翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
本番稼働用バリアントを使用してモデルをテストする
本番稼働用 ML ワークフローでは、データサイエンティストやエンジニアが、SageMaker AI の自動モデルチューニング、追加されたデータや最新のデータのトレーニング、機能選択の改善、より適切に更新されたインスタンスの使用、コンテナの提供など、さまざまな方法を使用して頻繁にパフォーマンスの改善を試みています。本番稼働用バリアントを使用して、モデル、インスタンス、コンテナを比較し、推論リクエストに応答するのに最もパフォーマンスの高い候補を選択できます。
SageMaker AI マルチバリアントエンドポイントでは、各バリアントにトラフィック分散を提供することで、エンドポイント呼び出し要求を複数の本番環境用バリアントに分散できます。または、リクエストごとに特定のバリアントを直接呼び出すこともできます。このトピックでは、ML モデルをテストするための両方の方法について説明します。
トラフィック分散を指定してモデルをテストする
複数のモデル間でトラフィックを分散してテストするには、エンドポイント構成の各本番稼働用バリアントの重みを指定して、各モデルにルーティングされるトラフィックの割合を指定します。詳細については、「CreateEndpointConfig」をご覧ください。次の図は、この詳しい仕組みを示しています。
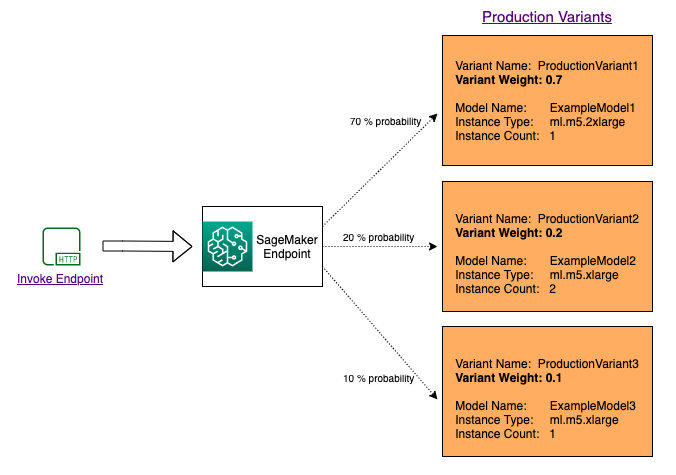
特定のバリアントを呼び出してモデルをテストする
リクエストごとに特定のモデルを呼び出して複数のモデルをテストするには、InvokeEndpoint を呼び出すときに、TargetVariant パラメータの値を入力して呼び出す特定のモデルバージョンを指定します。SageMaker AI は指定した本番稼働用バリアントを使用してリクエストが処理されるようにします。すでにトラフィック分散を指定し、 TargetVariant パラメータに値を指定している場合、ターゲットルーティングによってランダムなトラフィック分散が上書きされます。次の図は、この詳しい仕組みを示しています。
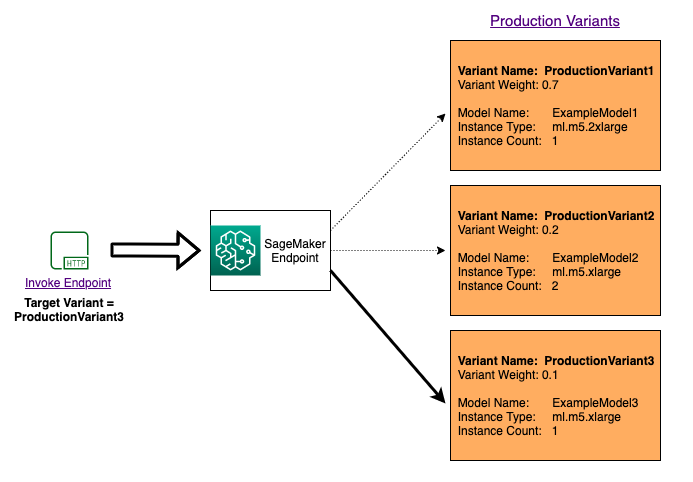
モデル A/B テスト例
新しいモデルと本番稼働用トラフィックのある古いモデル間で A/B テストを実行することは、新しいモデルの検証プロセスの効果的な最終ステップとなります。A/B テストでは、モデルのさまざまなバリアントをテストし、各バリアントのパフォーマンスを比較します。モデルの新しいバージョンが、既存のバージョンよりも優れたパフォーマンスを発揮する場合は、モデルの古いバージョンを本番環境の新しいバージョンに置き換えます。
次の例は、A/B モデルのテストの実行方法を示しています。この例を実装したサンプルノートブックについては、 「本番環境での A/B テスト ML モデル
ステップ 1: モデルの作成とデプロイ
まず、Amazon S3 のどこにモデルが配置されるかを定義します。これらの場所は、以降のステップでモデルをデプロイするときに使用されます。
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
次に、イメージとモデルデータを使用してモデルオブジェクトを作成します。これらのモデルオブジェクトは、エンドポイントに本番稼働用バリアントをデプロイするために使用されます。モデルは、異なるデータセット、異なるアルゴリズムまたは ML フレームワーク、および異なるハイパーパラメータで ML モデルをトレーニングすることによって開発されます。
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
ここでは、それぞれ独自のモデルとリソース要件 (インスタンスタイプと数) が異なる 2 つの本番稼働用バリアントを作成します。これにより、さまざまなインスタンスタイプでモデルをテストすることもできます。
両方のバリアントの initial_weight を 1 に設定します。これにより、リクエストの 50% が Variant1 に送信され、残りの 50% が Variant2 に送信されます。両方のバリアントの重みの合計は 2 で、各バリアントの重みの割り当ては 1 です。つまり、各バリアントは合計トラフィックの 1/2 (50%) を受信することになります。
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
これで、これらの本番稼働用バリアントを SageMaker AI エンドポイントにデプロイする準備が整いました。
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
ステップ 2: デプロイされたモデルを呼び出す
今度は、このエンドポイントにリクエストを送信して、リアルタイムで推論を取得します。トラフィック分散と直接ターゲティングの両方を使用します。
まず、前のステップで構成したトラフィック分散を使用します。各推論応答には、要求を処理する本番稼働用バリアントの名前が含まれているため、2 つの本番稼働用バリアントへのトラフィックはほぼ等しいことがわかります。
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker AI は、Amazon CloudWatch のバリアントごとに Latency や Invocations などのメトリクスを出力します。SageMaker AI が出力するメトリクスの詳しいリストについては、「Amazon CloudWatch における Amazon SageMaker AI メトリクス」を参照してください。CloudWatch をクエリしてバリアントごとの呼び出し回数を取得し、バリアント間で呼び出しを分割するデフォルトの方法を表示します。
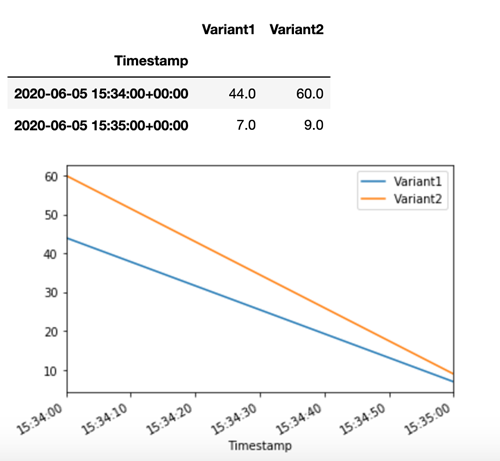
次に、TargetVariant の呼び出しで Variant1 を invoke_endpoint としてを指定することで、モデルの特定のバージョンを呼び出します。
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
すべての新しい呼び出しが Variant1 によって処理されたことを確認するには、CloudWatch のクエリを実行して、バリアントごとの呼び出し回数を取得します。最新の呼び出し (最新のタイムスタンプ) では、指定されたようにすべてのリクエストが Variant1 によって処理されたことがわかります。Variant2 に対する呼び出しはありませんでした。
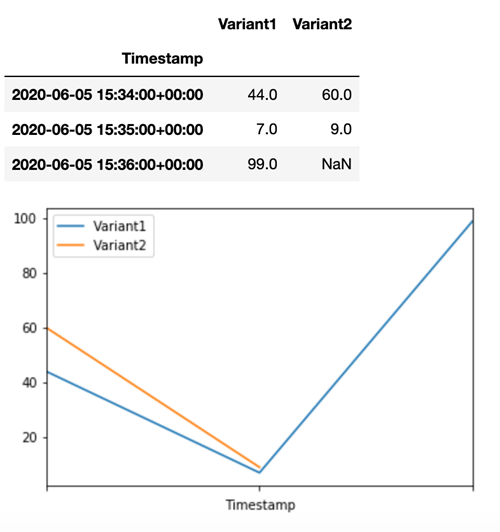
ステップ 3: モデルパフォーマンスの評価
どのモデルバージョンがより優れたパフォーマンスを発揮するかを確認するために、各バリアントの曲線の下にある正確性、精度、リコール、F1 スコア、レシーバー動作特性/領域を評価します。まず、Variant1 のメトリクスを見てみましょう。
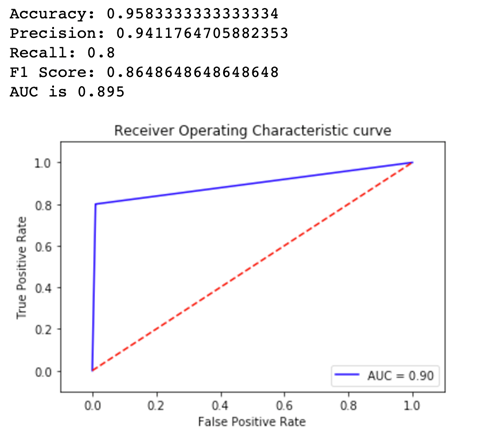
次に、Variant2 のメトリクスを見てみましょう。
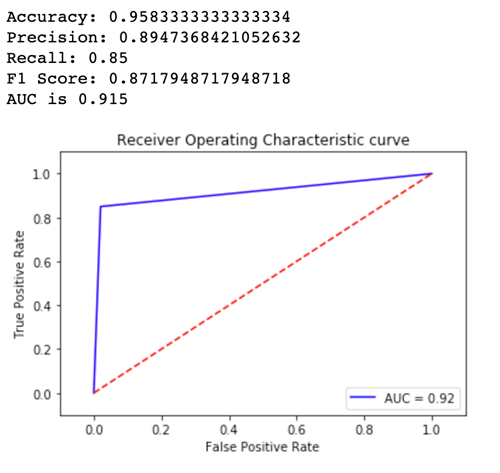
定義済みのメトリクスのほとんどについて、Variant2 のパフォーマンスが向上しているため、本番環境で使用するのはこれになります。
ステップ 4: 最適なモデルに対するトラフィックの増加
Variant2 のパフォーマンスが Variant1 より優れていると判断したため、より多くのトラフィックをそちらにシフトさせます。引き続き TargetVariant を使用して特定のモデルバリアントを呼び出すことができますが、より簡単なアプローチは、UpdateEndPointWeightsAndCapacities を呼び出して各バリアントに割り当てられた重みを更新する方法です。これにより、エンドポイントを更新することなく、運用バリアントへのトラフィック分散が変更されます。セットアップセクションから、トラフィックを 50/50 に分割するようバリアントの重みを設定したことを思い出してください。以下の各バリアントの合計呼び出し回数の CloudWatch メトリクスは、各バリアントの呼び出しパターンを示しています。
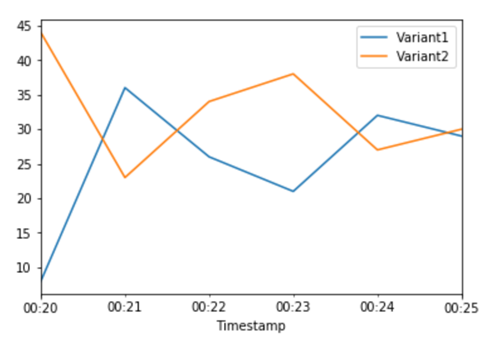
UpdateEndpointWeightsAndCapacities を使用して各バリアントに新しい重みを割り当てることで、トラフィックの 75% を Variant2 に移動します。SageMaker AI は推論リクエストの 75% をVariant2 に、残りの 25% を Variant1 に送ります。
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
各バリアントの合計呼び出し回数の CloudWatch メトリクスは、Variant2 の呼び出しのほうが Variant1 よりも呼び出し回数が多いことを示しています。
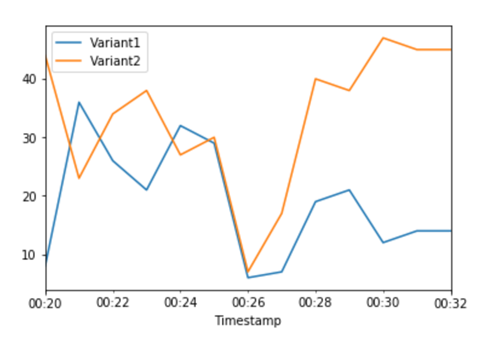
引き続きメトリクスを監視し、バリアントのパフォーマンスに満足したら、トラフィックの 100% をそのバリアントにルーティングできます。UpdateEndpointWeightsAndCapacities を使用して、バリアントのトラフィック割り当てを更新します。Variant1 の重みを 0 に、Variant2 の重みを 1 に設定します。SageMaker AI はすべての推論リクエストの 100% を Variant2 に送信します。
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
各バリアントの合計呼び出し回数の CloudWatch メトリクスは、すべての推論リクエストを Variant2 が処理し、Variant1 が処理する推論リクエストがないことを示しています。
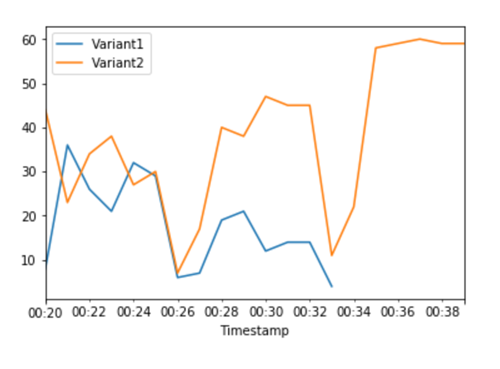
これで、エンドポイントを安全に更新し、エンドポイントから Variant1 を削除できるようになりました。エンドポイントに新しいバリアントを追加し、ステップ 2 ~ 4 を実行することで、本番環境での新しいモデルのテストを続行することもできます。
