翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
大規模な並列ワークロード向けに Step Functions で Map ステートを分散モードで使用する
ステートの管理とデータの変換
変数を使用したステート間のデータ受け渡しと JSONata を使用したデータ変換について説明します。
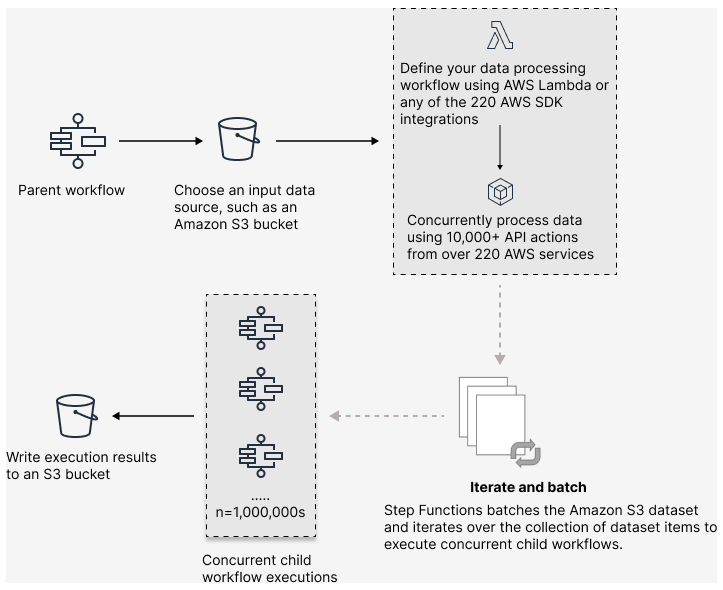
Step Functions を使用すると、大規模な並行ワークロードをオーケストレーションして、半構造化データのオンデマンド処理などのタスクを実行できます。これらの並行ワークロードにより、Amazon S3 に保存されている大規模なデータソースを同時に処理できます。例えば、大量のデータを含む 1 つの JSON または CSV ファイルを処理できます。あるいは、大量の Amazon S3 オブジェクトを処理する場合もあります。
ワークフローに大規模な並行ワークロードを設定するには、Map 状態を分散モードに含めます。マップステートは、データセット内のアイテムを同時に処理します。[分散] に設定された Map ステートは、分散マップ状態と呼ばれます。分散モードでは、Map 状態によって高度な同時処理が可能になります。分散モードでは、Map 状態はデータセット内の項目を子ワークフロー実行と呼ばれる反復処理を行います。並行して実行できる子ワークフローの実行数を指定できます。それぞれの子ワークフローの実行には、親ワークフローとは別の実行履歴があります。指定しない場合、Step Functions は 10,000 件の子ワークフローを並列で実行します。
次の図は、ワークフローに大規模な並行ワークロードを設定する方法を示しています。
ワークショップで学ぶ
Step Functions や Lambda などのサーバーレステクノロジーが、管理とスケーリングを簡素化し、未分化タスクをオフロードし、大規模な分散データ処理の課題に対処する方法について説明します。その過程で、分散マップを使用して同時実行性の高い処理を行います。このワークショップでは、ワークフローを最適化するためのベストプラクティス、およびクレーム処理、脆弱性スキャン、モンテカルロシミュレーションの実用的なユースケースについても説明します。
重要な用語
- 分散モード
-
マップステートの処理モード。このモードでは、
Map状態の各反復処理が子ワークフロー実行として実行されるため、高い同時実行性が可能になります。子ワークフローの実行にはそれぞれ独自の実行履歴があり、親ワークフローの実行履歴とは別のものです。このモードは、大規模な Amazon S3 のデータソースからの入力の読み取りをサポートします。 - 分散マップ状態
-
[分散] 処理モードに設定されたマップステート。
- マップワークフロー
Map状態が実行する一連のステップ。- 親ワークフロー
-
1 つ以上の分散マップ状態を含むワークフロー。
- 子ワークフロー実行
-
分散マップ状態の反復。子ワークフローの実行には独自の実行履歴があり、親ワークフローの実行履歴とは別のものです。
- マップ実行
-
分散モードで
Map状態を実行すると、Step Functions はマップ実行リソースを作成します。マップ実行とは、分散マップ状態によって開始する一連の子ワークフロー実行、およびこれらの実行をコントロールするランタイム設定を指します。Step Functions は、マップの実行に Amazon リソースネーム (ARN) を割り当てます。マップ実行は、Step Functions コンソールで確認できます。DescribeMapRunAPI アクションを呼び出すこともできます。Map Run の子ワークフロー実行は、メトリクスを に出力します CloudWatch。これらのメトリクスには、次の形式でラベル付けされたステートマシン ARN が含まれます。
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUID詳細については、「マップ実行の表示」を参照してください。
Distributed Map ステートの定義例 (JSONPath)
次の条件を満たす大規模な並列ワークロードをオーケストレーションする必要がある場合は、並列モードモードの Map 状態を使用します。
データセットのサイズが 256 KiB を超えている。
ワークフローの実行イベント履歴が 25,000 エントリを超えている。
40 回を超える並行イテレーションの同時実行が必要。
次の分散マップ状態の定義例では、データセットを Amazon S3 バケットに格納された CSV ファイルとして指定しています。また、CSV ファイルの各行のデータを処理する Lambda 関数も指定しています。この例では CSV ファイルを使用しているため、CSV 列ヘッダーの場所も指定しています。この例のステートマシン定義の詳細については、「分散マップを使用した大規模 CSV データのコピー」のチュートリアルを参照してください。
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}分散マップを実行するアクセス許可
ワークフローに分散マップ状態を含める場合、Step Functions には、ステートマシンのロールで分散マップ状態の StartExecution API アクションを呼び出すための適切な許可が必要です。
次の IAM ポリシー例では、ステートマシンのロールで分散マップ状態を実行するために必要な最小特権を付与しています。
注記
必ず stateMachineNamearn:aws:states:。region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
さらに、Amazon S3 バケットなど、分散マップ状態で使用される AWS リソースにアクセスするために必要な最小限の権限があることを確認する必要があります。詳細については、「分散マップ状態を使用するための IAM ポリシー」を参照してください。
分散マップ状態のフィールド
ワークフローで分散マップ状態を使用するには、これらのフィールドを 1 つ以上指定します。これらのフィールドは、共通状態フィールドに加えて指定します。
Type(必須)-
状態のタイプ (
Mapなど) を設定します。 ItemProcessor(必須)-
Map状態処理モードと定義を指定する次の JSON オブジェクトが含まれます。-
ProcessorConfig- 次のサブフィールドを使用して項目を処理するモードを指定する JSON オブジェクト。-
Mode-Map状態を分散モードで使用するにはDISTRIBUTEDに設定します。警告
分散モードは Standard ワークフローではサポートされていますが、Express ワークフローではサポートされていません。
-
ExecutionType- マップワークフローの実行タイプを [STANDARD] または [EXPRESS] のいずれかに指定します。DISTRIBUTEDをModeサブフィールドに指定した場合は、このフィールドを指定する必要があります。ワークフロータイプの詳細については、Step Functions でワークフロータイプを選択する を参照してください。
-
StartAt- ワークフローの最初の状態を示す文字列を指定します。この文字列は、大文字と小文字が区別され、いずれかの状態オブジェクトの名前と完全に一致する必要があります。この状態は、データセット内の各アイテムで最初に実行されます。Map状態に提供した実行入力は、まずStartAt状態に渡されます。States– カンマで区切られた一連の状態を含む JSON オブジェクト。このオブジェクトでは、Map workflowを定義します。
-
ItemReader-
データセットとその場所を指定します。
Map状態は指定されたデータセットから入力データを受け取ります。分散モードでは、以前の状態から渡された JSON ペイロードまたは大規模な Amazon S3 データソースのいずれかをデータセットとして使用できます。詳細については、「ItemReader (Map)」を参照してください。
Items(オプション、JSONata のみ)-
配列またはオブジェクトに対して評価する必要がある JSON 配列、JSON オブジェクト、または JSONata 式。
ItemsPath(オプション、JSONPath のみ)-
JsonPath
構文を使用して参照パスを指定し、項目の配列または状態入力内のキーと値のペアを持つオブジェクトを含む JSON ノードを選択します。 分散モードでは、前のステップの JSON 配列またはオブジェクトを状態入力として使用する場合にのみ、このフィールドを指定します。詳細については、「ItemsPath (マップ、JSONPath のみ)」を参照してください。
ItemSelector(オプション、JSONPath のみ)-
各
Map状態反復に渡される前に、個々のデータセットアイテムの値をオーバーライドします。このフィールドでは、キーと値のペアのコレクションを含む有効な JSON 入力を指定します。これらのペアは、ステートマシン定義で定義する静的な値でも、パスを使用して状態入力から選択された値でも、コンテキストオブジェクトからアクセスされる値でもかまいません。詳細については、「ItemSelector (Map)」を参照してください。
ItemBatcher(オプション)-
データセットアイテムの一括処理を指定します。子ワークフローを実行するたびに、入力としてこれらのバッチを受け取ります。詳細については、「ItemBatcher (Map)」を参照してください。
MaxConcurrency(オプション)-
並行して実行できる子ワークフローの実行数を指定します。インタープリタは、指定された回数までの子ワークフローの並行実行のみを許可します。同時実行値を指定しないか、0 に設定した場合、Step Functions は同時実行を制限せず、子ワークフローを 10,000 回並行実行します。JSONata ステートでは、整数として評価される JSONata 式を指定できます。
注記
並列子ワークフロー実行にはより高い同時実行制限を指定できますが、 などのダウンストリーム AWS サービスの容量を超えないようにすることをお勧めします AWS Lambda。
MaxConcurrencyPath(オプション、JSONPath のみ)-
リファレンスパスを使用して状態の入力からタイムアウト値を動的に最大同時実行値を指定する場合は、
MaxConcurrencyPathを使用してください。解決されると、リファレンスパスは、値が負でない整数のフィールドを選択する必要があります。注記
Map状態にはMaxConcurrencyとMaxConcurrencyPathの両方を含めることはできません。 ToleratedFailurePercentage(オプション)-
マップ実行で許容できる失敗項目の割合を定義します。この割合を超えると、マップ実行は自動的に失敗します。Step Functions は、失敗またはタイムアウトしたアイテムの総数をアイテムの総数で割った結果として、失敗したアイテムの割合を計算します。0 から 100 までの値を指定する必要があります。詳細については、「Step Functions での分散マップ状態の失敗しきい値の設定」を参照してください。
JSONata ステートでは、整数として評価される JSONata 式を指定できます。
ToleratedFailurePercentagePath(オプション、JSONPath のみ)-
リファレンスパスを使用して状態の入力から許容される失敗の割合の値を動的に指定したい場合は、
ToleratedFailurePercentagePathを使用してください。解決されると、リファレンスパスは、値が 0~100の フィールドを選択する必要があります。 ToleratedFailureCount(オプション)-
マップ実行で許容される障害アイテムの数を定義します。この数を超えると、マップ実行は自動的に失敗します。詳細については、「Step Functions での分散マップ状態の失敗しきい値の設定」を参照してください。
JSONata ステートでは、整数として評価される JSONata 式を指定できます。
ToleratedFailureCountPath(オプション、JSONPath のみ)-
リファレンスパスを使用して状態の入力から許容される失敗数の値を動的に指定したい場合は、
ToleratedFailureCountPathを使用してください。解決されると、リファレンスパスは、値が負でない整数のフィールドを選択する必要があります。 Label(オプション)-
Map状態を一意に識別する文字列。Step Functions は、マップ実行ごとにマップ実行 ARN にラベルを追加します。以下は、demoLabelという名前のカスタムラベルを持つマップ実行 ARN の例です。arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0bラベルを指定しない場合、Step Functions では一意のラベルが自動的に生成されます。
注記
ラベルは 40 文字を超える文字を含めることができず、1 台のステートマシン定義内で一意である必要があり、次の文字を含めることはできません。
-
空白
-
ワイルドカード文字 (
? *) -
角かっこ (
< > { } [ ]) -
特殊文字 (
: ; , \ | ^ ~ $ # % & ` ") -
制御文字 (
\\u0000-\\u001fまたは\\u007f-\\u009f)
Step Functions では、ステートマシン、実行、アクティビティ、ラベルに、ASCII 以外の文字を含む名前を使用できます。このような文字を使用すると Amazon CloudWatch がデータを記録できなくなるため、Step Functions のメトリクスを追跡できるように ASCII 文字のみを使用することをお勧めします。
-
ResultWriter(オプション)-
Step Functions がすべての子ワークフローの実行結果を書き込む Amazon S3 内の場所を指定します。
Step Functions は、実行の入出力、ARN、実行状態など、すべての子ワークフローの実行データを統合します。次に、指定した Amazon S3 の場所のそれぞれのファイルに、同じステータスの実行をエクスポートします。詳細については、「ResultWriter (Map)」を参照してください。
Map状態の結果をエクスポートしない場合、すべての子ワークフロー実行結果の配列が返されます。例えば、次のようになります。[1, 2, 3, 4, 5] ResultPath(オプション、JSONPath のみ)-
反復の出力を配置する入力内の場所を指定します。その後、入力は OutputPath フィールド (ある場合) に従ってフィルタリングされてから状態の出力として渡されます。詳細については、入力および出力処理を参照してください。
ResultSelector(オプション)-
値が静的であるか、結果から選択されたキーバリューのペアの集合を渡します。詳細については、「ResultSelector」を参照してください。
ヒント
ステートマシンで使用している並列またはマップステートが配列の配列を返す場合は、ResultSelector フィールドを使用して配列をフラットな配列に変換できます。詳細については、「配列の配列の平坦化」を参照してください。
Retry(オプション)-
Retrier と呼ばれるオブジェクトの配列。再試行ポリシーを定義します。状態でランタイムエラーが発生した場合、実行では再試行ポリシーが使用されます。詳細については、「Retry と Catch を使用するステートマシンの例」を参照してください。
注記
分散マップ状態に Retrier を定義すると、
Mapステートが開始したすべての子ワークフロー実行に再試行ポリシーが適用されます。例えば、Map状態で 3 つの子ワークフロー実行が開始され、そのうちの 1 つが失敗したとします。障害が発生すると、実行ではMap状態のRetryフィールド (定義されている場合) が使用されます。再試行ポリシーは、失敗した実行だけでなく、すべての子ワークフロー実行に適用されます。1 つ以上の子ワークフローの実行が失敗すると、マップ実行は失敗します。Map状態を再試行すると、新しいマップ実行が作成されます。 Catch(オプション)-
Catcher と呼ばれるオブジェクトの配列で、フォールバック状態を定義します。Step Functions は、状態で実行時エラーが発生した場合に、
Catchで定義されている Catcher を使用します。エラーが発生すると、実行は最初にRetryで定義されている Retrier を使用します。再試行ポリシーが定義されていないか使い果たされた場合、実行ではその Catcher (定義されている場合) を使用します。詳細については、「フォールバック状態」を参照してください。 Output(オプション、JSONata のみ)-
ステートからの出力を指定して変換するために使用します。指定すると、ステートのデフォルト出力がオーバーライドされます。
Output フィールドは、あらゆる型の JSON 値 (オブジェクト、配列、文字列、数値、boolean、null) を受け入れます。すべての文字列値は、オブジェクトや配列内の値を含め、{% %} 文字で囲まれていれば、JSONata として評価されます。
Output は JSONata 式を直接受け入れることもできます。例: "Output": "{% jsonata expression %}"
詳細については、「Step Functions での JSONata を使用したデータ変換」を参照してください。
-
Assign(オプション) -
変数を保存するために使用します。
Assignフィールドは、変数名とその割り当て値を定義するキーと値のペアを含む JSON オブジェクトを受け入れます。すべての文字列値は、オブジェクトや配列内の値を含め、{% %}文字で囲まれていれば、JSONata として評価されます。詳細については、「変数を使用したステート間のデータ受け渡し」を参照してください。
Step Functions での分散マップ状態の失敗しきい値の設定
大規模な並行ワークロードをオーケストレーションする場合、許容される失敗しきい値を定義することもできます。この値により、失敗したアイテムの最大数または割合をマップ実行の失敗しきい値として指定できます。指定した値によっては、しきい値を超えるとマップ実行が自動的に失敗します。両方の値を指定した場合、いずれかの値を超えるとワークフローは失敗します。
しきい値を指定すると、マップ実行全体が失敗する前に、特定の数の項目を失敗させることができます。Step Functions は、指定されたしきい値を超えたためにマップ実行が失敗すると States.ExceedToleratedFailureThreshold エラーを返します。
注記
Step Functions は、許容される失敗しきい値を超えた後でも、マップ実行が失敗する前に、マップ実行で子ワークフローを実行し続ける場合があります。
Workflow Studio でしきい値を指定するには、[ランタイム設定] フィールドの [追加設定] で [許容される失敗しきい値を設定] を選択します。
- 許容される失敗の割合
-
許容される失敗項目の割合を定義します。この値を超えるとマップ実行は失敗します。Step Functions は、失敗した項目またはタイムアウトした項目の合計数を項目の合計数で割った結果として、失敗した項目の割合を計算します。0 から 100 までの値を指定する必要があります。割合のデフォルトの値は 0 です。つまり、子ワークフローのいずれかの実行が失敗またはタイムアウトすると、ワークフローは失敗します。割合を 100 に指定すると、子ワークフローの実行がすべて失敗しても、ワークフローは失敗しません。
別の方法として、分散マップ状態の入力での既存のキーと値のペアへの参照パスとして割合を指定することもできます。このパスは、実行時に 0~100 の間の正の整数に変換されなければなりません。
ToleratedFailurePercentagePathサブフィールドに参照パスを指定します。例として、次の入力があるとします。
{"percentage":15}その入力への参照パスを使用して、次のように割合を指定できます。
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }重要
分散マップ状態の定義では、
ToleratedFailurePercentageまたはToleratedFailurePercentagePathのどちらかを指定できますが、両方は指定できません。 - 許容される失敗数
-
許容される失敗項目の数を定義します。この値を超えるとマップ実行は失敗します。
別の方法として、分散マップ状態の入力での既存のキーと値のペアへの参照パスとして数を指定することもできます。このパスは実行時に正の整数に変換されなければなりません。
ToleratedFailureCountPathサブフィールドに参照パスを指定します。例として、次の入力があるとします。
{"count":10}その入力への参照パスを使用して、次のように数を指定できます。
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }重要
分散マップ状態の定義では、
ToleratedFailureCountまたはToleratedFailureCountPathのどちらかを指定できますが、両方は指定できません。
分散マップの詳細
分散マップ状態の学習を続けるには、次のリソースを参照してください。
-
入力および出力処理
分散マップ状態が受け取る入力と生成される出力を設定するために、Step Functions には以下のフィールドが用意されています。
これらのフィールドに加えて、Step Functions では分散マップの許容障害しきい値を定義することもできます。この値により、失敗したアイテムの最大数または割合をマップ実行の失敗しきい値として指定できます。許容障害数のしきい値の設定の詳細については、「Step Functions での分散マップ状態の失敗しきい値の設定」を参照してください。
-
分散マップ状態の使用
分散マップ状態の使用を開始するには、以下のチュートリアルとサンプルプロジェクトを参照してください。
-
分散マップ状態の実行を調べる
Step Functions コンソールには、分散マップ状態実行に関連するすべての情報を表示する [マップ実行の詳細] ページがあります。このページに表示される情報を調べる方法については、「マップ実行の表示」を参照してください。
