Amazon Data Firehose란?
Amazon Data Firehose란 Amazon Simple Storage Service(Amazon S3), Amazon Redshift, Amazon OpenSearch Service, Amazon OpenSearch Serverless, Splunk, Apache Iceberg 테이블 및 사용자 지정 HTTP 엔드포인트 등의 대상 또는 지원되는 타사 서비스 공급자가 소유한 HTTP 엔드포인트(Datadog, Dynatrace, LogicMonitor, MongoDB, New Relic, Coralogix, Elastic 등)에 실시간 스트리밍 데이터
AWS 빅 데이터 솔루션에 대한 자세한 내용은 AWS 기반 빅 데이터
참고
생산자, 스트리밍 스토리지, 소비자, 대상을 통해 데이터가 흐르는 AWS CloudFormation 템플릿을 제공하는 Amazon MSK용 최신 AWS 스트리밍 데이터 솔루션
주요 개념 알아보기
Amazon Data Firehose를 처음 사용할 때 다음 개념을 이해하고 있으면 도움이 될 수 있습니다.
- Firehose 스트림
-
Amazon Data Firehose의 기본 엔터티입니다. Firehose 스트림을 만든 다음 데이터를 Firehose 스트림으로 전송하여 Amazon Data Firehose를 사용합니다. 자세한 내용은 자습서: 콘솔에서 Firehose 스트림 생성 및 Firehose 스트림으로 데이터 전송 섹션을 참조하세요.
- 레코드
-
데이터 생산자가 Firehose 스트림으로 보내는 관심 있는 데이터입니다. 레코드는 최대 1000KB가 될 수 있습니다.
- 데이터 생산자
-
생산자는 Firehose 스트림에 레코드를 전송합니다. 예를 들어, Firehose 스트림에 로그 데이터를 보내는 웹 서버가 데이터 생산자입니다. 기존 Kinesis 데이터 스트림에서 데이터를 자동으로 읽어서 대상에 로드하도록 Firehose 스트림을 구성할 수도 있습니다. 자세한 내용은 Firehose 스트림으로 데이터 전송 섹션을 참조하세요.
- 버퍼 크기와 버퍼 간격
-
Amazon Data Firehose는 수신되는 스트리밍 데이터를 대상으로 전송하기 전에 특정 기간 또는 특정 크기로 버퍼링합니다. Buffer Size의 단위는 ‘MB’이고 Buffer Interval의 단위는 '초'입니다.
Amazon Data Firehose의 데이터 흐름 이해
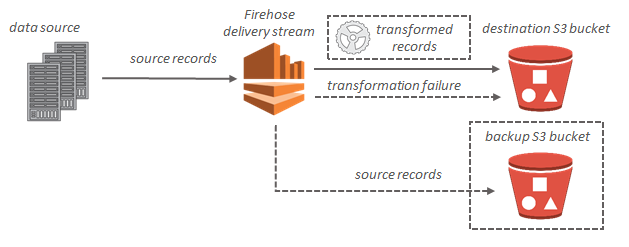
Amazon S3 대상인 경우, 스트리밍 데이터가 S3 버킷으로 전송됩니다. 데이터 변환이 활성화된 경우, 선택적으로 소스 데이터를 다른 Amazon S3 버킷으로 백업할 수 있습니다.
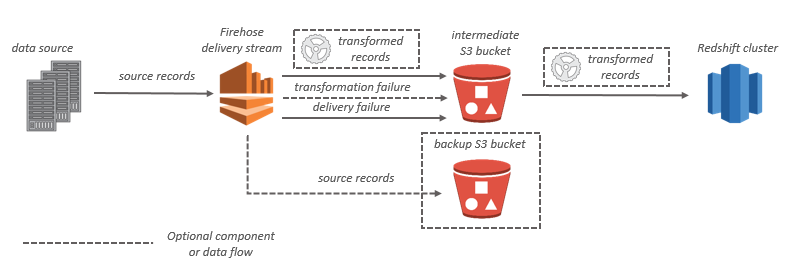
Amazon Redshift 대상인 경우, 스트리밍 데이터가 먼저 S3 버킷으로 전송됩니다. 그러면 Amazon Data Firehose는 Amazon Redshift COPY 명령을 실행하여 S3 버킷의 데이터를 Amazon Redshift 클러스터로 로드합니다. 데이터 변환이 활성화된 경우, 선택적으로 소스 데이터를 다른 Amazon S3 버킷으로 백업할 수 있습니다.
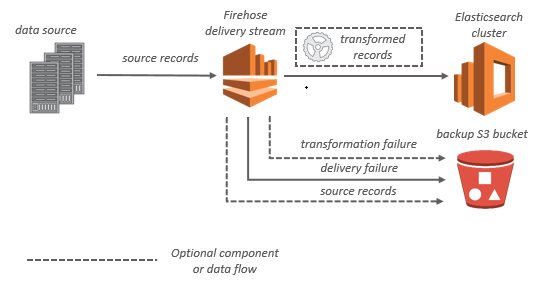
OpenSearch Service 대상인 경우 스트리밍 데이터가 OpenSearch Service 클러스터로 전송되며, 동시에 선택적으로 S3 버킷에 백업할 수 있습니다.
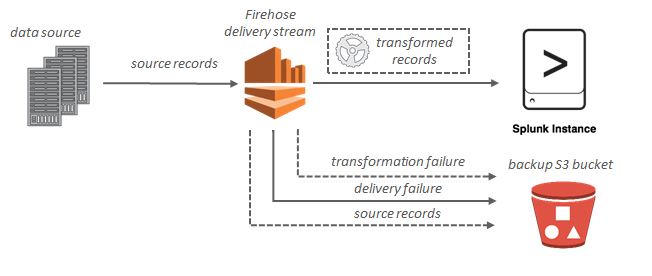
Splunk 대상인 경우 스트리밍 데이터가 Splunk 클러스터로 전송되며, 동시에 선택적으로 S3 버킷에 백업할 수 있습니다.