翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
分析および視覚化
Amazon SageMaker Data Wrangler には、数回のクリックでビジュアライゼーションとデータ分析を生成できる組み込みの分析が含まれています。独自のコードを使用してカスタム分析を作成することもできます。
データフレームに分析を追加するには、データフローでステップを選択し、[Add analysis] (分析を追加) を選択します。作成した分析にアクセスするには、分析を含むステップを選択し、分析を選択します。
すべての分析はデータセットの 100,000 行を使用して生成されます。
次の分析をデータフレームに追加できます。
-
ヒストグラムや散布図などのデータビジュアライゼーション。
-
エントリ数、最小値と最大値 (数値データの場合)、最も頻度の高いカテゴリ (カテゴリ別データの場合) など、データセットの簡単な要約。
-
各特徴の重要度スコアを生成するために使用できるデータセットの簡単なモデル。
-
1 つ以上の特徴がターゲットの特徴と強い相関性があるかどうかを判断するために使用できるターゲットの漏洩レポート。
-
独自のコードを使用したカスタムビジュアライゼーション。
これらのオプションの詳細については、次のセクションを参照してください。
ヒストグラム
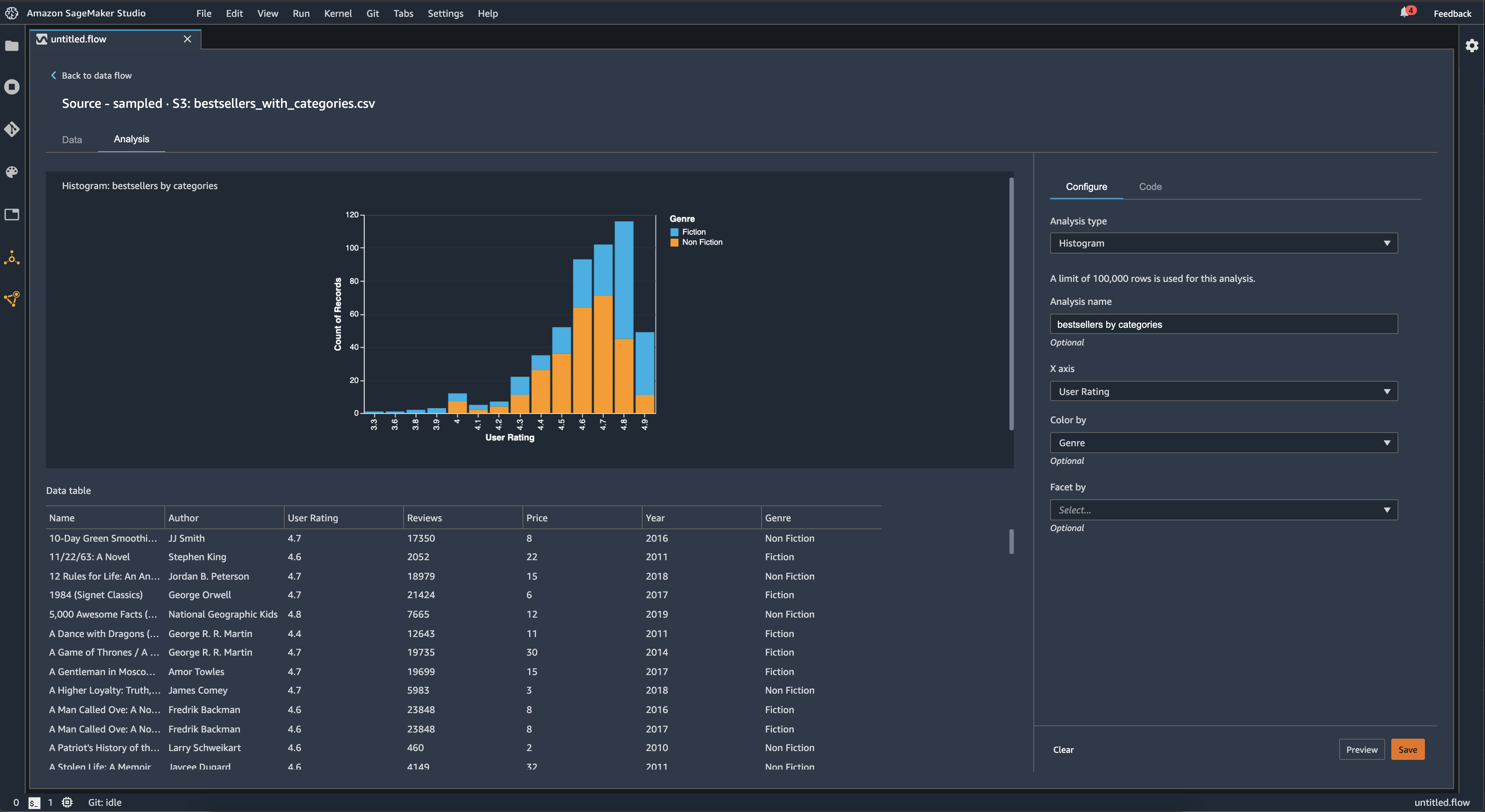
ヒストグラムを使用して、特定の特徴の特徴値の数を確認します。[Color by] (色分け) オプションを使用して特徴間の関係を確認できます。例えば、次のヒストグラムは、2009 年から 2019 年までに Amazon で最も売れた本のユーザー評価のディストリビューションをジャンル別に色分けしてグラフ化したものです。
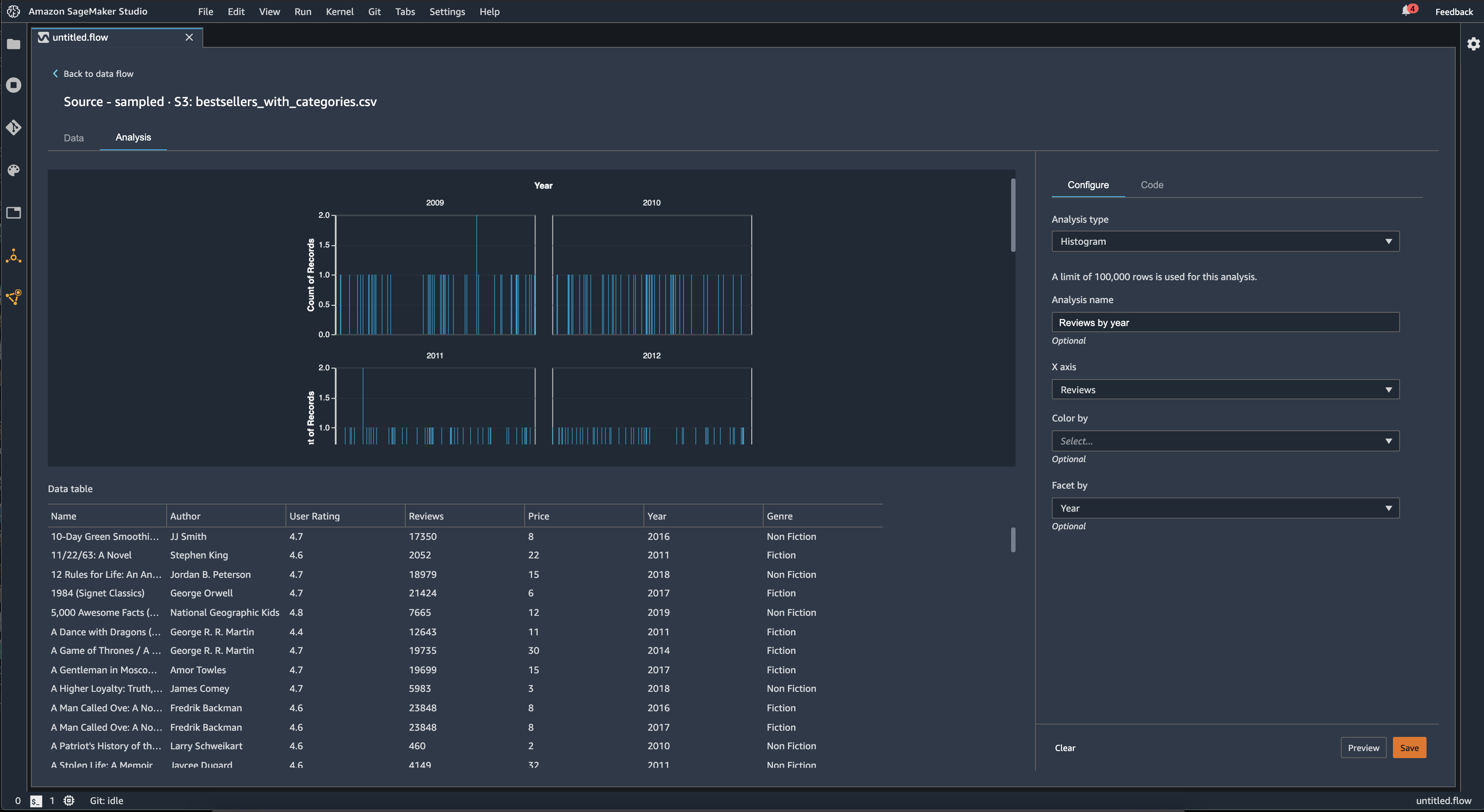
[Facet by] (ファセット別) 機能を使用して別の列の値ごとに、1 列のヒストグラムを作成できます。例えば、次の図は、Amazon で最も売れている本のユーザーレビューのヒストグラムを示しています。
散布図
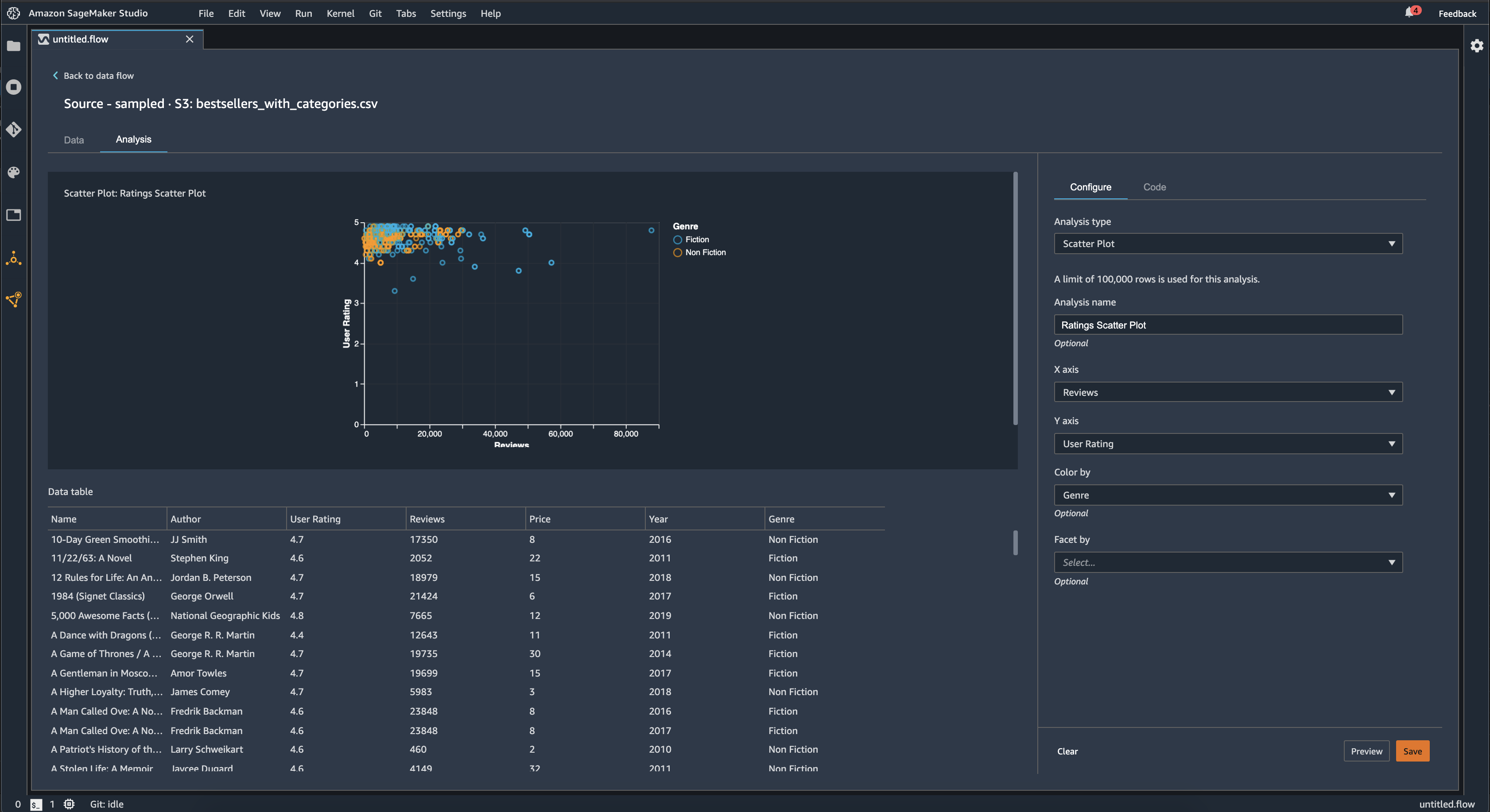
[散布図] 機能を使用して特徴間の関係を確認します。散布図を作成するには、[X 軸] と [Y 軸] でプロットする特徴を選択します。これらの列は両方とも数値型列でなければなりません。
散布図は追加の列で色分けできます。例えば、次の例は、2009 年から 2019 年まで Amazon で最も売れた本のユーザー評価に対するレビュー数を比較した散布図を示しています。散布図は本のジャンル別に色付けされています。
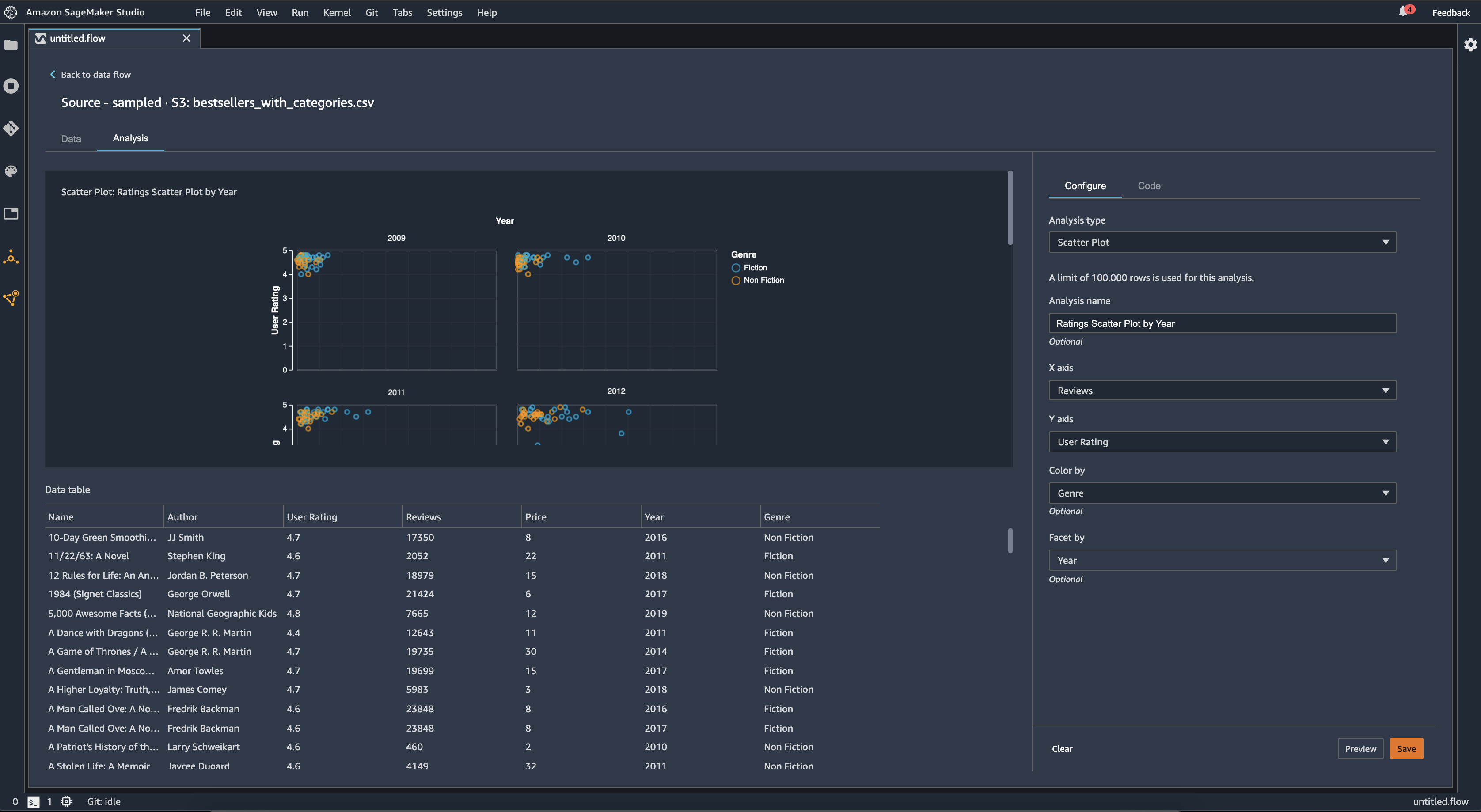
さらに、特徴別に散布図をファセット化することもできます。例えば、以下の画像は、同じレビューとユーザー評価の散布図を、年別にファセット化した例を示しています。
テーブルの概要
[テーブルの概要] 分析を使用してデータをすばやく要約します。
ログデータや浮動小数点データなどの数値データを含む列の場合、テーブルの概要は各列のエントリ数 (count)、最小値 (min)、最大 (max)、平均値、標準偏差 (stddev) を報告します。
文字列、ブール値、日付/時刻データなどの数値以外のデータを含む列の場合、テーブルの概要はエントリ数 (count)、最小頻度値 (min)、最大頻度値 (max) をレポートします。
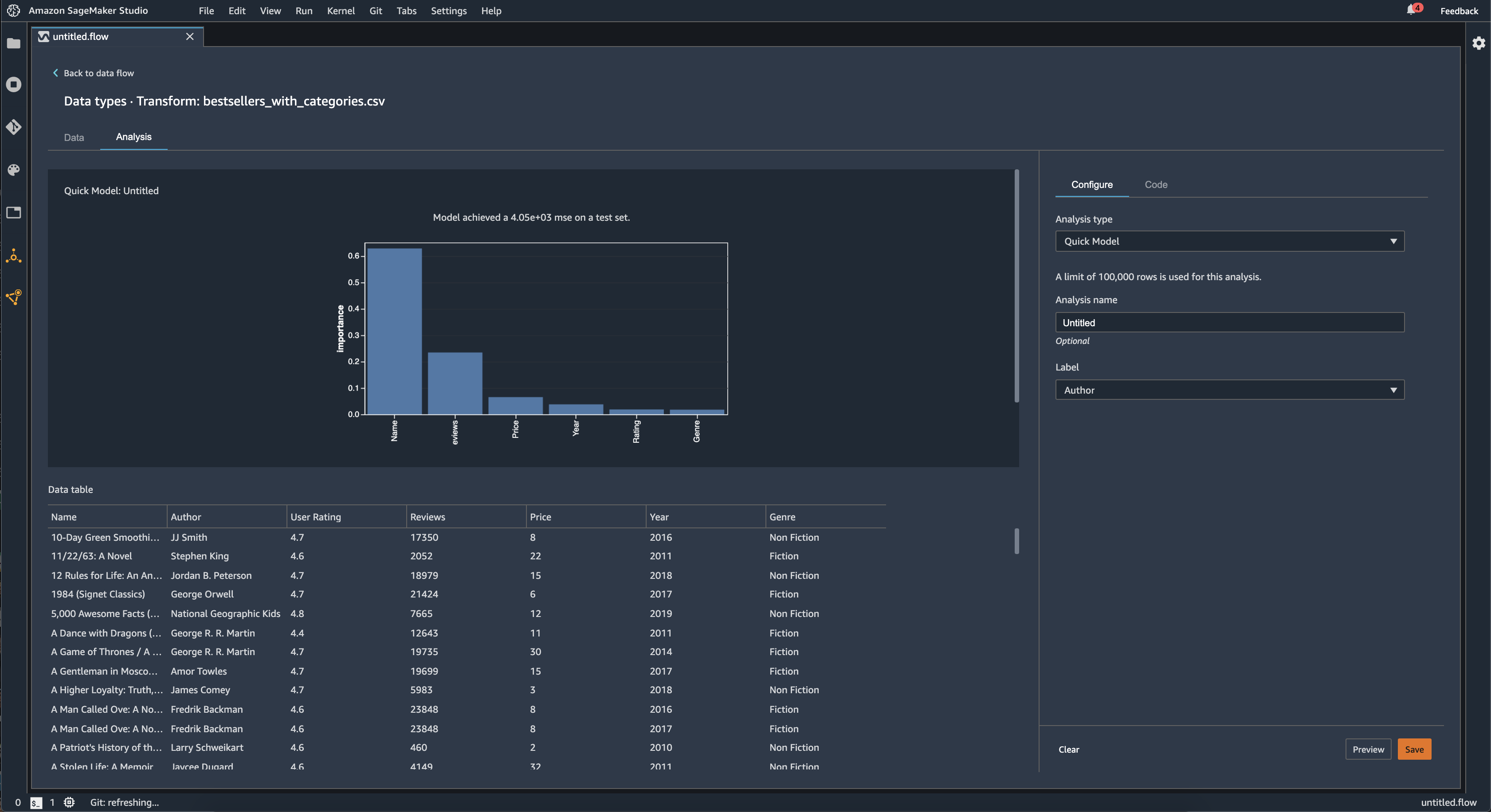
クイックモデル
[クイックモデル] ビジュアライゼーションを使用して、データをすばやく評価し、各特徴の重要度スコアを生成します。特徴の重要度スコア
クイックモデルチャートを作成する場合は、評価するデータセットと、特徴の重要度を比較するターゲットラベルを選択します。Data Wrangler は次を行います。
-
選択したデータセット内のターゲットラベルと各特徴に対するデータ型を推論します。
-
問題のタイプを決定します。Data Wrangler は、ラベル列内の個別の値の数に基づいて、その問題のタイプが回帰または分類のどちらであるかを判断します。Data Wrangler は、カテゴリ別しきい値を 100 に設定します。ラベル列に 100 を超える個別の値がある場合、Data Wrangler はそれを回帰問題として分類します。それ以外の場合、分類問題として分類されます。
-
トレーニング用に特徴とラベルデータを前処理します。使用されるアルゴリズムでは、ベクトルタイプに対するエンコーディング機能と double 型に対するエンコーディングラベルが必要です。
-
70% のデータでランダムフォレストアルゴリズムをトレーニングします。Spark の RandomForestRegressor
は回帰問題のモデルのトレーニングに使用されます。RandomForestClassifier は、分類問題のモデルのトレーニングに使用されます。 -
残りの 30% のデータでランダムフォレストモデルを評価します。Data Wrangler は F1 スコアを使用して分類モデルを評価し、MSE スコアを使用して回帰モデルを評価します。
-
Gini 重要度メソッドを使用して、各特徴の重要度を計算します。
次の図は、クイックモデル機能のユーザーインターフェイスを示しています。
ターゲット漏洩
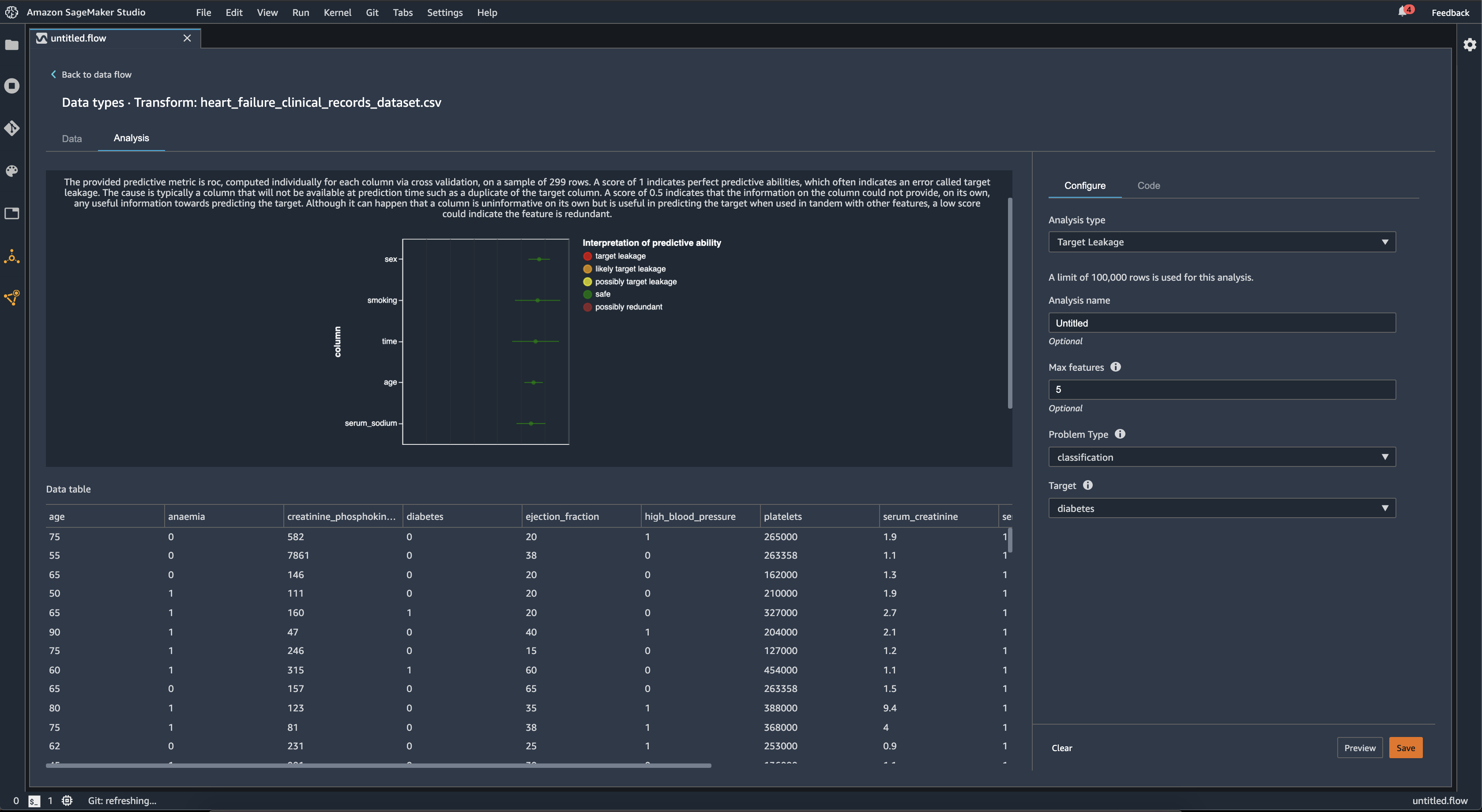
ターゲット漏洩は、機械学習のトレーニングデータセットにターゲットラベルと強い相関性があっても、実際のデータでは利用できないデータがある場合に発生します。例えば、モデルで予測する列のプロキシとして使われる列がデータセット内に存在するとします。
[ターゲット漏洩] 分析を使用する場合、次を指定します。
-
ターゲット: ML モデルで予測を行う対象の特徴です。
-
問題のタイプ: 作業している ML 問題のタイプです。問題のタイプは [分類] または [回帰] のいずれかになります。
-
(オプション) 最大特徴数: ビジュアライゼーション内に存在する特徴の最大数であり、ターゲット漏洩のリスクによってランク付けして特徴を表示しています。
分類の場合、ターゲット漏洩分析は、受信者動作特性の下にある領域、または各列の AUC-ROC 曲線を [最大特徴数] まで使用します。回帰の場合、決定の係数、または R2 メトリクスを使用します。
AUC-ROC 曲線は、最大約 1000 行のサンプルで、交差検証を使用して列ごとに個別に計算される予測メトリクスを提供します。スコア 1 は完璧な予測能力を示し、多くの場合はターゲット漏洩を示します。0.5 以下のスコアは、列の情報が、ターゲットの予測に有用な情報を単独で提供できなかったことを示します。列から単独で情報が得られないものの、他の特徴と併用するとターゲットの予測に役立つことがあり、低いスコアは特徴が冗長であることを示す場合があります。
例えば次の図は、糖尿病の分類問題、つまり、糖尿病にかかっているかどうかを予測するターゲット漏洩レポートを示しています。AUC - ROC 曲線は 5 つの特徴の予測能力を計算するために使用され、すべてがターゲット漏洩から保護されると判断されます。
多重共線性
多重共線性とは、2 つ以上の予測変数が互いに関連している状況です。予測変数は、ターゲット変数を予測するために使用するデータセット内の特徴量です。多重共線性がある場合、予測変数はターゲット変数を予測するだけでなく、相互の予測にもなります。
データ内の多重共線性の尺度として、[分散膨張係数 (VIF)]、[主成分分析 (PCA)]、または [Lasso 特徴量選択] を使用できます。詳細については、以下を参照してください。
時系列データの異常を検出する
異常検出ビジュアライゼーションを使用して、時系列データの外れ値を確認できます。異常と判断される基準を理解するには、時系列が予測項と誤差項に分解されることを理解しておく必要があります。時系列の季節性と傾向を予測項として処理します。残差を誤差項として処理します。
誤差項では、残差が異常と見なされるしきい値を、平均値から離れる偏差の標準の数として指定します。例えば、しきい値を 3 標準偏差として指定できます。平均値から 3 標準偏差を超える残差は異常値です。
次の手順に従って [異常検出] 分析を実行できます。
-
Data Wrangler のデータフローを開きます。
-
データフローの [データ型] で [+] を選択し、[分析を追加] を選択します。
-
[分析タイプ] で、[時系列] を選択します。
-
[ビジュアライゼーション] で、[異常検出] を選択します。
-
[異常しきい値] で、値が異常と見なされるしきい値を選択します。
-
[プレビュー] を選択して、分析のプレビューを生成します。
-
[追加] を選択して、Data Wrangler データフローに変換を追加します。
時系列データにおける季節的な傾向の分解
季節的な傾向分解ビジュアライゼーションを使用して、時系列データに季節性があるかどうかを判断できます。STL (LOESS を使用した季節的な傾向分解) メソッド使用して分解を実行します。時系列を季節性、傾向、残差コンポーネントに分解します。この傾向は、時系列の長期的な進行を反映しています。季節性は、ある期間内に再発する信号です。時系列から傾向と季節性を削除すると、残差が得られます。
次の手順に従って [季節性傾向分解] 分析を実行できます。
-
Data Wrangler のデータフローを開きます。
-
データフローの [データ型] で [+] を選択し、[分析を追加] を選択します。
-
[分析タイプ] で、[時系列] を選択します。
-
[ビジュアライゼーション] で、[季節性傾向分解] を選択します。
-
[異常しきい値] で、値が異常と見なされるしきい値を選択します。
-
[プレビュー] を選択して、分析のプレビューを生成します。
-
[Add] (追加) を選択して、Data Wrangler データフローに変換を追加します。
バイアスレポート
Data Wrangler のバイアスレポートを使用して、データ内の潜在的なバイアスを検出できます。バイアスレポートを生成するには、予測するターゲット列または [Label] (ラベル) を指定し、それに加えてバイアスについて確認する [Facet] (ファセット) または列を指定する必要があります。
[ラベル]: モデルに予測させる特徴量。例えば、顧客コンバージョンを予測する場合、顧客が注文したかどうかに関するデータを含む列を選択できます。また、この特徴がラベルかしきい値かを指定する必要があります。ラベルを指定する場合、データの正の結果の出力を指定する必要があります。顧客コンバージョンの例では、1 が注文列の正の結果であり、過去 3 か月以内に注文した顧客の正の結果を表します。しきい値を指定する場合、正の結果を定義する下限を指定する必要があります。例えば、顧客の注文列に昨年の注文数が含まれている場合、1 を指定します。
[ファセット]: バイアスについて確認する列。例えば、顧客コンバージョンを予測しようとする場合、ファセットが顧客の年齢である可能性があります。データが特定の年齢グループに偏っていると考えられるため、このファセットを選択できます。ファセットが値またはしきい値のどちらとして測定されるのかを特定する必要があります。例えば、1 つ以上の特定の年齢を調べる場合、[Value] (値) を選択し、年齢を指定します。年齢グループを調べる場合は、[Threshold] (しきい値) を選択し、調べる年齢のしきい値を指定します。
特徴とラベルを選択した後、計算するバイアスメトリクスのタイプを選択します。
詳細については、「事前トレーニングデータのバイアスのレポートを生成する」を参照してください。
カスタムビジュアライゼーションを作成する
Data Wrangler フローに分析を追加して、カスタムの可視化を作成できます。適用したすべての変換を含むデータセットは、Pandas DataFramedf 変数を使用してデータフレームを格納します。データフレームにアクセスするには、変数を呼び出します。
出力変数 chart を指定して、Altair
import altair as alt df = df.iloc[:30] df = df.rename(columns={"Age": "value"}) df = df.assign(count=df.groupby('value').value.transform('count')) df = df[["value", "count"]] base = alt.Chart(df) bar = base.mark_bar().encode(x=alt.X('value', bin=True, axis=None), y=alt.Y('count')) rule = base.mark_rule(color='red').encode( x='mean(value):Q', size=alt.value(5)) chart = bar + rule
カスタムビジュアライゼーションを作成するには、次の手順を実行します。
-
可視化したい変換を含むノードの横にある [+] を選択します。
-
[分析を追加] を選択します。
-
[分析タイプ] には、[カスタム可視化] を選択します。
-
[分析名] には名前を指定します。
-
コードボックスにコードを入力します。
-
[プレビュー] を選択して、ビジュアライゼーションをプレビューします。
-
[保存] を選択して可視化を追加します。
Python で Altair 可視化パッケージの使用方法がわからない場合は、カスタムコードスニペットを使用して始めることができます。
Data Wrangler には、検索可能な可視化スニペットのコレクションがあります。可視化スニペットを使用するには、[サンプルスニペットを検索] を選択し、検索バーにクエリを指定します。
次の例では、[ビン分割された散布図] のコードスニペットを使用しています。2 次元のヒストグラムをプロットします。
スニペットには、コードに加える必要のある変更を理解するのに役立つコメントが付いています。通常、コードにはデータセットの列名を指定する必要があります。
import altair as alt # Specify the number of top rows for plotting rows_number = 1000 df = df.head(rows_number) # You can also choose bottom rows or randomly sampled rows # df = df.tail(rows_number) # df = df.sample(rows_number) chart = ( alt.Chart(df) .mark_circle() .encode( # Specify the column names for binning and number of bins for X and Y axis x=alt.X("col1:Q", bin=alt.Bin(maxbins=20)), y=alt.Y("col2:Q", bin=alt.Bin(maxbins=20)), size="count()", ) ) # :Q specifies that label column has quantitative type. # For more details on Altair typing refer to # https://altair-viz.github.io/user_guide/encoding.html#encoding-data-types
