翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
パイプラインを定義する
Amazon SageMaker Pipelines を使用してワークフローをオーケストレートするには、JSON パイプライン定義の形式で有向非巡回グラフ (DAG) を生成する必要があります。DAG を使用すると、データの前処理、モデルトレーニング、モデル評価、モデルデプロイなど、ML プロセスに関するさまざまなステップや、このようなステップ間のデータの依存関係とフローを指定できます。次のトピックでは、パイプライン定義を生成する方法を説明します。
JSON パイプライン定義は、SageMaker Python SDK または Amazon SageMaker Studio のビジュアルドラッグアンドドロップパイプラインデザイナー機能を使用して生成できます。このチュートリアルで作成するパイプライン DAG は、次の画像のとおりです。
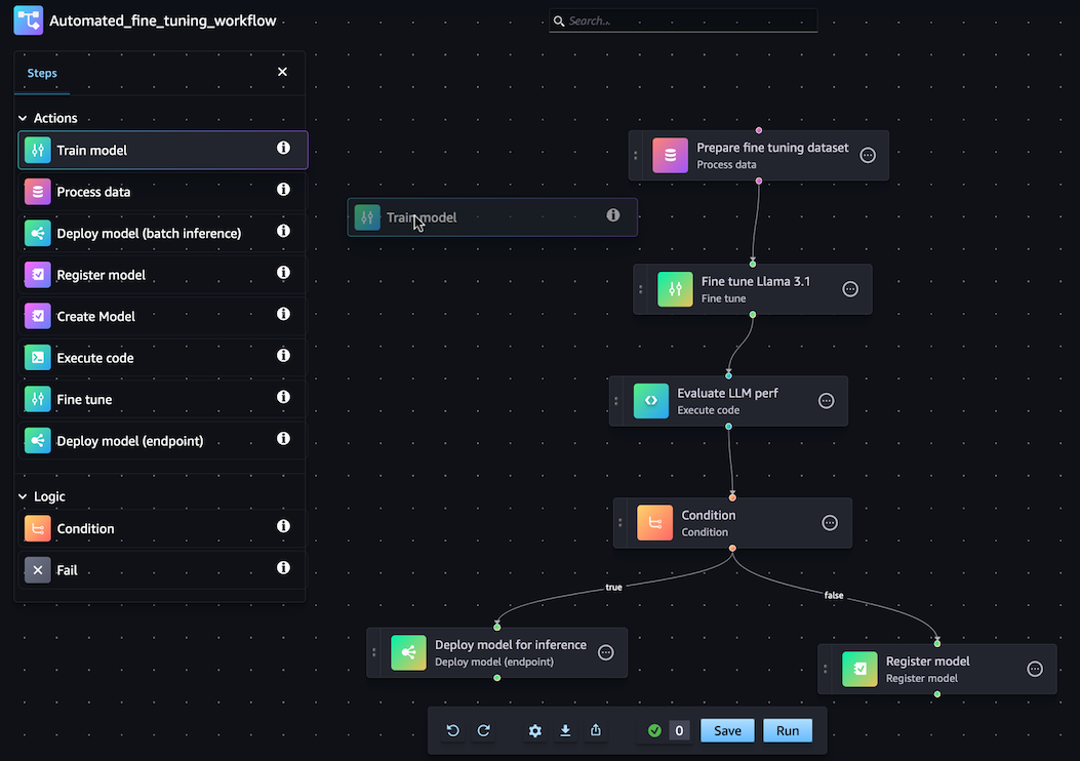
以降のセクションで定義するパイプラインは、リグレッションに関する問題を解決し、物理的な測定値に基づいてアワビの年齢を決定します。このチュートリアルのコンテンツを含む、実行可能な Jupyter Notebook については、「Orchestrating Jobs with Amazon SageMaker Model Building Pipelines
注記
モデルの場所をトレーニングステップのプロパティとして参照できます。Github でエンドツーエンドの例 CustomerChurn pipeline
トピック
以下のウォークスルーでは、ドラッグアンドドロップ Pipeline Designer を使用して、基本のパイプラインを作成する手順について説明します。ビジュアルデザイナーでパイプライン編集セッションを一時停止または終了する必要がある場合は、[エクスポート] オプションをクリックします。これにより、パイプラインの現在の定義をローカル環境にダウンロードできます。その後、パイプライン編集プロセスを再開する場合は、同じ JSON 定義ファイルをビジュアルデザイナーにインポートできます。
処理ステップを作成する
データ処理ジョブステップを作成するには、次の手順を実行します。
-
「Amazon SageMaker Studio を起動する」の手順に従って、Studio コンソールを開きます。
-
左側のナビゲーションペインで、[パイプライン] を選択します。
-
[作成] を選択します。
-
[指定なし] をクリックします。
-
左側のサイドバーで、[データ処理] を選択し、キャンバスにドラッグします。
-
キャンバスで、追加した [データ処理] ステップを選択します。
-
入力データセットを追加するには、右側のサイドバーの [データ (入力)] の下にある [追加] を選択して、データセットを選択します。
-
出力データセットを保存する場所を追加するには、右側のサイドバーの [データ (出力)] の下にある [追加] を選択して、保存先に移動します。
-
右側のサイドバーの残りのフィールドに入力します。これらのタブのフィールドの詳細については、「sagemaker.workflow.steps.ProcessingStep
」を参照してください。
トレーニングステップを作成する
モデルトレーニングステップを設定するには、次の手順を実行します。
-
左側のサイドバーで、[モデルをトレーニング] を選択し、キャンバスにドラッグします。
-
キャンバスで、追加した [モデルをトレーニング] ステップを選択します。
-
入力データセットを追加するには、右側のサイドバーの [データ (入力)] の下にある [追加] を選択して、データセットを選択します。
-
モデルアーティファクトを保存する場所を選択するには、[場所 (S3 URI)] フィールドに Amazon S3 URI を入力するか、[S3 を参照] をクリックして、送信先の場所に移動します。
-
右側のサイドバーの残りのフィールドに入力します。これらのタブのフィールドの詳細については、「sagemaker.workflow.steps.TrainingStep
」を参照してください。 -
カーソルをクリックして、前のセクションで追加した [データ処理] ステップから [モデルトレーニング] ステップにドラッグし、2 つのステップを接続するエッジを作成します。
モデル登録ステップを使用してモデルパッケージを作成する
モデル登録ステップを使用してモデルパッケージを作成するには、次の手順を実行します。
-
左側のサイドバーで、[モデルの登録] を選択し、キャンバスにドラッグします。
-
キャンバスで、追加した [モデルの登録] ステップを選択します。
-
登録するモデルを選択するには、[モデル (入力)] の下にある [追加] をクリックします。
-
[モデルグループを作成] をクリックして、モデルを新しいモデルグループに追加します。
-
右側のサイドバーの残りのフィールドに入力します。これらのタブのフィールドの詳細については、「sagemaker.workflow.step_collections.RegisterModel
」を参照してください。 -
カーソルをクリックして、前のセクションで追加した [モデルトレーニング] ステップから [モデル登録] ステップにドラッグし、2 つのステップを接続するエッジを作成します。
デプロイモデル (エンドポイント) ステップを使用してモデルをエンドポイントにデプロイする
モデルデプロイステップを使用してモデルをデプロイするには、次の手順を実行します。
-
左側のサイドバーで、[モデルの登録 (エンドポイント)] を選択し、キャンバスにドラッグします。
-
キャンバスで、追加した [モデルのデプロイ (エンドポイント)] ステップを選択します。
-
デプロイするモデルを選択するには、[モデル (入力)] の下にある [追加] をクリックします。
-
[エンドポイントの作成] ラジオボタンをオンにして、新しいエンドポイントを作成します。
-
エンドポイントの [名前] と [説明] を入力します。
-
カーソルをクリックして、前のセクションで追加した [モデル登録] ステップから [モデルのデプロイ (エンドポイント)] ステップにドラッグし、2 つのステップを接続するエッジを作成します。
-
右側のサイドバーの残りのフィールドに入力します。
パイプラインパラメータを定義する
実行ごとに値を更新できるパイプラインパラメータのセットを設定できます。パイプラインのパラメータを定義してデフォルト値を設定するには、ビジュアルデザイナーの下部にある歯車アイコンをクリックします。
パイプラインを保存する
パイプラインを作成するために必要な情報をすべて入力したら、ビジュアルデザイナーの下部にある [保存] をクリックします。これにより、ランタイムでパイプラインの潜在的なエラーが検証され、通知が送信されます。自動検証チェックでフラグが付けられたエラーすべてに対処するまで、[保存] オペレーションは正常に完了しません。後で編集を再開する場合は、進行中のパイプラインをローカル環境に JSON 定義として保存できます。ビジュアルデザイナーの下部にある [エクスポート] ボタンをクリックすると、パイプラインを JSON 定義ファイルとしてエクスポートできます。その後、パイプラインの更新を再開するには、[インポート] ボタンをクリックして、この JSON 定義ファイルをアップロードします。
前提条件
次のチュートリアルを実行するには、以下を実行する必要があります。
-
「ノートブックインスタンスを作成する」の説明に従って、ノートブックインスタンスを設定します。これにより、Amazon S3 での読み取りと書き込み、SageMaker AI でのトレーニング、バッチ変換、処理ジョブの作成のアクセス許可がロールに付与されます。
-
「ロールのアクセス許可ポリシーの変更 (コンソール)」に示すように、独自のロールを取得および渡すアクセス許可をノートブックに付与します。次の JSON スニペットを追加して、このポリシーをロールにアタッチします。
<your-role-arn>をノートブックインスタンスの作成に使用する ARN に置き換えます。 -
「ロールの信頼ポリシーの変更」の手順に従って、SageMaker AI サービスプリンシパルを信頼します。ロールの信頼関係に次のステートメントの断片を追加します。
{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": "sts:AssumeRole" }
環境をセットアップする
次のコードブロックを使用して、新しい SageMaker AI セッションを作成します。このコードブロックでは、セッションのロール ARN が返されます。このロール ARN は、前提条件として設定した実行ロール ARN になります。
import boto3 import sagemaker import sagemaker.session from sagemaker.workflow.pipeline_context import PipelineSession region = boto3.Session().region_name sagemaker_session = sagemaker.session.Session() role = sagemaker.get_execution_role() default_bucket = sagemaker_session.default_bucket() pipeline_session = PipelineSession() model_package_group_name = f"AbaloneModelPackageGroupName"
パイプラインを作成する
重要
Amazon SageMaker Studio または Amazon SageMaker Studio Classic に Amazon SageMaker リソースの作成を許可するカスタム IAM ポリシーでは、これらのリソースにタグを追加するアクセス許可も付与する必要があります。Studio と Studio Classic は、作成したリソースに自動的にタグ付けするため、リソースにタグを追加するアクセス許可が必要になります。IAM ポリシーで Studio と Studio Classic によるリソースの作成が許可されていても、タグ付けが許可されていない場合は、リソースを作成しようとしたときに「AccessDenied」エラーが発生する可能性があります。詳細については、「SageMaker AI リソースにタグ付けのアクセス許可を付与する」を参照してください。
SageMaker リソースを作成するためのアクセス許可を付与する AWS Amazon SageMaker AI の マネージドポリシー には、それらのリソースの作成中にタグを追加するためのアクセス許可もあらかじめ含まれています。
SageMaker AI ノートブックインスタンスから次のステップを実行して、以下のステップを含むパイプラインを作成します。
-
前処理
-
トレーニング
-
評価
-
条件評価
-
モデル登録
注記
ExecutionVariablesExecutionVariables はランタイムで解決されます。例えば、ExecutionVariables.PIPELINE_EXECUTION_ID は現在の実行の ID に解決されます。この ID は、実行ごとに一意の識別子として使用できます。
ステップ 1: データセットをダウンロードする
このノートブックでは、UCI Machine Learning Abalone Dataset を使用します。データセットには、次の特徴が含まれています。
-
length- アワビの最長の殻の測定値。 -
diameter- アワビの長さに垂直な直径。 -
height- 殻に身が入った状態のアワビの高さ。 -
whole_weight- アワビ全体の重量。 -
shucked_weight- アワビから取り出した身の重量。 -
viscera_weight- 血を抜いた後のアワビの内臓の重量。 -
shell_weight- 身を取り除き乾燥させた後のアワビの殻の重量。 -
sex- アワビの性別。「M」、「F」、「I」のいずれか。「I」は子供のアワビを表す。 -
rings- アワビの殻の輪の数。
アワビの殻の輪の数によって、年齢の近似値が求められます (公式 age=rings + 1.5 を使用)。ただし、このような数値の取得には時間がかかります。コーンから殻を切断し、断面を染色して、顕微鏡で覗きながら輪の数を数えなければなりません。ただし、その他の物理的な測定値は簡単に入手できます。このノートブックではデータセットを使用し、他の物理的な測定値を用いた不定の輪の数の予測モデルを構築します。
データセットをダウンロードするには
-
アカウントのデフォルトの Amazon S3 バケットにデータセットをダウンロードします。
!mkdir -p data local_path = "data/abalone-dataset.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset.csv", local_path ) base_uri = f"s3://{default_bucket}/abalone" input_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(input_data_uri) -
モデルを作成したら、バッチ変換用の 2 つ目のデータセットをダウンロードします。
local_path = "data/abalone-dataset-batch.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset-batch", local_path ) base_uri = f"s3://{default_bucket}/abalone" batch_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(batch_data_uri)
ステップ 2: パイプラインのパラメータを定義する
このコードブロックは、パイプラインの以下のパラメータを定義します。
-
processing_instance_count- 処理ジョブのインスタンス数。 -
input_data- 入力データの Amazon S3 の場所。 -
batch_data- バッチ変換用の入力データの Amazon S3 の場所。 -
model_approval_status- CI/CD のトレーニング済みモデルを登録するための承認ステータス。詳細については、「SageMaker プロジェクトを使用した MLOps の自動化」を参照してください。
from sagemaker.workflow.parameters import ( ParameterInteger, ParameterString, ) processing_instance_count = ParameterInteger( name="ProcessingInstanceCount", default_value=1 ) model_approval_status = ParameterString( name="ModelApprovalStatus", default_value="PendingManualApproval" ) input_data = ParameterString( name="InputData", default_value=input_data_uri, ) batch_data = ParameterString( name="BatchData", default_value=batch_data_uri, )
ステップ 3: 特徴量エンジニアリングの処理ステップを定義する
このセクションでは、データセットからトレーニング用のデータを準備するための処理ステップの作成方法を説明します。
処理ステップを作成するには
-
処理スクリプト用のディレクトリを作成します。
!mkdir -p abalone -
/abaloneディレクトリに次の内容でpreprocessing.pyというファイルを作成します。この前処理スクリプトは、入力データの実行のための処理ステップに渡されます。次に、トレーニングステップでは、前処理されたトレーニング機能とラベルを使用してモデルをトレーニングします。評価ステップでは、トレーニング済みモデル、前処理済みテスト機能、ラベルを使用してモデルを評価します。スクリプトはscikit-learnを使用して次の処理を実行します。-
不足している
sexカテゴリデータと入力し、トレーニング用にエンコードします。 -
ringsとsexを除くすべての数値フィールドをスケーリングして正規化します。 -
データをトレーニング、テスト、検証のデータセットに分割します。
%%writefile abalone/preprocessing.py import argparse import os import requests import tempfile import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, OneHotEncoder # Because this is a headerless CSV file, specify the column names here. feature_columns_names = [ "sex", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ] label_column = "rings" feature_columns_dtype = { "sex": str, "length": np.float64, "diameter": np.float64, "height": np.float64, "whole_weight": np.float64, "shucked_weight": np.float64, "viscera_weight": np.float64, "shell_weight": np.float64 } label_column_dtype = {"rings": np.float64} def merge_two_dicts(x, y): z = x.copy() z.update(y) return z if __name__ == "__main__": base_dir = "/opt/ml/processing" df = pd.read_csv( f"{base_dir}/input/abalone-dataset.csv", header=None, names=feature_columns_names + [label_column], dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype) ) numeric_features = list(feature_columns_names) numeric_features.remove("sex") numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) categorical_features = ["sex"] categorical_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="constant", fill_value="missing")), ("onehot", OneHotEncoder(handle_unknown="ignore")) ] ) preprocess = ColumnTransformer( transformers=[ ("num", numeric_transformer, numeric_features), ("cat", categorical_transformer, categorical_features) ] ) y = df.pop("rings") X_pre = preprocess.fit_transform(df) y_pre = y.to_numpy().reshape(len(y), 1) X = np.concatenate((y_pre, X_pre), axis=1) np.random.shuffle(X) train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))]) pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False) pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False) pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False) -
-
SKLearnProcessorのインスタンスを作成して処理ステップに渡します。from sagemaker.sklearn.processing import SKLearnProcessor framework_version = "0.23-1" sklearn_processor = SKLearnProcessor( framework_version=framework_version, instance_type="ml.m5.xlarge", instance_count=processing_instance_count, base_job_name="sklearn-abalone-process", sagemaker_session=pipeline_session, role=role, ) -
処理ステップを作成します。このステップは、
SKLearnProcessor、入出力チャネル、作成したpreprocessing.pyスクリプトを受け取ります。これは、SageMaker AI Python SDK のプロセッサインスタンスのrunメソッドと非常によく似ています。ProcessingStepに渡されるinput_dataパラメータはステップ自体の入力データです。この入力データは、プロセッサインスタンスの実行時に使用されます。"train、"validation、"test"で指定されるチャネルは、処理ジョブの出力設定で指定されたものになります。このようなステップのPropertiesは、後続のステップで使用し、ランタイム中にランタイム値に解決できます。from sagemaker.processing import ProcessingInput, ProcessingOutput from sagemaker.workflow.steps import ProcessingStep processor_args = sklearn_processor.run( inputs=[ ProcessingInput(source=input_data, destination="/opt/ml/processing/input"), ], outputs=[ ProcessingOutput(output_name="train", source="/opt/ml/processing/train"), ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"), ProcessingOutput(output_name="test", source="/opt/ml/processing/test") ], code="abalone/preprocessing.py", ) step_process = ProcessingStep( name="AbaloneProcess", step_args=processor_args )
ステップ 4: にトレーニングステップを定義する
このセクションでは、SageMaker AI の XGBoost アルゴリズムを使用して、処理ステップから出力されたトレーニングデータでモデルをトレーニングする方法を説明します。
トレーニングステップを定義するには
-
トレーニングからモデルを保存するモデルパスを指定します。
model_path = f"s3://{default_bucket}/AbaloneTrain" -
XGBoost アルゴリズムの推定器と入力データセットを設定します。トレーニングインスタンスタイプは推定器に渡されます。一般的なトレーニングスクリプトは、以下のとおりです。
-
入力チャネルからデータをロードする
-
ハイパーパラメータを使用してトレーニングを設定する
-
モデルをトレーニングする
-
モデルを
model_dirに保存して、後でホストできるようにする
SageMaker AI はトレーニングジョブの終了時に、
model.tar.gzの形式でモデルを Amazon S3 にアップロードします。from sagemaker.estimator import Estimator image_uri = sagemaker.image_uris.retrieve( framework="xgboost", region=region, version="1.0-1", py_version="py3", instance_type="ml.m5.xlarge" ) xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, sagemaker_session=pipeline_session, role=role, ) xgb_train.set_hyperparameters( objective="reg:linear", num_round=50, max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.7, silent=0 ) -
-
推定器インスタンスのプロパティと
ProcessingStepのプロパティを使用してTrainingStepを作成します。"train"出力チャネルと"validation"出力チャネルのS3UriをTrainingStepに渡します。from sagemaker.inputs import TrainingInput from sagemaker.workflow.steps import TrainingStep train_args = xgb_train.fit( inputs={ "train": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, ) step_train = TrainingStep( name="AbaloneTrain", step_args = train_args )
ステップ 5: モデル評価の処理ステップを定義する
このセクションでは、モデルの精度を評価するための処理ステップの作成方法を説明します。このモデル評価の結果は、条件ステップで実行する実行パスを決定するために使用されます。
モデル評価の処理ステップを定義するには
-
/abaloneディレクトリにevaluation.pyという名前のファイルを作成します。このスクリプトは、モデル評価を実行するための処理ステップで使用されます。トレーニング済みのモデルとテストデータセットを入力として受け取り、分類評価メトリクスを含む JSON ファイルを生成します。%%writefile abalone/evaluation.py import json import pathlib import pickle import tarfile import joblib import numpy as np import pandas as pd import xgboost from sklearn.metrics import mean_squared_error if __name__ == "__main__": model_path = f"/opt/ml/processing/model/model.tar.gz" with tarfile.open(model_path) as tar: tar.extractall(path=".") model = pickle.load(open("xgboost-model", "rb")) test_path = "/opt/ml/processing/test/test.csv" df = pd.read_csv(test_path, header=None) y_test = df.iloc[:, 0].to_numpy() df.drop(df.columns[0], axis=1, inplace=True) X_test = xgboost.DMatrix(df.values) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) std = np.std(y_test - predictions) report_dict = { "regression_metrics": { "mse": { "value": mse, "standard_deviation": std }, }, } output_dir = "/opt/ml/processing/evaluation" pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True) evaluation_path = f"{output_dir}/evaluation.json" with open(evaluation_path, "w") as f: f.write(json.dumps(report_dict)) -
ProcessingStepの作成に使用されるScriptProcessorのインスタンスを作成します。from sagemaker.processing import ScriptProcessor script_eval = ScriptProcessor( image_uri=image_uri, command=["python3"], instance_type="ml.m5.xlarge", instance_count=1, base_job_name="script-abalone-eval", sagemaker_session=pipeline_session, role=role, ) -
プロセッサインスタンス、入力チャネルと出力チャネル、
evaluation.pyスクリプトを使用してProcessingStepを作成します。以下を渡します。-
step_trainトレーニングステップのS3ModelArtifactsプロパティ -
step_process処理ステップの"test"出力チャネルのS3Uri
これは、SageMaker AI Python SDK のプロセッサインスタンスの
runメソッドと非常によく似ています。from sagemaker.workflow.properties import PropertyFile evaluation_report = PropertyFile( name="EvaluationReport", output_name="evaluation", path="evaluation.json" ) eval_args = script_eval.run( inputs=[ ProcessingInput( source=step_train.properties.ModelArtifacts.S3ModelArtifacts, destination="/opt/ml/processing/model" ), ProcessingInput( source=step_process.properties.ProcessingOutputConfig.Outputs[ "test" ].S3Output.S3Uri, destination="/opt/ml/processing/test" ) ], outputs=[ ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"), ], code="abalone/evaluation.py", ) step_eval = ProcessingStep( name="AbaloneEval", step_args=eval_args, property_files=[evaluation_report], ) -
ステップ 6: バッチ変換用の CreateModelStep を定義する
重要
SageMaker Python SDK v2.90.0 以降では、モデルステップ を使用してモデルを作成することをお勧めします。CreateModelStep は SageMaker Python SDK の以前のバージョンでも引き続き動作しますが、サポートは終了しました。
このセクションでは、トレーニングステップの出力から SageMaker AI モデルを作成する方法を説明します。このモデルは、新しいデータセットのバッチ変換に使用されます。このステップは条件ステップに渡され、条件ステップが true と評価された場合にのみ実行されます。
バッチ変換用の CreateModelStep を定義するには
-
SageMaker AI モデルを作成します。
step_trainトレーニングステップのS3ModelArtifactsプロパティを渡します。from sagemaker.model import Model model = Model( image_uri=image_uri, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, sagemaker_session=pipeline_session, role=role, ) -
SageMaker AI モデルのモデル入力を定義します。
from sagemaker.inputs import CreateModelInput inputs = CreateModelInput( instance_type="ml.m5.large", accelerator_type="ml.eia1.medium", ) -
CreateModelInputと定義した SageMaker AI モデルインスタンスを使用して、CreateModelStepを作成します。from sagemaker.workflow.steps import CreateModelStep step_create_model = CreateModelStep( name="AbaloneCreateModel", model=model, inputs=inputs, )
ステップ 7: バッチ変換を実行するための TransformStep を定義する
このセクションでは、モデルのトレーニング後にデータセットにバッチ変換を実行する TransformStep の作成方法を説明します。このステップは条件ステップに渡され、条件ステップが true と評価された場合にのみ実行されます。
バッチ変換を実行するための TransformStep を定義するには
-
該当するコンピューティングインスタンスタイプ、インスタンス数、目的の出力 Amazon S3 バケット URI を使用して、トランスフォーマーインスタンスを作成します。
step_create_modelCreateModelステップのModelNameプロパティを渡します。from sagemaker.transformer import Transformer transformer = Transformer( model_name=step_create_model.properties.ModelName, instance_type="ml.m5.xlarge", instance_count=1, output_path=f"s3://{default_bucket}/AbaloneTransform" ) -
定義したトランスフォーマーインスタンスと
batch_dataパイプラインパラメータを使用して、TransformStepを作成します。from sagemaker.inputs import TransformInput from sagemaker.workflow.steps import TransformStep step_transform = TransformStep( name="AbaloneTransform", transformer=transformer, inputs=TransformInput(data=batch_data) )
ステップ 8: モデルパッケージを作成するための RegisterModel ステップを定義する
重要
SageMaker Python SDK の v2.90.0 以降では、モデルステップ を使用してモデルを登録することをお勧めします。RegisterModel は SageMaker Python SDK の以前のバージョンでも引き続き動作しますが、現在サポートは終了しています。
このセクションでは、RegisterModel のインスタンスを作成する方法を説明します。パイプラインで RegisterModel を実行すると、モデルパッケージが作成されます。モデルパッケージは、再利用可能なモデルアーティファクトを抽象化したものであり、推論に必要なすべての成分がまとめられています。オプションのモデルの重みの場所と共に使用する推論イメージを定義する推論仕様で構成されます。モデルパッケージグループは、モデルパッケージがまとめられたものです。Pipelines で ModelPackageGroup を使用すると、パイプラインの実行ごとに新しいバージョンとモデルパッケージをグループに追加できます。モデルのレジストリの詳細については、「Model Registry を使用したモデル登録デプロイ」をご参照ください。
このステップは条件ステップに渡され、条件ステップが true と評価された場合にのみ実行されます。
モデルパッケージを作成するための RegisterModel ステップを定義するには
-
トレーニングステップに使用した推定器インスタンスを使用して
RegisterModelステップを作成します。step_trainトレーニングステップのS3ModelArtifactsプロパティを渡し、ModelPackageGroupを作成します。パイプラインは、このModelPackageGroupを自動的に作成します。from sagemaker.model_metrics import MetricsSource, ModelMetrics from sagemaker.workflow.step_collections import RegisterModel model_metrics = ModelMetrics( model_statistics=MetricsSource( s3_uri="{}/evaluation.json".format( step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"] ), content_type="application/json" ) ) step_register = RegisterModel( name="AbaloneRegisterModel", estimator=xgb_train, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, content_types=["text/csv"], response_types=["text/csv"], inference_instances=["ml.t2.medium", "ml.m5.xlarge"], transform_instances=["ml.m5.xlarge"], model_package_group_name=model_package_group_name, approval_status=model_approval_status, model_metrics=model_metrics )
ステップ 9: モデルの精度を検証するための条件ステップを定義する
ConditionStep を使用すると、ステッププロパティの条件に基づいて、パイプライン DAG での条件付き実行が Pipelines でサポートされるようになります。この場合、モデルの精度が求められる値を超える場合にのみ、モデルパッケージを登録します。モデルの精度は、モデル評価ステップによって決まります。精度が必要な値を超過すると、パイプラインは SageMaker AI モデルも作成し、データセットに対してバッチ変換を実行します。このセクションでは、条件ステップを定義する方法を説明します。
モデルの精度を検証するための条件ステップを定義するには
-
モデル評価の処理ステップ
step_evalの出力で見つかった精度値を使用して、ConditionLessThanOrEqualTo条件を定義します。この出力を取得するには、処理ステップでインデックス付けしたプロパティファイルと、平均二乗誤差値"mse"のそれぞれの JSONPath を使用します。from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo from sagemaker.workflow.condition_step import ConditionStep from sagemaker.workflow.functions import JsonGet cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=step_eval.name, property_file=evaluation_report, json_path="regression_metrics.mse.value" ), right=6.0 ) -
ConditionStepを作成します。ConditionEquals条件を渡し、条件が満たされた場合の次のステップとなる、モデルパッケージの登録ステップとバッチ変換ステップを設定します。step_cond = ConditionStep( name="AbaloneMSECond", conditions=[cond_lte], if_steps=[step_register, step_create_model, step_transform], else_steps=[], )
ステップ 10: パイプラインを作成する
以上ですべてのステップが作成できました。次は、それらのステップをパイプラインに結合します。
パイプラインを作成するには
-
パイプラインの
name、parameters、stepsを定義します。名前は、(account, region)ペア内で一意である必要があります。注記
ステップは、パイプラインのステップリストまたは条件ステップの if/else ステップリストに 1 回のみ表示できます。また、両方に表示することはできません。
from sagemaker.workflow.pipeline import Pipeline pipeline_name = f"AbalonePipeline" pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, model_approval_status, input_data, batch_data, ], steps=[step_process, step_train, step_eval, step_cond], ) -
(オプション) JSON パイプラインの定義を調べて、フォーマットに誤りがないことを確認します。
import json json.loads(pipeline.definition())
パイプライン定義を SageMaker AI に送信する準備が整いました。次のチュートリアルでは、このパイプラインを SageMaker AI に送信し、実行を開始します。
boto3
{'Version': '2020-12-01', 'Metadata': {}, 'Parameters': [{'Name': 'ProcessingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ProcessingInstanceCount', 'Type': 'Integer', 'DefaultValue': 1}, {'Name': 'TrainingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ModelApprovalStatus', 'Type': 'String', 'DefaultValue': 'PendingManualApproval'}, {'Name': 'ProcessedData', 'Type': 'String', 'DefaultValue': 'S3_URL', {'Name': 'InputDataUrl', 'Type': 'String', 'DefaultValue': 'S3_URL', 'PipelineExperimentConfig': {'ExperimentName': {'Get': 'Execution.PipelineName'}, 'TrialName': {'Get': 'Execution.PipelineExecutionId'}}, 'Steps': [{'Name': 'ReadTrainDataFromFS', 'Type': 'Processing', 'Arguments': {'ProcessingResources': {'ClusterConfig': {'InstanceType': 'ml.m5.4xlarge', 'InstanceCount': 2, 'VolumeSizeInGB': 30}}, 'AppSpecification': {'ImageUri': 'IMAGE_URI', 'ContainerArguments': [....]}, 'RoleArn': 'ROLE', 'ProcessingInputs': [...], 'ProcessingOutputConfig': {'Outputs': [.....]}, 'StoppingCondition': {'MaxRuntimeInSeconds': 86400}}, 'CacheConfig': {'Enabled': True, 'ExpireAfter': '30d'}}, ... ... ... }
次のステップ: パイプラインを実行する
