DynamoDB의 관계형 데이터 모델링에 대한 예
이 예는 Amazon DynamoDB에서 관계형 데이터를 모델링하는 방법을 설명합니다. DynamoDB 테이블 설계는 관계형 모델링에 표시된 관계형 주문 입력 스키마에 해당합니다. 이는 DynamoDB에서 관계형 데이터 구조를 표시하는 범용적인 방식인 인접 목록 설계 패턴을 따릅니다.
이 설계 패턴의 경우, 사용자가 관계형 스키마의 다양한 테이블과 연결되는 항목 유형 세트를 정의해야 합니다. 그런 후 복합(파티션 및 정렬) 기본 키를 사용하여 테이블에 개체 항목을 추가합니다. 이런 개체 항목의 파티션 키는 항목을 고유하게 식별하는 속성이며, 대체로 PK인 모든 항목을 가리킵니다. 정렬 키 속성에는 반전 인덱스나 글로벌 보조 인덱스에 사용할 수 있는 속성 값이 포함되어 있습니다. 대체로 SK입니다.
관계형 주문 입력 스키마를 지원하는 다음 개체를 정의합니다.
-
HR-Employee - PK: EmployeeID, SK: Employee Name
-
HR-Region - PK: RegionID, SK: Region Name
-
HR-Country - PK: CountryId, SK: Country Name
-
HR-Location - PK: LocationID, SK: Country Name
-
HR-Job - PK: JobID, SK: Job Title
-
HR-Department - PK: DepartmentID, SK: DepartmentName
-
OE-Customer - PK: CustomerID, SK: AccountRepID
-
OE-Order - PK OrderID, SK: CustomerID
-
OE-Product - PK: ProductID, SK: Product Name
-
OE-Warehouse - PK: WarehouseID, SK: Region Name
테이블에 이런 개체 항목을 추가하고, 개체 항목 파티션에 엣지 항목을 추가해 항목 간 관계를 정의할 수 있습니다. 다음은 이 단계에 대해 설명하고 있는 테이블입니다.
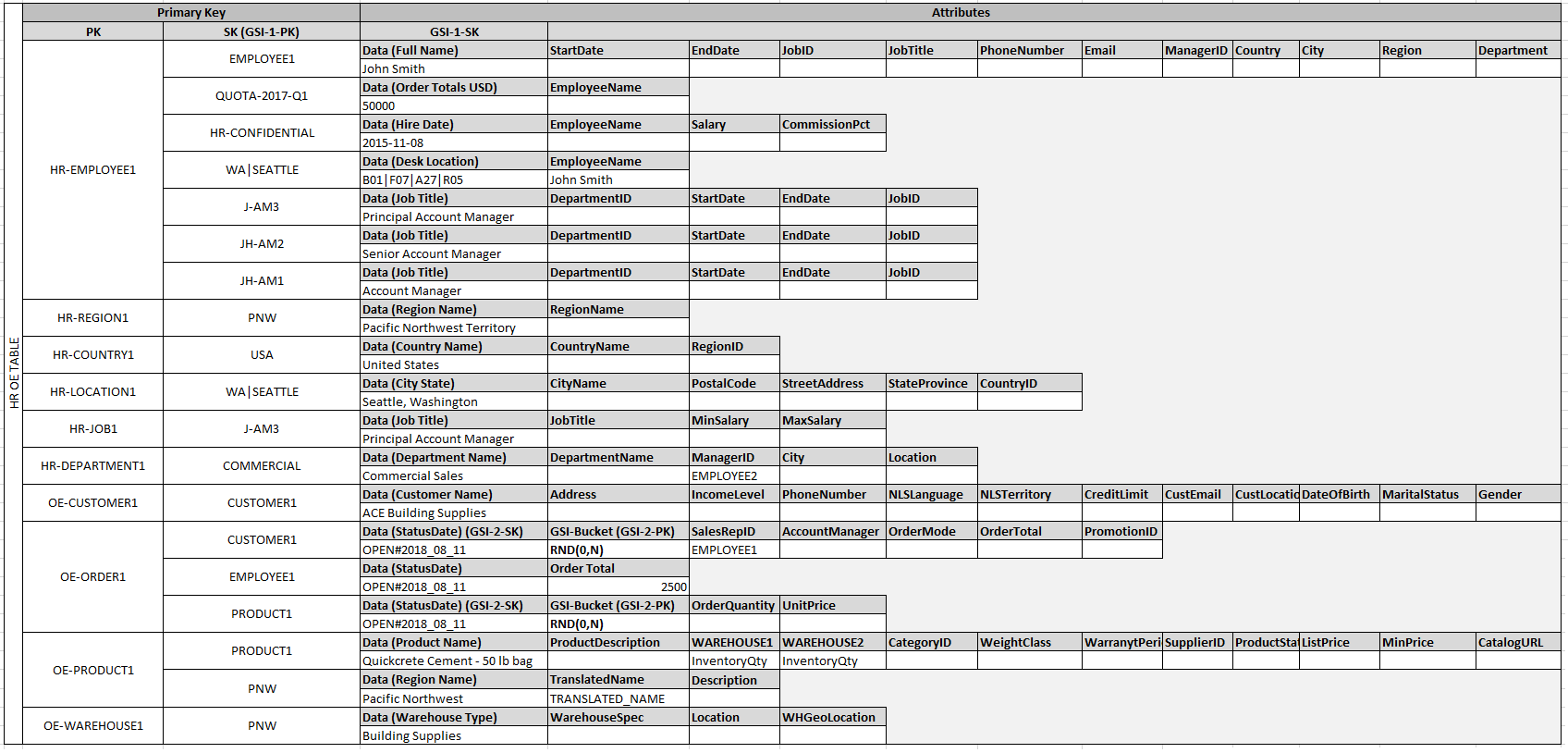
이 예에서 테이블의 Employee, Order 및 Product
Entity 파티션에는 테이블의 다른 개체 항목에 대한 포인터가 포함되어 있는 추가 엣지 항목이 있습니다. 이제 앞서 정의한 모든 액세스 패턴을 지원하는 몇 개의 글로벌 보조 인덱스(GSI)를 정의합니다. 개체 항목들의 기본 키나 정렬 키 속성에 사용되는 값의 유형이 다릅니다. 기본 키와 정렬 키 속성을 테이블에 삽입할 수 있도록 준비하는 것만 요구됩니다.
적절한 이름을 사용하고 있는 개체가 있는 반면 다른 개체의 ID를 정렬 키 값으로 사용하는 개체도 있습니다. 이를 통해 동일한 글로벌 보조 인덱스로 여러 유형의 쿼리를 지원할 수 있습니다. 이 기법을 GSI 오버로딩이라고 합니다. 이 방법을 사용하면 여러 항목 유형이 포함된 테이블에 대해 20개의 글로벌 보조 인덱스라는 기본 제한이 사실상 제거됩니다. GSI 1이라는 다이어그램에 설명되어 있습니다.
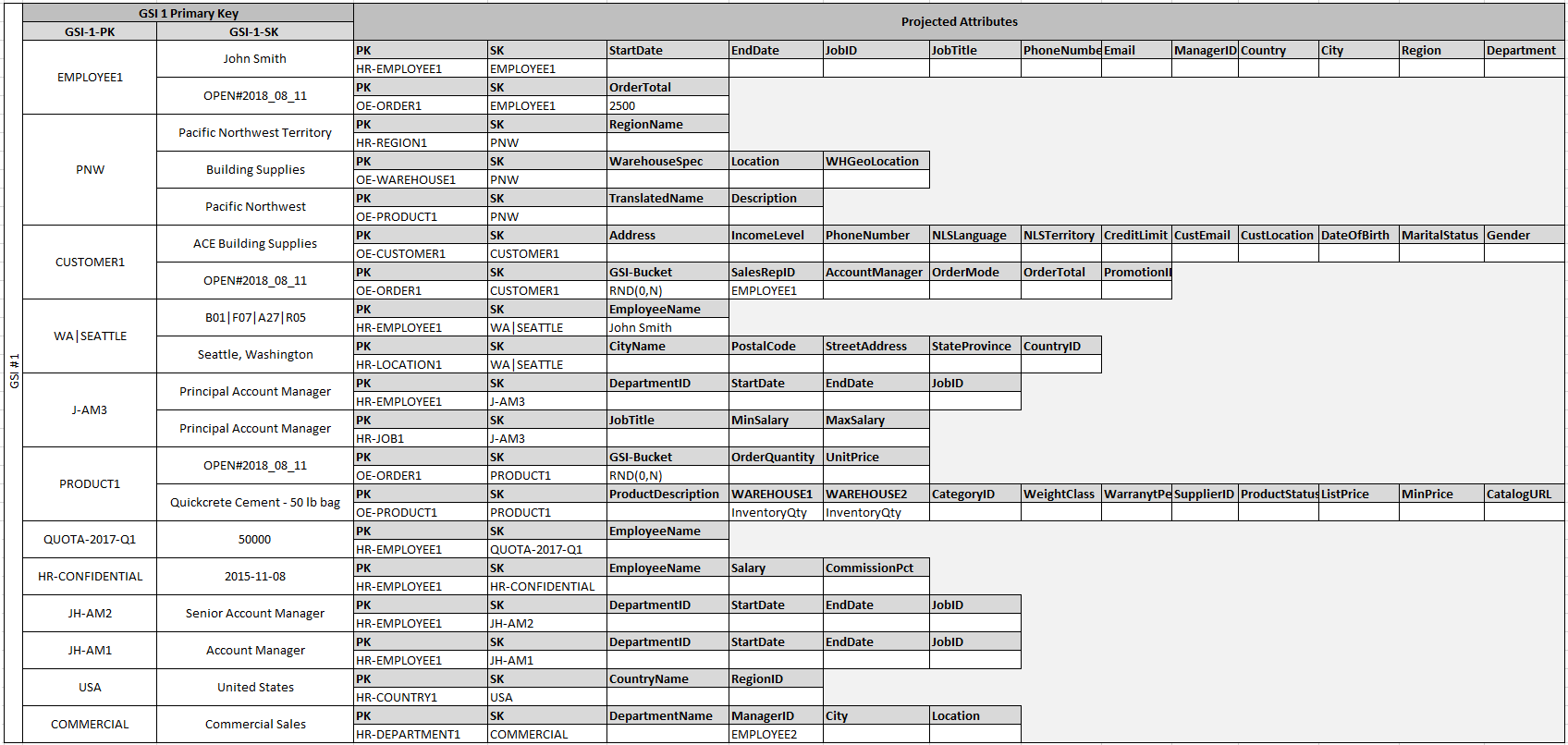
GSI 2는 특정 상태를 가지고 있는 표의 모든 항목을 가져오는 비교적 범용적인 애플리케이션 액세스 패턴을 지원하도록 설계되어 있습니다. 가용한 상태에 대한 항목의 분포가 고르지 않은 라지 테이블의 경우, 항목을 병렬로 쿼리할 수 있도록 하나 이상의 논리적 파티션에 분포하지 않는 경우 '핫' 키가 초래될 수 있습니다. 이런 설계 패턴을 write sharding라고 합니다.
GSI 2에 이 작업을 수행하기 위해 애플리케이션은 모든 Order 항목에 GSI 2 기본 키 속성을 추가합니다. 0~N 범위의 난수로 채워 넣습니다. N은 일반적으로 다음 공식을 사용해 계산할 수 있습니다(이렇게 하지 않아야 하는 이유가 있는 경우 제외).
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
예를 들어, 다음을 기대한다고 가정하겠습니다.
-
시스템의 주문은 최대 200만이고, 5년 내에 300만으로 증가할 것입니다.
-
특정 시점에서 열려 있는 상태의 주문은 최대 20%입니다.
-
평균적으로 주문 레코드는 약 100바이트이고, 주문 파티션의 3개
OrderItem레코드는 각각 약 50바이트이므로 평균적으로 주문 엔터티의 크기는 250바이트입니다.
이 테이블에서 N 팩터는 다음과 같이 계산합니다.
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
이 경우, GSI 2의 논리적 파티션 13개 이상에 모든 주문을 배포해 OPEN 상태인 모든 Order 항목의 읽기 작업이 물리적 스토리지 계층에서 핫 파티션을 초래하지 않도록 만들어야 합니다. 이 숫자를 덧대 데이터세트에서 이상(이례)을 허용하는 것이 좋습니다. 즉 N = 15을 사용하는 모델이 아마 좋을 것입니다. 앞서 언급했듯이 테이블에 삽입된 각 Order 및 OrderItem 레코드의 GSI 2 PK 속성에 0~N 사이의 임의의 값을 추가해 이렇게 할 수 있습니다.
이는 모든 OPEN 인보이스 수집을 요구하는 액세스 패턴이 비교적 적게 발생해, 버스트 용량으로 요청을 충족할 수 있다는 가정 아래 분석을 한 것입니다. State 및 Date Range Sort Key 조건을 사용하는 다음의 글로벌 보조 인덱스를 쿼리해 필요한 특정 상태의 모든 Orders의 하위집합을 생성할 수 있습니다.

이 예에서는 15개의 논리적 파티션을 대상으로 항목을 임의 배포합니다. 이 구조는 액세스 패턴에 검색할 항목의 수가 많기 때문에 작동을 합니다. 즉 15개 스레드 중 어느 하나가 낭비된 용량을 대표할 수 있는 비어있는 결과 세트를 반환할 확률이 낮습니다. 반환이 없거나, 작성된 데이터가 없는 경우에도, 쿼리는 항상 1RCU(읽기 용량 단위)나 1WCU(쓰기 용량 단위)을 사용합니다.
액세스 패턴이 희소한 결과 세트를 반환하는 이러한 글로벌 보조 인덱스에 요구하는 쿼리 속도가 빨라야 하는 경우, 임의 패턴보다는 항목을 분산시키는 해시 알고리즘을 사용하는 것이 더 좋을 수 있습니다. 이 경우, 쿼리가 실행 시간에 실행될 때 알려진 속성을 선택하고 이 속성을 항목이 삽입될 때 0~14의 키 공간에 해시합니다. 그러면 글로벌 보조 인덱스에서 효율적으로 읽기 작업을 수행할 수 있습니다.
마지막으로 앞서 정의한 액세스 패턴을 다시 살펴보겠습니다. 다음은 수용하는 애플리케이션의 새 DynamoDB 버전과 함께 사용할 수 있는 액세스 패턴과 쿼리 조건의 목록입니다.
| 일련 번호 | 액세스 패턴 | 쿼리 조건 |
|---|---|---|
|
1 |
직원 ID별로 직원 세부 정보 조회 |
테이블의 프라이머리 키, ID='HR-EMPLOYEE' |
|
2 |
직원 이름별 직원 세부 정보 쿼리 |
GSI-1, PK = 'Employee Name' 사용 |
|
3 |
직원의 현재 작업 세부 정보만 가져오기 |
테이블의 프라이머리 키, PK=HR-EMPLOYEE-1, SK는 'JH'로 시작 |
|
4 |
특정 고객의 특정 날짜 범위 주문 가져오기 |
각 StatusCode에 대해 GSI-1, PK=CUSTOMER1, SK='STATUS-DATE' 사용 |
|
5 |
모든 고객에 걸쳐 특정 날짜 범위에 OPEN 상태인 모든 주문 표시 |
OPEN-Date1과 OPEN-Date2 사이의 범위 [0..N], SK에 대해 병렬로 GSI-2, PK=query 사용 |
|
6 |
최근 채용된 모든 직원 |
GSI-1, PK='HR-CONFIDENTIAL', SK > date1 사용 |
|
7 |
특정 창고의 모든 직원 찾기 |
GSI-1, PK=WAREHOUSE1 사용 |
|
8 |
창고 위치 재고를 포함하여 제품에 대한 모든 주문 품목 가져오기 |
GSI-1, PK=PRODUCT1 사용 |
|
9 |
계정 담당자별로 고객 가져오기 |
GSI-1, PK=ACCOUNT-REP 사용 |
|
10 |
계정 담당자 및 날짜별로 주문 가져오기 |
각 StatusCode에 대해 GSI-1, PK=ACCOUNT-REP, SK='STATUS-DATE' 사용 |
|
11 |
특정 직책의 모든 직원 가져오기 |
GSI-1, PK=JOBTITLE 사용 |
|
12 |
제품 및 창고별로 재고 가져오기 |
테이블의 프라이머리 키, PK=OE-PRODUCT1,SK=PRODUCT1 |
|
13 |
전체 제품 재고 가져오기 |
테이블의 프라이머리 키, PK=OE-PRODUCT1,SK=PRODUCT1 |
|
14 |
주문 총계 및 판매 기간별로 순위가 지정된 계정 담당자 가져오기 |
GSI-1, PK=YYYY-Q1, scanIndexForward=False 사용 |
