翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
回復力に関する責任共有モデル
耐障害性は、 AWS とユーザーの間で共有される責任です。ディザスタリカバリ (DR) と可用性が回復力の一環として、この責任共有モデルにおいてどのように運用されるのかを理解することが重要です。
AWS 責任 - クラウドの耐障害性
AWS は、 で提供されるすべてのサービスを実行するインフラストラクチャの回復性を担当します AWS クラウド。このインフラストラクチャは、 AWS クラウド サービスを実行するハードウェア、ソフトウェア、ネットワーク、および施設で構成されます。 は、これらの AWS クラウド サービスを利用可能にするために商業的に合理的な努力を AWS 払い、サービスの可用性がAWS サービスレベルアグリーメント (SLAs)
AWS グローバルクラウドインフラストラクチャ
お客様の責任 - クラウドの回復力
お客様の責任は、選択した AWS クラウド サービスによって決まります。選択したサービスにより、お客様が回復力に関する責任の一環として実行する必要がある、設定作業の量が決まります。例えば、Amazon Elastic Compute Cloud (Amazon EC2) などのサービスでは、必要な耐障害性設定および管理タスクをすべて実行する必要があります。Amazon EC2インスタンスをデプロイするお客様は、複数のロケーション (アベイラビリティーゾーンなど) に Amazon EC2インスタンスをデプロイし、Auto Scaling などの サービスを使用して自己修復を実装し、インスタンスにインストールされたアプリケーションの回復力のあるワークロードアーキテクチャのベストプラクティスを使用する責任があります。 AWS Amazon S3 や Amazon DynamoDB などのマネージドサービスの場合、 はインフラストラクチャレイヤー、オペレーティングシステム、プラットフォーム AWS を操作し、顧客はエンドポイントにアクセスしてデータを保存および取得します。お客様は、バックアップ、バージョニング、レプリケーション戦略など、データの回復力を管理する責任があります。
の複数のアベイラビリティーゾーンにワークロードをデプロイすることは、問題を 1 つのアベイラビリティーゾーンに分離してワークロードを保護するように設計された高可用性戦略の一部 AWS リージョン です。このアベイラビリティーゾーンは、他のアベイラビリティーゾーンの冗長性を使用してリクエストを処理し続けます。マルチ AZ アーキテクチャは、ワークロードをより適切に分離し、停電、落雷、竜巻、地震などの問題から保護するように設計された DR 戦略の一環でもあります。DR 戦略として、複数の AWS リージョンを利用することもできます。例えば、アクティブ/パッシブ設定では、アクティブなリージョンがリクエストを処理できなくなった場合に、ワークロードのサービスはアクティブなリージョンから DR リージョンにフェイルオーバーします。
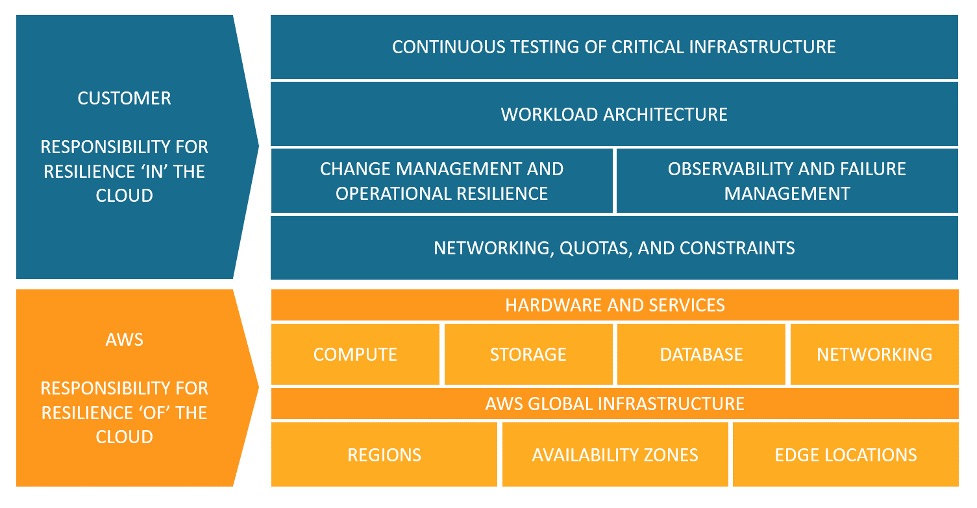
お客様と AWSの、クラウド内およびクラウドの回復力に対する責任。
AWS サービスを使用して、耐障害性目標を達成できます。お客様は、システムの以下の側面を管理して、クラウド内の回復力を実現する責任を負います。特定の各サービスの詳細については、「AWS のドキュメント」を参照してください。
ネットワーキング、クォータ、制約
-
この分野の責任共有モデルのベストプラクティスについては、「基礎」で詳しく説明しています。
-
必要に応じて、含めるサービスの Service Quotas と制約を把握し、予想される負荷リクエストの増加に基づいて、スケーリングのための十分な余裕を持ってアーキテクチャを計画します。
-
可用性、冗長性、スケーラビリティに優れたネットワークトポロジを設計します。
変更管理と運用上の回復力
-
変更管理には、環境に変更を導入および管理する方法が含まれます。変更を実装するには、ランブックを構築し、アプリケーションとインフラストラクチャのデプロイ戦略を最新の状態に保つ必要があります。
-
ワークロードリソースをモニタリングするための回復力のある戦略では、技術メトリクスとビジネスメトリクス、通知、自動化、分析を含むすべてのコンポーネントを考慮します。
-
クラウド内のワークロードは、使用量の減損や変動に伴う需要のスケーリングの変化に適応する必要があります。
オブザーバビリティ管理と障害管理
-
ワークロードがコンポーネントの障害に耐えられるようにヒーリングを自動化するには、モニタリングによる障害の監視が必要です。
-
障害管理には、データのバックアップ、ワークロードがコンポーネントの障害に耐えられるようにするためのベストプラクティスの適用、ディザスタリカバリの計画が必要です。
ワークロードアーキテクチャ
-
ワークロードアーキテクチャには、ビジネスドメインを中心にサービスを設計する方法、障害を防ぐためにシステム設計を適用SOAして分散する方法、スロットリング、再試行、キュー管理、タイムアウト、緊急レバーなどの機能を組み込みます。
-
ベストプラクティスとジャンプスタートの実装に合わせて、実証済みの AWS ソリューション
、Amazon Builders Library 、サーバーレスパターン を活用します。 -
継続的な改善を採用すると、システムを分散サービスに分解し、スケーリングとイノベーションを加速できます。AWS マイクロサービス
ガイダンスとマネージドサービスオプションを使用して、変更とイノベーションを導入する能力を簡素化し、高速化します。
重要なインフラストラクチャの継続的テスト
-
信頼性のテストでは、機能レベル、パフォーマンスレベル、カオスレベルでのテストと、インシデント分析とゲームデープラクティスを採用して、十分に把握していない問題を解決するための専門知識を構築します。
-
すべてをクラウドに移行した (オールイン) アプリケーションとハイブリッドアプリケーションの両方で、問題発生時やコンポーネントの停止時にアプリケーションがどのように動作するかを把握しておくと、停止から迅速かつ確実に復旧できます。
-
繰り返し可能な実験を作成し、文書化して、期待どおりにいかない場合にシステムがどのように動作するかを把握しておきます。このようなテストは、全体的な回復力の有効性を証明するものであり、実際の障害シナリオに直面する前に、運用手順のフィードバックループを提供します。
