더 이상 Amazon Machine Learning 서비스를 업데이트하거나 새 사용자를 받지 않습니다. 이 설명서는 기존 사용자에 제공되지만 더 이상 업데이트되지 않습니다. 자세한 내용은 머신 러닝이란? 단원을 참조하세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
2단계: 학습 데이터 세트 생성
Simple Storage Service(S3) 위치에 banking.csv 데이터 세트를 업로드한 후 데이터 세트를 사용하여 학습 데이터 소스를 생성합니다. 데이터 소스는 입력 데이터와 입력 데이터에 대한 중요한 메타데이터의 위치를 포함하고 있는 Amazon Machine Learning(Amazon ML) 객체입니다. Amazon ML은 데이터 소스를 ML 모델 학습 및 평가 등의 작업에 사용합니다.
데이터 소스를 생성하려면 다음을 제공합니다.
-
데이터의 Amazon S3 위치 및 데이터에 대한 액세스 권한
-
데이터에 있는 속성의 이름과 각 속성의 유형(숫자, 텍스트, 범주형 또는 이진)을 포함하고 있는 스키마
-
Amazon ML에서 예측 방법을 학습하도록 하려는 답변(대상 속성)이 들어 있는 속성의 이름
참고
데이터 소스는 데이터를 실제로 저장하지 않고 참조만 합니다. Amazon S3에 저장된 파일을 이동하거나 변경하지 마십시오. 파일을 이동하거나 변경할 경우 Amazon ML이 해당 파일에 액세스하여 ML 모델을 만들거나 평가를 생성하거나 예측을 생성할 수 없습니다.
학습 데이터 소스를 만들려면
https://console.aws.amazon.com/machinelearning/
에서 머신 러닝 콘솔을 엽니다. -
Get started를 선택합니다.
참고
이 자습서에서는 Amazon ML을 처음 사용하는 것으로 가정합니다. 이전에 ML을 사용해 본 적이 있다면 ML 대시보드의 새로 생성... 드롭다운 목록을 사용하여 새 데이터 소스를 생성해도 됩니다.
-
머신 러닝 시작하기 페이지에서 시작을 선택합니다.
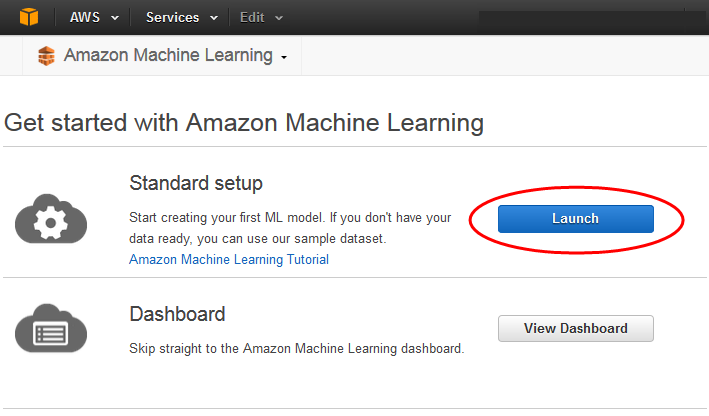
-
데이터 입력 페이지에서 데이터 위치에 대해 S3가 선택되었는지 확인합니다.

-
S3 위치에 대해 1단계: 데이터 준비의
banking.csv파일 전체 위치를 입력합니다. 예:your-bucket/banking.csv. Amazon ML이 사용자를 대신하여 버킷 이름 앞에 s3://를 추가합니다. -
데이터소스 이름에 대해
Banking Data 1를 입력합니다.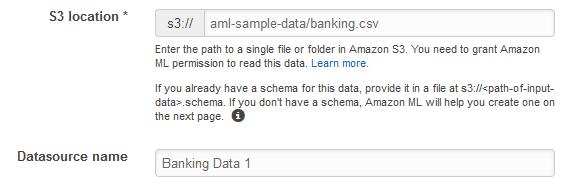
-
Verify를 선택합니다.
-
S3 권한 대화 상자에서 예를 선택합니다.
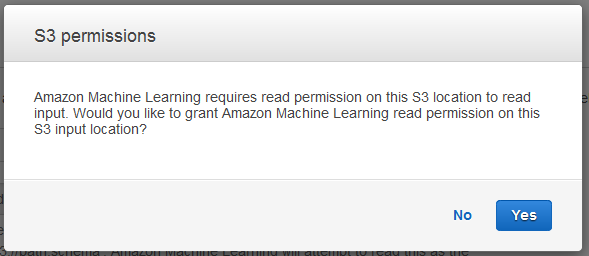
-
Amazon ML이 S3 위치의 데이터 파일에 액세스하고 읽을 수 있는 경우 다음과 비슷한 페이지가 표시됩니다. 속성을 검토한 다음 계속을 선택합니다.

그 다음, 스키마를 설정합니다. 스키마는 ML이 속성 이름 및 할당된 데이터 형식, 특수 속성의 이름 등을 포함하여 ML 모델의 입력 데이터를 해석하는 데 필요한 정보입니다. Amazon ML에 스키마를 제공하는 방법은 다음 두 가지가 있습니다.
-
Amazon S3 데이터를 업로드할 때 별도의 스키마 파일을 제공합니다.
-
Amazon ML이 속성 유형을 유추하고 스키마를 생성하도록 허용합니다.
이 자습서에서는 Amazon ML에 스키마를 유추하도록 요청할 것입니다.
별도의 스키마 파일을 생성하는 방법에 대한 자세한 내용은 Amazon ML용 데이터 스키마 생성 단원을 참조하세요.
Amazon ML이 스키마를 유추할 수 있도록 하려면
-
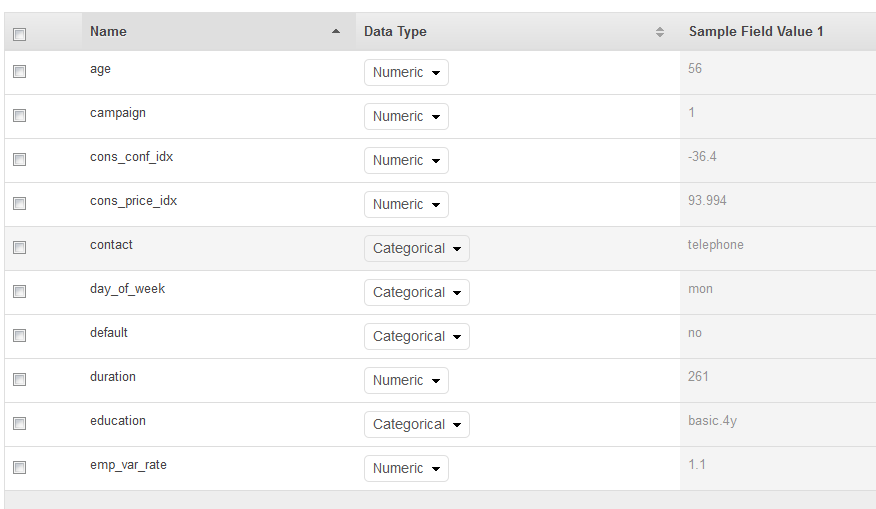
스키마 페이지에는 ML이 유추한 스키마가 표시됩니다. Amazon ML에서 속성에 대해 유추한 데이터 유형을 검토합니다. Amazon ML이 데이터를 올바르게 수집하고 속성에 대한 올바른 특성 처리를 가능하게 하려면 속성에 올바른 데이터 유형을 할당하는 것이 중요합니다.
-
예 또는 아니요와 같이 두 가지 상태만 가능한 속성은 이진으로 표시해야 합니다.
-
범주를 나타내는 데 사용되는 숫자 또는 문자열인 속성은 범주형으로 표시해야 합니다.
-
순서에 의미가 있는 숫자 수량인 속성은 숫자로 표시해야 합니다.
-
문자열을 공백으로 구분한 단어로 취급하려는 속성은 텍스트로 표시해야 합니다.
-
-
이 자습서에서는 ML이 모든 속성에 대한 데이터 유형을 올바르게 식별했으므로 계속을 선택합니다.
그 다음, 대상 속성을 선택합니다.
대상은 ML 모델이 예측 방법을 학습해야 하는 속성이라는 점을 명심하세요. 속성 y는 개인이 과거에 캠페인을 구독했는지 여부를 나타냅니다(1(예) 또는 0(아니요)).
참고
ML 모델 학습 및 평가에 데이터 소스를 사용할 경우에만 대상 속성을 선택합니다.
y를 대상 속성으로 선택하려면
-
표 오른쪽 하단에서 단일 화살표를 선택하여 표의 마지막 페이지로 이동합니다. 그러면
y라는 이름이 지정된 속성이 나타납니다.
-
대상 열에서
y를 선택합니다.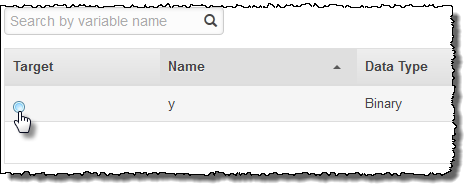
ML이 y가 대상으로 선택되었음을 확인해줍니다.
-
계속을 선택합니다.
-
행 ID 페이지에서 데이터에 식별자가 포함되어 있습니까?에 대해 기본값인 아니요가 선택되어 있는지 확인합니다.
-
계속, 등록을 차례로 선택합니다.
이제 학습 데이터 소스가 준비되었으므로 모델을 생성할 준비가 되었습니다.
