DynamoDB의 관계형 데이터 모델링 모범 사례
이 섹션에서는 Amazon DynamoDB의 관계형 데이터 모델링 모범 사례를 제공합니다. 먼저 기존 데이터 모델링 개념을 소개합니다. 그런 다음 기존 관계형 데이터베이스 관리 시스템에 비해 DynamoDB를 사용할 때의 이점, 즉 JOIN 작업의 필요성이 없어지고 오버헤드가 줄어드는 것에 대해 설명합니다.
또한 효율적으로 확장되는 DynamoDB 테이블을 설계하는 방법을 설명합니다. 마지막으로 DynamoDB에서 관계형 데이터를 모델링하는 방법에 대한 예를 제공합니다.
주제
기존 관계형 데이터베이스 모델
기존의 관계형 데이터베이스 관리 시스템(RDBMS)은 데이터를 정규화된 관계형 구조로 저장합니다. 관계형 데이터 모델의 목적은 정규화를 통해 데이터 중복을 줄여 참조 무결성을 지원하고 데이터 이상 현상을 줄이는 것입니다.
다음 스키마는 일반 주문 입력 애플리케이션을 위한 관계형 데이터 모델의 예입니다. 이 애플리케이션은 가상의 제조업체의 운영 및 비즈니스 지원 시스템을 뒷받침하는 HR 스키마를 지원합니다.
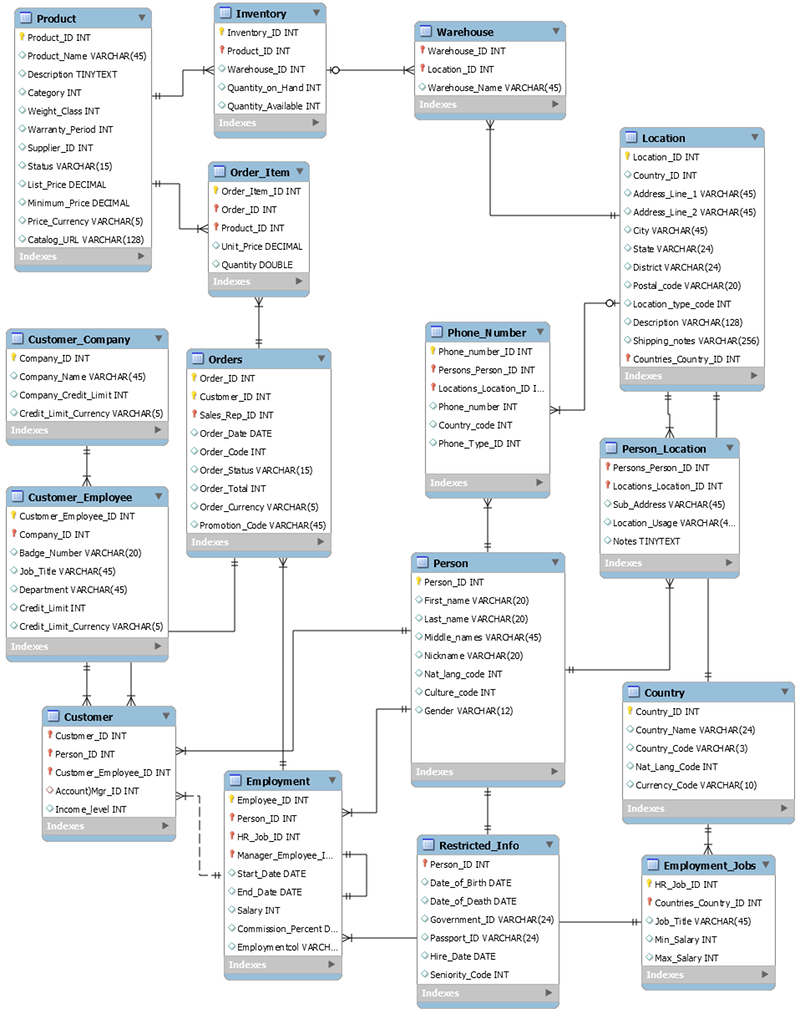
비관계형 데이터베이스 서비스인 DynamoDB는 기존의 관계형 데이터베이스 관리 시스템에 비해 많은 이점을 제공합니다.
DynamoDB를 통해 JOIN 작업의 필요성을 없애는 방법
RDBMS는 구조 쿼리 언어(SQL)를 사용하여 데이터를 애플리케이션에 반환합니다. 데이터 모델의 정규화로 인해 이러한 쿼리에서는 일반적으로 JOIN 연산자를 사용하여 하나 이상의 테이블에서 데이터를 결합해야 합니다.
예를 들어, 각 항목을 출하할 수 있는 모든 창고의 재고량을 기준으로 정렬된 구매 주문 항목 목록을 생성하려면, 앞서 스키마에 대해 다음 SQL 쿼리를 발행할 수 있습니다.
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESC이런 유형의 SQL 쿼리는 데이터에 유연하게 액세스 할 수 있는 API를 제공할 수 있지만, 상당히 많은 처리량이 필요합니다. 쿼리의 각 조인은 각 테이블의 데이터를 스테이징한 다음 조합하여 결과 집합을 반환해야 하므로 쿼리의 런타임 복잡성이 증가합니다.
쿼리를 실행하는 데 걸리는 시간에 영향을 줄 수 있는 추가 요소로는 테이블 크기 및 조인되는 열의 인덱스 여부가 있습니다. 앞의 쿼리는 여러 테이블을 대상으로 복잡한 쿼리를 시작한 후, 결과 세트를 분류합니다.
JOINs에 대한 필요를 없애는 것이 NoSQL 데이터 모델링의 핵심입니다. 이것이 바로 Amazon.com을 지원하기 위해 DynamoDB를 구축한 이유이자 DynamoDB가 모든 규모에서 일관된 성능을 제공할 수 있는 이유입니다. SQL 쿼리 및 JOINs의 런타임 복잡성을 고려할 때 RDBMS 성능은 규모에 따라 일정하지 않으므로 고객 애플리케이션이 확장됨에 따라 성능 문제가 발생합니다.
데이터를 정규화하면 디스크에 저장되는 데이터의 양이 줄어들지만 성능에 영향을 미치는 가장 제한적인 리소스는 CPU 시간과 네트워크 지연 시간인 경우가 많습니다.
DynamoDB는 항목에 대한 단일 요청으로 애플리케이션 쿼리에 완전히 응답하도록 JOINs을 제거(및 데이터 비정규화를 촉진)하고 데이터베이스 아키텍처를 최적화하고 두 제약 조건을 모두 최소화하도록 구축되었습니다. 이러한 특성 덕분에 DynamoDB는 어떤 규모에서든 한 자릿수 밀리초 수준의 성능을 제공할 수 있습니다. DynamoDB 작업의 런타임 복잡성은 데이터 크기와 관계없이 일반적인 액세스 패턴에서 일정하기 때문입니다.
DynamoDB 트랜잭션이 쓰기 프로세스의 오버헤드를 제거하는 방법
RDBMS를 느리게 할 수 있는 또 다른 요인은 트랜잭션을 사용하여 정규화된 스키마에 쓰는 것입니다. 예시에서 볼 수 있는 것처럼 대부분의 온라인 트랜잭션 처리(OLTP) 애플리케이션이 사용하는 관계형 데이터 구조는 구분한 후 RDBMS에 저장할 때 여러 논리적 테이블로 배포해야 합니다.
즉 ACID를 준수하는 트랜잭션 프레임워크로 애플리케이션이 쓰기 처리 중에 객체 읽기를 시도할 때 발생할 수 있는 교착 상태와 데이터 무결성 문제를 방지해야 합니다. 이러한 트랜잭션 프레임워크는 관계형 스키마와 결합될 때 쓰기 프로세스에 상당한 오버헤드를 추가할 수 있습니다.
DynamoDB에서 트랜잭션을 구현하면 RDBMS에서 발생하는 일반적인 규모 조정 문제를 방지할 수 있습니다. 트랜잭션이 단일 API 호출로 실행되고 해당 단일 트랜잭션에서 액세스할 수 있는 항목 수가 제한되기 때문입니다. 장기 실행 트랜잭션은 트랜잭션이 닫히지 않기 때문에 장기간 또는 영구적으로 데이터 잠금을 유지하여 운영상의 문제를 일으킬 수 있습니다.
DynamoDB에서 이러한 문제를 방지하기 위해 트랜잭션은 두 개의 고유한 API 작업인 TransactWriteItems 및 TransactGetItems를 사용하여 구현되었습니다. 이러한 API 작업에는 RDBMS에서 흔히 볼 수 있는 시작 및 종료 시맨틱이 없습니다. 또한 DynamoDB는 트랜잭션 내에 100개의 항목 액세스 제한을 두어 장기 실행 트랜잭션을 유사하게 방지합니다. DynamoDB 트랜잭션에 대해 자세히 알아보려면 트랜잭션 작업을 참조하세요.
이런 이유로 비즈니스에서 트래픽이 많은 쿼리에 지연 시간이 낮은 응답이 요구되는 경우, NoSQL 시스템을 활용하는 것이 기술적 및 경제적으로 합리적입니다. Amazon DynamoDB는 이를 방지해 관계형 시스템의 확장성을 제한하는 문제를 해결하는 데 도움을 줍니다.
RDBMS의 성능은 일반적으로 다음과 같은 이유로 제대로 확장되지 않습니다.
-
고가의 조인을 사용해 필요한 쿼리 결과 보기를 재수집해야 합니다.
-
데이터를 정규화해서, 여러 테이블에 저장을 하는 데, 디스크 쓰기 작업에 여러 쿼리가 요구됩니다.
-
ACID 준수 트랜잭션 시스템의 경우 일반적으로 성능과 관련된 '비용'이 발생합니다.
DynamoDB는 다음 이유 때문에 효과적으로 조정이 됩니다.
-
스키마 유연성 덕분에 DynamoDB가 복잡한 계층적 데이터를 단일 항목으로 저장할 수 있습니다.
-
복합 키 설계 덕분에 관련 항목을 동일한 테이블에 함께 가까이 저장할 수 있습니다.
-
트랜잭션은 한 번의 작업으로 수행되며 장시간 실행되는 작업을 피하기 위해 액세스할 수 있는 항목 수를 100개로 제한합니다.
데이터 스토어에 대한 쿼리가 훨씬 더 간단합니다(아래 형식인 경우가 많음).
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB는 이전 예의 RDBMS보다 요청 데이터 반환이 효과적입니다.
