기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
를 사용하여 온프레미스 데이터 웨어하우스에서 Amazon Redshift로 데이터 마이그레이션 AWS Schema Conversion Tool
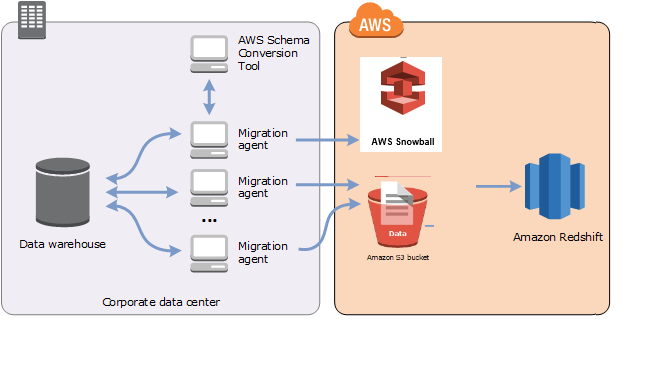
AWS SCT 에이전트를 사용하여 온프레미스 데이터 웨어하우스에서 데이터를 추출하고 Amazon Redshift로 마이그레이션할 수 있습니다. 에이전트는 데이터를 추출하고 Amazon S3 또는 대규모 마이그레이션의 경우 AWS Snowball Edge Edge 디바이스에 데이터를 업로드합니다. 그런 다음 AWS SCT 에이전트를 사용하여 Amazon Redshift에 데이터를 복사할 수 있습니다.
또는 AWS Database Migration Service (AWS DMS)를 사용하여 데이터를 Amazon Redshift로 마이그레이션할 수 있습니다. AWS DMS 의 장점은 지속적인 복제(변경 데이터 캡처)를 지원한다는 것입니다. 그러나 데이터 마이그레이션 속도를 높이려면 여러 AWS SCT 에이전트를 병렬로 사용합니다. 테스트 AWS SCT 에 따르면 에이전트는 데이터를 15~35% 더 빠르게 마이그레이션 AWS DMS 합니다. 속도 차이는 데이터 압축, 테이블 파티션의 병렬 마이그레이션 지원, 다양한 구성 설정으로 인해 발생합니다. 자세한 내용은 AWS Database Migration Service대상으로 Amazon Redshift 데이터베이스 사용 섹션을 참조하세요.
Amazon S3은 스토리지 및 검색 서비스입니다. Amazon S3에 객체를 저장하려면 저장할 파일을 Amazon S3 버킷에 업로드합니다. 파일을 업로드하면 객체 및 메타데이터에도 권한을 설정할 수 있습니다.
대규모 마이그레이션
대규모 데이터 마이그레이션에는 수 테라바이트의 정보가 포함될 수 있으며, 네트워크 성능과 이동해야 하는 데이터의 양에 따라 속도가 느려질 수 있습니다. AWS Snowball Edge 엣지는 AWS소유 어플라이언스를 사용하여 faster-than-network 속도로 클라우드로 데이터를 전송하는 데 사용할 수 있는 AWS 서비스입니다. AWS Snowball Edge Edge 디바이스는 최대 100TB의 데이터를 저장할 수 있습니다. 256비트 암호화와 업계 표준 TPM(Trusted Platform Module)을 사용하여 data. AWS SCT works에서 AWS Snowball Edge Edge 디바이스에 대한 보안 및 전체 chain-of-custody을 모두 보장합니다.
AWS SCT 및 AWS Snowball Edge Edge 디바이스를 사용하는 경우 두 단계로 데이터를 마이그레이션합니다. 먼저 AWS SCT 를 사용하여 로컬에서 데이터를 처리한 다음 해당 데이터를 Edge 디바이스로 AWS Snowball Edge 이동합니다. 그런 다음 엣지 프로세스를 AWS 사용하여 디바이스를 AWS Snowball Edge 로 전송한 다음 Amazon S3 버킷에 데이터를 AWS 자동으로 로드합니다. 다음으로 Amazon S3에서 데이터를 사용할 수 있는 경우 AWS SCT 를 사용하여 데이터를 Amazon Redshift로 마이그레이션합니다. 데이터 추출 에이전트는이 닫힌 상태에서 백그라운드에서 작동할 수 AWS SCT 있습니다.
다음 다이어그램은 지원되는 시나리오를 보여 줍니다.
데이터 추출 에이전트는 현재 다음과 같은 소스 데이터 웨어하우스에서 지원됩니다.
Azure Synapse Analytics
BigQuery
Greenplum Database(버전 4.3)
Microsoft SQL Server(버전 2008 이상)
Netezza(버전 7.0.3 이상)
Oracle(버전 10 이상)
Snowflake(버전 3)
Teradata(버전 13 이상)
Vertica(버전 7.2.2 이상)
FIPS(Federal Information Processing Standard) 보안 요구 사항을 준수해야 하는 경우 Amazon Redshift용 FIPS 엔드포인트에 연결할 수 있습니다. FIPS 엔드포인트는 다음 AWS 리전에서 사용할 수 있습니다.
미국 동부(버지니아 북부) 리전(redshift-fips.us-east-1.amazonaws.com)
미국 동부(오하이오) 리전(redshift-fips.us-east-2.amazonaws.com)
미국 서부(캘리포니아 북부) 리전(redshift-fips.us-west-1.amazonaws.com)
미국 서부(오레곤) 리전(redshift-fips.us-west-2.amazonaws.com)
다음 항목의 정보를 사용하여 데이터 추출 에이전트를 사용하는 방법을 알아봅니다.
주제
데이터 추출 에이전트 사용을 위한 사전 조건
데이터 추출 에이전트를 사용하기 전에 Amazon Redshift에 필요한 권한을 대상으로 Amazon Redshift 사용자에게 추가합니다. 자세한 내용은 Amazon Redshift를 대상으로 사용할 수 있는 권한 단원을 참조하십시오.
그런 다음, Amazon S3 버킷 정보를 저장하고 SSL(Secure Sockets Layer) 트러스트 및 키 스토어를 설정합니다.
Amazon S3 설정
에이전트가 데이터를 추출한 후에는 Amazon S3 버킷에 업로드합니다. 계속하기 전에 AWS 계정 및 Amazon S3 버킷에 연결할 자격 증명을 제공해야 합니다. 자격 증명과 버킷 정보를 글로벌 애플리케이션 설정의 프로필에 저장한 다음 해당 프로필을 AWS SCT 프로젝트와 연결합니다. 필요한 경우 전역 설정을 선택하여 새 프로필을 생성합니다. 자세한 내용은 에서 프로필 관리 AWS Schema Conversion Tool 단원을 참조하십시오.
데이터를 대상 Amazon Redshift 데이터베이스로 마이그레이션하려면 AWS SCT 데이터 추출 에이전트가 사용자를 대신하여 Amazon S3 버킷에 액세스할 수 있는 권한이 필요합니다. 이 권한을 제공하려면 다음 정책을 사용하여 AWS Identity and Access Management (IAM) 사용자를 생성합니다.
이전 예제에서 bucket_name111122223333:user/DataExtractionAgentName
IAM 역할 수임
추가 보안을 위해 AWS Identity and Access Management (IAM) 역할을 사용하여 Amazon S3 버킷에 액세스할 수 있습니다. 이를 위해 권한 없이 데이터 추출 에이전트의 IAM 사용자를 생성합니다. 그런 다음, Amazon S3 액세스를 지원하는 IAM 역할을 생성하고 이 역할을 수임할 수 있는 서비스 및 사용자 목록을 지정합니다. 자세한 내용은 IAM 사용 설명서에서 IAM 역할을 참조하세요.
Amazon S3 버킷에 액세스하도록 IAM 역할을 구성하려면
-
새 IAM 사용자를 생성합니다. 사용자 보안 인증에 대해 프로그래밍 방식 액세스 유형을 선택합니다.
-
데이터 추출 에이전트가에서 AWS SCT 제공하는 역할을 수임할 수 있도록 호스트 환경을 구성합니다. 이전 단계에서 구성한 사용자가 데이터 추출 에이전트에서 보안 인증 공급자 체인을 사용할 수 있도록 지원하는지 확인합니다. 자세한 내용을 알아보려면 AWS SDK for Java 개발자 안내서의 보안 인증 사용을 참조하세요.
-
Amazon S3 버킷에 대한 액세스 권한이 있는 새 IAM 역할을 생성합니다.
-
이전에 생성한 사용자가 역할을 맡을 수 있도록 하려면 이 역할의 트러스트 섹션을 수정합니다. 다음 예에서
111122223333:user/DataExtractionAgentName{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111122223333:user/DataExtractionAgentName" }, "Action": "sts:AssumeRole" } -
redshift.amazonaws.com이 역할을 맡을 수 있도록 하려면 이 역할의 트러스트 섹션을 수정합니다.{ "Effect": "Allow", "Principal": { "Service": [ "redshift.amazonaws.com" ] }, "Action": "sts:AssumeRole" } -
Amazon Redshift 클러스터에 IAM 역할을 연결합니다.
이제 AWS SCT에서 데이터 추출 에이전트를 실행할 수 있습니다.
IAM 역할 수임을 사용하는 경우 데이터 마이그레이션이 다음과 같은 방식으로 작동합니다. 데이터 추출 에이전트는 보안 인증 공급자 체인을 사용하여 시작하고 사용자 보안 인증을 가져옵니다. 그런 다음에서 데이터 마이그레이션 작업을 생성한 다음 AWS SCT데이터 추출 에이전트가 수임할 IAM 역할을 지정하고 작업을 시작합니다. AWS Security Token Service (AWS STS)는 Amazon S3에 액세스하기 위한 임시 자격 증명을 생성합니다. 데이터 추출 에이전트는 이러한 보안 인증을 사용하여 Amazon S3에 데이터를 업로드합니다.
그런 다음는 IAM 역할을 사용하여 Amazon Redshift를 AWS SCT 제공합니다. 그러면 Amazon Redshift는에서 새로운 임시 자격 증명을 가져와 Amazon S3 AWS STS 에 액세스합니다. Amazon Redshift는 이러한 보안 인증을 사용하여 Amazon S3에서 Amazon Redshift 테이블로 데이터를 복사합니다.
보안 설정
AWS Schema Conversion Tool 및 추출 에이전트는 Secure Sockets Layer(SSL)를 통해 통신할 수 있습니다. SSL을 활성화하려면 트러스트 스토어와 키 스토어를 설정합니다.
추출 에이전트와의 안전한 통신을 설정하려면
-
를 시작합니다 AWS Schema Conversion Tool.
-
설정 메뉴를 열고 전역 설정을 선택합니다. 전역 설정 대화 상자가 나타납니다.
-
보안을 선택합니다.
-
Generate trust and key store를 선택하거나 Select existing trust store를 선택합니다.
Generate trust and key store를 선택한 경우, 트러스트 및 키 스토어의 이름과 암호, 그리고 생성된 파일이 저장될 위치의 경로를 지정합니다. 이후 단계에서 이 파일을 사용합니다.
Select existing trust store를 선택한 경우, 트러스트 및 키 스토어의 암호와 파일 이름을 지정합니다. 이후 단계에서 이 파일을 사용합니다.
-
트러스트 스토어와 키 스토어를 지정한 후 확인을 선택하여 전역 설정 대화 상자를 닫습니다.
데이터 추출 에이전트의 환경 구성
단일 호스트에 여러 데이터 추출 에이전트를 설치할 수 있습니다. 그러나 하나의 호스트에서 하나의 데이터 추출 에이전트를 실행하는 것이 좋습니다.
데이터 추출 에이전트를 실행하려면 vCPU가 4개 이상 있고 메모리가 32GB 이상인 호스트를 사용해야 합니다. 또한 사용 가능한 최소 메모리를 AWS SCT 4GB 이상으로 설정합니다. 자세한 내용은 추가 메모리 구성 단원을 참조하십시오.
최적의 에이전트 호스트 구성과 수는 각 고객의 특정 상황에 따라 달라집니다. 마이그레이션할 데이터의 양, 네트워크 대역폭, 데이터 추출 시간 등의 요소를 고려해야 합니다. 먼저 PoC(개념 증명)를 수행한 후 이 PoC의 결과에 따라 데이터 추출 에이전트와 호스트를 구성할 수 있습니다.
추출 에이전트 설치
AWS Schema Conversion Tool를 실행 중인 컴퓨터와 별도로 개별 컴퓨터에 여러 추출 에이전트를 설치하는 것이 좋습니다.
추출 에이전트는 현재 다음 운영 체제에서 지원됩니다.
Microsoft Windows
Red Hat Enterprise Linux(RHEL) 6.0
Ubuntu Linux(버전 14.04 이상)
다음 절차에 따라 추출 에이전트를 설치합니다. 추출 에이전트를 설치할 각 컴퓨터에서 이 절차를 반복해서 수행합니다.
추출 에이전트를 설치하려면
-
AWS SCT 설치 관리자 파일을 아직 다운로드하지 않은 경우의 지침에 따라 설치 및 구성 AWS Schema Conversion Tool 다운로드합니다. AWS SCT 설치 관리자 파일이 포함된 .zip 파일에는 추출 에이전트 설치 관리자 파일도 포함되어 있습니다.
-
최신 버전의 Amazon Corretto 11을 다운로드하여 설치합니다. 자세한 내용은 Amazon Corretto 11 사용 설명서의 Amazon Corretto 11 다운로드를 참조하세요.
-
이름이 agents인 하위 폴더에서 추출 에이전트의 설치 관리자 파일을 찾습니다. 각 컴퓨터 운영 체제에서 추출 에이전트를 설치하기 위한 올바른 파일은 다음과 같습니다.
운영 체제 파일 이름 Microsoft Windows
aws-schema-conversion-tool-extractor-2.0.1.build-number.msiRHEL
aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpmUbuntu Linux
aws-schema-conversion-tool-extractor-2.0.1.build-number.deb -
설치 관리자 파일을 새 컴퓨터에 복사하여 추출 에이전트를 별도의 컴퓨터에 설치합니다.
-
설치 관리자 파일을 실행합니다. 다음에 표시된 운영 체제별 지침을 사용하십시오.
운영 체제 설치 지침 Microsoft Windows
파일을 두 번 클릭하여 설치 프로그램을 실행합니다.
RHEL
파일을 다운로드 또는 이동한 폴더에서 다음 명령을 실행합니다.
sudo rpm -ivh aws-schema-conversion-tool-extractor-2.0.1.build-number.x86_64.rpm sudo ./sct-extractor-setup.sh --configUbuntu Linux
파일을 다운로드 또는 이동한 폴더에서 다음 명령을 실행합니다.
sudo dpkg -i aws-schema-conversion-tool-extractor-2.0.1.build-number.deb sudo ./sct-extractor-setup.sh --config -
다음을 선택하고 라이선스 계약에 동의한 후 다음을 선택합니다.
-
AWS SCT 데이터 추출 에이전트를 설치할 경로를 입력하고 다음을 선택합니다.
-
설치를 선택하여 데이터 추출 에이전트를 설치합니다.
AWS SCT 는 데이터 추출 에이전트를 설치합니다. 설치를 완료하려면 데이터 추출 에이전트를 구성합니다.는 구성 설정 프로그램을 AWS SCT 자동으로 시작합니다. 자세한 내용은 추출 에이전트 구성 단원을 참조하십시오.
-
데이터 추출 에이전트를 구성한 후 완료를 선택하여 설치 마법사를 닫습니다.
추출 에이전트 구성
다음 절차를 사용하여 추출 에이전트를 구성합니다. 추출 에이전트가 설치된 각 컴퓨터에서 이 절차를 반복합니다.
추출 에이전트를 구성하려면
-
구성 설정 프로그램을 시작합니다.
-
Windows에서는 데이터 추출 에이전트를 설치하는 동안 구성 설정 프로그램을 자동으로 AWS SCT 시작합니다.
필요한 경우 설정 프로그램을 수동으로 시작할 수 있습니다. 이렇게 하려면 Windows에서
ConfigAgent.bat파일을 실행합니다. 에이전트를 설치한 폴더에서 이 파일을 찾을 수 있습니다. -
RHEL 및 Ubuntu에서는 에이전트를 설치한 위치에서
sct-extractor-setup.sh파일을 실행합니다.
설정 프로그램에서 정보를 확인하는 프롬프트 메시지를 표시합니다. 각 프롬프트에는 기본값이 표시됩니다.
-
-
각 프롬프트의 기본값을 그대로 사용하거나 새 값을 입력합니다.
다음과 같은 정보를 지정합니다.
Listening port에 에이전트가 수신 대기하는 포트 번호를 입력합니다.
Add a source vendor에 yes를 입력한 다음, 소스 데이터 웨어하우스 플랫폼을 입력합니다.
JDBC 드라이버에 JDBC 드라이버를 설치한 위치를 입력합니다.
작업 폴더에 AWS SCT 데이터 추출 에이전트가 추출된 데이터를 저장할 경로를 입력합니다. 작업 폴더는 에이전트와 다른 컴퓨터에 있을 수 있으며, 서로 다른 컴퓨터에 있는 여러 에이전트가 단일 작업 폴더를 공유할 수 있습니다.
Enable SSL communication에 yes를 입력합니다.
Key store에 키 스토어 파일의 위치를 입력합니다.
Key store password에 키 스토어의 암호를 입력합니다.
Enable client SSL authentication에 yes를 입력합니다.
트러스트 스토어에 트러스트 스토어 파일의 위치를 입력합니다.
Trust store password에 트러스트 스토어의 암호를 입력합니다.
설치 프로그램이 추출 에이전트의 설정 파일을 업데이트합니다. 설정 파일은 이름이 settings.properties이며 추출 에이전트를 설치한 위치에 있습니다.
다음은 샘플 설정 파일입니다.
$ cat settings.properties
#extractor.start.fetch.size=20000
#extractor.out.file.size=10485760
#extractor.source.connection.pool.size=20
#extractor.source.connection.pool.min.evictable.idle.time.millis=30000
#extractor.extracting.thread.pool.size=10
vendor=TERADATA
driver.jars=/usr/share/lib/jdbc/terajdbc4.jar
port=8192
redshift.driver.jars=/usr/share/lib/jdbc/RedshiftJDBC42-1.2.43.1067.jar
working.folder=/data/sct
extractor.private.folder=/home/ubuntu
ssl.option=OFF구성 설정을 변경하려면 텍스트 편집기를 사용하여 settings.properties 파일을 편집하거나 에이전트 구성을 다시 실행할 수 있습니다.
전용 복사 에이전트가 있는 추출 에이전트 설치 및 구성
공유 스토리지와 전용 복사 에이전트가 있는 구성에서 추출 에이전트를 설치할 수 있습니다. 다음은 이 시나리오를 설명하는 다이어그램입니다
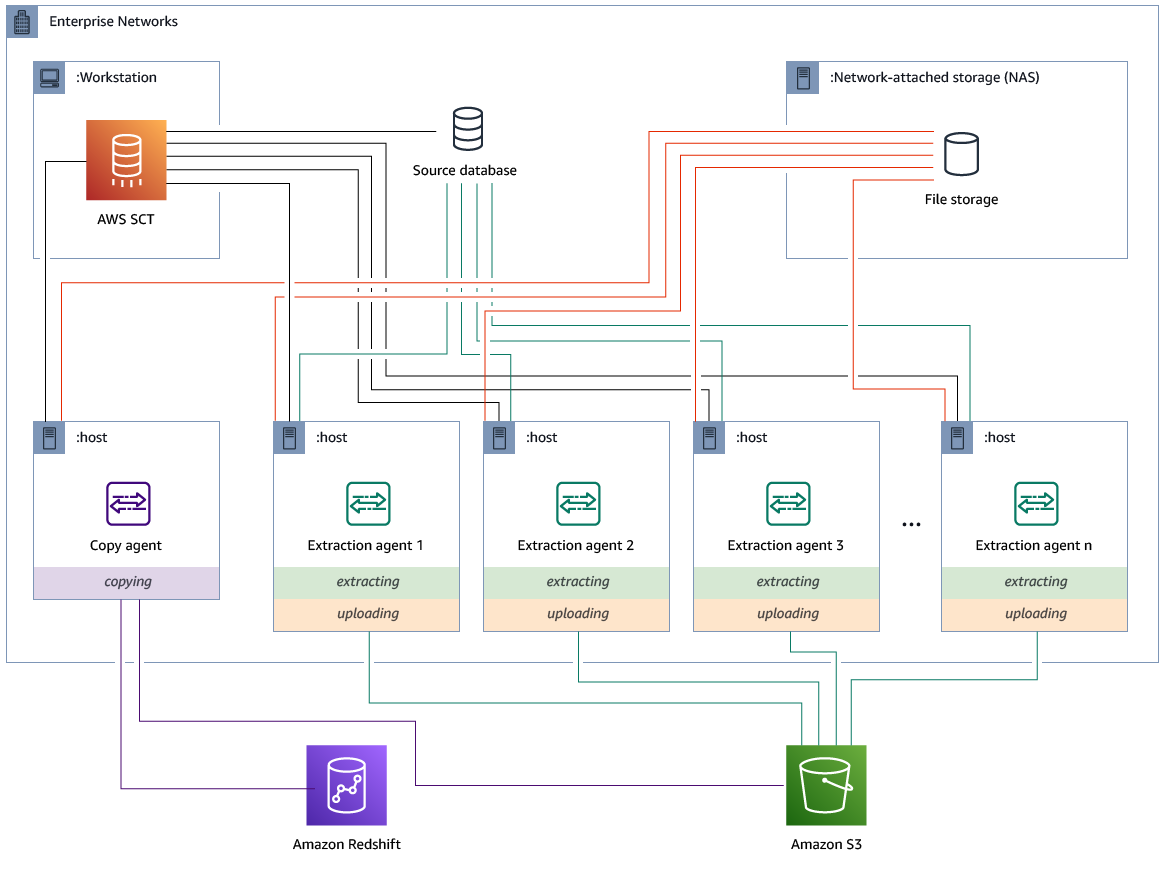
이 구성은 소스 데이터베이스 서버가 최대 120개의 연결을 지원하고 네트워크에 충분한 스토리지가 연결된 경우 유용할 수 있습니다. 다음 절차를 사용하여 전용 복사 에이전트가 있는 추출 에이전트를 구성합니다.
추출 에이전트와 전용 복사 에이전트를 설치 및 구성하려면
-
모든 추출 에이전트의 작업 디렉터리가 공유 스토리지의 동일한 폴더를 사용하는지 확인합니다.
-
추출 에이전트 설치의 단계에 따라 추출기 에이전트를 설치합니다.
-
추출 에이전트 구성의 단계에 따라 추출 에이전트를 구성하되 소스 JDBC 드라이버만 지정합니다.
-
추출 에이전트 구성의 단계에 따라 전용 복사 에이전트를 구성하되 Amazon Redshift JDBC 드라이버만 지정합니다.
추출 에이전트 시작
다음 절차에 따라 추출 에이전트를 시작합니다. 추출 에이전트가 설치된 각 컴퓨터에서 이 절차를 반복합니다.
추출 에이전트는 리스너의 역할을 합니다. 이 절차를 사용하여 에이전트를 시작하면 해당 에이전트가 명령의 수신 대기를 시작합니다. 이후 섹션에서는 데이터 웨어하우스에서 데이터를 추출하는 명령을 에이전트로 보냅니다.
추출 에이전트를 시작하려면
-
추출 에이전트가 설치된 컴퓨터에서 운영 체제에 따라 아래에 나온 명령을 실행합니다.
운영 체제 시작 명령 Microsoft Windows
StartAgent.bat배치 파일을 두 번 클릭합니다.RHEL
에이전트를 설치한 폴더 경로에서 다음 명령을 실행합니다.
sudo initctlstartsct-extractorUbuntu Linux
에이전트를 설치한 폴더 경로에서 다음 명령을 실행합니다. 사용 중인 Ubuntu 버전에 적합한 명령을 사용합니다.
Ubuntu 14.04:
sudo initctlstartsct-extractorUbuntu 15.04 이상:
sudo systemctlstartsct-extractor
에이전트의 상태를 확인하려면 동일한 명령을 실행하고 start를 status로 바꿉니다.
에이전트를 중지하려면 동일한 명령을 실행하고 start를 stop으로 바꿉니다.
에 추출 에이전트 등록 AWS Schema Conversion Tool
를 사용하여 추출 에이전트를 관리합니다 AWS SCT. 추출 에이전트가 리스너의 역할을 합니다. 에서 지침을 받으면 데이터 웨어하우스에서 데이터를 AWS SCT추출합니다.
다음 절차에 따라 AWS SCT 프로젝트에 추출 에이전트를 등록합니다.
추출 에이전트를 등록하려면
-
를 시작하고 프로젝트를 AWS Schema Conversion Tool엽니다.
-
보기 메뉴를 열고 Data Migration view (other)를 선택합니다. 에이전트 탭이 나타납니다. 이전에 에이전트를 등록한 경우 AWS SCT 는 탭 상단의 그리드에 해당 에이전트를 표시합니다.
-
등록을 선택합니다.
AWS SCT 프로젝트에 에이전트를 등록한 후에는 동일한 에이전트를 다른 프로젝트에 등록할 수 없습니다. AWS SCT 프로젝트에서 더 이상 에이전트를 사용하지 않는 경우 등록을 취소할 수 있습니다. 그런 다음, 다른 프로젝트에 등록할 수 있습니다.
-
Redshift 데이터 에이전트를 선택하고 확인을 선택합니다.
-
대화 상자의 연결 탭에 정보를 입력합니다.
-
설명에 에이전트의 설명을 입력합니다.
-
호스트 이름에 에이전트 컴퓨터의 호스트 이름 또는 IP 주소를 입력합니다.
-
포트에 에이전트가 수신 대기하는 포트 번호를 입력합니다.
-
등록을 선택하여 AWS SCT 프로젝트에 에이전트를 등록합니다.
-
-
AWS SCT 프로젝트에 여러 에이전트를 등록하려면 이전 단계를 반복합니다.
AWS SCT 에이전트에 대한 정보 숨기기 및 복구
AWS SCT 에이전트는 사용자 키-트러스트 스토어의 암호, 데이터베이스 계정, AWS 계정 정보 및 유사한 항목과 같은 상당한 양의 정보를 암호화합니다. seed.dat라는 특수 파일을 사용하여 이 작업을 수행합니다. 기본적으로 에이전트는 에이전트를 처음 구성한 사용자의 작업 폴더에 이 파일을 만듭니다.
여러 사용자가 에이전트를 구성하고 실행할 수 있으므로 seed.dat의 경로는 settings.properties 파일의 {extractor.private.folder} 파라미터에 저장됩니다. 에이전트가 시작되면 이 경로를 사용하여 에이전트가 작업을 수행하는 데이터베이스의 키 트러스트 스토어 정보에 액세스하는 데 사용할 seed.dat 파일을 찾을 수 있습니다.
다음과 같은 경우에는 에이전트가 저장한 암호를 복구해야 할 수 있습니다.
사용자가
seed.dat파일을 분실하고 AWS SCT 에이전트의 위치와 포트가 변경되지 않은 경우.사용자가
seed.dat파일을 분실하고 AWS SCT 에이전트의 위치와 포트가 변경된 경우. 이 경우 일반적으로 에이전트가 다른 호스트 또는 포트로 마이그레이션되어seed.dat파일의 정보가 더 이상 유효하지 않기 때문에 변경이 발생합니다.
이러한 경우 에이전트를 SSL 없이 시작하면 에이전트가 시작된 후 이전에 만든 에이전트 스토리지에 액세스합니다. 그러면 Waiting for recovery 상태로 전환됩니다.
하지만 이런 경우에는 에이전트가 SSL를 사용하여 시작되어도 에이전트를 다시 시작할 수 없습니다. 이는 에이전트가 settings.properties 파일에 저장된 인증서의 암호를 해독할 수 없기 때문입니다. 이 유형의 시작에서는 에이전트가 시작되지 않습니다. 다음과 비슷한 오류가 로그에 기록됩니다. “SSL 모드를 활성화한 상태에서 에이전트를 시작할 수 없습니다. 에이전트를 다시 구성하십시오. 원인: 키 스토어 암호가 올바르지 않습니다.”
이 문제를 해결하려면 새 에이전트를 만들고 SSL 인증서에 액세스하는 데 기존 암호를 사용하도록 에이전트를 구성합니다. 이렇게 하려면 다음 절차를 사용하세요.
이 절차를 수행한 후 에이전트는를 실행하고 복구 대기 중 상태로 전환해야 합니다.는 필요한 암호를 복구 대기 중 상태의 에이전트에게 AWS SCT 자동으로 전송합니다. 에이전트에 암호가 있으면 모든 작업이 다시 시작됩니다. AWS SCT 에서 추가적인 사용자 조치는 필요하지 않습니다.
에이전트를 재구성하고 SSL 인증서에 액세스하기 위한 암호를 복원하려면
새 AWS SCT 에이전트를 설치하고 구성을 실행합니다.
새 에이전트가 기존 에이전트 스토리지에서 작동하도록 하려면
instance.properties파일의agent.name속성을 스토리지를 만들 때 사용한 에이전트의 이름으로 변경합니다.instance.properties파일은 에이전트의 프라이빗 폴더에 저장되며, 이 폴더의 이름은{규칙에 따라 지정됩니다.output.folder}\dmt\{hostName}_{portNumber}\{의 이름을 이전 에이전트의 출력 폴더 이름으로 변경합니다.output.folder}이 시점에서 AWS SCT 는 여전히 이전 호스트 및 포트에서 이전 추출기에 액세스하려고 합니다. 따라서 액세스할 수 없는 추출기는 FAILED 상태가 됩니다. 그 다음, 호스트와 포트를 변경할 수 있습니다.
요청 흐름을 새 에이전트로 리디렉션하도록 수정 명령을 사용하여 이전 에이전트의 호스트, 포트 또는 둘 모두 수정합니다.
가 새 에이전트를 ping할 AWS SCT 수 있는 경우는 에이전트로부터 복구 대기 중 상태를 AWS SCT 수신합니다. AWS SCT 그런 다음는 에이전트의 암호를 자동으로 복구합니다.
에이전트 스토리지를 사용하는 각 에이전트는 {에 있는 output.folder}\{agentName}\storage\storage.lck라는 특수 파일을 업데이트합니다. 이 파일에는 에이전트의 네트워크 ID와 스토리지가 잠길 때까지의 시간이 포함되어 있습니다. 에이전트가 에이전트 스토리지로 작업할 경우 storage.lck 파일을 업데이트하고 스토리지 임대 기간을 5분마다 10분씩 연장합니다. 임대가 만료되기 전에는 다른 인스턴스가 이 에이전트 스토리지를 사용할 수 없습니다.
에서 데이터 마이그레이션 규칙 생성 AWS SCT
를 사용하여 데이터를 추출하기 전에 추출하는 데이터의 양을 줄이는 필터를 설정할 AWS Schema Conversion Tool수 있습니다. WHERE 절을 사용하여 데이터 마이그레이션 규칙을 만들면 추출하는 데이터를 줄일 수 있습니다. 예를 들어 단일 테이블에서 데이터를 선택하는 WHERE 절을 작성할 수 있습니다.
데이터 마이그레이션 규칙을 생성하고 필터를 프로젝트의 일부로 저장할 수 있습니다. 프로젝트를 연 상태에서 다음 절차를 사용하여 데이터 마이그레이션 규칙을 생성합니다.
데이터 마이그레이션 규칙을 만들려면
-
보기 메뉴를 열고 Data Migration view (other)를 선택합니다.
-
Data migration rules를 선택한 다음, 새 규칙 추가를 선택합니다.
-
데이터 마이그레이션 규칙을 구성합니다.
-
이름에 데이터 마이그레이션 규칙의 이름을 입력합니다.
-
Where schema name is like에, 스키마에 적용할 필터를 입력합니다. 이 필터에서는
LIKE절을 사용하여WHERE절을 평가합니다. 스키마 하나를 선택하려면 정확한 스키마 이름을 입력합니다. 여러 스키마를 선택하려면 “%” 문자를 와일드카드로 사용하여 스키마 이름에서 원하는 문자 수와 일치시킵니다. -
table name like에, 테이블에 적용할 필터를 입력합니다. 이 필터에서는
LIKE절을 사용하여WHERE절을 평가합니다. 테이블 하나를 선택하려면 정확한 이름을 입력합니다. 여러 테이블을 선택하려면 “%” 문자를 와일드카드로 사용하여 테이블 이름에서 원하는 문자 수와 일치시킵니다. -
Where 절에 데이터를 필터링할
WHERE절을 입력합니다.
-
-
필터를 구성한 후 저장을 선택하여 필터를 저장하거나 취소를 선택하여 변경 내용을 취소합니다.
-
필터 추가, 편집 및 삭제를 완료한 후 모두 저장을 선택하여 변경 내용을 모두 저장합니다.
필터를 삭제하지 않고 끄려면 토글 아이콘을 사용합니다. 기존 필터를 복제하려면 복사 아이콘을 사용합니다. 기존 필터를 삭제하려면 삭제 아이콘을 사용합니다. 필터 변경 내용을 저장하려면 모두 저장을 선택합니다.
프로젝트 설정에서 추출기 및 복사 설정 변경
의 프로젝트 설정 창에서 데이터 추출 에이전트 및 Amazon Redshift COPY 명령에 대한 설정을 선택할 AWS SCT수 있습니다.
이러한 설정을 선택하려면 설정, 프로젝트 설정을 선택한 다음, 데이터 마이그레이션을 선택합니다. 여기에서 추출 설정, Amazon S3 설정 및 복사 설정을 편집할 수 있습니다.
다음 테이블의 지침을 사용하여 추출 설정에 대한 정보를 제공합니다.
| 이 파라미터의 경우 | 조치 |
|---|---|
압축 형식 |
입력 파일의 압축 형식을 지정합니다. GZIP, BZIP2, ZSTD 또는 압축 없음 옵션 중 하나를 선택합니다. |
구분 기호 문자 |
입력 파일의 필드를 구분하는 ASCII 문자를 지정합니다. 인쇄되지 않는 문자는 지원되지 않습니다. |
NULL value as a string |
데이터에 null 종결자가 포함된 경우 이 옵션을 켭니다. 이 옵션을 끄면 Amazon Redshift |
Sorting strategy |
정렬을 사용하여 실패 지점부터 추출을 다시 시작합니다. Use sorting after the first fail (recommended), Use sorting if possible 또는 Never use sorting 등의 정렬 전략 중 하나를 선택합니다. 자세한 내용은 를 사용하여 마이그레이션하기 전에 데이터 정렬 AWS SCT 단원을 참조하십시오. |
Source temp schema |
추출 에이전트가 임시 객체를 생성할 수 있는 소스 데이터베이스의 스키마 이름을 입력합니다. |
Out file size (in MB) |
Amazon S3에 업로드된 파일의 크기를 MB 단위로 입력합니다. |
Snowball out file size (in MB) |
업로드된 파일의 크기를 MB 단위로 입력합니다 AWS Snowball Edge. 파일의 크기는 1~1,000MB일 수 있습니다. |
Use automatic partitioning. Greenplum과 Netezza의 경우 지원되는 테이블의 최소 크기를 MB 단위로 입력 |
테이블 파티셔닝을 사용하려면 이 옵션을 켠 다음, Greenplum 및 Netezza 소스 데이터베이스를 분할할 테이블 크기를 입력합니다. Oracle에서 Amazon Redshift로 마이그레이션하는 경우 AWS SCT 는 분할된 모든 테이블에 대한 하위 작업을 생성하기 때문에이 필드를 비워 둘 수 있습니다. |
Extract LOBs |
소스 데이터베이스에서 큰 객체(LOB)를 추출하려면 이 옵션을 켭니다. LOB에는 BLOB, CLOB, NCLOB, XML 파일 등이 포함됩니다. AWS SCT 추출 에이전트는 모든 LOB에 대해 데이터 파일을 생성합니다. |
Amazon S3 bucket LOBs folder |
AWS SCT 추출 에이전트가 LOBs를 저장할 위치를 입력합니다. |
Apply RTRIM to string columns |
추출된 문자열 끝에서 지정된 문자 세트를 트리밍하려면 이 옵션을 켭니다. |
Keep files locally after upload to Amazon S3 |
데이터 추출 에이전트가 Amazon S3에 파일을 업로드한 후 로컬 시스템에 파일을 유지하려면 이 옵션을 켭니다. |
다음 테이블의 지침을 사용하여 Amazon S3 설정에 대한 정보를 제공합니다.
| 이 파라미터의 경우 | 조치 |
|---|---|
프록시 사용 |
프록시 서버를 사용하여 Amazon S3에 데이터를 업로드하려면 이 옵션을 켭니다. 그런 다음 데이터 전송 프로토콜을 선택하고 호스트 이름, 포트, 사용자 이름 및 암호를 입력합니다. |
[엔드포인트 유형] |
Federal Information Processing Standard(FIPS) 엔드포인트를 사용하려면 FIPS를 선택합니다. Virtual Private Cloud(VPC) 엔드포인트를 사용하려면 VPCE를 선택합니다. 그런 다음 VPC 엔드포인트에 VPC 엔드포인트의 도메인 이름 시스템(DNS)을 입력합니다. |
Keep files on Amazon S3 after copying to Amazon Redshift |
추출된 파일을 Amazon Redshift에 복사한 후 Amazon S3에 유지하려면 이 옵션을 켭니다. |
다음 테이블의 지침을 사용하여 복사 설정에 대한 정보를 제공합니다.
| 이 파라미터의 경우 | 조치 |
|---|---|
Maximum error count |
로드 오류 개수를 입력합니다. 작업이이 한도에 도달하면 AWS SCT 데이터 추출 에이전트는 데이터 로드 프로세스를 종료합니다. 기본값은 0입니다. 즉, AWS SCT 데이터 추출 에이전트는 실패에 관계없이 데이터 로드를 계속합니다. |
Replace not valid UTF-8 characters |
유효하지 않은 UTF-8 문자를 지정된 문자로 바꾸고 데이터 로드 작업을 계속하려면 이 옵션을 켭니다. |
Use blank as null value |
공백 문자로 구성된 빈 필드를 null로 로드하려면 이 옵션을 켭니다. |
Use empty as null value |
비어 있는 |
Truncate columns |
데이터 유형의 사양에 맞게 열의 데이터를 자르려면 이 옵션을 켭니다. |
Automatic compression |
복사 작업 중에 압축 인코딩을 적용하려면 이 옵션을 켭니다. |
Automatic statistics refresh |
복사 작업 종료 시 통계를 새로 고치려면 이 옵션을 켭니다. |
Check file before load |
Amazon Redshift에 데이터 파일을 로드하기 전에 해당 데이터 파일을 검증하려면 이 옵션을 켭니다. |
를 사용하여 마이그레이션하기 전에 데이터 정렬 AWS SCT
로 마이그레이션하기 전에 데이터를 정렬하면 몇 가지 이점 AWS SCT 이 있습니다. 데이터를 먼저 정렬하는 경우는 실패 후 마지막으로 저장된 지점에서 추출 에이전트를 다시 시작할 수 AWS SCT 있습니다. 또한 데이터를 Amazon Redshift로 마이그레이션하고 데이터를 먼저 정렬하는 경우는 Amazon Redshift에 더 빠르게 데이터를 삽입할 AWS SCT 수 있습니다.
이러한 이점은가 데이터 추출 쿼리를 AWS SCT 생성하는 방법과 관련이 있습니다. 경우에 따라 이러한 쿼리에서 DENSE_RANK 분석 함수를 AWS SCT 사용합니다. 그러나 DENSE_RANK는 많은 시간과 서버 리소스를 사용하여 추출에서 발생하는 데이터 세트를 정렬할 수 있으므로가 데이터 세트 없이 작동할 AWS SCT 수 있다면 그렇게 됩니다.
를 사용하여 마이그레이션하기 전에 데이터를 정렬하려면 AWS SCT
AWS SCT 프로젝트를 엽니다.
객체의 컨텍스트(마우스 오른쪽 버튼 클릭) 메뉴를 열고 Create Local task를 선택합니다.
고급 탭을 선택하고 Sorting strategy에서 다음 옵션 중 하나를 선택합니다.
Never use sorting – 추출 에이전트가 DENSE_RANK 분석 함수를 사용하지 않으며 오류가 발생할 경우 처음부터 다시 시작합니다.
Use sorting if possible – 테이블에 프라이머리 키 또는 고유한 제약 조건이 있는 경우 추출 에이전트는 DENSE_RANK를 사용합니다.
Use sorting after first fail (recommended) - 추출 에이전트가 먼저 DENSE_RANK를 사용하지 않고 데이터를 가져오려고 합니다. 첫 번째 시도에 실패하면 추출 에이전트가 DENSE_RANK를 사용하여 쿼리를 다시 작성하고 실패 시 해당 위치를 보존합니다.
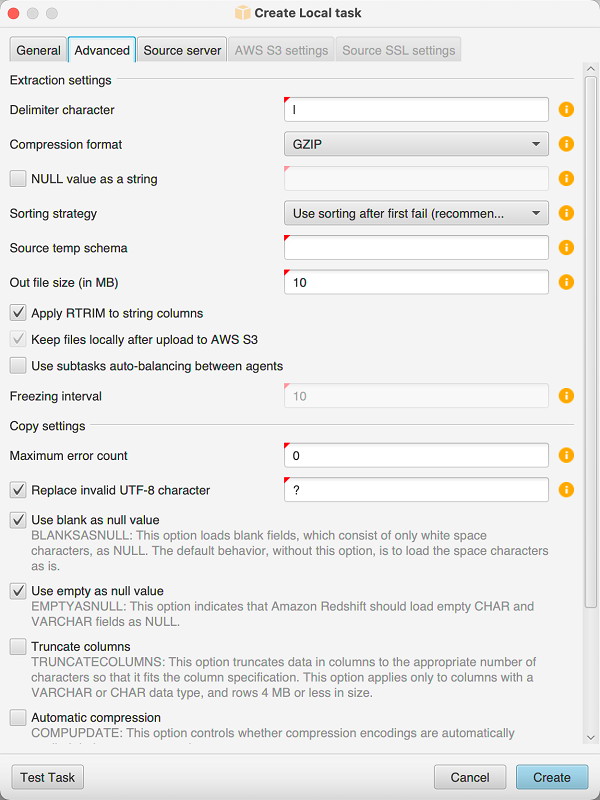
아래에서 설명한 대로 추가 파라미터를 설정하고 생성을 선택하여 데이터 추출 작업을 생성합니다.
AWS SCT 데이터 추출 작업 생성, 실행 및 모니터링
다음 절차를 사용하여 데이터 추출 작업을 작성, 실행 및 모니터링합니다.
에이전트에 작업을 할당하고 데이터를 마이그레이션하려면
-
에서 스키마를 변환한 AWS Schema Conversion Tool후 프로젝트의 왼쪽 패널에서 테이블을 하나 이상 선택합니다.
모든 테이블을 선택할 수 있지만 성능상의 이유로 그렇게 하지 않는 것이 좋습니다. 데이터 웨어하우스의 테이블 크기에 따라 여러 테이블에 대해 여러 작업을 생성하는 것이 좋습니다.
-
각 테이블에 대한 컨텍스트(마우스 오른쪽 버튼 클릭) 메뉴를 연 다음, 태스크 생성을 선택합니다. Create Local task 대화 상자가 열립니다.
-
작업 이름에 해당 작업의 이름을 입력합니다.
-
Migration mode에서 다음 중 하나를 선택합니다.
-
Extract only - 데이터를 추출한 후 로컬 작업 폴더에 데이터를 저장합니다.
-
Extract and upload - 데이터를 추출한 후 Amazon S3에 데이터를 업로드합니다.
-
Extract, upload and copy - 데이터를 추출하고 Amazon S3에 데이터를 업로드한 다음, Amazon Redshift 데이터 웨어하우스로 복사합니다.
-
-
암호화 유형에서 다음 중 하나를 선택합니다.
-
없음 - 전체 데이터 마이그레이션 프로세스에서 데이터 암호화를 끕니다.
-
CSE_SK - 대칭 키를 사용한 클라이언트측 암호화를 통해 데이터를 마이그레이션합니다. AWS SCT 가 자동으로 암호화 키를 생성하고 Secure Sockets Layer(SSL)를 사용하여 이 키를 데이터 추출 에이전트에 전송합니다. 데이터 마이그레이션 중에는 AWS SCT 에서 큰 객체(LOB)를 암호화하지 않습니다.
-
-
큰 객체를 추출하려면 Extract LOBs를 선택합니다. 큰 객체를 추출할 필요가 없으면 해당 확인란을 선택 취소할 수 있습니다. 그러면 추출하는 데이터의 양이 줄어듭니다.
-
작업에 대한 세부 정보를 보려면 Enable task logging을 선택합니다. 작업 로그를 사용하여 문제를 디버깅할 수 있습니다.
작업 로깅을 활성화하는 경우 보려는 세부 정보 수준을 선택합니다. 수준은 다음과 같으며, 각 수준에는 이전 수준의 모든 메시지가 포함됩니다.
ERROR– 가장 적은 양의 세부 정보입니다.WARNINGINFODEBUGTRACE– 가장 많은 양의 세부 정보입니다.
-
BigQuery에서 데이터를 내보내려면 Google Cloud Storage 버킷 폴더를 AWS SCT 사용합니다. 데이터 추출 에이전트가 이 폴더에 소스 데이터를 저장합니다.
Google Cloud Storage 버킷 폴더의 경로를 입력하려면 고급을 선택합니다. Google CS bucket folder에 버킷 이름과 폴더 이름을 입력합니다.
-
데이터 추출 에이전트 사용자 역할을 맡으려면 Amazon S3 설정을 선택합니다. IAM role에, 사용할 역할의 이름을 입력합니다. 리전에서이 역할의 AWS 리전 를 선택합니다.
-
Test task를 선택하여 작업 폴더, Amazon S3 버킷 및 Amazon Redshift 데이터 웨어하우스에 연결할 수 있는지 확인합니다. 확인 방법은 선택한 마이그레이션 모드에 따라 달라집니다.
-
생성을 선택하여 작업을 생성합니다.
-
이전 단계를 반복하여 마이그레이션하려는 모든 데이터에 대한 작업을 생성합니다.
작업을 실행 및 모니터링하려면
-
보기에서 Data Migration view를 선택합니다. 에이전트 탭이 나타납니다.
-
작업 탭을 선택합니다. 작업이 다음과 같이 상단 그리드에 표시됩니다. 위쪽 그리드에서는 작업 상태를 확인하고 아래쪽 그리드에서는 하위 작업 상태를 확인할 수 있습니다.
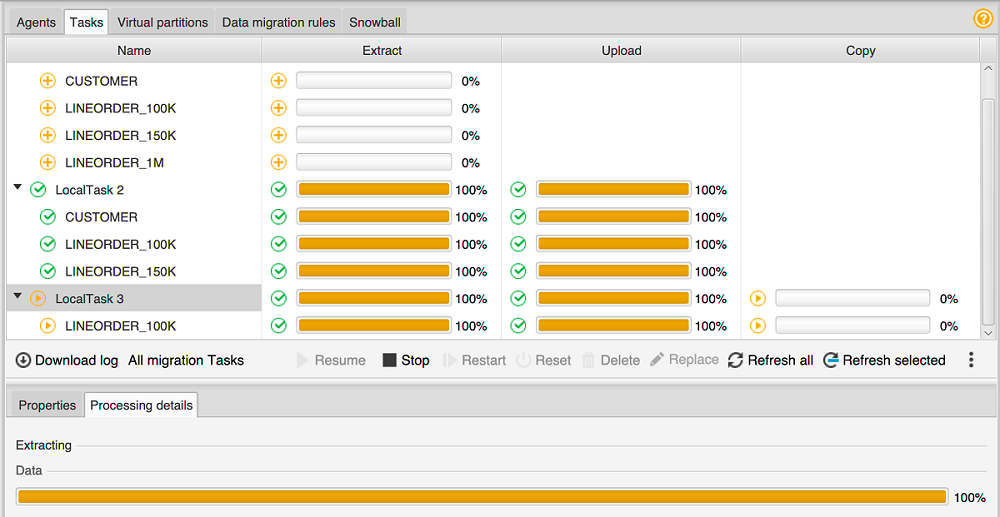
-
위쪽 그리드에서 작업을 선택하고 확장합니다. 선택한 마이그레이션 모드에 따라 작업이 추출, 업로드, 복사로 구분되어 표시됩니다.
-
작업에 대해 시작을 선택하여 해당 작업을 시작합니다. 작업이 진행되는 동안 작업의 상태를 모니터링할 수 있습니다. 하위 작업은 병렬로 실행됩니다. 또한 추출, 업로드 및 복사도 병렬로 실행됩니다.
-
작업을 설정할 때 로깅을 활성화한 경우에는 로그를 볼 수 있습니다.
-
로그 다운로드를 선택합니다. 로그 파일이 있는 폴더의 이름과 함께 메시지가 나타납니다. 메시지를 닫습니다.
-
태스크 세부 정보 탭에 링크가 표시됩니다. 링크를 선택하여 로그 파일이 있는 폴더를 엽니다.
-
종료해도 에이전트와 태스크는 계속 실행 AWS SCT됩니다. AWS SCT 나중에 다시 열어 작업 상태를 확인하고 작업 로그를 볼 수 있습니다.
데이터 추출 작업을 로컬 디스크에 저장한 후 내보내기와 가져오기를 사용하여 같은 프로젝트 또는 다른 프로젝트에 복원할 수 있습니다. 작업을 내보내려면 프로젝트에 추출 작업이 하나 이상 생성되어 있어야 합니다. 단일 추출 작업 또는 프로젝트에서 만든 모든 작업을 가져올 수 있습니다.
추출 작업을 내보낼 때는 해당 작업에 대해 별도의 .xml 파일을 AWS SCT 생성합니다. .xml 파일에는 작업의 메타데이터 정보(예: 작업 속성, 설명, 하위 작업 등)가 저장됩니다. .xml 파일에 추출 작업 처리에 대한 정보는 포함되지 않습니다. 작업을 가져오면 다음과 같은 정보가 다시 생성됩니다.
-
작업 진행 상황
-
하위 작업 및 스테이지 상태
-
하위 작업 및 스테이지별 추출 에이전트 분포
-
작업 및 하위 작업 ID
-
[Task name]
AWS SCT 데이터 추출 작업 내보내기 및 가져오기
AWS SCT 내보내기 및 가져오기를 사용하여 한 프로젝트에서 기존 작업을 빠르게 저장하고 다른 프로젝트(또는 동일한 프로젝트)에서 복원할 수 있습니다. 데이터 추출 작업을 내보내고 가져오려면 다음 절차를 따릅니다.
데이터 추출 작업을 내보내고 가져오려면
-
보기에서 Data Migration view를 선택합니다. 에이전트 탭이 나타납니다.
-
작업 탭을 선택합니다. 표시되는 그리드에 작업이 나열됩니다.
-
작업 목록 아래의 오른쪽 하단 모서리에 있는 세로로 정렬된 세 개의 점(줄임표 아이콘)을 선택합니다.
-
팝업 메뉴에서 내보내기 작업을 선택합니다.
-
작업 내보내기
.xml파일을 배치 AWS SCT 할 폴더를 선택합니다.AWS SCT 는 파일 이름 형식이 인 작업 내보내기 파일을 생성합니다
TASK-DESCRIPTION_TASK-ID.xml -
작업 목록 아래의 오른쪽 하단에 있는 세로로 정렬된 세 개의 점(줄임표 아이콘)을 선택합니다.
-
팝업 메뉴에서 가져오기 작업을 선택합니다.
소스 데이터베이스에 연결된 프로젝트로 추출 작업을 가져올 수 있으며, 프로젝트에는 등록된 활성 추출 에이전트가 하나 이상 있습니다.
-
내보낸 추출 작업에 사용할
.xml파일을 선택합니다.AWS SCT 는 파일에서 추출 작업의 파라미터를 가져와 작업을 생성하고 추출 에이전트에 작업을 추가합니다.
-
추가로 데이터 추출 작업을 내보내고 가져오려면 이 단계를 반복합니다.
이 프로세스가 끝나면 내보내기와 가져오기가 완료되고 데이터 추출 작업을 사용할 준비가 됩니다.
AWS Snowball Edge Edge 디바이스를 사용한 데이터 추출
AWS SCT 및 AWS Snowball Edge Edge를 사용하는 프로세스에는 여러 단계가 있습니다. 마이그레이션에는가 데이터 추출 에이전트를 AWS SCT 사용하여 데이터를 AWS Snowball Edge Edge 디바이스로 이동하는 로컬 작업과가 AWS Snowball Edge Edge 디바이스에서 Amazon S3 버킷으로 데이터를 AWS 복사하는 중간 작업이 포함됩니다. 이 프로세스는 Amazon S3 버킷에서 Amazon Redshift로 데이터 AWS SCT 로드를 완료합니다.
이 개요의 다음 섹션에서는 이러한 각 작업에 대한 단계별 지침을 제공합니다. 이 절차에서는를 AWS SCT 설치하고 전용 시스템에 데이터 추출 에이전트를 구성하고 등록했다고 가정합니다.
AWS Snowball Edge Edge를 사용하여 로컬 데이터 스토어에서 AWS 데이터 스토어로 데이터를 마이그레이션하려면 다음 단계를 수행합니다.
AWS Snowball Edge 콘솔을 사용하여 AWS Snowball Edge Edge 작업을 생성합니다.
로컬 전용 Linux 시스템을 사용하여 AWS Snowball Edge Edge 디바이스의 잠금을 해제합니다.
에서 새 프로젝트를 생성합니다 AWS SCT.
데이터 추출 에이전트를 설치 및 구성합니다.
Amazon S3 버킷에 사용할 권한을 생성하고 설정합니다.
AWS Snowball Edge AWS SCT 작업을 프로젝트로 가져옵니다.
AWS SCT에 데이터 추출 에이전트를 등록합니다.
에서 로컬 작업을 생성합니다 AWS SCT.
AWS SCT에서 데이터 마이그레이션 작업을 실행하고 모니터링합니다.
AWS SCT 및 AWS Snowball Edge Edge를 사용하여 데이터를 마이그레이션하기 위한 Step-by-step 절차
다음 섹션에서는 마이그레이션 단계에 대한 자세한 정보를 제공합니다.
1단계: AWS Snowball Edge Edge 작업 생성
Edge AWS Snowball Edge 개발자 안내서의 엣지 AWS Snowball Edge 작업 생성 섹션에 설명된 단계에 따라 작업을 생성합니다. AWS Snowball Edge
2단계: AWS Snowball Edge Edge 디바이스 잠금 해제
AWS DMS 에이전트를 설치한 시스템에서 Snowball Edge Edge 디바이스를 잠금 해제하고 자격 증명을 제공하는 명령을 실행합니다. 이러한 명령을 실행하면 AWS DMS 에이전트 호출이 AWS Snowball Edge Edge 디바이스에 연결되도록 할 수 있습니다. AWS Snowball Edge Edge 디바이스 잠금 해제에 대한 자세한 내용은 Snowball Edge Edge 잠금 해제를 참조하세요.
aws s3 ls s3://<bucket-name> --profile <Snowball Edge profile> --endpoint http://<Snowball IP>:8080 --recursive
3단계: 새 AWS SCT 프로젝트 생성
그런 다음 새 AWS SCT 프로젝트를 생성합니다.
에서 새 프로젝트를 생성하려면 AWS SCT
-
를 시작합니다 AWS Schema Conversion Tool. 파일 메뉴에서 새 프로젝트를 선택합니다. 새 프로젝트 대화 상자가 나타납니다.
-
컴퓨터에서 로컬로 저장되는 프로젝트의 이름을 입력합니다.
-
로컬 프로젝트 파일의 위치를 입력합니다.
-
확인을 선택하여 AWS SCT 프로젝트를 생성합니다.
-
소스 추가를 선택하여 AWS SCT 프로젝트에 새 소스 데이터베이스를 추가합니다.
-
대상 추가를 선택하여 AWS SCT 프로젝트에 새 대상 플랫폼을 추가합니다.
-
왼쪽 패널에서 소스 데이터베이스 스키마를 선택합니다.
-
오른쪽 패널에서 선택한 소스 스키마의 대상 데이터베이스 플랫폼을 지정합니다.
-
매핑 생성을 선택합니다. 이 버튼은 소스 데이터베이스 스키마와 대상 데이터베이스 플랫폼을 선택한 후에 활성화됩니다.
4단계: 데이터 추출 에이전트 설치 및 구성
AWS SCT 는 데이터 추출 에이전트를 사용하여 데이터를 Amazon Redshift로 마이그레이션합니다. 설치하기 위해 다운로드한 .zip 파일에는 추출 에이전트 설치 프로그램 파일이 AWS SCT포함되어 있습니다. Windows, Red Hat Enterprise Linux 또는 Ubuntu에 데이터 추출 에이전트를 설치할 수 있습니다. 자세한 내용은 추출 에이전트 설치 단원을 참조하십시오.
데이터 추출 에이전트를 구성하려면 소스 및 대상 데이터베이스 엔진을 입력합니다. 또한 데이터 추출 에이전트를 실행하는 컴퓨터에 소스 및 대상 데이터베이스용 JDBC 드라이버를 다운로드했는지 확인합니다. 데이터 추출 에이전트는 이 드라이버를 사용하여 소스 및 대상 데이터베이스에 연결합니다. 자세한 내용은 용 JDBC 드라이버 설치 AWS Schema Conversion Tool 단원을 참조하십시오.
Windows에서는 데이터 추출 에이전트 설치 관리자가 명령 프롬프트 창에서 구성 마법사를 시작합니다. Linux에서는 에이전트를 설치한 위치에서 sct-extractor-setup.sh 파일을 실행합니다.
5단계: Amazon S3 버킷에 액세스 AWS SCT 하도록 구성
Amazon S3 버킷 구성에 대한 자세한 내용은 Amazon Simple Storage Service 사용 설명서의 버킷 개요를 참조하세요.
6단계: AWS SCT 프로젝트에 AWS Snowball Edge 작업 가져오기
AWS SCT 프로젝트를 AWS Snowball Edge Edge 디바이스에 연결하려면 AWS Snowball Edge 작업을 가져옵니다.
AWS Snowball Edge 작업을 가져오려면
-
설정 메뉴를 열고 전역 설정을 선택합니다. 전역 설정 대화 상자가 나타납니다.
-
AWS 서비스 프로필을 선택한 다음, 작업 가져오기를 선택합니다.
AWS Snowball Edge 작업을 선택합니다.
-
AWS Snowball Edge IP를 입력합니다. 자세한 내용은 AWS Snowball Edge 사용 설명서에서 IP 주소 변경을 참조하세요.
-
AWS Snowball Edge 포트를 입력합니다. 자세한 내용은 Edge 개발자 안내서의 AWS Snowball Edge Edge 디바이스에서 AWS 서비스를 사용하는 데 필요한 포트를 참조하세요. AWS Snowball Edge
-
AWS Snowball Edge 액세스 키와 AWS Snowball Edge 비밀 키를 입력합니다. 자세한 내용은 AWS Snowball Edge 사용 설명서의 AWS Snowball Edge에서 권한 부여 및 액세스 제어를 참조하세요.
적용을 선택하고 확인을 선택합니다.
7단계:에 데이터 추출 에이전트 등록 AWS SCT
이 섹션에서는 데이터 추출 에이전트를 AWS SCT에 등록합니다.
데이터 추출 에이전트를 등록하려면
-
보기 메뉴에서 Data migration view (other)를 선택한 다음, 등록을 선택합니다.
-
설명에 데이터 추출 에이전트의 이름을 입력합니다.
-
호스트 이름에 데이터 추출 에이전트를 실행하는 컴퓨터의 IP 주소를 입력합니다.
-
포트에는 구성된 수신 포트를 입력합니다.
-
등록을 선택합니다.
8단계: 로컬 작업 생성
다음으로, 마이그레이션 작업을 생성합니다. 이 작업에는 하위 작업 두 개가 포함됩니다. 하나의 하위 작업은 소스 데이터베이스에서 AWS Snowball Edge Edge 어플라이언스로 데이터를 마이그레이션합니다. 또 다른 하위 작업은 어플라이언스에서 Amazon S3 버킷으로 로드하는 데이터를 가져와서 이를 대상 데이터베이스로 마이그레이션합니다.
마이그레이션 작업을 생성하려면
-
보기 메뉴에서 Data migration view (other)를 선택합니다.
소스 데이터베이스의 스키마를 표시하는 왼쪽 패널에서 마이그레이션할 스키마 객체를 선택합니다. 객체의 컨텍스트(마우스 오른쪽 버튼 클릭) 메뉴를 열고 Create local task를 선택합니다.
-
작업 이름에 데이터 마이그레이션 작업을 설명하는 이름을 입력합니다.
-
Migration mode에서 Extract, upload, and copy를 선택합니다.
-
Amazon S3 settings를 선택합니다.
-
Snowball Edge 사용을 선택합니다.
-
데이터 추출 에이전트가 데이터를 저장할 수 있는 Amazon S3 버킷의 폴더와 하위 폴더를 입력합니다.
-
생성을 선택하여 작업을 생성합니다.
9단계:에서 데이터 마이그레이션 작업 실행 및 모니터링 AWS SCT
데이터 마이그레이션 작업을 시작하려면 시작을 선택합니다. 소스 데이터베이스, Amazon S3 버킷, AWS Snowball Edge 디바이스에 대한 연결과 대상 데이터베이스에 대한 연결을 설정했는지 확인합니다 AWS.
작업 탭에서 데이터 마이그레이션 작업과 해당 하위 작업을 모니터링하고 관리할 수 있습니다. 데이터 마이그레이션 진행 상황을 확인하고 데이터 마이그레이션 작업을 일시 중지하거나 다시 시작할 수 있습니다.
데이터 추출 작업 출력
마이그레이션 작업이 완료되면 데이터가 준비됩니다. 선택한 마이그레이션 모드 및 데이터 위치에 따라 작업 진행 방법을 결정하려면 다음 정보를 사용합니다.
| 마이그레이션 모드 | 데이터 위치 |
|---|---|
|
추출, 업로드 및 복사 |
데이터는 Amazon Redshift 데이터 웨어하우스에 이미 있습니다. 데이터가 있는지 확인한 후 사용할 수 있습니다. 자세한 내용은 클라이언트 도구 및 코드에서 클러스터에 연결을 참조하세요. |
|
추출 및 업로드 |
추출 에이전트가 데이터를 Amazon S3 버킷에 파일로 저장했습니다. Amazon Redshift COPY 명령을 사용하여 Amazon Redshift에 데이터를 로드할 수 있습니다. 자세한 내용은 Amazon Redshift 설명서의 Amazon S3에서 데이터 로드를 참조하세요. Amazon S3 버킷에는 설정된 추출 작업에 해당하는 여러 폴더가 있습니다. Amazon Redshift로 데이터를 로드할 때 각 작업에서 생성한 매니페스트 파일의 이름을 지정합니다. 매니페스트 파일은 다음과 같이 Amazon S3 버킷의 작업 폴더에 나타납니다. 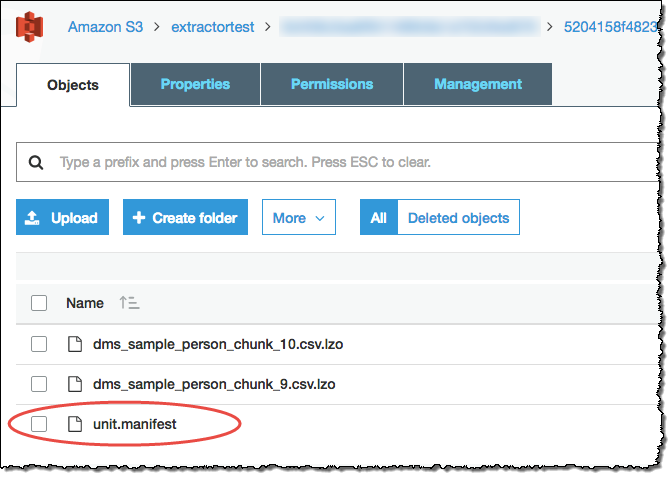
|
|
추출만 |
추출 에이전트가 데이터를 작업 폴더에 파일로 저장했습니다. Amazon S3 버킷에 데이터를 수동으로 복사한 다음, 추출 및 업로드를 위한 명령을 사용하여 작업을 진행합니다. |
에서 가상 파티셔닝 사용 AWS Schema Conversion Tool
필터링 규칙을 사용하여 테이블 데이터의 가상 파티션을 생성하는 하위 작업을 만들면 분할되지 않은 큰 테이블을 최적으로 관리할 수 있습니다. 에서 마이그레이션된 데이터에 대한 가상 파티션을 생성할 AWS SCT수 있습니다. 특정 데이터 유형에 사용할 수 있는 세 가지 파티션 유형이 있습니다.
RANGE 파티션 유형은 숫자 및 날짜/시간 데이터 유형에서 작동합니다.
LIST 파티션 유형은 숫자, 문자 및 날짜/시간 데이터 유형에서 작동합니다.
DATE AUTO SPLIT 파티션 유형은 숫자, 날짜 및 시간 데이터 유형에서 작동합니다.
AWS SCT 는 파티션을 생성하기 위해 제공하는 값을 검증합니다. 예를 들어 데이터 형식이 NUMERIC인 열을 분할하려고 하지만 다른 데이터 형식의 값을 제공하면 오류가 AWS SCT 발생합니다.
또한 AWS SCT 를 사용하여 Amazon Redshift로 데이터를 마이그레이션하는 경우 기본 파티셔닝을 사용하여 대규모 테이블에서 마이그레이션을 관리할 수 있습니다. 자세한 내용은 네이티브 파티셔닝 사용 단원을 참조하십시오.
가상 파티셔닝 생성 시 제한
가상 파티션을 만들 때는 다음과 같은 제한 사항이 있습니다.
분할되지 않은 테이블에만 가상 파티셔닝을 사용할 수 있습니다.
데이터 마이그레이션 보기에서만 가상 파티셔닝을 사용할 수 있습니다.
UNION ALL VIEW 옵션은 가상 파티셔닝에서 사용할 수 없습니다.
RANGE 파티션 유형
RANGE 파티션 유형은 숫자 및 날짜/시간 데이터 유형의 열 값 범위를 기반으로 데이터를 분할합니다. 이 파티션 유형은 WHERE 절을 생성하며 각 파티션의 값 범위를 제공합니다. 분할된 열의 값 목록을 지정하려면 값 상자를 사용합니다. .csv 파일을 사용하여 값 정보를 로드할 수 있습니다.
RANGE 파티션 유형은 파티션 값의 양쪽 끝에서 기본 파티션을 만듭니다. 이러한 기본 파티션은 지정된 파티션 값보다 작거나 큰 데이터를 모두 포착합니다.
예를 들어, 제공된 값 범위를 기반으로 여러 개의 파티션을 만들 수 있습니다. 다음 예에서는 LO_TAX의 파티셔닝 값을 지정하여 여러 파티션을 생성합니다.
Partition1: WHERE LO_TAX <= 10000.9 Partition2: WHERE LO_TAX > 10000.9 AND LO_TAX <= 15005.5 Partition3: WHERE LO_TAX > 15005.5 AND LO_TAX <= 25005.95
RANGE 가상 파티션을 만들려면
를 엽니다 AWS SCT.
Data Migration view (other) 모드를 선택합니다.
가상 파티셔닝을 설정할 테이블을 선택합니다. 테이블에 대한 컨텍스트(마우스 오른쪽 버튼 클릭) 메뉴를 열고 Add virtual partitioning을 선택합니다.
Add virtual partitioning 대화 상자에 다음과 같이 정보를 입력합니다.
옵션 작업 파티션 유형
RANGE를 선택합니다. 선택한 유형에 따라 대화 상자 UI가 달라집니다.
열 이름
분할하려는 열을 선택합니다.
열 유형
열의 값에 대한 데이터 유형을 선택합니다.
값
새 값 상자에 각 값을 입력한 다음, 더하기 기호를 선택하여 값을 추가하면 새 값을 추가할 수 있습니다.
파일에서 로드
(선택 사항) 파티션 값이 포함된 .csv 파일의 이름을 입력합니다.
-
확인을 선택합니다.
LIST 파티션 유형
LIST 파티션 유형은 숫자, 문자, 날짜/시간 데이터 형식의 열 값을 기반으로 데이터를 분할합니다. 이 파티션 유형은 WHERE 절을 생성하며 각 파티션의 값을 제공합니다. 분할된 열의 값 목록을 지정하려면 값 상자를 사용합니다. .csv 파일을 사용하여 값 정보를 로드할 수 있습니다.
예를 들어, 제공된 값을 기반으로 여러 개의 파티션을 만들 수 있습니다. 다음 예에서는 LO_ORDERKEY의 파티셔닝 값을 지정하여 여러 파티션을 생성합니다.
Partition1: WHERE LO_ORDERKEY = 1 Partition2: WHERE LO_ORDERKEY = 2 Partition3: WHERE LO_ORDERKEY = 3 … PartitionN: WHERE LO_ORDERKEY = USER_VALUE_N
또한 지정된 파티션에 포함되지 않은 값에 대한 기본 파티션을 생성할 수도 있습니다.
마이그레이션에서 특정 값을 제외하려는 경우 LIST 파티션 유형을 사용하여 소스 데이터를 필터링할 수 있습니다. 예를 들어, LO_ORDERKEY = 4를 사용하여 행을 생략하려 한다고 가정합니다. 이 경우 파티션 값 목록에 4 값이 포함되지 않도록 하고 Include other values를 선택하지 않아야 합니다.
LIST 가상 파티션을 만들려면
를 엽니다 AWS SCT.
Data Migration view (other) 모드를 선택합니다.
가상 파티셔닝을 설정할 테이블을 선택합니다. 테이블에 대한 컨텍스트(마우스 오른쪽 버튼 클릭) 메뉴를 열고 Add virtual partitioning을 선택합니다.
Add virtual partitioning 대화 상자에 다음과 같이 정보를 입력합니다.
옵션 작업 파티션 유형
LIST를 선택합니다. 선택한 유형에 따라 대화 상자 UI가 달라집니다.
열 이름
분할하려는 열을 선택합니다.
새 값
파티셔닝 값 세트에 값을 추가하려면 여기에 해당 값을 입력합니다.
Include other values
파티셔닝 기준에 맞지 않는 모든 값이 저장되는 기본 파티션을 만들려면 이 옵션을 선택합니다.
파일에서 로드
(선택 사항) 파티션 값이 포함된 .csv 파일의 이름을 입력합니다.
확인을 선택합니다.
DATE AUTO SPLIT 파티션 유형
DATE AUTO SPLIT 파티션 유형은 RANGE 파티션을 자동으로 생성하는 방법입니다. DATA AUTO SPLIT AWS SCT 을 사용하면 파티셔닝 속성, 시작 및 종료 위치, 값 간 범위 크기를 지정합니다. 그런 다음 AWS SCT 에서 파티션 값을 자동으로 계산합니다.
DATA AUTO SPLIT은 범위 파티션 생성과 관련된 많은 작업을 자동화합니다. 이 방법을 사용하는 것과 범위 파티셔닝 사이의 단점은 파티션 경계에 대해 얼마나 많은 제어가 필요한가 하는 것입니다. 자동 분할 프로세스는 항상 동일한 크기(균일한)의 범위를 생성합니다. 범위 파티셔닝을 사용하면 특정 데이터 분포에 필요한 경우 각 범위의 크기를 변경할 수 있습니다. 예를 들어, 일별, 주별, 격주, 월별 등을 사용할 수 있습니다.
Partition1: WHERE LO_ORDERDATE >= ‘1954-10-10’ AND LO_ORDERDATE < ‘1954-10-24’ Partition2: WHERE LO_ORDERDATE >= ‘1954-10-24’ AND LO_ORDERDATE < ‘1954-11-06’ Partition3: WHERE LO_ORDERDATE >= ‘1954-11-06’ AND LO_ORDERDATE < ‘1954-11-20’ … PartitionN: WHERE LO_ORDERDATE >= USER_VALUE_N AND LO_ORDERDATE <= ‘2017-08-13’
DATE AUTO SPLIT 가상 파티션을 만들려면
를 엽니다 AWS SCT.
Data Migration view (other) 모드를 선택합니다.
가상 파티셔닝을 설정할 테이블을 선택합니다. 테이블에 대한 컨텍스트(마우스 오른쪽 버튼 클릭) 메뉴를 열고 Add virtual partitioning을 선택합니다.
Add virtual partitioning 대화 상자에 다음과 같이 정보를 입력합니다.
옵션 작업 파티션 유형
DATE AUTO SPLIT을 선택합니다. 선택한 유형에 따라 대화 상자 UI가 달라집니다.
열 이름
분할하려는 열을 선택합니다.
시작일
시작 날짜를 입력합니다.
종료일
종료 날짜를 입력합니다.
간격
간격 단위를 입력하고 해당 단위의 값을 선택합니다.
확인을 선택합니다.
네이티브 파티셔닝 사용
데이터 마이그레이션 속도를 높이기 위해 데이터 추출 에이전트는 소스 데이터 웨어하우스 서버의 네이티브 테이블 파티션을 사용할 수 있습니다.는 Greenplum, Netezza 및 Oracle에서 Amazon Redshift로의 마이그레이션을 위한 네이티브 파티셔닝을 AWS SCT 지원합니다.
예를 들어, 프로젝트를 생성한 후 스키마에 대한 통계를 수집하고 마이그레이션을 위해 선택한 테이블의 크기를 분석할 수 있습니다. 지정된 크기를 초과하는 테이블의 경우는 네이티브 파티셔닝 메커니즘을 AWS SCT 트리거합니다.
네이티브 파티셔닝을 사용하려면
-
파일을 AWS SCT열고 파일의 새 프로젝트를 선택합니다. 새 프로젝트 대화 상자가 나타납니다.
-
새 프로젝트를 만들고, 소스 및 대상 서버를 추가하고, 매핑 규칙을 생성합니다. 자세한 내용은 에서 프로젝트 시작 및 관리 AWS SCT 단원을 참조하십시오.
-
보기를 선택하고 Main view를 선택합니다.
-
프로젝트 설정에서 데이터 마이그레이션 탭을 선택합니다. Use automatic partitioning을 선택합니다. Greenplum 및 Netezza 소스 데이터베이스의 경우 지원되는 테이블의 최소 크기를 MB 단위로 입력합니다(예: 100). AWS SCT 가 비어 있지 않은 각 네이티브 파티션에 대해 개별 마이그레이션 하위 작업을 자동으로 생성합니다. Oracle에서 Amazon Redshift로 마이그레이션하는 경우는 파티셔닝된 모든 테이블에 대한 하위 작업을 AWS SCT 생성합니다.
-
소스 데이터베이스의 스키마를 표시하는 왼쪽 패널에서 스키마를 선택합니다. 객체의 컨텍스트(마우스 오른쪽 버튼 클릭) 메뉴를 열고 Collect statistics를 선택합니다. Oracle에서 Amazon Redshift로 데이터를 마이그레이션하는 경우 이 단계를 건너뛸 수 있습니다.
-
마이그레이션할 테이블을 모두 선택합니다.
-
필요한 수의 에이전트를 등록합니다. 자세한 내용은 에 추출 에이전트 등록 AWS Schema Conversion Tool 단원을 참조하십시오.
-
선택한 테이블에 대한 데이터 추출 작업을 생성합니다. 자세한 내용은 AWS SCT 데이터 추출 작업 생성, 실행 및 모니터링 단원을 참조하십시오.
큰 테이블이 하위 작업으로 분할되어 있는지, 각 하위 작업이 소스 데이터 웨어하우스의 한 부분에 있는 테이블의 일부를 나타내는 데이터 세트와 일치하는지 확인합니다.
-
AWS SCT 데이터 추출 에이전트가 소스 테이블에서 데이터 마이그레이션을 완료할 때까지 마이그레이션 프로세스를 시작하고 모니터링합니다.
Amazon Redshift로 LOB 마이그레이션
Amazon Redshift는 대용량 바이너리 객체(LOB) 저장을 지원하지 않습니다. 그러나 하나 이상의 LOBs를 Amazon Redshift로 마이그레이션해야 하는 경우에서 마이그레이션을 수행할 수 AWS SCT 있습니다. 이 작업을 수행하기 위해 AWS SCT 가 Amazon S3 버킷을 사용하여 LOB를 저장하고 Amazon Redshift에 저장된 마이그레이션된 데이터에 Amazon S3 버킷의 URL을 기록합니다.
LOB를 Amazon Redshift로 마이그레이션하려면
AWS SCT 프로젝트를 엽니다.
소스 및 대상 데이터베이스에 연결합니다. 대상 데이터베이스에서 메타데이터를 새로 고치고 변환된 테이블이 있는지 확인합니다.
작업에서 Create local task를 선택합니다.
-
Migration mode에서 다음 중 하나를 선택합니다.
-
Extract and upload - 데이터를 추출한 후 Amazon S3에 데이터를 업로드합니다.
-
Extract, upload and copy - 데이터를 추출하고 Amazon S3에 데이터를 업로드한 다음, Amazon Redshift 데이터 웨어하우스로 복사합니다.
-
Amazon S3 settings를 선택합니다.
Amazon S3 bucket LOBs folder에서 LOB를 저장하려는 Amazon S3 버킷의 폴더 이름을 입력합니다.
AWS 서비스 프로파일을 사용하는 경우이 필드는 선택 사항입니다. 프로파일의 기본 설정을 사용할 AWS SCT 수 있습니다. 다른 Amazon S3 버킷을 사용하려면 여기에 경로를 입력합니다.
-
프록시 서버를 사용하여 Amazon S3에 데이터를 업로드하려면 프록시 사용 옵션을 켭니다. 그런 다음 데이터 전송 프로토콜을 선택하고 호스트 이름, 포트, 사용자 이름 및 암호를 입력합니다.
-
Federal Information Processing Standard(FIPS) 엔드포인트를 사용하려면 엔드포인트 유형에서 FIPS를 선택합니다. Virtual Private Cloud(VPC) 엔드포인트를 사용하려면 VPCE를 선택합니다. 그런 다음 VPC 엔드포인트에 VPC 엔드포인트의 도메인 이름 시스템(DNS)을 입력합니다.
-
추출된 파일을 Amazon Redshift로 파일을 복사한 후 Amazon S3에 이러한 파일을 유지하려면 Keep files on Amazon S3 after copying to Amazon Redshift 옵션을 켭니다.
생성을 선택하여 작업을 생성합니다.
데이터 추출 에이전트에 대한 모범 사례 및 문제 해결
다음은 추출 에이전트 사용에 대한 모범 사례와 문제 해결 제안 사항입니다.
| 문제 | 문제 해결 제안 |
|---|---|
|
성능이 느림 |
성능을 개선하기 위해 다음이 권장됩니다.
|
|
경합 지연 |
너무 많은 에이전트가 동시에 데이터 웨어하우스에 액세스하지 않도록 합니다. |
|
에이전트가 일시적으로 작동 중지됨 |
에이전트가 작동 중지되면 AWS SCT에 각 작업의 상태가 실패한 것으로 표시됩니다. 기다리면 경우에 따라 에이전트가 복구될 수 있습니다. 이런 경우에는 AWS SCT에서 작업 상태가 업데이트됩니다. |
|
에이전트가 영구적으로 작동 중지됨 |
에이전트를 실행하는 컴퓨터가 영구적으로 작동 중지되는 경우 해당 에이전트가 작업을 실행 중이면 새 에이전트를 대체하여 작업을 계속할 수 있습니다. 원래 에이전트의 작업 폴더가 원래 에이전트와 같은 컴퓨터에 없는 경우에만 새 에이전트를 대체할 수 있습니다. 새 에이전트를 대체하려면 다음을 수행합니다.
|
