기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS DeepRacer에서의 강화 학습
강화 학습에서는 의도한 목표를 달성하기 위한 목표를 가진 물리적 또는 가상 AWS DeepRacer 차량과 같은 에이전트가 환경과 상호 작용하여 에이전트의 총 보상을 극대화합니다. 에이전트는 정책이라고 하는 전략에 따라 주어진 환경 상태에서 조치를 취하고 새로운 상태에 도달합니다. 어떤 행동이든 즉각적인 보상으로 이어집니다. 이러한 보상은 행동의 적합성을 나타내는 척도입니다. 즉각적인 보상은 환경에서 반환되는 것으로 알려져 있습니다.
AWS DeepRacer에서 강화 학습의 목적은 임의 환경에서 최적의 정책을 학습하는 데 있습니다. 여기에서 학습이란 시행 착오가 반복되는 프로세스를 말합니다. 에이전트는 무작위로 초기 행동을 보이면서 새로운 상태에 도달합니다. 그런 다음 해당 단계를 반복하여 새로운 상태에서 다음 상태로 넘어갑니다. 에이전트는 시간이 지나면서 이러한 방식으로 장기적 보상을 극대화하는 행동을 발견합니다. 초기 상태에서 최종 상태까지 이어지는 에이전트의 상호 작용을 에피소드라고 부릅니다.
다음은 학습 프로세스를 도식으로 나타낸 그림입니다.
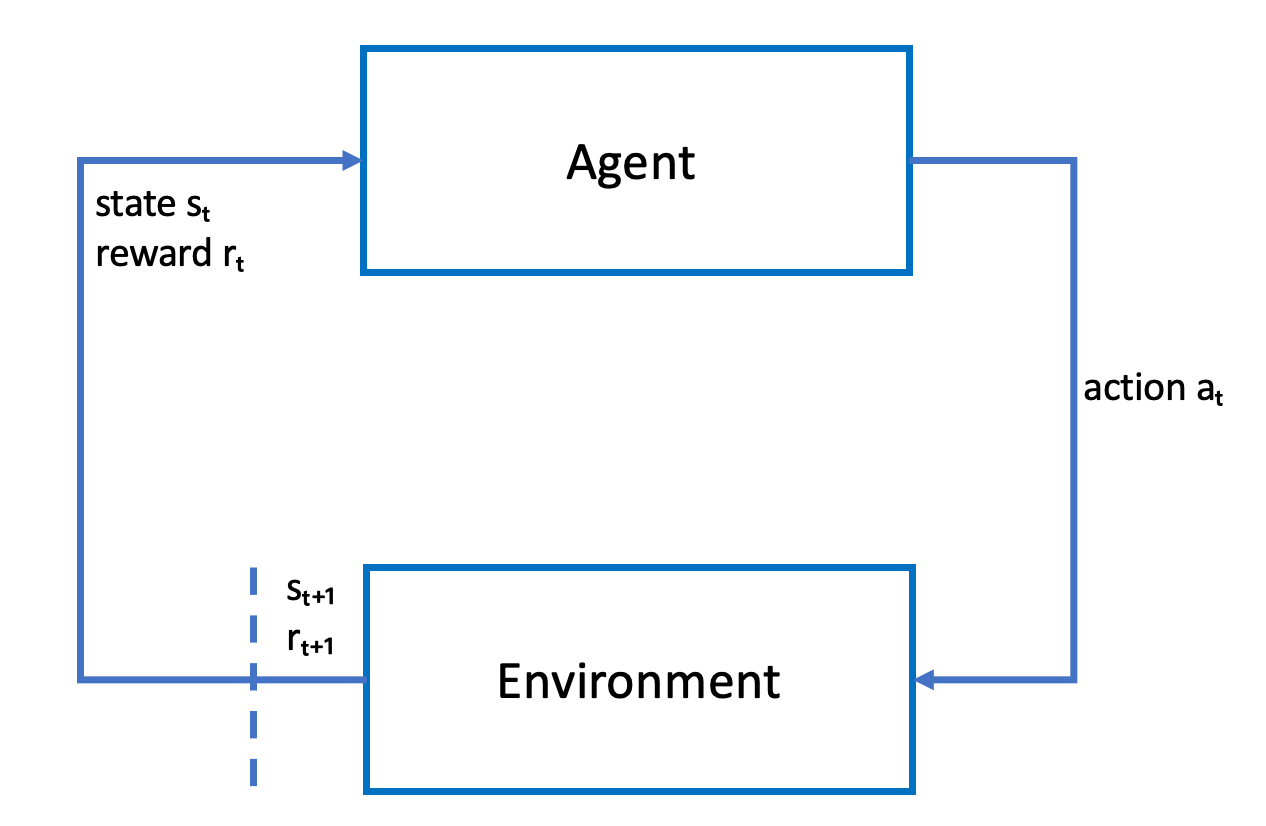
에이전트는 신경망을 구체화하고, 신경망은 에이전트의 정책에 대한 근사 함수를 표현합니다. 차량의 정방 카메라에서 촬영된 이미지는 환경 상태이고, 에이전트 행동은 에이전트의 속도와 조향 각도로 결정됩니다.
에이전트가 트랙을 벗어나지 않고 완주하면 양의 보상을, 그리고 트랙에서 벗어나면 음의 보상을 받습니다. 에피소드는 레이스 트랙의 임의 구간에서 에이전트와 함께 시작되어 에이전트가 트랙에서 벗어나거나 한 바퀴를 완주할 때 종료됩니다.
참고
엄밀히 말해서 환경 상태는 문제와 관련된 모든 것을 말합니다. 예를 들어 트랙의 차량 위치나 트랙 형상도 환경 상태가 될 수 있습니다. 차량 전면에 장착된 카메라를 통해 수집되는 이미지로는 전체 환경 상태를 알 수 없습니다. 이러한 이유로 환경은 부분적으로 관측된 결과라고 할 수 있으며, 에이전트에 대한 입력 데이터가 상태가 아닌 관측 결과라고 불리는 이유도 여기에 있습니다. 하지만 이번 문서에서는 단순화할 목적으로 상태와 관측 결과를 동일한 의미로 사용합니다.
시뮬레이션 환경에서 에이전트를 훈련하면 다음과 같은 이점이 있습니다.
-
시뮬레이션에서는 에이전트의 진행 상황을 예상하면서 트랙에서 이탈하는 시점을 찾아내 보상을 계산할 수 있습니다.
-
시뮬레이션에서는 마치 물리적 환경에서 훈련하는 것처럼 트랙에서 이탈할 때마다 번거롭게 차량을 재설정할 필요가 없습니다.
-
시뮬레이션은 훈련 속도를 높일 수 있습니다.
-
시뮬레이션에서는 다른 트랙, 배경 및 차량 조건을 선택하는 등 환경 조건을 효과적으로 제어할 수 있습니다.
강화 학습에 대한 대안으로 지도 학습이 있으며, 모방 학습으로도 불립니다. 모방 학습에서는 임의 환경에서 수집되어 알려진 데이터 세트([이미지, 행동] 튜플)가 에이전트 훈련에 사용됩니다. 모방 학습을 통해 훈련되는 모델도 자율 주행에 적용할 수 있습니다. 단, 카메라에서 촬영된 이미지가 훈련 데이터 세트의 이미지와 비슷할 때만 효과가 있습니다. 따라서 견고한 주행을 위해서는 훈련 데이터 세트가 포괄적이어야 합니다. 이와 반대로 강화 학습에서는 포괄적인 라벨링 작업 없이 시뮬레이션에서 완전한 훈련이 가능합니다. 강화 학습은 무작위 행동으로 시작되기 때문에 에이전트가 다양한 환경 및 트랙 조건을 학습합니다. 강화 학습으로 훈련된 모델이 견고한 이유도 여기에 있습니다.
