더 이상 Amazon Machine Learning 서비스를 업데이트하거나 새 사용자를 받지 않습니다. 이 설명서는 기존 사용자에 제공되지만 더 이상 업데이트되지 않습니다. 자세한 내용은 머신 러닝이란? 단원을 참조하세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 분할
ML 모델의 기본 목표는 모델 학습에 사용되는 데이터 외에도 미래의 데이터 인스턴스에 대해 정확한 예측을 하는 것입니다. ML 모델을 사용하여 예측하기 전에 먼저 모델의 예측 성능을 평가해야 합니다. 아직 확인하지 못한 데이터로 ML 모델 예측의 품질을 추정하기 위해, 이미 답을 알고 있는 데이터의 일부를 미래 데이터에 대한 프록시로 예약하거나 분할하여 ML 모델이 해당 데이터에 대한 정답을 얼마나 잘 예측하는지 평가할 수 있습니다. 데이터 소스를 학습 데이터 소스의 일부와 평가 데이터 소스의 일부로 분할합니다.
Amazon ML에서는 다음 세 가지 데이터 분할 옵션을 제공합니다.
-
데이터 사전 분할 - 데이터를 두 개의 데이터 입력 위치로 분할한 다음, 데이터를 Simple Storage Service(S3)에 업로드하고 이를 통해 두 개의 개별 데이터 소스를 생성할 수 있습니다.
-
ML 순차 분할 - 학습 및 평가 데이터 소스를 생성할 때 ML에 데이터를 순차적으로 분할하도록 지시할 수 있습니다.
-
ML 임의 분할 - 학습 및 평가 데이터 소스를 생성할 때 ML에 초기 설정된 무작위 방법을 사용하여 데이터를 분할하도록 지시할 수 있습니다.
데이터 사전 분할
학습 및 평가 데이터 소스의 데이터를 명시적으로 제어하려면 데이터를 별도의 데이터 위치로 분할하고 입력 위치와 평가 위치에 대해 별도의 데이터 소스를 만듭니다.
데이터 순차적 분할
학습 및 평가를 위해 입력 데이터를 분할하는 간단한 방법은 데이터 레코드의 순서를 유지하면서 중복되지 않는 데이터 하위 집합을 선택하는 것입니다. 이 접근 방식은 특정 날짜 또는 특정 시간 범위 내의 데이터를 기반으로 ML 모델을 평가하려는 경우에 유용합니다. 예를 들어 지난 5개월 동안의 고객 참여 데이터가 있는데 이 과거 데이터를 사용하여 다음 달의 고객 참여를 예측한다고 가정해 보겠습니다. 전체 데이터 범위에서 추출한 레코드 데이터를 사용하는 것보다 범위의 시작 부분은 학습에 사용하고, 범위의 끝 부분에서 나온 데이터는 평가에 사용한다면 모델 품질을 더 정확하게 추정할 수 있습니다.
다음 그림은 순차 분할 전략을 사용해야 하는 경우와 무작위 전략을 사용해야 하는 경우의 예를 보여줍니다.

데이터 소스를 생성할 때 데이터 소스를 순차적으로 분할하도록 선택할 수 있으며, Amazon ML은 데이터의 처음 70%는 학습에 사용하고 나머지 30%는 평가에 사용합니다. 이것이 Amazon ML 콘솔을 사용하여 데이터를 분할할 때의 기본 접근 방식입니다.
데이터 무작위 분할
입력 데이터를 학습 및 평가 데이터 소스로 무작위로 분할하면 데이터가 학습 데이터 소스와 평가 데이터 소스에서 비슷하게 분배될 수 있습니다. 입력 데이터의 순서를 유지할 필요가 없는 경우 이 옵션을 선택하세요.
Amazon ML은 시드된 유사 난수 생성 방법을 사용하여 데이터를 분할합니다. 시드는 일부는 입력 문자열 값을, 일부는 데이터 자체의 내용을 각각 기반으로 합니다. Amazon ML 콘솔은 기본적으로 입력 데이터의 S3 위치를 문자열로 사용합니다. API 사용자는 사용자 지정 문자열을 제공할 수 있습니다. 즉, 동일한 S3 버킷과 데이터가 주어지면 Amazon ML은 매번 같은 방식으로 데이터를 분할합니다. ML이 데이터를 분할하는 방식을 변경하려면 CreateDatasourceFromS3, CreateDatasourceFromRedshift 또는 CreateDatasourceFromRDS API를 사용하고 시드 문자열에 값을 제공하면 됩니다. 이러한 API를 사용하여 학습 및 평가를 위한 별도의 데이터 소스를 생성할 때는 학습 데이터와 평가 데이터 간에 중복이 없도록 두 데이터 소스에 동일한 시드 문자열 값을 사용하고 한 데이터 소스에는 보완 플래그를 사용하는 것이 중요합니다.
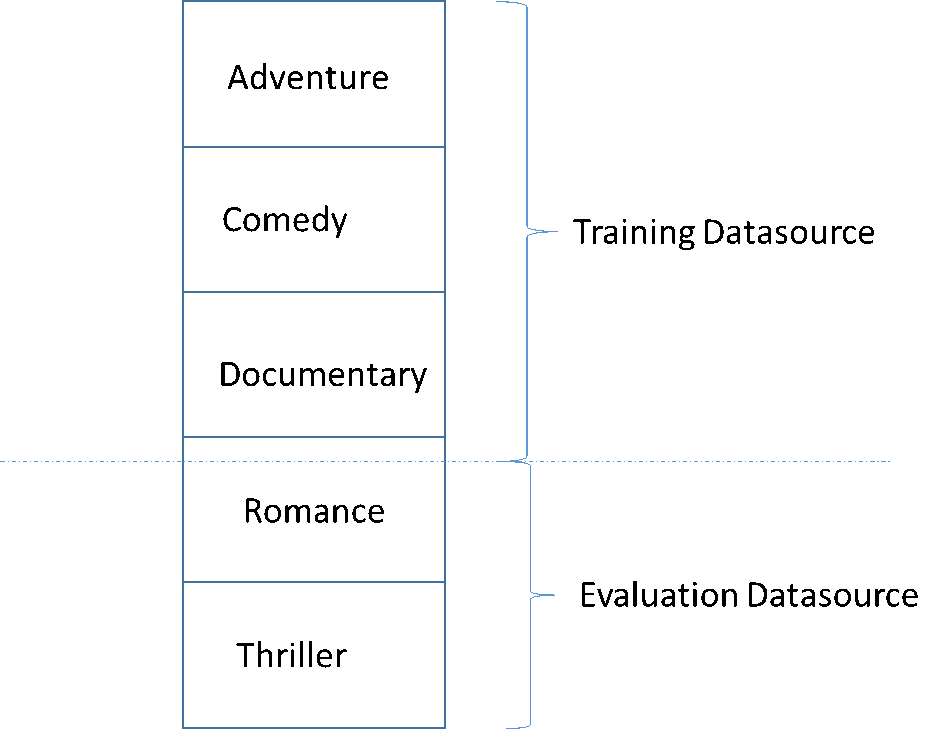
고품질 ML 모델을 개발할 때 흔히 저지르는 실수 중 하나가 학습에 사용되는 데이터와 유사하지 않은 데이터를 기반으로 ML 모델을 평가하는 것입니다. 예를 들어 ML을 사용하여 영화 장르를 예측하고 있는데 학습 데이터에 어드벤처, 코미디, 다큐멘터리 장르의 영화가 포함되어 있다고 가정해 보겠습니다. 하지만 평가 데이터에는 로맨스와 스릴러 장르의 데이터만 포함되어 있습니다. 이 경우 ML 모델이 로맨스 장르와 스릴러 장르에 대한 정보를 전혀 학습하지 않았으며, 어드벤처, 코미디, 다큐멘터리 장르의 패턴을 모델이 얼마나 잘 학습했는지 평가하지 않았습니다. 따라서 장르 정보는 쓸모가 없으며 모든 장르에 대한 ML 모델 예측의 품질이 저하됩니다. 모델과 평가가 너무 달라지게 되어(설명 통계가 매우 다름) 유용하지 않게 됩니다. 입력 데이터를 데이터 세트의 열 중 하나를 기준으로 정렬한 다음 순차적으로 분할하면 이렇게 될 수 있습니다.
학습 데이터 소스와 평가 데이터 소스의 데이터 분포가 서로 다른 경우 모델 평가 시 평가 경보가 표시됩니다. 평가 경보에 대한 자세한 내용은 평가 경보 단원을 참조하세요.
S3에서 입력 데이터를 무작위로 셔플링하거나 데이터 소스를 생성할 때 Redshift SQL 쿼리의 random() 함수 또는 MySQL 쿼리의 rand() 함수를 사용하는 등 이미 입력 데이터를 무작위로 구성한 경우 ML에서 임의 분할을 사용할 필요가 없습니다. 이러한 경우 순차 분할 옵션을 사용하여 유사한 분포의 학습 및 평가 데이터 소스를 생성할 수 있습니다.
