレーニングレポートで次のような損失曲線が見つかる場合があります。これは、オーバーフィットの問題があることを明確に示しています。
次のコードを実行すると、Debugger トレーニングレポートが生成される S3 バケット URI を指定し、レポートが存在するかどうかを確認します。
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursiveDebugger XGBoost トレーニングレポートとプロファイリングレポートを現在のワークスペースにダウンロードします。
! aws s3 cp {rule_output_path} ./ --recursive次の IPython スクリプトを実行すると、XGBoost トレーニングレポートのファイルリンクを取得します。
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))次の IPython スクリプトは、EC2 インスタンスのリソース使用率、システムボトルネックの検出結果、Python オペレーションプロファイリング結果の概要と詳細を示す Debugger プロファイリングレポートのファイルリンクを返します。
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))ヒント
HTML レポートの JupyterLab ビューにプロットがレンダリングされない場合は、レポートの上部にある [HTML を信頼] を選択する必要があります。
オーバーフィット、勾配の消失、モデルの収束を妨げるその他の問題など、トレーニングの問題を特定するには、SageMaker Debugger を使用して機械学習モデルのプロトタイプ作成やトレーニング中の自動化アクションを取得します。詳細については、「Amazon SageMaker デバッガー」を参照してください。モデルパラメータの詳細な解析を確認するには、「Amazon SageMaker Debugger による説明可能性
」サンプルノートブックを参照してください。
これで、XGBoost モデルをトレーニングしました。SageMaker AI は、モデルアーティファクトを S3 バケットに保存します。モデルアーティファクトの場所を確認するには、次のコードを実行して xgb_model 推定器の model_data 属性を出力します。
xgb_model.model_data
ヒント
機械学習ライフサイクル (データ収集、モデルトレーニングとチューニング、予測用にデプロイされた機械学習モデルのモニタリング) の各段階で発生する可能性のあるバイアスを測定するには、SageMaker Clarify を使用します。詳細については、「モデルの説明可能性」を参照してください。エンドツーエンドの例については、「Fairness and Explainability with SageMaker Clarify
