Aurora Serverless v2의 성능 및 크기 조정
다음 프로시저와 예는 Aurora Serverless v2 클러스터 및 연결된 DB 인스턴스의 용량 범위를 설정하는 방법을 보여줍니다. 다음 프로시저를 사용하여 DB 인스턴스의 사용량을 모니터링할 수도 있습니다. 그런 다음 결과를 사용하여 용량 범위를 상향 조정해야 하는지 하향 조정해야 하는지 결정할 수 있습니다.
이 프로시저를 사용하기 전에 Aurora Serverless v2 크기 조정이 작동하는 방식을 잘 알고 있어야 합니다. 크기 조정 메커니즘은 Aurora Serverless v1과 다릅니다. 자세한 내용은 Aurora Serverless v2 크기 조정 페이지을 참조하세요.
목차
Aurora 클러스터의 Aurora Serverless v2 용량 범위 선택
Aurora Serverless v2 DB 인스턴스를 사용하면 DB 클러스터에 첫 번째 Aurora Serverless v2 DB 인스턴스를 추가하는 동시에 DB 클러스터의 모든 DB 인스턴스에 적용되는 용량 범위를 설정합니다. 이러한 절차는 클러스터의 Aurora Serverless v2 용량 설정 페이지를 참조하세요.
기존 클러스터의 용량 범위도 변경할 수 있습니다. 다음 섹션에서는 적절한 최소값과 최대값을 선택하는 방법과 용량 범위를 변경하면 어떻게 되는지 자세히 설명합니다. 예를 들어 용량 범위를 변경하면 일부 구성 파라미터의 기본값을 수정할 수 있습니다. 모든 파라미터 변경 사항을 적용하려면 각 Aurora Serverless v2 DB 인스턴스를 재부팅해야 할 수 있습니다.
주제
클러스터에 대한 최소 Aurora Serverless v2 용량 설정 선택
최소한으로 Aurora Serverless v2 용량 설정으로 항상 0.5를 선택하는 것이 좋습니다. 이 값을 사용하면 DB 인스턴스가 완전히 유휴 상태일 때 가장 많이 축소할 수 있습니다. 그러나 해당 클러스터를 사용하는 방법과 구성하는 기타 설정에 따라 가장 효과적인 값은 다를 수도 있습니다. 최소 용량 설정을 선택할 때는 다음 요소를 고려하세요.
-
Aurora Serverless v2 DB 인스턴스의 크기 조정 비율은 현재 용량에 따라 다릅니다. 현재 용량이 높을수록 더 빠르게 확장할 수 있습니다. DB 인스턴스를 매우 높은 용량으로 빠르게 확장해야 하는 경우 크기 조정 속도가 요구 사항을 충족하는 값으로 최소 용량을 설정하는 것이 좋습니다.
-
일반적으로 특히 높거나 낮은 워크로드를 예상하여 DB 인스턴스의 DB 인스턴스 클래스를 수정하는 경우 해당 경험을 사용하여 동등한 Aurora Serverless v2 용량 범위를 대략적으로 추정할 수 있습니다. 트래픽이 적은 시간에 사용할 메모리 크기를 결정할 때는 Aurora에 대한 DB 인스턴스 클래스의 하드웨어 사양 페이지를 참조하세요.
예를 들어 클러스터의 워크로드가 낮은 경우 db.r6g.xlarge DB 인스턴스 클래스를 사용한다고 가정합니다. 해당 DB 인스턴스 클래스에는 32GiB의 메모리가 있습니다. 따라서 최소 Aurora 용량 단위(ACU) 설정을 16으로 지정하여 거의 동일한 용량으로 축소할 수 있는 Aurora Serverless v2 DB 인스턴스를 설정할 수 있습니다. 이는 각 ACU가 약 2GiB의 메모리에 해당하기 때문입니다. db.r6g.xlarge DB 인스턴스가 때때로 충분히 활용되지 않는 경우에 대비하여 DB 인스턴스가 더 축소되도록 약간 더 낮은 값을 지정할 수 있습니다.
-
DB 인스턴스의 버퍼 캐시에 일정량의 데이터가 있을 때 애플리케이션이 가장 효율적으로 작동하는 경우 메모리가 자주 액세스하는 데이터를 저장할 수 있을 만큼 충분히 큰 최소 ACU 설정을 지정하는 것이 좋습니다. 그렇지 않으면 Aurora Serverless v2 DB 인스턴스가 더 낮은 메모리 크기로 축소될 때 버퍼 캐시에서 일부 데이터가 제거됩니다. 그런 다음 DB 인스턴스가 다시 확장되면 시간이 지남에 따라 정보가 버퍼 캐시로 다시 읽혀집니다. 데이터를 버퍼 캐시로 다시 가져오기 위한 I/O 양이 많은 경우 최소 ACU 값을 높이는 것이 더 효과적일 수 있습니다.
-
Aurora Serverless v2 DB 인스턴스가 특정 용량에서 대부분 실행되는 경우 해당 기준보다 낮지만 너무 낮지 않은 최소 용량 설정을 지정하는 것이 좋습니다. Aurora Serverless v2 DB 인스턴스는 현재 용량이 필요한 용량보다 크게 낮지 않은 경우 확장할 양과 속도를 가장 효과적으로 추정할 수 있습니다.
-
프로비저닝된 워크로드에 T3 또는 T4g와 같은 소규모 DB 인스턴스 클래스에 비해 너무 높은 메모리 요구 사항이 있는 경우 R5 또는 R6g DB 인스턴스에 필적하는 메모리를 제공하는 최소 ACU 설정을 선택합니다.
특히 지정된 기능과 함께 사용하려면 다음과 같은 최소 용량을 권장합니다(이 권장 사항은 변경될 수 있음).
-
성능 개선 도우미— 2 ACU
-
Aurora 글로벌 데이터베이스 - 8 ACU(기본 AWS 리전에만 적용)
-
-
경우에 따라 클러스터에 라이터와 독자적으로 확장되는 Aurora Serverless v2 리더 DB 인스턴스가 포함될 수 있습니다. 그렇다면 라이터 DB 인스턴스가 쓰기 집약적인 워크로드로 바쁠 때 리더 DB 인스턴스가 뒤처지지 않고 라이터의 변경 사항을 적용할 수 있을 만큼 충분히 높은 최소 용량 설정을 선택하세요. 프로모션 티어 2~15에 있는 리더에서 복제본 지연이 관찰되면 클러스터의 최소 용량 설정을 늘리는 것이 좋습니다. 리더 DB 인스턴스가 라이터와 함께 또는 독자적으로 확장되는지를 선택하는 방법에 대한 자세한 내용은 Aurora Serverless v2 리더에 대한 승격 티어 선택 페이지를 참조하세요.
-
Aurora Serverless v2 리더 DB 인스턴스가 있는 DB 클러스터가 있는 경우, 리더의 승격 티어가 0 또는 1이 아니면 리더는 라이터 DB 인스턴스와 함께 조정되지 않습니다. 이 경우 최소 용량을 낮게 설정하면 과도한 복제 지연이 발생할 수 있습니다. 데이터베이스가 사용 중일 때 리더의 용량이 라이터의 변경 사항을 적용하기에 충분하지 않을 수 있기 때문입니다. 최소 용량을 라이터 DB 인스턴스와 비슷한 메모리 및 CPU 용량을 나타내는 값으로 설정하는 것이 좋습니다.
-
Aurora Serverless v2 DB 인스턴스의
max_connections파라미터 값은 최대 ACU에서 파생된 메모리 크기를 기반으로 합니다. 하지만 PostgreSQL 호환 DB 인스턴스의 최소 용량을 0.5ACU로 지정하면max_connections의 최대 용량을 2,000으로 제한됩니다.연결이 높은 워크로드에 Aurora PostgreSQL 클러스터를 사용하려는 경우 최소 ACU 설정을 1 이상으로 사용하는 것이 좋습니다. Aurora Serverless v2가
max_connections구성 파라미터를 처리하는 방법에 대한 자세한 내용은 Aurora Serverless v2의 최대 연결 수 페이지를 참조하세요. -
Aurora Serverless v2 DB 인스턴스가 최소 용량에서 최대 용량으로 확장되는 데 걸리는 시간은 최소 ACU 값과 최대 ACU 값의 차이에 따라 다릅니다. DB 인스턴스의 현재 용량이 클 때 Aurora Serverless v2는 DB 인스턴스가 작은 용량에서 시작할 때보다 더 큰 증분으로 크기를 확장합니다. 따라서 상대적으로 큰 최대 용량을 지정하고 DB 인스턴스가 해당 용량 근처에서 대부분의 시간을 보내는 경우 최소 ACU 설정을 높이는 것이 좋습니다. 이렇게 하면 유휴 DB 인스턴스가 더 빠르게 최대 용량까지 다시 확장할 수 있습니다.
클러스터의 최대 Aurora Serverless v2 용량 설정 선택
최대 Aurora Serverless v2 용량 설정에 대해 항상 높은 값을 선택하는 것이 좋습니다. 최대 용량이 크면 DB 인스턴스가 집약적인 워크로드를 실행할 때 가장 많이 확장할 수 있습니다. 낮은 값은 예기치 않은 요금의 가능성을 방지합니다. 해당 클러스터를 사용하는 방법과 구성하는 기타 설정에 따라 가장 효과적인 값은 원래 생각했던 것보다 높거나 낮을 수 있습니다. 최대 용량 설정을 선택할 때는 다음 요소를 고려하세요.
-
최대 용량은 최소 용량보다는 커야 합니다. 최대 및 최소 용량은 동일하게 설정할 수 있습니다. 그러나 이 경우 용량은 절대 확장하거나 축소되지 않습니다. 따라서 최소 및 최대 용량에 대해 동일한 값을 사용하는 것은 테스트 상황 외에는 적절하지 않습니다.
-
최대 용량은 0.5ACU보다 커야 합니다. 대부분의 경우 최소 및 최대 용량을 동일하게 설정할 수 있습니다. 단, 최소값과 최대값 모두에 0.5를 지정할 수는 없습니다. 최대 용량은 값 1 이상이어야 합니다.
-
일반적으로 특히 높거나 낮은 워크로드를 예상하여 DB 인스턴스의 DB 인스턴스 클래스를 수정하는 경우 해당 경험을 사용하여 동등한 Aurora Serverless v2 용량 범위를 추정할 수 있습니다. 트래픽이 많은 시간에 사용할 메모리 크기를 결정하려면 Aurora에 대한 DB 인스턴스 클래스의 하드웨어 사양 페이지를 참조하세요.
예를 들어 클러스터의 워크로드가 높은 경우 db.r6g.4xlarge DB 인스턴스 클래스를 사용한다고 가정합니다. 해당 DB 인스턴스 클래스에는 128GiB의 메모리가 있습니다. 따라서 최대 ACU 설정을 64로 지정하여 거의 동일한 용량으로 확장할 수 있는 Aurora Serverless v2 DB 인스턴스를 설정할 수 있습니다. 이는 각 ACU가 약 2GiB의 메모리에 해당하기 때문입니다. db.r6g.4xlarge DB 인스턴스에 워크로드를 효과적으로 처리할 수 있는 용량이 충분하지 않은 경우에 대비하여 DB 인스턴스를 더 확장할 수 있도록 다소 높은 값을 지정할 수 있습니다.
-
데이터베이스 사용량에 대한 예산 상한이 있는 경우 모든 Aurora Serverless v2 DB 인스턴스가 항상 최대 용량으로 실행되더라도 해당 상한 내에서 유지되는 값을 선택하세요. 클러스터에 n Aurora Serverless v2 DB 인스턴스가 있는 경우 클러스터가 언제든지 사용할 수 있는 이론상 최대 B1 용량은 Aurora Serverless v2n에 클러스터의 최대 ACU 설정을 곱한 것입니다. (예를 들어 일부 리더가 라이터와 독자적으로 확장하는 경우 실제 소비량은 더 적을 수 있습니다.)
-
Aurora Serverless v2 리더 DB 인스턴스를 사용하여 라이터 DB 인스턴스에서 읽기 전용 워크로드의 일부를 오프로드하는 경우 더 낮은 최대 용량 설정을 선택할 수 있습니다. 클러스터에 단일 DB 인스턴스만 포함되어 있는 것처럼 각 리더 DB 인스턴스를 높게 확장할 필요가 없음을 반영하기 위해 이 작업을 수행합니다.
-
애플리케이션에서 잘못 구성된 데이터베이스 파라미터터 또는 비효율적인 쿼리로 인한 과도한 사용을 방지하는 경우를 가정해 보겠습니다. 이 경우 설정할 수 있는 절대 최대값보다 낮은 최대 용량 설정을 선택하여 우발적인 남용을 방지할 수 있습니다.
-
실제 사용자 활동으로 인한 스파이크가 드물지만 발생하는 경우 최대 용량 설정을 선택할 때 이러한 경우를 고려할 수 있습니다. 애플리케이션이 전체 성능과 확장성을 유지하여 계속 실행하는 것이 우선 순위인 경우 정상 사용에서 관찰되는 것보다 더 높은 최대 용량 설정을 지정할 수 있습니다. 활동이 극도로 급증하는 동안 애플리케이션이 감소된 처리량으로 실행되는 것이 괜찮다면 약간 더 낮은 최대 용량 설정을 선택할 수 있습니다. 애플리케이션을 계속 실행하기에 충분한 메모리와 CPU 리소스가 있는 설정을 선택했는지 확인하세요.
-
클러스터에서 각 DB 인스턴스의 메모리 사용량을 늘리는 설정을 켜면 최대 ACU 값을 결정할 때 해당 메모리를 고려합니다. 이러한 설정에는 성능 개선 도우미, Aurora MySQL 병렬 쿼리, Aurora MySQL 성능 스키마 및 Aurora MySQL 바이너리 로그 복제에 대한 설정이 포함됩니다. 최대 ACU 값이 Aurora Serverless v2 DB 인스턴스가 해당 기능이 사용 중일 때 워크로드를 처리할 수 있을 만큼 충분히 확장할 수 있도록 허용하는지 확인하세요. 낮은 최대 ACU 설정과 메모리 오버헤드를 부과하는 Aurora 기능의 조합으로 인해 발생하는 문제 해결에 대한 정보는 메모리 부족 오류 방지 페이지를 참조하세요.
예: Aurora MySQL 클러스터의 Aurora Serverless v2 용량 범위 변경
다음 AWS CLI 예제는 기존 Aurora MySQL 클러스터에서 Aurora Serverless v2 DB 인스턴스의 ACU 범위를 업데이트하는 방법을 보여줍니다. 처음에 클러스터의 용량 범위는 8~32 ACU였습니다.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
DB 인스턴스는 유휴 상태이며 8 ACU로 축소됩니다. 이 시점에서 DB 인스턴스에 다음 용량 관련 설정이 적용됩니다. 버퍼 풀의 크기를 쉽게 읽을 수 있는 단위로 나타내기 위해 2의 30제곱으로 나누어 기비바이트(GiB) 단위로 측정합니다. Aurora의 메모리 관련 측정은 10의 거듭제곱이 아닌 2의 거듭제곱을 기반으로 하는 단위를 사용하기 때문입니다.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 9294577664 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 8.65625 | +-----------+ 1 row in set (0.00 sec)
다음으로 클러스터의 용량 범위를 변경합니다. modify-db-cluster 명령이 완료된 후 클러스터의 ACU 범위는 12.5~80입니다.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
용량 범위를 변경하면 일부 구성 파라미터의 기본값이 변경됩니다. Aurora는 이러한 새로운 기본값 중 일부를 즉시 적용할 수 있습니다. 그러나 일부 파라미터 변경 사항은 재부팅 후에만 적용됩니다. pending-reboot 상태는 일부 파라미터터 변경 사항을 적용하려면 재부팅이 필요함을 나타냅니다.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
이 시점에서 클러스터는 유휴 상태이고 DB 인스턴스 serverless-v2-instance-1은 12.5 ACU를 사용하고 있습니다. innodb_buffer_pool_size 파라미터는 DB 인스턴스의 현재 용량을 기반으로 이미 조정되었습니다. max_connections 파라미터는 여전히 이전 최대 용량의 값을 반영합니다. 해당 값을 재설정하려면 DB 인스턴스를 재부팅해야 합니다.
참고
사용자 지정 DB 파라미터 그룹에서 max_connections 파라미터를 직접 설정하는 경우 재부팅할 필요가 없습니다.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 15572402176 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +---------------+ | gibibytes | +---------------+ | 14.5029296875 | +---------------+ 1 row in set (0.00 sec)
이제 DB 인스턴스를 재부팅하고 다시 사용할 수 있을 때까지 기다립니다.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
pending-reboot 상태가 지워집니다. 값 in-sync는 Aurora가 보류 중인 모든 파라미터 변경 사항을 적용했음을 확인합니다.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
유휴 DB 인스턴스에 대해 innodb_buffer_pool_size 파라미터가 최종 크기로 증가했습니다. max_connections 파라미터는 최대 ACU 값에서 파생된 값을 반영하도록 증가했습니다. Aurora가 max_connections에 사용하는 공식은 메모리 크기가 2배가 되면 1,000이 증가합니다.
mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 16139681792 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 15.03125 | +-----------+ 1 row in set (0.00 sec) mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 4000 | +-------------------+ 1 row in set (0.00 sec)
용량 범위를 0.5~128ACU로 설정하고, DB 인스턴스를 재부팅했습니다. 이제 유휴 DB 인스턴스의 버퍼 캐시 크기가 1GiB 미만이므로 이를 메비바이트(MiB) 단위로 측정합니다. max_connections 값 5000은 최대 용량 설정의 메모리 크기에서 파생됩니다.
mysql> select @@innodb_buffer_pool_size / pow(2,20) as mebibytes, @@max_connections; +-----------+-------------------+ | mebibytes | @@max_connections | +-----------+-------------------+ | 672 | 5000 | +-----------+-------------------+ 1 row in set (0.00 sec)
예: Aurora MySQL 클러스터의 Aurora Serverless v2 용량 범위 변경
다음 CLI 예제는 기존 Aurora PostgreSQL 클러스터에서 Aurora Serverless v2 DB 인스턴스의 ACU 범위를 업데이트하는 방법을 보여줍니다.
-
클러스터의 용량 범위는 0.5~1 ACU에서 시작합니다.
-
용량 범위를 8~32 ACU로 변경합니다.
-
용량 범위를 12.5~80 ACU로 변경합니다.
-
용량 범위를 0.5~128 ACU로 변경합니다.
-
용량을 초기 범위인 0.5~1 ACU로 되돌립니다.
다음 그림은 Amazon CloudWatch에서의 용량 변화를 보여 줍니다.
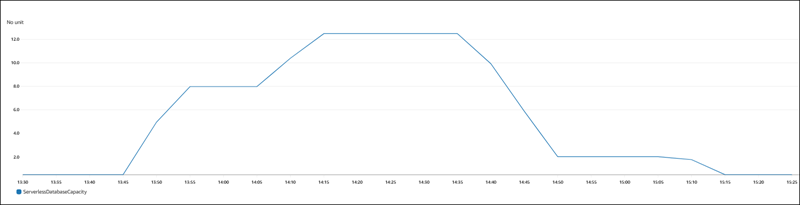
DB 인스턴스는 유휴 상태이며 0.5 ACU로 축소됩니다. 이 시점에서 DB 인스턴스에 다음 용량 관련 설정이 적용됩니다.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
다음으로 클러스터의 용량 범위를 변경합니다. modify-db-cluster 명령이 완료된 후 클러스터의 ACU 범위는 8.0~32입니다.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
용량 범위를 변경하면 일부 구성 파라미터의 기본값이 변경됩니다. Aurora는 이러한 새로운 기본값 중 일부를 즉시 적용할 수 있습니다. 그러나 일부 파라미터 변경 사항은 재부팅 후에만 적용됩니다. pending-reboot 상태는 일부 파라미터 변경 사항을 적용하려면 재부팅이 필요함을 나타냅니다.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
이 시점에서 클러스터는 유휴 상태이고 DB 인스턴스 serverless-v2-instance-1은 8.0 ACU를 사용하고 있습니다. shared_buffers 파라미터는 DB 인스턴스의 현재 용량을 기반으로 이미 조정되었습니다. max_connections 파라미터는 여전히 이전 최대 용량의 값을 반영합니다. 해당 값을 재설정하려면 DB 인스턴스를 재부팅해야 합니다.
참고
사용자 지정 DB 파라미터 그룹에서 max_connections 파라미터를 직접 설정하는 경우 재부팅할 필요가 없습니다.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
이제 DB 인스턴스를 재부팅하고 다시 사용할 수 있을 때까지 기다립니다.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
DB 인스턴스가 재부팅되었으므로 이제 pending-reboot 상태가 지워집니다. 값 in-sync는 Aurora가 보류 중인 모든 파라미터 변경 사항을 적용했음을 확인합니다.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
재부팅이 끝나면 max_connections에 새 최대 용량의 값이 표시됩니다.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
다음으로 클러스터의 용량 범위를 12.5~80 ACU로 변경합니다.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
이 시점에서 클러스터는 유휴 상태이고 DB 인스턴스 serverless-v2-instance-1은 12.5 ACU를 사용하고 있습니다. shared_buffers 파라미터는 DB 인스턴스의 현재 용량을 기반으로 이미 조정되었습니다. max_connections 값은 여전히 5000입니다.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
다시 재부팅하지만 파라미터 값은 동일하게 유지됩니다. max_connections의 경우 Aurora PostgreSQL을 실행하는 Aurora Serverless v2 DB 클러스터의 최대값이 5000이기 때문입니다.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
이제 용량 범위를 0.5~128 ACU로 설정합니다. DB 클러스터는 10 ACU로 축소된 다음 2 ACU로 축소됩니다. DB 인스턴스를 재부팅합니다.
postgres=> show max_connections; max_connections ----------------- 2000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Aurora Serverless v2 DB 인스턴스의 max_connections 값은 최대 ACU에서 파생된 메모리 크기를 기반으로 합니다. 하지만 PostgreSQL 호환 DB 인스턴스의 최소 용량을 0.5ACU로 지정하면 max_connections의 최대 용량을 2,000으로 제한됩니다.
이제 용량을 최초 범위인 0.5~1 ACU로 되돌리고 DB 인스턴스를 재부팅합니다. max_connections 파라미터가 원래 값으로 돌아갔습니다.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Aurora Serverless v2에 대한 파라미터 그룹 작업
Aurora Serverless v2 DB 클러스터를 생성할 때 특정 Aurora DB 엔진 및 연결된 DB 클러스터 파라미터 그룹을 선택합니다. Aurora가 파라미터 그룹을 사용하여 클러스터 간에 구성 설정을 일관되게 적용하는 방법에 익숙하지 않은 경우 Amazon Aurora의 파라미터 그룹 페이지를 참조하세요. 파라미터 그룹에 대한 생성, 수정, 적용 및 기타 작업에 대한 모든 프로시저는 Aurora Serverless v2에 적용됩니다.
파라미터 그룹 기능은 일반적으로 프로비저닝된 클러스터와 Aurora Serverless v2 DB 인스턴스를 포함하는 클러스터 간에 동일하게 작동합니다.
-
클러스터의 모든 DB 인스턴스에 대한 기본 파라미터 값은 클러스터 파라미터 그룹에 의해 정의됩니다.
-
특정 DB 인스턴스에 대한 사용자 지정 DB 파라미터 그룹을 지정하여 특정 DB 인스턴스에 대한 일부 파라미터를 재정의할 수 있습니다. 특정 DB 인스턴스에 대한 디버깅 또는 성능 조정 중에 그렇게 할 수 있습니다. 예를 들어, 일부 Aurora Serverless v2 DB 인스턴스와 일부 프로비저닝된 DB 인스턴스가 포함된 클러스터가 있다고 가정합니다. 이 경우 사용자 지정 DB 파라미터 그룹을 사용하여 프로비저닝된 DB 인스턴스에 대해 몇 가지 다른 파라미터를 지정할 수 있습니다.
-
Aurora Serverless v2의 경우 매개변수 그룹의
SupportedEngineModes속성에 값이provisioned인 모든 파라미터를 사용할 수 있습니다. Aurora Serverless v1에서는SupportedEngineModes속성에serverless가 있는 파라미터의 하위 집합만 사용할 수 있습니다.
주제
기본 파라미터 값
프로비저닝된 DB 인스턴스와 Aurora Serverless v2 DB 인스턴스의 중요한 차이점은 Aurora가 DB 인스턴스 용량과 관련된 특정 파라미터에 대한 모든 사용자 지정 파라미터 값을 재정의한다는 것입니다. 사용자 지정 파라미터 값은 클러스터의 프로비저닝된 DB 인스턴스에 계속 적용됩니다. Aurora Serverless v2 DB 인스턴스가 Aurora 파라미터 그룹의 파라미터를 해석하는 방법에 대한 자세한 내용은 Aurora 클러스터에 대한 구성 파라미터 섹션을 참조하세요. Aurora Serverless v2에서 재정의하는 특정 파라미터는 Aurora Serverless v2의 확장 및 축소에 따라 Aurora가 조정하는 파라미터 및 Aurora가 Aurora Serverless v2 최대 용량을 기반으로 계산하는 파라미터 페이지를 참조하세요.
describe-db-cluster-parameters CLI 명령을 사용하고 AWS 리전을 쿼리하여 다양한 Aurora DB 엔진의 기본 파라미터 그룹의 기본값 목록을 가져올 수 있습니다. 다음은 Aurora Serverless v2와 호환되는 엔진 버전의 --db-parameter-group-family 및 -db-parameter-group-name 옵션에 사용할 수 있는 값입니다.
| 데이터베이스 엔진 및 버전 | 파라미터터 그룹 패밀리 | 기본 파라미터 그룹 이름 |
|---|---|---|
|
Aurora MySQL 버전 3 |
|
|
|
Aurora PostgreSQL 버전 13.x |
|
|
|
Aurora PostgreSQL 버전 14.x |
|
|
|
Aurora PostgreSQL 버전 15.x |
|
|
|
Aurora PostgreSQL 버전 16.x |
|
|
다음 예제에서는 Aurora MySQL 버전 3 및 Aurora PostgreSQL 13의 기본 DB 클러스터 그룹에서 파라미터 목록을 가져옵니다. 이 버전은 Aurora Serverless v2와 함께 사용하는 Aurora MySQL 및 Aurora PostgreSQL 버전입니다.
대상 LinuxmacOS, 또는Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-mysql8.0 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-postgresql13 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text
Windows의 경우:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-mysql8.0 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-postgresql13 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text
Aurora Serverless v2의 최대 연결 수
Aurora MySQL 및 Aurora PostgreSQL 모두에서 Aurora Serverless v2 DB 인스턴스는 max_connections 파라미터를 일정하게 유지하므로 DB 인스턴스가 축소될 때 연결이 끊어지지 않습니다. 이 파라미터의 기본값은 DB 인스턴스의 메모리 크기를 기반으로 하는 공식에서 파생됩니다. 프로비저닝된 DB 인스턴스 클래스의 공식 및 기본값에 대한 자세한 내용은 Aurora MySQL DB 인스턴스에 대한 최대 연결 및 Aurora PostgreSQL DB 인스턴스에 대한 최대 연결 페이지를 참조하세요.
Aurora Serverless v2는 공식을 평가할 때 현재 ACU 값이 아니라 DB 인스턴스의 최대 Aurora 용량 단위(ACU)를 기반으로 하는 메모리 크기를 사용합니다. 기본값을 변경하는 경우 상수 값을 지정하는 대신 수식의 변형을 사용하는 것이 좋습니다. 이렇게 하면 Aurora Serverless v2는 최대 용량을 기준으로 적절한 크기의 설정을 사용할 수 있습니다.
Aurora Serverless v2 DB 클러스터의 최대 용량을 변경할 때는 Aurora Serverless v2 DB 인스턴스를 재부팅해야 max_connections 값이 업데이트됩니다. max_connections가 Aurora Serverless v2의 정적 파라미터이기 때문입니다.
다음 표에서는 최대 ACU 값을 기반으로 하는 Aurora Serverless v2의 max_connections 기본값을 확인할 수 있습니다.
| 최대 ACU | Aurora MySQL의 기본 최대 연결 수 | Aurora PostgreSQL의 기본 최대 연결 수 |
|---|---|---|
| 1 | 90 | 189 |
| 4 | 135 | 823 |
| 8 | 1,000 | 1,669 |
| 16 | 2,000 | 3,360 |
| 32 | 3,000 | 5,000 |
| 64 | 4,000 | 5,000 |
| 128 | 5,000 | 5,000 |
| 192 | 6,000 | 5,000 |
| 256 | 6,000 | 5,000 |
참고
Aurora Serverless v2 DB 인스턴스의 max_connections 값은 최대 용량에서 파생된 메모리 크기를 기반으로 합니다. 하지만 PostgreSQL 호환 DB 인스턴스의 최소 용량을 0.5ACU로 지정하면 max_connections의 최대 용량을 2,000으로 제한됩니다.
최대 ACU 값에 따른 max_connections 변화를 보여주는 구체적인 예는 예: Aurora MySQL 클러스터의 Aurora Serverless v2 용량 범위 변경 및 예: Aurora MySQL 클러스터의 Aurora Serverless v2 용량 범위 변경에서 확인할 수 있습니다.
Aurora Serverless v2의 확장 및 축소에 따라 Aurora가 조정하는 파라미터
Auto Scaling 중에 Aurora Serverless v2는 증가 또는 감소된 용량에 가장 적합하도록 각 DB 인스턴스의 파라미터를 변경할 수 있어야 합니다. 따라서 용량과 관련된 일부 파라미터를 재정의할 수 없습니다. 재정의할 수 있는 일부 파라미터의 경우 고정 값을 하드코딩하지 마세요. 용량과 관련된 이러한 설정에는 다음 고려 사항이 적용됩니다.
Aurora MySQL의 경우 Aurora Serverless v2는 크기 조정 중에 일부 파라미터의 크기를 동적으로 조정합니다. 다음 파라미터의 경우 Aurora Serverless v2는 사용자가 지정하는 사용자 지정 파라미터 값을 사용하지 않습니다.
-
innodb_buffer_pool_size -
innodb_purge_threads -
table_definition_cache -
table_open_cache
Aurora PostgreSQL의 경우 Aurora Serverless v2는 크기 조정 중에 다음 파라미터의 크기를 동적으로 조정합니다. 다음 파라미터의 경우 Aurora Serverless v2는 사용자가 지정하는 사용자 지정 파라미터 값을 사용하지 않습니다.
-
shared_buffers
여기에 나열된 파라미터 이외의 모든 파라미터에 대해, Aurora Serverless v2 DB 인스턴스는 프로비저닝된 DB 인스턴스와 동일하게 작동합니다. 기본 파라미터 값은 클러스터 파라미터 그룹에서 상속됩니다. 사용자 지정 클러스터 파라미터 그룹을 사용하여 전체 클러스터의 기본값을 수정할 수 있습니다. 또는 사용자 지정 DB 파라미터 그룹을 사용하여 특정 DB 인스턴스의 기본값을 수정할 수 있습니다. 동적 파라미터는 즉시 업데이트됩니다. 정적 파라미터에 대한 변경 사항은 DB 인스턴스를 재부팅한 후에만 적용됩니다.
Aurora가 Aurora Serverless v2 최대 용량을 기반으로 계산하는 파라미터
다음 파라미터에 대해 Aurora PostgreSQL은 max_connections와 마찬가지로 최대 ACU 설정을 기반으로 메모리 크기에서 파생된 기본값을 사용합니다.
-
autovacuum_max_workers -
autovacuum_vacuum_cost_limit -
autovacuum_work_mem -
effective_cache_size -
maintenance_work_mem
메모리 부족 오류 방지
Aurora Serverless v2 DB 인스턴스 중 하나가 지속적으로 최대 용량 한도에 도달하는 경우 Aurora는 DB 인스턴스를 incompatible-parameters 상태로 설정하여 이 조건을 나타냅니다. DB 인스턴스가 incompatible-parameters 상태인 동안 일부 작업이 차단됩니다. 예를 들어 엔진 버전을 업그레이드할 수 없습니다.
일반적으로 메모리 부족 오류로 인해 DB 인스턴스가 자주 다시 시작되면 이 상태가 됩니다. Aurora는 이러한 유형의 재시작이 발생할 때 이벤트를 기록합니다. Amazon RDS 이벤트 보기 프로시저에 따라 이벤트를 볼 수 있습니다. 성능 개선 도우미 및 IAM 인증과 같은 설정을 켜는 오버헤드로 인해 비정상적으로 높은 메모리 사용량이 발생할 수 있습니다. 또한 DB 인스턴스의 과중한 워크로드 또는 많은 수의 스키마 객체와 연결된 메타데이터 관리로 인해 발생할 수 있습니다.
메모리 압력이 낮아져 DB 인스턴스가 최대 용량에 자주 도달하지 않는 경우 Aurora는 자동으로 DB 인스턴스 상태를 다시 available로 변경합니다.
이 조건에서 복구하려면 다음 작업 중 일부 또는 전부를 수행할 수 있습니다.
-
클러스터의 최소 Aurora 용량 단위)(ACU) 값을 변경하여 B1 DB 인스턴스의 용량 하한을 늘립니다. 이렇게 하면 유휴 데이터베이스가 클러스터에서 켜진 기능에 필요한 것보다 적은 메모리를 가진 용량으로 축소되는 문제를 피할 수 있습니다. 클러스터의 ACU 설정을 변경한 후 Aurora Serverless v2 DB 인스턴스를 재부팅합니다. 이렇게 하면 Aurora가 상태를 다시
available로 재설정할 수 있는지 여부를 평가합니다. -
클러스터의 최대 ACU 값을 변경하여 Aurora Serverless v2 DB 인스턴스의 용량 상한을 늘립니다. 이렇게 하면 사용량이 많은 데이터베이스가 클러스터 및 데이터베이스 워크로드에서 켜진 기능을 위한 충분한 메모리로 용량을 확장할 수 없는 문제를 피할 수 있습니다. 클러스터의 ACU 설정을 변경한 후 Aurora Serverless v2 DB 인스턴스를 재부팅합니다. 이렇게 하면 Aurora가 상태를 다시
available로 재설정할 수 있는지 여부를 평가합니다. -
메모리 오버헤드가 필요한 구성 설정을 끕니다. 예를 들어 AWS Identity and Access Management(IAM), 성능 개선 도우미 또는 Aurora MySQL 바이너리 로그 복제와 같은 기능이 켜져 있지만 사용하지 않는다고 가정합니다. 이 경우 끌 수 있습니다. 또는 클러스터의 최소 및 최대 용량 값을 더 높게 조정하여 해당 기능에서 사용하는 메모리를 고려할 수 있습니다. 최소 및 최대 용량 설정 선택에 대한 지침은 Aurora 클러스터의 Aurora Serverless v2 용량 범위 선택 페이지를 참조하세요.
-
DB 인스턴스의 워크로드를 줄입니다. 예를 들어 클러스터에 리더 DB 인스턴스를 추가하여 읽기 전용 쿼리의 로드를 더 많은 DB 인스턴스에 분산할 수 있습니다.
-
더 적은 리소스를 사용하도록 애플리케이션에서 사용하는 SQL 코드를 튜닝합니다. 예를 들어 쿼리 계획을 검사하거나 느린 쿼리 로그를 확인하거나 테이블의 인덱스를 조정할 수 있습니다. 기존에 있는 다른 종류의 SQL 튜닝을 수행할 수도 있습니다.
Aurora Serverless v2에 대한 중요 Amazon CloudWatch 지표
Aurora Serverless v2 DB 인스턴스용 Amazon CloudWatch를 시작하려면 Amazon CloudWatch에서 Aurora Serverless v2 로그 보기 페이지를 참조하세요. CloudWatch를 통해 Aurora DB 클러스터를 모니터링하는 방법에 대한 자세한 내용은 Amazon CloudWatch에서 로그 이벤트 모니터링 섹션을 참조하세요.
CloudWatch에서 Aurora Serverless v2 DB 인스턴스를 보고 ServerlessDatabaseCapacity 지표를 통해 각 DB 인스턴스에서 소비한 용량을 모니터링할 수 있습니다. DatabaseConnections 및 Queries와 같은 모든 표준 Aurora CloudWatch 지표를 모니터링할 수도 있습니다. Aurora에 대해 모니터링할 수 있는 CloudWatch 지표의 전체 목록은 Amazon Aurora에 대한 Amazon CloudWatch 지표 페이지를 참조하세요. 메트릭은 Amazon Aurora에 대한 클러스터 수준 지표 및 Amazon Aurora에 대한 인스턴스 수준 지표에서 클러스터 수준 및 인스턴스 수준 메트릭으로 나뉩니다.
다음 CloudWatch 인스턴스 수준 지표는 Aurora Serverless v2 DB 인스턴스가 확장 및 축소되는 방식을 이해하기 위해 모니터링하는 데 중요합니다. 이러한 모든 지표는 매초마다 계산됩니다. 그렇게 하면 Aurora Serverless v2 DB 인스턴스의 현재 상태를 모니터링할 수 있습니다. Aurora Serverless v2 DB 인스턴스가 용량과 관련된 지표 임계값에 도달하면 알림을 받도록 경보를 설정할 수 있습니다. 최소 및 최대 용량 설정이 적절한지 또는 조정이 필요한지 결정할 수 있습니다. 데이터베이스의 효율성을 최적화하기 위해 집중할 부분을 결정할 수 있습니다.
-
ServerlessDatabaseCapacity. 인스턴스 수준 지표로서 현재 DB 인스턴스 용량이 나타내는 ACU 수를 보고합니다. 클러스터 수준의 지표로 클러스터 내 모든ServerlessDatabaseCapacityDB 인스턴스의 Aurora Serverless v2 값 평균을 나타냅니다. 이 지표는 Aurora Serverless v1의 클러스터 수준 지표일 뿐입니다. Aurora Serverless v2에서는 DB 인스턴스 수준과 클러스터 수준에서 사용할 수 있습니다. -
ACUUtilization. 이 지표는 Aurora Serverless v2의 새로운 기능입니다. 이 값은 백분율로 표시됩니다.ServerlessDatabaseCapacity지표의 값을 DB 클러스터의 최대 ACU 값으로 나눈 값으로 계산됩니다. 이 지표를 해석하고 조치를 취하려면 다음 지침을 고려하세요.-
이 지표가
100.0값에 가까워지면 DB 인스턴스가 가능한 한 높게 확장된 것입니다. 클러스터에 대한 최대 ACU 설정을 늘리는 것이 좋습니다. 이렇게 하면 라이터와 리더 DB 인스턴스 모두 더 높은 용량으로 확장할 수 있습니다. -
읽기 전용 워크로드로 인해 리더 DB 인스턴스가
100.0의ACUUtilization에 접근하는 반면 라이터 DB 인스턴스는 최대 용량에 근접하지 않는다고 가정합니다. 이 경우 클러스터에 리더 DB 인스턴스를 추가하는 것이 좋습니다. 이렇게 하면 워크로드의 읽기 전용 부분을 더 많은 DB 인스턴스에 분산시켜 각 리더 DB 인스턴스의 부하를 줄일 수 있습니다. -
성능과 확장성이 주요 고려 사항인 프로덕션 애플리케이션을 실행하고 있다고 가정합니다. 이 경우 클러스터의 최대 ACU 값을 높은 값으로 설정할 수 있습니다. 목표는
ACUUtilization지표가 항상100.0아래에 있도록 하는 것입니다. 최대 ACU 값이 높으면 데이터베이스 활동이 예기치 않게 급증하는 경우에 충분한 공간이 확보되어 있다는 확신을 가질 수 있습니다. 실제로는 사용한 데이터베이스 용량에 대해서만 요금이 청구됩니다.
-
-
CPUUtilization. 이 지표는 프로비저닝된 DB 인스턴스와 Aurora Serverless v2에서 다르게 해석됩니다. Aurora Serverless v2의 경우 이 값은 현재 사용 중인 CPU의 양을 DB 클러스터의 최대 ACU 값 아래에서 사용 가능한 CPU 용량으로 나눈 값입니다. Aurora는 이 값을 자동으로 모니터링하고 DB 인스턴스가 CPU 용량의 높은 비율을 지속적으로 사용하는 경우 Aurora Serverless v2 DB 인스턴스를 확장합니다.이 지표가
100.0값에 가까워지면 DB 인스턴스가 최대 CPU 용량에 도달한 것입니다. 클러스터에 대한 최대 ACU 설정을 늘리는 것이 좋습니다. 이 지표가 리더 DB 인스턴스에서100.0값에 가까워지는 경우 클러스터에 리더 DB 인스턴스를 추가하는 것이 좋습니다. 이렇게 하면 워크로드의 읽기 전용 부분을 더 많은 DB 인스턴스에 분산시켜 각 리더 DB 인스턴스의 로드를 줄일 수 있습니다. -
FreeableMemory. 이 값은 Aurora Serverless v2 DB 인스턴스가 최대 용량으로 확장될 때 사용 가능한 미사용 메모리의 양을 나타냅니다. 현재 용량이 최대 용량 미만인 모든 ACU에 대해 이 값은 약 2GiB씩 증가합니다. 따라서 DB 인스턴스가 가능한 한 높게 확장될 때까지 이 지표는 0에 접근하지 않습니다.이 지표가
0값에 접근하면 DB 인스턴스가 가능한 한 확장되었으며 사용 가능한 메모리 한도에 근접한 것입니다. 클러스터에 대한 최대 ACU 설정을 늘리는 것이 좋습니다. 이 지표가 리더 DB 인스턴스에서0값에 가까워지는 경우 클러스터에 리더 DB 인스턴스를 추가하는 것이 좋습니다. 이렇게 하면 워크로드의 읽기 전용 부분을 더 많은 DB 인스턴스에 분산하여 각 리더 DB 인스턴스의 메모리 사용량을 줄일 수 있습니다. -
TempStorageIops. DB 인스턴스에 연결된 로컬 스토리지에서 수행된 IOPS 수입니다. 여기에는 읽기와 쓰기에 모두 대한 IOPS가 포함됩니다. 이 지표는 개수를 나타내며 초당 한 번 측정됩니다. 이 지표는 Aurora Serverless v2의 새로운 지표입니다. 자세한 내용은 Amazon Aurora에 대한 인스턴스 수준 지표 페이지을 참조하세요. -
TempStorageThroughput. DB 인스턴스와 연결된 로컬 스토리지에서 전송되는 데이터의 양입니다. 이 지표는 개수를 나타내며 초당 한 번 측정됩니다. 이 지표는 Aurora Serverless v2의 새로운 지표입니다. 자세한 내용은 Amazon Aurora에 대한 인스턴스 수준 지표 페이지을 참조하세요.
일반적으로 Aurora Serverless v2 DB 인스턴스에 대한 대부분의 확장은 메모리 사용량과 CPU 활동으로 인해 발생합니다. TempStorageIops 및 TempStorageThroughput 지표는 DB 인스턴스와 로컬 스토리지 디바이스 간의 전송에 대한 네트워크 활동이 예상치 못한 용량 증가의 원인이 되는 드문 경우를 진단하는 데 도움이 될 수 있습니다. 다른 네트워크 활동을 모니터링하려면 다음과 같은 기존 지표를 사용할 수 있습니다.
-
NetworkReceiveThroughput -
NetworkThroughput -
NetworkTransmitThroughput -
StorageNetworkReceiveThroughput -
StorageNetworkThroughput -
StorageNetworkTransmitThroughput
Aurora가 데이터베이스 로그 중 일부 또는 전체를 CloudWatch에 게시하게 할 수 있습니다. Aurora Serverless v2 DB 인스턴스가 포함된 클러스터와 연결된 DB 클러스터 파라미터에서 general_log 및 slow_query_log와 같은 구성 파라미터 그룹을 켜서 게시할 로그를 선택합니다. 로그 구성 파라미터를 끄면 CloudWatch에 대한 해당 로그 게시가 중지됩니다. 더 이상 필요하지 않은 경우 CloudWatch에서 로그를 삭제할 수도 있습니다.
Aurora Serverless v2 지표가 AWS 청구서에 적용되는 방식
AWS 청구서의 Aurora Serverless v2 요금은 모니터링할 수 있는 동일한 ServerlessDatabaseCapacity 지표를 기반으로 계산됩니다. Aurora Serverless v2 용량을 한 시간의 일부만 사용하는 경우 청구 메커니즘은 이 지표에 대해 계산된 CloudWatch 평균과 다를 수 있습니다. 시스템 문제로 인해 CloudWatch 지표를 짧은 기간 동안 사용할 수 없는 경우에도 다를 수 있습니다. 따라서 청구서에 ACU-시간 값이 ServerlessDatabaseCapacity 평균값에서 직접 계산하는 경우와 약간 다를 수 있습니다.
Aurora Serverless v2 지표에 대한 CloudWatch 명령의 예
다음 AWS CLI 예제는 Aurora Serverless v2와 관련된 가장 중요한 CloudWatch 지표를 모니터링하는 방법을 보여줍니다. 각 경우에 --dimensions 파라미터의 Value= 문자열을 고유한 Aurora Serverless v2 DB 인스턴스의 식별자로 바꿉니다.
다음 Linux 예제는 1시간 동안 10분마다 측정된 DB 인스턴스의 최소, 최대 및 평균 용량 값을 표시합니다. Linux date 명령은 현재 날짜 및 시간을 기준으로 시작 및 종료 시간을 지정합니다. --query 파라미터의 sort_by 함수는 Timestamp 필드를 기준으로 결과를 시간순으로 정렬합니다.
aws cloudwatch get-metric-statistics --metric-name "ServerlessDatabaseCapacity" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
다음 Linux 예제는 클러스터에 있는 각 DB 인스턴스의 용량 모니터링을 보여줍니다. 각 DB 인스턴스의 최소, 최대 및 평균 용량 사용률을 측정합니다. 측정은 3시간 동안 매시간에 한 번씩 측정됩니다. 이 예에서는 고정된 수의 ACU를 나타내는 ServerlessDatabaseCapacity 대신 ACU에 대한 상한의 백분율을 나타내는 ACUUtilization 지표를 사용합니다. 이렇게 하면 용량 범위에서 최소 및 최대 ACU 값의 실제 수치를 알 필요가 없습니다. 0에서 100 사이의 백분율을 볼 수 있습니다.
aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_writer_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_reader_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
다음 Linux 예제는 이전 예제와 유사한 측정을 수행합니다. 이 경우 측정은 B1 지표에 대한 것입니다. 측정은 1시간 동안 10분마다 수행됩니다. 이 수치는 DB 인스턴스의 최대 용량 설정까지 사용 가능한 CPU 리소스를 기준으로 사용된 사용 가능한 CPU의 백분율을 나타냅니다.
aws cloudwatch get-metric-statistics --metric-name "CPUUtilization" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
다음 Linux 예제는 이전 예제와 유사한 측정을 수행합니다. 이 경우 측정은 B1 지표에 대한 것입니다. 측정은 1시간 동안 10분마다 수행됩니다.
aws cloudwatch get-metric-statistics --metric-name "FreeableMemory" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
성능 개선 도우미로 Aurora Serverless v2 성능 모니터링
성능 개선 도우미를 사용하여 Aurora Serverless v2 DB 인스턴스의 성능을 모니터링할 수 있습니다. 성능 개선 도우미 프로시저는 성능 개선 도우미를 통한 Amazon Aurora 모니터링 페이지를 참조하세요.
다음과 같은 새로운 성능 개선 도우미 카운터가 Aurora Serverless v2 DB 인스턴스에 적용됩니다.
-
os.general.serverlessDatabaseCapacity- ACU에 있는 DB 인스턴스의 현재 용량입니다. DB 인스턴스에 대한ServerlessDatabaseCapacityCloudWatch 지표에 해당하는 값입니다. -
os.general.acuUtilization- 구성된 최대 용량에서 현재 용량의 백분율입니다. DB 인스턴스에 대한ACUUtilizationCloudWatch 지표에 해당하는 값입니다. -
os.general.maxConfiguredAcu- 이 Aurora Serverless v2 DB 인스턴스에 대해 구성한 최대 용량입니다. ACU로 측정됩니다. -
os.general.minConfiguredAcu- 이 Aurora Serverless v2 DB 인스턴스에 대해 구성한 최소 용량입니다. ACU로 측정됩니다.
성능 개선 도우미 카운터의 전체 목록은 성능 개선 도우미 카운터 페이지를 참조하세요.
성능 개선 도우미에서 Aurora Serverless v2 DB 인스턴스에 대해 vCPU 값이 표시되는 경우 해당 값은 DB 인스턴스에 대한 ACU 값을 기반으로 한 추정치를 나타냅니다. 기본 간격인 1분 간격으로 모든 분수 vCPU 값은 가장 가까운 정수로 반올림됩니다. 더 긴 간격의 경우 표시된 vCPU 값은 분당 정수 vCPU 값의 평균입니다.
Aurora Serverless v2 용량 문제 해결
데이터베이스에 부하가 없는데도 Aurora Serverless v2이 최소값으로 축소되지 않는 경우가 있습니다. 원인은 다음과 같습니다.
-
특정 기능을 사용하면 리소스 사용량을 늘리고, 데이터베이스가 최소 용량으로 스케일 다운되는 것을 방지할 수 있습니다. 이러한 기능은 다음과 같습니다.
-
Aurora 글로벌 데이터베이스
-
CloudWatch 로그 내보내기
-
Aurora PostgreSQL 호환 DB 클러스터에서
pg_audit활성화 -
확장 모니터링
-
성능 개선 도우미
자세한 내용은 클러스터에 대한 최소 Aurora Serverless v2 용량 설정 선택 단원을 참조하십시오.
-
-
리더 인스턴스가 최소 용량으로 축소되지 않고 라이터 인스턴스와 같거나 더 높은 용량을 유지하는 경우, 리더 인스턴스의 우선 순위 등급을 확인하십시오. Aurora Serverless v2 0 또는 1 등급 리더 DB 인스턴스는 라이터 DB 인스턴스보다 같거나 높은 최소 용량으로 유지됩니다. 리더의 우선 순위 등급을 2 이상으로 변경하여 라이터와 별개로 크기를 늘리거나 줄이십시오. 자세한 내용은 Aurora Serverless v2 리더에 대한 승격 티어 선택 단원을 참조하십시오.
-
공유 메모리 크기에 영향을 주는 데이터베이스 파라미터를 기본값으로 설정합니다. 기본값보다 높은 값을 설정하면 공유 메모리 요구 사항이 증가하고 데이터베이스가 최소 용량으로 축소되지 않습니다. 대표적인 예는
max_connections및max_locks_per_transaction입니다.참고
공유 메모리 파라미터를 업데이트하면 데이터베이스를 다시 시작해야 변경 사항이 적용됩니다.
-
데이터베이스 워크로드가 많으면 리소스 사용량이 증가할 수 있습니다.
-
데이터베이스 볼륨이 크면 리소스 사용량이 증가할 수 있습니다.
Amazon Aurora는 DB 클러스터 관리에 메모리와 CPU 리소스를 사용합니다. 데이터베이스 볼륨이 큰 DB 클러스터를 관리하려면 Aurora에 더 많은 CPU와 메모리가 필요합니다. 클러스터의 최소 용량이 클러스터 관리에 필요한 최소 용량보다 작으면 클러스터가 최소 용량으로 스케일 다운되지 않습니다.
-
제거와 같은 백그라운드 프로세스도 리소스 사용량을 높일 수 있습니다.
그래도 데이터베이스가 구성된 최소 용량까지 축소되지 않는다면, 데이터베이스를 중지하고 다시 시작하여 시간이 지남에 따라 형성된 메모리 조각을 회수하십시오. 데이터베이스를 중지하고 다시 시작하면 다운타임이 발생하므로 이 작업은 최소한으로 수행하는 것이 좋습니다.
