翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
フィルター式の使用
フィルター式を使用して、特定のリクエスト、サービス、2 つのサービス間の接続 (エッジ)、または条件を満たすリクエストのトレースマップまたはトレースを表示できます。X-Ray にはフィルタ式言語があり、リクエストヘッダー、レスポンスステータス、元セグメントのインデックス付きフィールドのデータに基づいて、リクエスト、サービス、エッジをフィルタリングできます。
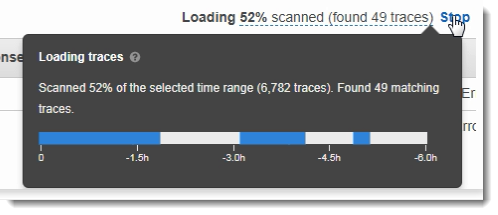
X-Ray コンソールで表示するトレースの期間を選択すると、コンソールが表示できる以上の結果が得られることがあります。右上隅には、スキャンしたトレースの数と使用可能なトレースが他にもあるかどうかがコンソールに表示されます。フィルター式を使用して、検索するトレースだけに結果を絞り込むことができます。
フィルタ式の詳細
トレースマップのノードを選択すると、コンソールはノードのサービス名と選択に基づいて、存在するエラーのタイプに基づいてフィルター式を構成します。パフォーマンスの問題を示すトレースや特定のリクエストに関連するトレースを見つけるには、コンソールが提供する式を調整するか、独自の式を作成します。X-Ray SDK で注釈を追加する場合は、注釈キーまたはキーの値に基づいてフィルターを適用することもできます。
注記
トレースマップで相対的な時間範囲を選択し、ノードを選択した場合、コンソールによって時間範囲が絶対開始時刻と終了時刻に変換されます。ノードのトレースが検索結果に確実に表示され、ノードがアクティブでないときのスキャン時間を避けるために、時間範囲にはノードがトレースを送信した時間だけが含まれます。現在の時刻を基準にして検索するには、トレースページで相対的な時間範囲に戻って再度スキャンすることができます。
コンソールが表示できるものより多くの結果がまだある場合、コンソールには一致したトレースの数とスキャンされたトレースの数が表示されます。表示される割合は、スキャンされた選択済みの時間枠の割合です。結果に表示されているすべての一致するトレースを確認するには、フィルタ式をさらに絞り込むか、より短い時間枠を選択します。
一番新しい結果を得るために、コンソールは時間範囲の終わりにスキャンを開始し、逆方向に動作します。多数のトレースがあるが結果が少ない場合、コンソールは時間範囲をチャンクに分割し、それらを並行してスキャンします。進行状況バーには、スキャンされた時間範囲の一部が表示されます。
グループでフィルタ式を使用する
グループは、フィルタ式で定義されるトレースのコレクションです。グループを使用して、追加のサービスグラフを生成し、Amazon CloudWatch メトリクスを指定できます。
グループは名前または Amazon リソースネーム (ARN) で識別され、フィルタ式を含みます。サービスは着信トレースを式と比較し、それに応じてそれらを保管します。
フィルタ式検索バーの左側にあるドロップダウンメニューを使用して、グループを作成および変更できます。
注記
グループの認定中に、サービスでエラーが検出された場合、そのグループは着信トレースの処理に含まれなくなり、エラーメトリクスが記録されます。
グループの詳細については、グループの設定を参照してください。
フィルタ式の構文
フィルタ式にキーワード、単項またはバイナリの演算子、値を追加して比較することができます。
keyword operator value演算子が異なる場合は、異なるタイプのキーワードを使用できます。たとえば、responsetime は、数値型キーワードを指し、数値に関する演算子と比較することができます。
例- 応答時間が 5 秒を超えたリクエスト
responsetime > 5AND 演算子および OR 演算子を使用して、複合式内で複数の式を結合できます。
例- 総所要時間が 5〜8 秒のリクエスト
duration >= 5 AND duration <= 8キーワードおよび演算子をシンプルにすると、トレースレベルでのみ問題を見つけることができます。エラーによってダウンロードが発生したが、アプリケーションによって処理され、ユーザーに返らない場合、error の検索では見つけることができません。
ダウンストリームの問題があるトレースを見つけるには、「複合型キーワード」、service()、および edge() を使用できます。これらのキーワードを使用して、すべてのダウンストリームノード、単一のダウンストリームノード、または 2 つのノード間のエッジにフィルタ式を適用することができます。さらに詳細にする場合は、「id() 関数」を使用して、タイプごとにサービスおよびエッジをフィルタリングすることができます。
ブール型キーワード
ブール値のキーワード値は true または false です。これらのキーワードを使用して、エラーの原因となったトレースを見つけます。
ブール型キーワード
-
ok- レスポンスステータスコードは 2XX Success でした。 -
error- レスポンスステータスコードは 4XX Client Error でした。 -
throttle- レスポンスステータスコードは 429 Too Many Requests でした。 -
fault- レスポンスステータスコードは 5XX Server Error でした。 -
partial- リクエスト内に不完全なセグメントがあります。 -
inferred- リクエスト内に推定セグメントがあります。 -
first- 要素は列挙リストの最初です。 -
last- 要素は列挙リストの最後です。 -
remote- 根本原因のエンティティがリモートです。 -
root- サービスはエントリポイント、またはトレースのルートセグメントです。
ブール演算子は、指定されたキーが true または false のセグメントを見つけます。
ブール演算子
-
none - キーワードが true の場合、式は true と評価されます。
-
!- キーワードが false の場合、式は true と評価されます。 -
=,!=- キーワードの値を文字列trueまたはfalseと比較します。これらの演算子は、他の演算子と同じように動作しますが、より明示的です。
例- レスポンスステータスが 2XX OK である
ok例- レスポンスステータスが 2XX OK ではない
!ok例- レスポンスステータスが 2XX OK ではない
ok = false例- 最後の列挙障害トレースにエラー名「逆シリアル化」がある
rootcause.fault.entity { last and name = "deserialize" }例- カバレッジが 0.7 より大きく、サービス名が「トレース」であるリモートセグメントを持つリクエスト
rootcause.responsetime.entity { remote and coverage > 0.7 and name = "traces" }例- サービスタイプが「AWS:DynamoDB」の推定セグメントがあるリクエスト
rootcause.fault.service { inferred and name = traces and type = "AWS::DynamoDB" }例- ルートとして「data-plane」という名前のセグメントのあるリクエスト
service("data-plane") {root = true and fault = true}数値型キーワード
数値型キーワードを使用して、特定の応答時間、期間、応答ステータスを含むリクエストを検索します。
数値型キーワード
-
responsetime- サーバーでレスポンスの送信に要した時間。 -
duration- すべてのダウンストリーム呼び出しを含むリクエスト総所要時間。 -
http.status- レスポンスステータスコード。 -
index- 列挙リスト内の要素の位置。 -
coverage- ルートセグメントの応答時間に対するエンティティの応答時間の 10 進数の割合。応答時間の根本原因のエンティティにのみ適用されます。
数値型演算子
数値型キーワードでは、標準の品質と比較演算子を使用しています。
-
=,!=- キーワードが数値と同等か、等しくない。 -
<、<=、>、>=– キーワードが数値より小さい、または大きい。
例- レスポンスステータスが 200 OK ではない
http.status != 200例- 総所要時間が 5〜8 秒のリクエスト
duration >= 5 AND duration <= 8例- すべてのダウンストリーム呼び出しを含めて 3 秒未満で正常に完了したリクエスト
ok !partial duration <3例- 5 より大きいインデックスを持つ列挙型リストエンティティ
rootcause.fault.service { index > 5 }例- 最後のエンティティが 0.8 より大きいカバレッジを持つリクエスト
rootcause.responsetime.entity { last and coverage > 0.8 }文字列型キーワード
文字列型キーワードを使用すると、リクエストヘッダーに特定のテキストを含むトレースや特定のユーザー ID のトレースを見つけることができます。
文字列型キーワード
-
http.url- リクエストの URL。 -
http.method- リクエストメソッド。 -
http.useragent- リクエストのユーザーエージェント文字列。 -
http.clientip- リクエスタの IP アドレス。 -
user- Trace の任意の セグメント におけるユーザーフィールドの値。 -
name- サービスの名前、または例外。 -
type- サービスタイプ。 -
message- 例外メッセージ。 -
availabilityzone- トレース内の任意のセグメントのアベイラビリティーゾーンフィールドの値。 -
instance.id- トレース内の任意のセグメントのインスタンス ID フィールドの値。 -
resource.arn- トレース内の任意のセグメントのリソース ARN フィールドの値。
文字列演算子は、特定のテキストと一致する値、または特定のテキストを含む値を見つけます。値は、必ず引用符で囲います。
文字列演算子
-
=,!=- キーワードが数値と同等か、等しくない。 -
CONTAINS- キーワードに特定の文字列が含まれている。 -
BEGINSWITH,ENDSWITH- キーワードが特定の文字列で始まる、または終わる。
例- Http.url フィルター
http.url CONTAINS "/api/game/"フィールドがトレースに存在するかどうかをテストするには、その値に関係なく、空の文字列が含まれているかどうかを確認します。
例- ユーザー フィルター
ユーザー ID を持つすべてのトレースを見つけます。
user CONTAINS ""例- 「Auth」という名前のサービスを含む、障害の根本原因を含むトレースの選択
rootcause.fault.service { name = "Auth" }例- 最後のサービスに DynamoDB タイプがある応答時間の根本原因を含むトレースの選択
rootcause.responsetime.service { last and type = "AWS::DynamoDB" }例- 最後の例外に「account_id:1234567890 のアクセスが拒否されました」というメッセージのある障害の根本原因を含むトレースの選択
rootcause.fault.exception { last and message = "Access Denied for account_id: 1234567890" 複合型キーワード
複雑なキーワードを使用し、サービス名、エッジ名、または注釈値に基づいてリクエストを見つけます。サービスとエッジについては、サービスまたはエッジに適用される追加のフィルタ式を指定できます。注釈では、ブール値、数値、または文字列演算子を使用して、特定のキーで注釈の値をフィルタリングできます。
複合型キーワード
-
annotation[- フィールドkey][key](キー)の注釈の値。注釈の値は、ブール値、数値、文字列のいずれかであるため、このタイプの比較演算子のいずれも使用することができます。このキーワードはserviceまたはedgeキーワードと組み合わせて使用することができます。ドット (ピリオド) を含む注釈キーは角かっこで囲む必要があります ([ ])。 -
edge(-source,destination) {filter}[source](ソース)サービスと[destination](宛先) サービス間の接続。オプションの中括弧には、この接続のセグメントに適用されるフィルタ式を含めることができます。 -
group.— グループ名またはグループ ARN で参照されるグループのフィルター式の値。name/ group.arn -
json- JSON 根本原因オブジェクト。プログラムで JSON エンティティを作成する手順については、AWS 「X-Ray からデータを取得する」を参照してください。 -
service(- 名前がname) {filter}[name]のサービス。オプションの中括弧には、サービスで作成されたセグメントに適用されるフィルタ式を含めることができます。
サービスのキーワードを使用して、トレースマップの特定のノードにヒットするリクエストのトレースを見つけます。
複合型キーワード演算子は、指定されたキーが設定されている、または設定されていないセグメントを見つけます。
複合型キーワード演算子
-
none - キーワードが 設定されている場合、式は true と評価されます。キーワードがブール型の場合は、ブール値として評価されます。
-
!- キーワードが setでない場合、式は true と評価されます。キーワードがブール型の場合は、ブール値として評価されます。 -
=,!=— キーワードの値を比較します。 -
edge(-source,destination) {filter}[source](ソース) サービスと[destination](宛先) サービス間の接続。オプションの中括弧には、この接続のセグメントに適用されるフィルタ式を含めることができます。 -
annotation[- フィールドkey][key](キー)の注釈の値。注釈の値は、ブール値、数値、文字列のいずれかであるため、このタイプの比較演算子のいずれも使用することができます。このキーワードはserviceまたはedgeキーワードと組み合わせて使用することができます。 -
json- JSON 根本原因オブジェクト。プログラムで JSON エンティティを作成する手順については、AWS 「X-Ray からデータを取得する」を参照してください。
サービスのキーワードを使用して、トレースマップの特定のノードにヒットするリクエストのトレースを見つけます。
例- サービスフィルター
障害 (500 シリーズのエラー) が発生した api.example.com の呼び出しを含んだリクエスト。
service("api.example.com") { fault }サービス名を除外して、フィルタ式をサービスマップのすべてのノードに適用することができます。
例- サービスフィルター
トレースマップの任意の場所で障害が発生したリクエスト。
service() { fault }エッジキーワードは、フィルタ式を 2 つのノード間の接続に適用します。
例- エッジ フィルター
サービス api.example.com から backend.example.com への呼び出しが失敗してエラーが発生したリクエスト。
edge("api.example.com", "backend.example.com") { error }また、サービスまたはエッジのキーワードを含む ! 演算子を使用して、サービスまたはエッジを他のフィルタ式の結果から除外することもできます。
例- サービスおよびリクエスト フィルター
URL が http://api.example.com/ で始まって /v2/ を含むが、api.example.com という名前のサービスに達しないリクエスト。
http.url BEGINSWITH "http://api.example.com/" AND http.url CONTAINS "/v2/" AND !service("api.example.com")例— サービスと応答時間のフィルター
http url が設定され、応答時間が 2 秒を超えているトレースを見つけてください。
http.url AND responseTime > 2注釈について、annotation[ が設定されているか、値のタイプに対応する比較演算子を使用しているかすべてのトレースを呼び出すことができます。key]
例- 文字列値を含む注釈
文字列値 gameid の "817DL6VO" という名前のリクエスト。
annotation[gameid] = "817DL6VO"例— 注釈が設定されている
age 設定という名前の注釈を持つリクエスト。
annotation[age]例— 注釈が設定されていません
age 設定という名前の注釈のないリクエスト。
!annotation[age]例- 数値を含む注釈
アノテーション期間が数値 29 より大きいリクエスト。
annotation[age] > 29例– サービスまたはエッジと組み合わせた注釈
service { annotation[request.id] = "917DL6VO" }edge { source.annotation[request.id] = "916DL6VO" }edge { destination.annotation[request.id] = "918DL6VO" }例— ユーザーとグループ化
トレースがhigh_response_time グループフィルター (例:responseTime > 3) を満たし、ユーザーの名前が Alice のリクエスト。
group.name = "high_response_time" AND user = "alice"例- 根本原因のエンティティを含む JSON
根本原因エンティティが一致するリクエスト
rootcause.json = #[{ "Services": [ { "Name": "GetWeatherData", "EntityPath": [{ "Name": "GetWeatherData" }, { "Name": "get_temperature" } ] }, { "Name": "GetTemperature", "EntityPath": [ { "Name": "GetTemperature" } ] } ] }]id 関数
service または edge のキーワードにサービス名を入力すると、そのサービス名を含むすべてのノードの結果が得られます。詳細にフィルタリングする場合は、id 関数を使用してサービスのタイプと名前を指定し、同一名を持つノードを区別することができます。
モニタリングアカウント内の複数のアカウントのトレースを表示する場合、account.id 関数を使用してサービスの特定のアカウントを指定します。
id(name: "service-name", type:"service::type", account.id:"account-ID")サービスフィルタおよびエッジフィルタで、サービス名ではなく、id 関数を使用することもできます。
service(id(name: "service-name", type:"service::type")) { filter }edge(id(name: "service-one", type:"service::type"), id(name: "service-two", type:"service::type")) { filter }たとえば、 AWS Lambda 関数はトレースマップに 2 つのノードを作成します。1 つは関数の呼び出し用、もう 1 つは Lambda サービス用です。この 2 つのノードは同じ名前ですが、タイプが異なります。標準サービスフィルタは、両ノードのトレースを見つけます。
例- サービスフィルター
random-name という名前を持つすべてのサービスにエラーを含むリクエスト。
service("random-name") { error }id 関数を使用して、関数そのもののエラーを絞り込み、サービスからエラーを除外します。
例- id 関数を使用したサービスフィルター
サービスタイプが random-name の AWS::Lambda::Function という名前のサービスにエラーを含むリクエスト。
service(id(name: "random-name", type: "AWS::Lambda::Function")) { error }タイプ別にノードを検索するには、名前を完全に除外します。
例– id 関数とサービスタイプを使用したサービスフィルター
サービスタイプが AWS::Lambda::Function のサービスにエラーを含むリクエスト。
service(id(type: "AWS::Lambda::Function")) { error }特定のノードを検索するには AWS アカウント、アカウント ID を指定します。
例– id 関数とアカウント ID を使用したサービスフィルター
特定のアカウント ID AWS::Lambda::Function 内のサービスを含むリクエスト。
service(id(account.id: "account-id"))