翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データセットを作成する
注記
5 GB を超えるデータセットを Amazon SageMaker Canvas にインポートする場合は、Canvas の Data Wrangler 機能を使用してデータフローを作成することをお勧めします。Data Wrangler は、データの結合や連結などの高度なデータ準備機能をサポートしています。データフローを作成したら、データフローを Canvas データセットとしてエクスポートし、モデルの構築を開始できます。詳細については、「エクスポートしてモデルを作成する」を参照してください。
以下のセクションでは、Amazon SageMaker Canvas でデータセットを作成する方法について説明します。カスタムモデルでは、表形式データと画像データ用のデータセットを作成できます。 Ready-to-use モデルでは、表形式データセットとイメージデータセット、ドキュメントデータセットを使用できます。以下の情報を参照して、ワークフローを選択してください。
-
カテゴリ、数値、テキスト、時系列データについては、「表形式データをインポートする」を参照してください。
-
画像データについては、「画像データをインポートする」を参照してください。
-
ドキュメントデータについては、「」を参照してくださいドキュメントデータをインポートする。
データセットは複数のファイルで構成できます。例えば、インベントリデータのファイルを CSV 形式で複数作成できます。ファイルのスキーマ (または列名とデータ型) が一致している場合、これらのファイルをデータセットとしてまとめてアップロードできます。
Canvas は、データセットの複数のバージョンの管理もサポートしています。データセットを作成すると、最初のバージョンには「V1」というラベルが付けられます。データセットを更新することで、データセットの新しいバージョンを作成できます。手動で更新することも、データセットを新しいデータで自動更新するスケジュールを設定することもできます。詳細については、「データセットを更新する」を参照してください。
データを Canvas にインポートする際は、データが以下の表の要件を満たしていることを確認する必要があります。制限は、作成するモデルのタイプによって異なります。
| 制限 | 2 カテゴリモデル、3+ カテゴリモデル、数値モデル、時系列モデル | テキスト予測モデル | 画像予測モデル | *モデルのドキュメントデータ Ready-to-use |
|---|---|---|---|---|
[サポートされているファイルの種類] |
CSV および Parquet (ローカルアップロード、Amazon S3、またはデータベース) JSON (データベース) |
CSV および Parquet (ローカルアップロード、Amazon S3、またはデータベース) JSON (データベース) |
JPG, PNG |
PDF, JPG, PNG, TIFF |
最大ファイルサイズ |
ローカルアップロード: 5 GB データソース: PBs |
ローカルアップロード: 5 GB データソース: PBs |
1 画像あたり 30 MB |
1 ドキュメントあたり 5 MB |
一度にアップロードできるファイルの最大数 |
30 |
30 |
該当なし |
該当なし |
列の最大数 |
1,000 |
1,000 |
該当なし |
該当なし |
クイックビルドの最大エントリ数 (行、画像、またはドキュメント) |
該当なし |
7500 行 |
5000 イメージ |
該当なし |
標準ビルドの最大エントリ数 (行、画像、またはドキュメント) |
該当なし |
150,000 行 |
180,000 イメージ |
該当なし |
クイックビルドの最小エントリ数 (行) |
2 つのカテゴリ: 500 行 3+ カテゴリ、数値、時系列: 該当なし |
該当なし |
該当なし |
該当なし |
標準ビルドの最小エントリ数 (行、画像、またはドキュメント) |
250 行 |
50 行 |
50 イメージ |
該当なし |
|
1 ラベルあたりの最小エントリ数 (行または画像) |
該当なし |
25 行 |
25 行 |
該当なし |
ラベルの最小数 |
2 カテゴリ: 2 3+ カテゴリ: 3 数値、時系列: 該当なし |
2 |
2 |
該当なし |
|
ランダムサンプリングの最小サンプルサイズ |
500 |
該当なし |
該当なし |
該当なし |
|
ランダムサンプリングの最大サンプルサイズ |
200,000 件の |
該当なし |
該当なし |
該当なし |
| ラベルの最大数 |
2 カテゴリ: 2 3+ カテゴリ、数値、時系列: 該当なし |
1,000 |
1,000 |
該当なし |
*現在、ドキュメントデータは、ドキュメントデータを受け入れるReady-to-use モデルでのみサポートされています。ドキュメントデータを使用してカスタムモデルを構築することはできません。
以下の制限があることにも注意してください。
-
Amazon S3 バケットからデータをインポートする場合は、Amazon S3 バケット名に が含まれていないことを確認してください
.。バケット名に が含まれている場合.、Canvas にデータをインポートしようとするとエラーが発生する可能性があります。 -
表形式のデータの場合、Canvas では、ローカルアップロードと Amazon S3 インポートの両方で、.csv、.parquet、.parq、.pqt 以外の拡張子を持つファイルを選択できません。CSV ファイルは、任意の共通またはカスタム区切り文字を使用できます。また、新しい行を示す場合を除き、改行文字があってはなりません。
-
Parquet ファイルを使用する表形式のデータについては、次の点に注意してください。
Parquet ファイルには、マップやリストのような複雑なタイプを含めることはできません。
Parquet ファイルの列名にはスペースを含めることはできません。
圧縮を使用する場合、Parquet ファイルには gzip または snappy の圧縮タイプを使用する必要があります。こられの圧縮タイプの詳細については、gzip ドキュメント
および snappy ドキュメント を参照してください。
-
ラベルの付いていない画像データには、モデルを構築する前にラベルを付ける必要があります。Canvas アプリケーション内で画像にラベルを割り当てる方法については、「画像データセットを編集する」を参照してください。
-
データセットの自動更新または自動バッチ予測設定を行う場合、Canvas アプリケーションで作成できる設定の合計は最大 20 個です。詳細については、「オートメーションを管理する方法」を参照してください。
データセットをインポートした後は、[データセット] ページでいつでもデータセットを確認できます。
表形式データをインポートする
表形式のデータセットを使用すると、カテゴリ、数値、時系列予測、テキスト予測の各モデルを構築できます。前のデータセットのインポートセクションの制限表を確認して、データが表形式データの要件を満たしていることを確認します。
表敬式のデータセットを Canvas にインポートするには、次の手順に従います。
-
SageMaker Canvas アプリケーションを開きます。
-
左のナビゲーションペインの [Dataset] (データセット) を選択します。
-
[データをインポート] を選択します。
-
ドロップダウンメニューから、表形式 を選択します。
-
ポップアップダイアログボックスの [データセット名] フィールドに、データセットの名前を入力して、[作成] を選択します。
-
表形式のデータセットの作成ページで、データソースドロップダウンメニューを開きます。
-
データソースを選択します。
-
コンピュータからファイルをアップロードするには、[ローカルアップロード] を選択します。
-
Amazon S3 バケットや Snowflake データベースなど、他のソースからデータをインポートするには、[検索データソースバー] でデータソースを検索します。その後、インポートするデータソースのタイルを選択します。
注記
データは接続が有効になっているタイルからのみインポートできます。利用できないデータソースに接続する場合は、管理者に連絡してください。管理者の方は、「データソースに接続する」を参照してください。
次のスクリーンショットは、[データソース] ドロップダウンメニューを示しています。
![[データソース] ドロップダウンメニュー、および検索バーでのデータソース検索のスクリーンショット。](images/studio/canvas/import-data-choose-source.png)
-
-
(オプション) Amazon Redshift または Snowflake データベースに初めて接続する場合、接続を作成するためのダイアログボックスが表示されます。ダイアログボックスに認証情報を入力し、[接続の作成] を選択します。既に接続がある場合は、接続を選択します。
-
データソースでインポートするファイルを選択します。ローカルアップロードと Amazon S3 からのインポートでは、ファイルを選択できます。Amazon S3 のみの場合、Input S3 エンドポイントフィールドにバケットまたは S3 アクセスポイントARNの S3 URI、エイリアス、または を直接入力し、インポートするファイルを選択するオプションもあります。 S3 データベースソースの場合、左側のナビゲーションペインからデータテーブルを作成できます drag-and-drop。
-
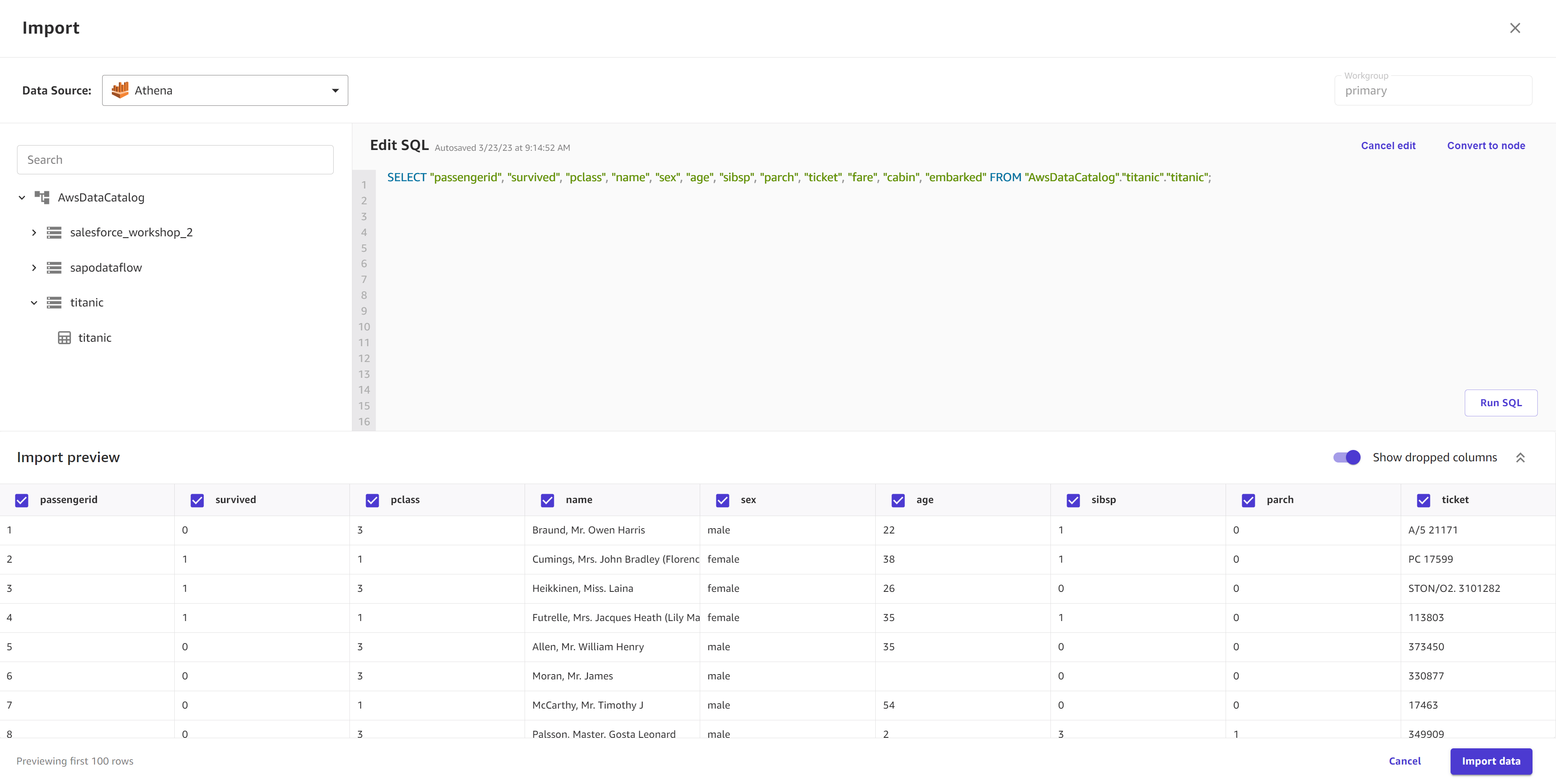
(オプション) SQLクエリをサポートする表形式のデータソース (Amazon Redshift、Amazon Athena、Snowflake など) では、 で編集SQLを選択して、インポートする前にSQLクエリを実行できます。
次のスクリーンショットは、Amazon Athena データソースの編集SQLビューを示しています。
-
データセットのプレビューを選択して、インポートする前にデータをプレビューします。
-
インポート設定 で、データセット名を入力するか、デフォルトのデータセット名を使用します。
-
(オプション) Amazon S3 からインポートするデータには、高度な設定が表示され、次のフィールドに入力できます。
データセットの最初の行を列名として使用する場合は、最初の行をヘッダーとして使用するオプションを に切り替えます。複数のファイルを選択した場合、これは各ファイルに適用されます。
CSV ファイルをインポートする場合は、ファイルエンコーディング (CSV) ドロップダウンでデータセットファイルのエンコーディングを選択します。
UTF-8がデフォルトです。区切り文字ドロップダウンで、データ内の各セルを区切る区切り文字を選択します。デフォルトの区切り文字は です
,。カスタム区切り文字を指定することもできます。Canvas でデータセット全体をマルチラインセル用に手動で解析する場合は、マルチライン検出を選択します。デフォルトでは、このオプションは選択されず、Canvas はデータのサンプルを取得してマルチラインサポートを使用するかどうかを決定します。ただし、Canvas はサンプル内のマルチラインセルを検出しない場合があります。マルチラインセルがある場合は、マルチライン検出オプションを選択して、Canvas がデータセット全体にマルチラインセルがないかチェックするように強制することをお勧めします。
データをインポートする準備ができたら、データセットの作成 を選択します。
データセットを Canvas にインポートしている間、[データセット] ページのリストにデータセットが表示されます。このページからは、データセットの詳細を表示する を行えます。
データセットの [ステータス] に Ready と表示されたら、Canvas にデータが正常にインポートされ、モデルの構築を続行できます。
Amazon Redshift データベースや SaaS コネクタなどのデータソースに接続している場合は、その接続に戻ることができます。Amazon Redshift と Snowflake の場合、別のデータセットを作成して [データのインポート] ページに戻り、その接続の [データソース] タイルを選択することで、別の接続を追加できます。ドロップダウンメニューで前の接続を開くか、[接続を追加] を選択します。
注記
SaaS プラットフォームでは、データソースごとに 1 つの接続しか使用できません。
画像データをインポートする
画像データセットを使用すると、画像のラベルを予測する単一ラベルの画像予測カスタムモデルを構築できます。上記の「データセットをインポートする」セクションの制限表を確認して、画像データセットが画像データの要件を満たしていることを確認してください。
注記
画像データセットは、ローカルファイルのアップロードまたは Amazon S3 バケットからのみインポートできます。また画像データセットでは、1 つのラベルにつき少なくとも 25 個の画像が必要です。
画像データセットを Canvas にインポートするには、次の手順に従います。
-
SageMaker Canvas アプリケーションを開きます。
-
左のナビゲーションペインの [Dataset] (データセット) を選択します。
-
[データをインポート] を選択します。
-
ドロップダウンメニューで、[画像] を選択します。
-
ポップアップダイアログボックスの [データセット名] フィールドに、データセットの名前を入力して、[作成] を選択します。
-
[インポート] ページで、[データソース] ドロップダウンメニューを開きます。
-
データソースを選択します。コンピュータからファイルをアップロードするには、[ローカルアップロード] を選択します。Amazon S3 からファイルをインポートするには、[Amazon S3] を選択します。
-
コンピュータまたは Amazon S3 バケットで、アップロードする画像または画像フォルダを選択します。
-
データをインポートする準備ができたら、[データをインポート] を選択します。
データセットを Canvas にインポートしている間、[データセット] ページのリストにデータセットが表示されます。このページからは、データセットの詳細を表示する を行えます。
データセットの [ステータス] に Ready と表示されたら、Canvas にデータが正常にインポートされ、モデルの構築を続行できます。
モデルの構築中は、画像データセットの編集、ラベルの割り当てや再割り当て、画像の追加、データセットからの画像の削除を行うことができます。画像データセットの編集方法の詳細については、「画像データセットを編集する」を参照してください。
ドキュメントデータをインポートする
経費分析、ID Ready-to-useドキュメント分析、ドキュメント分析、ドキュメントクエリのモデルは、ドキュメントデータをサポートします。ドキュメントデータを使用してカスタムモデルを構築することはできません。
ドキュメントデータセットを使用すると、経費分析、アイデンティティドキュメント分析、ドキュメント分析、ドキュメントクエリ Ready-to-useモデルの予測を生成できます。「データセットを作成する」セクションの制限表を確認して、ドキュメントデータセットがドキュメントデータの要件を満たしていることを確認してください。
注記
ドキュメントデータセットは、ローカルファイルのアップロードまたは Amazon S3 バケットからのみインポートできます。
ドキュメントデータセットを Canvas にインポートするには、次の手順に従います。
-
SageMaker Canvas アプリケーションを開きます。
-
左のナビゲーションペインの [Dataset] (データセット) を選択します。
-
[データをインポート] を選択します。
-
ドロップダウンメニューで、[ドキュメント] を選択します。
-
ポップアップダイアログボックスの [データセット名] フィールドに、データセットの名前を入力して、[作成] を選択します。
-
[インポート] ページで、[データソース] ドロップダウンメニューを開きます。
-
データソースを選択します。コンピュータからファイルをアップロードするには、[ローカルアップロード] を選択します。Amazon S3 からファイルをインポートするには、[Amazon S3] を選択します。
-
コンピュータまたは Amazon S3 バケットで、アップロードするドキュメントファイルを選択します。
-
データをインポートする準備ができたら、[データをインポート] を選択します。
データセットを Canvas にインポートしている間、[データセット] ページのリストにデータセットが表示されます。このページからは、データセットの詳細を表示する を行えます。
データセットの [ステータス] が Ready と表示されたら、データが Canvas に正常にインポートされたことを示します。
[データセット] ページでは、データセットを選択してプレビューできます。プレビューでは、データセットの最初の 100 件のドキュメントが表示されます。
データセットの詳細を表示する
各データセットでは、データセット内のすべてのファイル、データセットのバージョン履歴、およびデータセットの自動更新設定を確認できます。[データセット] ページから、データセットを更新する や カスタムモデルの仕組み などのアクションを開始することもできます。
データセットの詳細を表示するには、次の手順に従います。
-
SageMaker Canvas アプリケーションを開きます。
-
左のナビゲーションペインの [Dataset] (データセット) を選択します。
-
データセットリストで、データセットを選択します。
[データ] タブにデータのプレビューが表示されます。[データセットの詳細] を選択すると、データセットに含まれるすべてのファイルが表示されます。ファイルを選択すると、選択したファイルのデータのみがプレビューに表示されます。画像データセットのプレビューでは、データセットの最初の 100 個の画像のみが表示されます。
[バージョン履歴] タブには、データセットのすべてのバージョンのリストが表示されます。データセットを更新するたびに、新しいバージョンが作成されます。データセットの更新の詳細については、「データセットを更新する」を参照してください。次のスクリーンショットは、Canvas アプリケーションの [バージョン履歴] タブを示しています。
![データセットの [バージョン履歴] タブとデータセットのバージョン一覧のスクリーンショット。](images/studio/canvas/canvas-version-history.png)
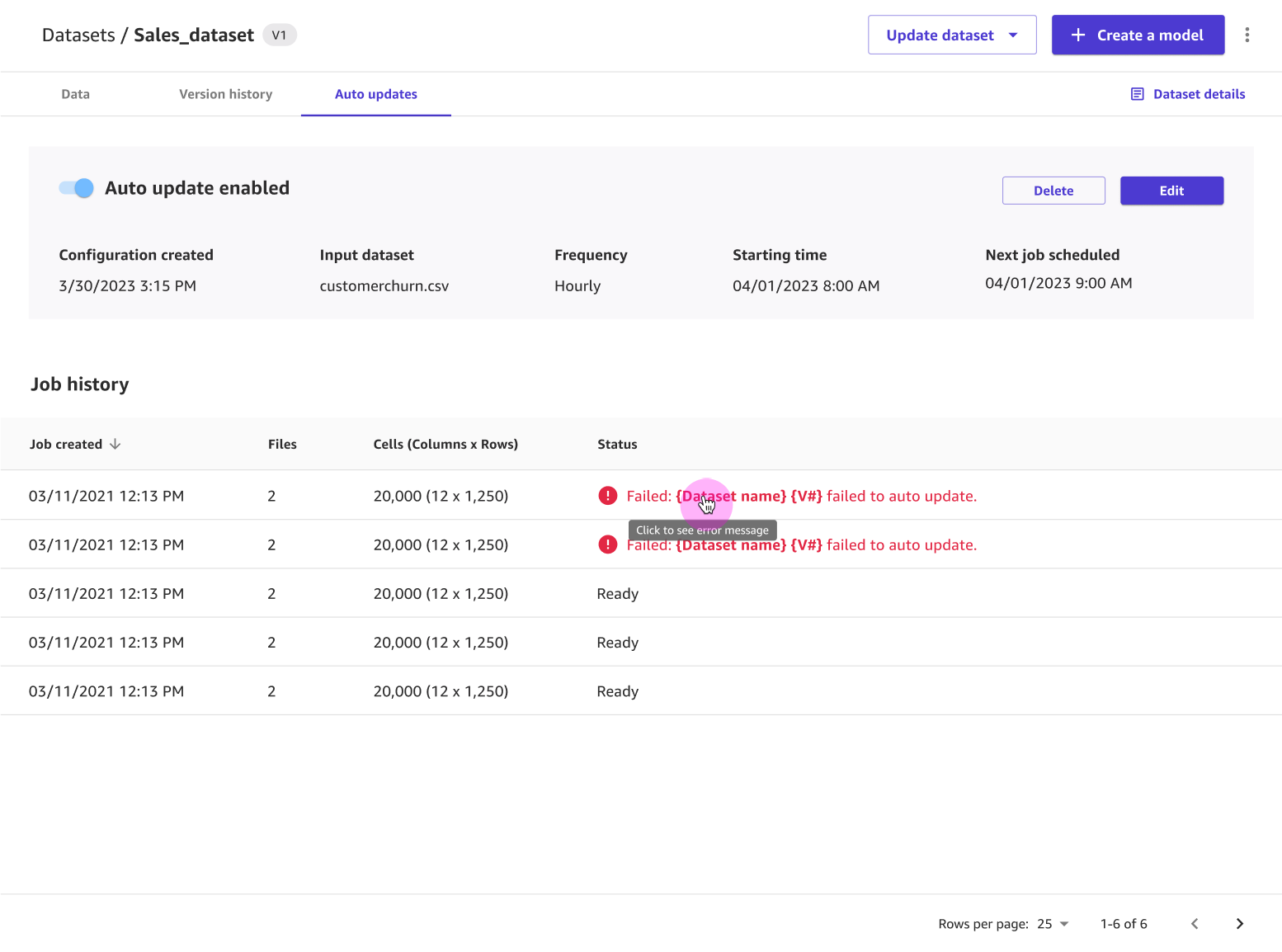
[自動更新] タブでは、データセットの自動更新を有効にして、データセットの定期的な更新を設定できます。データセットの自動更新の詳細については、「データセットの自動更新を設定する」を参照してください。次のスクリーンショットは、自動更新が有効になっている [自動更新] タブと、データセットに対して実行された自動更新ジョブのリストを示しています。