翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
SageMaker AI DeepAR 予測アルゴリズムを使用する
Amazon SageMaker AI DeepAR 予測アルゴリズムは、再帰型ニューラルネットワーク (RNN) を使用してスカラー (1 次元) 時系列を予測するための、教師あり学習アルゴリズムです。自己回帰和分移動平均 (ARIMA) や指数平滑法 (ETS) などの古典的な予測方法は、単一のモデルを各時系列に適合させます。その後、そのモデルを使用して時系列から未来を外挿します。
ただし多くのアプリケーションでは、一連の横断的な単位にわたって同様の時系列が多数あります。たとえば、さまざまな商品に対する需要、サーバーの負荷、およびウェブページのリクエストを時系列でグループ化することができます。このタイプのアプリケーションでは、すべての時系列にわたって単一のモデルを共同でトレーニングすることにより、メリットを享受できます。DeepAR はこのアプローチを使用します。データセットに何百もの関連する時系列データが含まれている場合、DeepAR は標準の ARIMA や ETS メソッドよりも優れています。トレーニングしたモデルを使用して、トレーニングしたモデルと似た新しい時系列の予測を生成することもできます。
DeepAR アルゴリズムのトレーニング入力は、同一または同様のプロセスによって生成された、1 つまたは可能であればそれ以上の時系列 (target) です。この入力データセットに基づき、アルゴリズムではこのプロセスの近似値を学習するモデルをトレーニングし、それを使用してターゲットの時系列がどのように進化するかを予測します。必要に応じて、各ターゲット時系列を cat フィールドで指定された静的 (時系に依存しない) カテゴリ別の特徴のベクトルと、dynamic_feat フィールドで指定された動的 (時系に依存する) の時系列のベクトルと関連付けることができます。SageMaker AI は、トレーニングデータセットの各時系列からいくつかのトレーニング例をランダムにサンプリングすることによって DeepAR モデルをトレーニングします。各トレーニング例は、事前定義された固定長を持つ一対の隣接コンテキストと予測ウィンドウで構成されています。ネットワークがどの程度までの過去を遡れるかを制御するには、context_length ハイパーパラメータを使用します。ネットワークがどの程度までの未来を予測できるかを制御するには、prediction_length ハイパーパラメータを使用します。詳細については、「DeepAR アルゴリズムの仕組み」を参照してください。
トピック
DeepAR アルゴリズムの入出力インターフェイス
DeepAR は、2 つのデータチャネルをサポートしています。必須の train チャネルは、トレーニングデータセットを表します。オプションの test チャネルは、アルゴリズムがトレーニング後にモデルの精度を評価するために使用するデータセットを表します。トレーニングデータセットとテストデータセットは JSON Lines
トレーニングデータとテストデータのパスを指定するときには、単一のファイルまたは複数のファイルを含むディレクトリを指定できます。これらのファイルはサブディレクトリに保存されていても構いません。ディレクトリを指定すると、ピリオド (.) で始まるファイルと _SUCCESS という名前のファイルを除いて、ディレクトリ内のすべてのファイルが対応するチャネルの入力として使用されます。これにより、Spark ジョブによって生成された出力フォルダを DeepAR トレーニングジョブの入力チャネルとして直接使用できるようになります。
DeepAR モデルはデフォルトでは、指定された入力パスのファイル拡張子 (.json、.json.gz、または .parquet) から入力形式を判別します。パスの末尾がこれらの拡張子以外である場合、SDK for Python で形式を明示的に指定する必要があります。s3_inputcontent_type パラメータを使用します。
入力ファイルのレコードには、以下のフィールドが含まれています。
-
start-YYYY-MM-DD HH:MM:SS形式の文字列。開始タイムスタンプにタイムゾーン情報を含めることはできません。 -
target- 時系列を表す浮動小数点値または整数の配列。欠損値は、nullリテラル、JSON の"NaN"文字列、または Parquet のnan浮動小数点値としてエンコードできます。 -
dynamic_feat(オプション) - カスタムの特徴の時系列 (動的特徴) のベクトルを表す、浮動小数点値または整数の配列の配列。このフィールドを設定した場合は、すべてのレコードに同じ数の内部配列 (同じ数の特徴時系列) が含まれている必要があります。さらに、各内部配列は、関連付けられているtarget値とprediction_lengthと同じ長さにする必要があります。欠損値は特徴ではサポートされません。たとえば、ターゲットの時系列がさまざまな製品の需要を表す場合、関連付けられたdynamic_featは、プロモーションが特定の商品に適用されたか (1) または適用されていないか (0) を示すブール時系列になります。{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(オプション) - レコードが属するグループをエンコードするために使用できるカテゴリ別特徴の配列。カテゴリ別特徴は、0 から始まる正の整数のシーケンスとしてエンコードする必要があります。たとえば、カテゴリ別ドメイン {R, G, B} は {0, 1, 2} としてエンコードできます。各カテゴリ別ドメインのすべての値が、トレーニングデータセット内で表されている必要があります。これは、DeepAR アルゴリズムが、トレーニング中に観察されたカテゴリについてしか予測できないためです。さらに、各カテゴリ別特徴は、次元がembedding_dimensionハイパーパラメータによって制御される低次元空間に埋め込まれています。詳細については、「DeepAR ハイパーパラメータ」を参照してください。
JSON ファイルを使用する場合は、ファイルが JSON Lines
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
この例では、各時系列に、関連付けられている 2 つのカテゴリ別特徴と 1 つの時系列特徴があります。
Parquet の場合、同じ 3 つのフィールドを列として使用します。さらに、"start" を datetime 型として使用できます。Parquet ファイルを圧縮するには、gzip (gzip) または Snappy 圧縮ライブラリ (snappy) を使用します。
アルゴリズムが cat フィールドと dynamic_feat フィールドなしでトレーニングされる場合、「グローバル」モデル、つまり推論時のターゲットの時系列の特定のアイデンティティに依存せず、その形状のみによる条件付きのモデルを学習します。
モデルが各時系列で提供された cat および dynamic_feat の特徴データの条件付きである場合、予測は、対応する cat の特徴を持つ時系列の特性の影響を受ける場合があります。たとえば、target の時系列が衣料品の需要を表す場合は、最初のコンポーネントの品目の種類 (0 = 靴、1 = 衣服など) と、2 番目のコンポーネントの品目の色 (例: 0 = 赤、1 = 青) をエンコードする 2 次元の cat ベクトルを関連付けることができます。サンプルの入力は次のようになります。
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
推論時、トレーニングデータで観測された cat の値の組み合わせである、cat の値を持つターゲットの予測をリクエストできます。次に例を示します。
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
トレーニングデータには以下のガイドラインが適用されます。
-
時系列の開始時刻と長さは異なる場合があります。たとえば、マーケティングでは通常、製品がカタログに掲載される日は異なるため、開始日も異なります。ただし、すべてのシリーズにおいて、頻度やカテゴリ別特徴の数、動的特徴の数は同じでなければなりません。
-
トレーニングファイルを、ファイル内の時系列の位置に関してシャッフルします。つまり、時系列はファイル内でランダムな順序で出現します。
-
startフィールドが正しく設定されていることを確認します。アルゴリズムはstartタイムスタンプを使用して内部の特徴を取得します。 -
カテゴリ別特徴 (
cat) を使用する場合は、すべての時系列には同じ数のカテゴリ別特徴が含まれている必要があります。データセットにcatフィールドが含まれている場合、アルゴリズムはそれを使用してデータセットからグループの基数を抽出します。デフォルトでは、cardinalityは"auto"です。データセットにcatフィールドが含まれていても、それを使用しないようにするには、無効にするために、cardinalityを""に設定します。モデルが特徴catを使用してトレーニングされた場合は、推論のためにそれを含める必要があります。 -
データセットに
dynamic_featフィールドが含まれている場合、アルゴリズムはそれを自動的に使用します。すべての時系列に、同じ数の特徴時系列が含まれている必要があります。各特徴時系列の時間ポイントは、ターゲットの時間ポイントと 1 対 1 で対応します。さらに、dynamic_featフィールドのエントリはtargetと同じ長さである必要があります。データセットにdynamic_featフィールドが含まれていても、それを使用しないようにするには、無効にするために、num_dynamic_featを""に設定します。モデルがdynamic_featフィールドを使用してトレーニングされた場合は、推論のためにこのフィールドを提供する必要があります。さらに各特徴は、提供されたターゲットの長さにprediction_lengthを加えた長さである必要があります。つまり、未来の特徴値を提供する必要があります。
オプションのテストチャネルデータを指定した場合、DeepAR アルゴリズムは異なる正確性メトリクスでトレーニング済みモデルを評価します。アルゴリズムは、テストデータの二乗平均平方根誤差 (RMSE) を次のように計算します。
-y(i,t))^2))](images/deepar-1.png)
ここで、yi,t は時間 t における時系列 i の真の値です。ŷi,t は、平均予測です。合計は、テストセット内の n 個の時系列すべてと、各時系列の最後の T 個の時間ポイントの和です。ここで、T は予測期間に対応します。予測期間の長さを指定するには、prediction_length ハイパーパラメータを設定します。詳細については、「DeepAR ハイパーパラメータ」を参照してください。
さらにこのアルゴリズムは、重み付けされた分位損失を使用して予測分布の正確性を評価します。[0, 1] の範囲にある変位値の場合、重み付けされた分位損失は次のように定義されます。
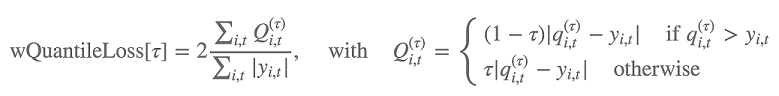
qi,t(τ) は、モデルが予測する分布の τ 分位数です。損失を計算する分位数を指定するには、test_quantiles ハイパーパラメータを設定します。これらに加えて、規定の分位損失の平均がトレーニングログの一部として報告されます。詳細については、「DeepAR ハイパーパラメータ」を参照してください。
推論のために、DeepAR は JSON 形式と以下のフィールドを受け入れます。
-
"instances": JSON Lines 形式の時系列を 1 つ以上含む -
"configuration"の名前: 予測を生成するためのパラメータを含む
詳細については、「DeepAR 推論の形式」を参照してください。
DeepAR アルゴリズム使用のベストプラクティス
時系列データを準備するときには、以下のベストプラクティスに従うと、最善の結果を得ることができます。
-
トレーニングとテストのデータセットを分割する場合を除き、トレーニングとテストのため、および推論のためにモデルを呼び出す際には、常に時系列全体を提供します。
context_lengthの設定方法にかかわらず、時系列を分割したり、その一部だけを指定したりしないでください。モデルは、遅延値の特徴には、context_lengthに設定された値より遡ったデータポイントを使用します。 -
DeepAR モデルを調整するときには、データセットを分割して、トレーニングデータセットとテストデータセットを作成することができます。典型的な評価では、トレーニングに使用したのと同じ時系列でモデルをテストしますが、トレーニング中に表示される最後の時間ポイントの直後に続く未来の
prediction_length時間ポイントでモデルをテストします。この基準を満たすトレーニングデータセットとテストデータセットを作成するには、テストセットとしてデータセット全体 (使用可能なすべての時系列の全長) を使用し、トレーニング用に各時系列から最後のprediction_lengthポイントを削除します。トレーニング中には、モデルはテスト時に評価される時間ポイントのターゲット値を確認しません。テスト中、アルゴリズムはテストセット内の各時系列の最後のprediction_lengthポイントを保留し、予測を生成します。その後、保留した値と予測を比較します。より複雑な評価を作成するには、テストセット内で時系列を複数回繰り返しますが、それぞれ異なる終了ポイントで切り捨てます。このアプローチにより、精度メトリクスは、さまざまな時間ポイントからの複数の予測で平均化されます。詳細については、「DeepAR モデルを調整する」を参照してください。 -
prediction_lengthに非常に大きい値 (>400) を使用しないでください。このような値を設定すると、モデルの速度が遅くなり、精度が低下します。未来の予測をさらに生成するには、より低い頻度でデータを集約することを検討してください。例えば、1minではなく5minを使用します。 -
遅延が使用されるため、モデルは
context_lengthに指定された値より遡って時系列を調べることができます。そのため、このパラメータを大きい値に設定する必要はありません。prediction_lengthに使用した値から開始することをお勧めします。 -
可能な限り多くの時系列について DeepAR モデルをトレーニングすることをお勧めします。単一の時系列でトレーニングされた DeepAR モデルも問題なく機能する可能性はありますが、ARIMA や ETS などの標準的な予測アルゴリズムは、より正確な結果を提供する可能性があります。データセットに関連する時系列データが何百も含まれている場合、DeepAR アルゴリズムは標準の方法より優れた性能を発揮するようになります。DeepAR では現在、すべてのトレーニング時系列にわたって利用可能な観測の総数が 300 以上であることが要求されます。
DeepAR アルゴリズムの EC2 インスタンスの推奨事項
GPU と CPU インスタンスの両方で、単一および複数マシンの両方の設定で DeepAR をトレーニングできます。1 つの CPU インスタンス (ml.c4.2xlarge や ml.c4.4xlarge など) から開始することをお勧めします。必要な場合のみ GPU インスタンスと複数マシンに切り替えます。GPU と複数のマシンを使用すると、大規模モデル (1 レイヤーに多数のセルが含まれ、多数のレイヤーから成る) の場合、および大サイズのミニバッチ (たとえば、512 を上回るサイズ) の場合にのみスループットが向上します。
推論のために DeepAR がサポートするのは、CPU インスタンスのみです。
context_length、prediction_length、num_cells、num_layers、または mini_batch_size に大きな値を指定すると、スモールインスタンスには大きすぎるモデルが作成される可能性があります。この場合は、使用するインスタンスタイプをより大きなものにするか、これらのパラメータの値を小さくします。この問題は、ハイパーパラメータ調整ジョブを実行するときにも頻繁に発生します。その場合は、モデル調整ジョブに十分な大きさのインスタンスタイプを使用し、重要なパラメータの上限値を制限することを検討して、ジョブの失敗を回避してください。
DeepAR サンプルノートブック
SageMaker AI DeepAR アルゴリズムをトレーニングするための時系列データセットを準備する方法、および推論を実行するためにトレーニング済みモデルをデプロイする方法を示すサンプルノートブックについては、「DeepAR demo on electricity dataset
Amazon SageMaker AI DeepAR アルゴリズムの詳細については、次のブログ記事を参照してください。
