기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Apache Spark의 주요 주제
이 단원에서는 Apache Spark 성능 튜닝을 AWS Glue 위한 Apache Spark 기본 개념과 주요 주제를 설명합니다. 실제 튜닝 전략을 논의하기 전에 이러한 개념과 주제를 이해하는 것이 중요합니다.
아키텍처
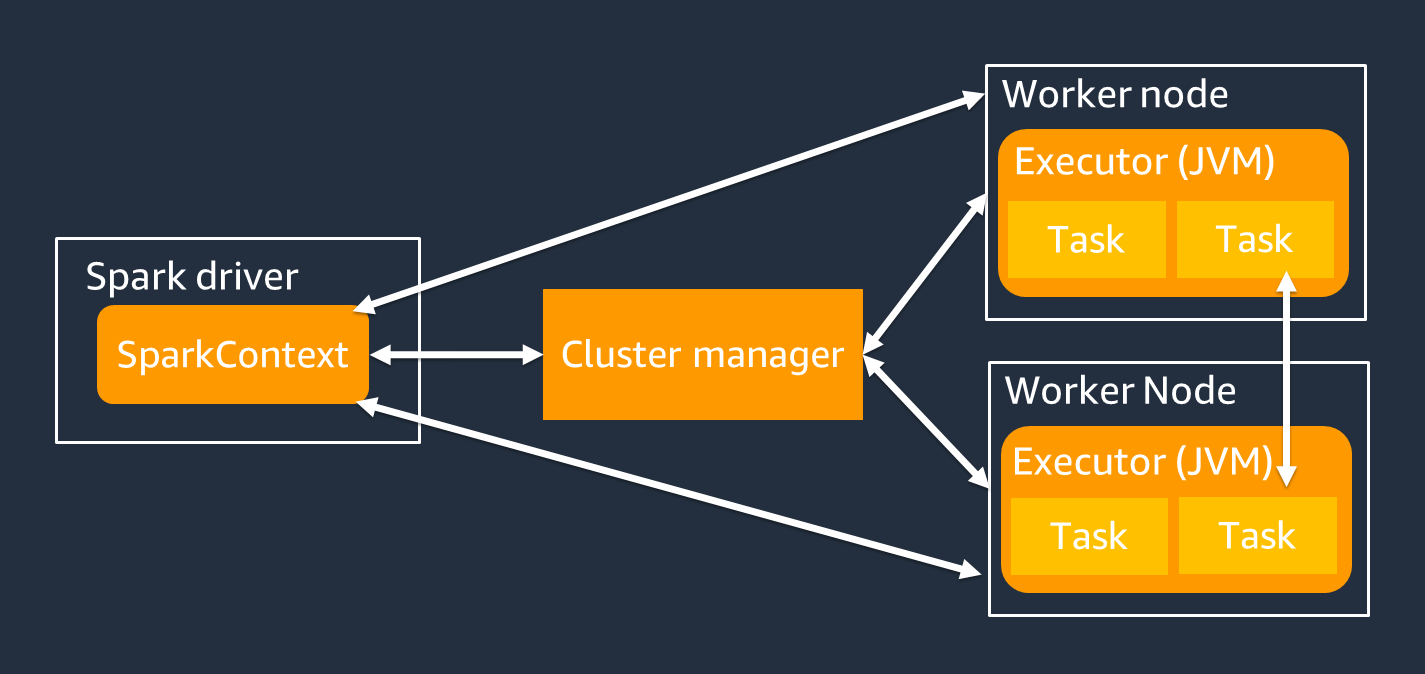
Spark 드라이버는 주로 Spark 애플리케이션을 개별 작업자에서 수행할 수 있는 작업으로 분할하는 역할을 합니다. Spark 드라이버에는 다음과 같은 책임이 있습니다.
-
코드
main()에서 실행 -
실행 계획 생성
-
클러스터의 리소스를 관리하는 클러스터 관리자와 함께 Spark 실행기 프로비저닝
-
Spark 실행기에 대한 작업 예약 및 작업 요청
-
작업 진행 상황 및 복구 관리
SparkContext 객체를 사용하여 작업 실행을 위해 Spark 드라이버와 상호 작용합니다.
Spark 실행기는 Spark 드라이버에서 전달되는 데이터를 보관하고 작업을 실행하는 작업자입니다. Spark 실행기 수는 클러스터 크기에 따라 오르내립니다.
참고
Spark 실행기에는 여러 개의 슬롯이 있으므로 여러 작업을 병렬로 처리할 수 있습니다. Spark는 기본적으로 각 가상 CPU(vCPU) 코어에 대해 하나의 작업을 지원합니다. 예를 들어 실행기에 4개의 CPU 코어가 있는 경우 4개의 동시 태스크를 실행할 수 있습니다.
탄력적 분산 데이터 세트
Spark는 Spark 실행기에서 대규모 데이터 세트를 저장하고 추적하는 복잡한 작업을 수행합니다. Spark 작업에 대한 코드를 작성할 때는 스토리지 세부 정보를 고려할 필요가 없습니다. Spark는 복원력이 뛰어난 분산 데이터 세트(RDD) 추상화를 제공합니다.이 추상화는에서 병렬로 작동할 수 있고 클러스터의 Spark 실행기에서 분할할 수 있는 요소의 모음입니다.
다음 그림은 Python 스크립트가 일반적인 환경에서 실행될 때와 Spark 프레임워크(PySpark)에서 실행될 때 메모리에 데이터를 저장하는 방법의 차이를 보여줍니다.
![Python val [1,2,3 N], Apache Spark rdd = sc.parallelize[1,2,3 N].](images/store-data-memory.png)
-
Python - Python 스크립트
val = [1,2,3...N]에 작성하면 코드가 실행되는 단일 시스템의 메모리에 데이터가 유지됩니다. -
PySpark – Spark는 RDD 데이터 구조를 제공하여 여러 Spark 실행기의 메모리에 분산된 데이터를 로드하고 처리합니다. 와 같은 코드를 사용하여 RDD를 생성할 수 있으며
rdd = sc.parallelize[1,2,3...N], Spark는 여러 Spark 실행기에서 메모리에 데이터를 자동으로 배포하고 보관할 수 있습니다.많은 AWS Glue 작업에서 DynamicFrames 및 Spark DataFrames를 통해 AWS Glue RDDs를 사용합니다. DataFrames 이는 RDD에서 데이터의 스키마를 정의하고 해당 추가 정보로 상위 수준 작업을 수행할 수 있는 추상화입니다. RDDs 내부적으로 사용하기 때문에 데이터는 투명하게 배포되고 다음 코드의 여러 노드에 로드됩니다.
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
RDD에는 다음과 같은 기능이 있습니다.
-
RDDs 파티션이라는 여러 부분으로 분할된 데이터로 구성됩니다. 각 Spark 실행기는 하나 이상의 파티션을 메모리에 저장하고 데이터는 여러 실행기에 분산됩니다.
-
RDDs는 변경할 수 없습니다. 즉, 생성된 후에는 변경할 수 없습니다. DataFrame을 변경하려면 다음 섹션에 정의된 변환을 사용할 수 있습니다.
-
RDDs 사용 가능한 노드 간에 데이터를 복제하므로 노드 장애로부터 자동으로 복구할 수 있습니다.
지연 평가
RDDs 기존 작업에서 새 데이터 세트를 생성하는 변환과 데이터 세트에서 계산을 실행한 후 드라이버 프로그램에 값을 반환하는 작업이라는 두 가지 유형의 작업을 지원합니다.
-
변환 - RDDs는 변경할 수 없으므로 변환을 사용해야만 변경할 수 있습니다.
예를 들어
map는 각 데이터 세트 요소를 함수를 통해 전달하고 결과를 나타내는 새 RDD를 반환하는 변환입니다.map메서드는 출력을 반환하지 않습니다. Spark는 결과와 상호 작용할 수 있도록 하는 대신 향후 추상 변환을 저장합니다. Spark는 사용자가 작업을 호출할 때까지 변환에 대해 작업하지 않습니다. -
작업 - 변환을 사용하여 논리적 변환 계획을 수립합니다. 계산을 시작하려면 ,
write,countshow또는 같은 작업을 실행합니다collect.Spark의 모든 변환은 결과를 즉시 계산하지 않기 때문에 지연됩니다. 대신 Spark는 Amazon Simple Storage Service(Amazon S3) 객체와 같은 일부 기본 데이터세트에 적용된 일련의 변환을 기억합니다. 변환은 작업이 드라이버에 결과를 반환해야 하는 경우에만 계산됩니다. 이 설계를 통해 Spark를 더 효율적으로 실행할 수 있습니다. 예를 들어,
map변환을 통해 생성된 데이터 세트가와 같이 행 수를 크게 줄이는 변환에 의해서만 사용되는 상황을 생각해 보세요reduce. 그런 다음 매핑된 더 큰 데이터 세트를 전달하는 대신 두 변환을 모두 수행한 더 작은 데이터 세트를 드라이버에 전달할 수 있습니다.
Spark 애플리케이션의 용어
이 섹션에서는 Spark 애플리케이션 용어를 다룹니다. Spark 드라이버는 실행 계획을 생성하고 여러 추상화에서 애플리케이션의 동작을 제어합니다. 다음 용어는 Spark UI를 사용한 개발, 디버깅 및 성능 튜닝에 중요합니다.
-
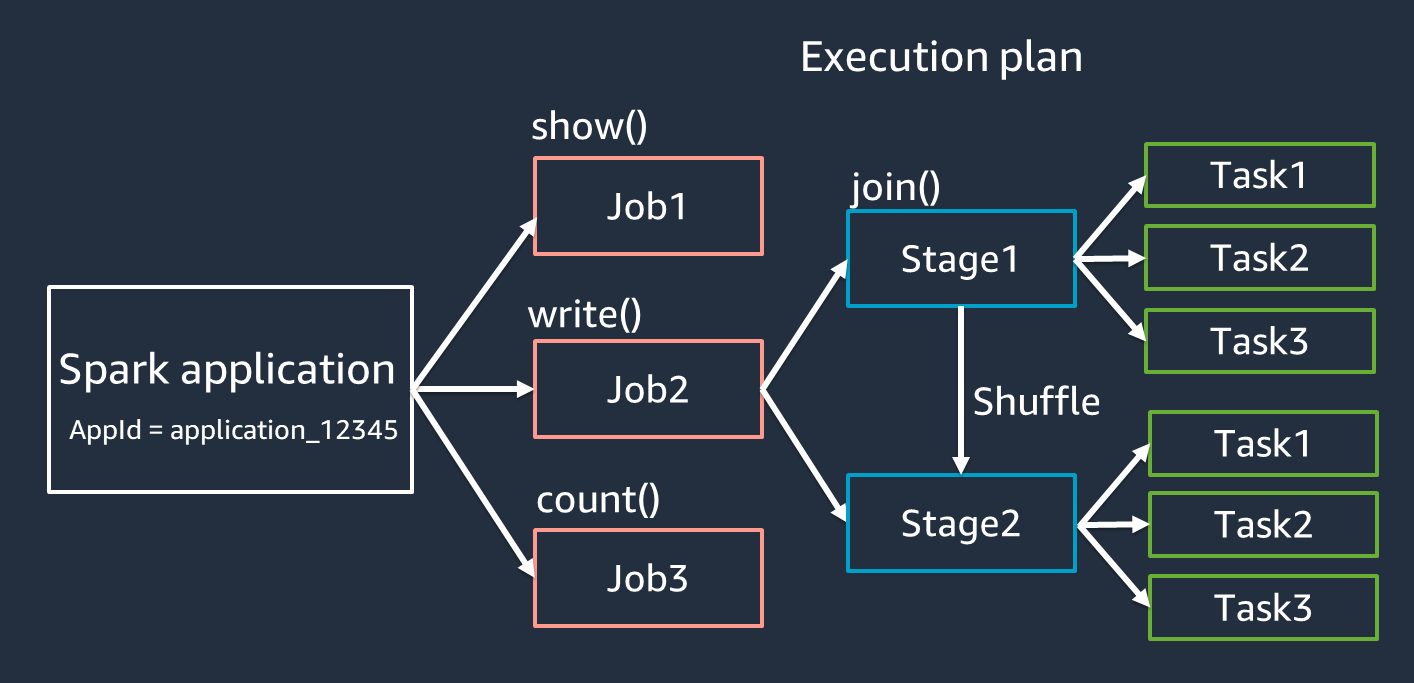
애플리케이션 - Spark 세션(Spark 컨텍스트)을 기반으로 합니다. 와 같은 고유 ID로 식별됩니다
<application_XXX>. -
작업 - RDD에 대해 생성된 작업을 기반으로 합니다. 작업은 하나 이상의 단계로 구성됩니다.
-
스테이지 - RDD에 대해 생성된 셔플 을 기반으로 합니다. 단계는 하나 이상의 작업으로 구성됩니다. 셔플은 RDD 파티션 간에 다르게 그룹화되도록 데이터를 재배포하기 위한 Spark의 메커니즘입니다. 와 같은 특정 변환에는 셔플이
join()필요합니다. 셔플은 셔플 튜닝 최적화 연습에서 자세히 설명합니다. -
작업 - 작업은 Spark에서 예약한 최소 처리 단위입니다. 태스크는 각 RDD 파티션에 대해 생성되며 태스크 수는 스테이지의 최대 동시 실행 수입니다.
참고
병렬 처리를 최적화할 때 고려해야 할 가장 중요한 사항은 태스크입니다. RDD 수에 따라 조정되는 작업 수
Parallelism
Spark는 데이터 로드 및 변환 작업을 병렬화합니다.
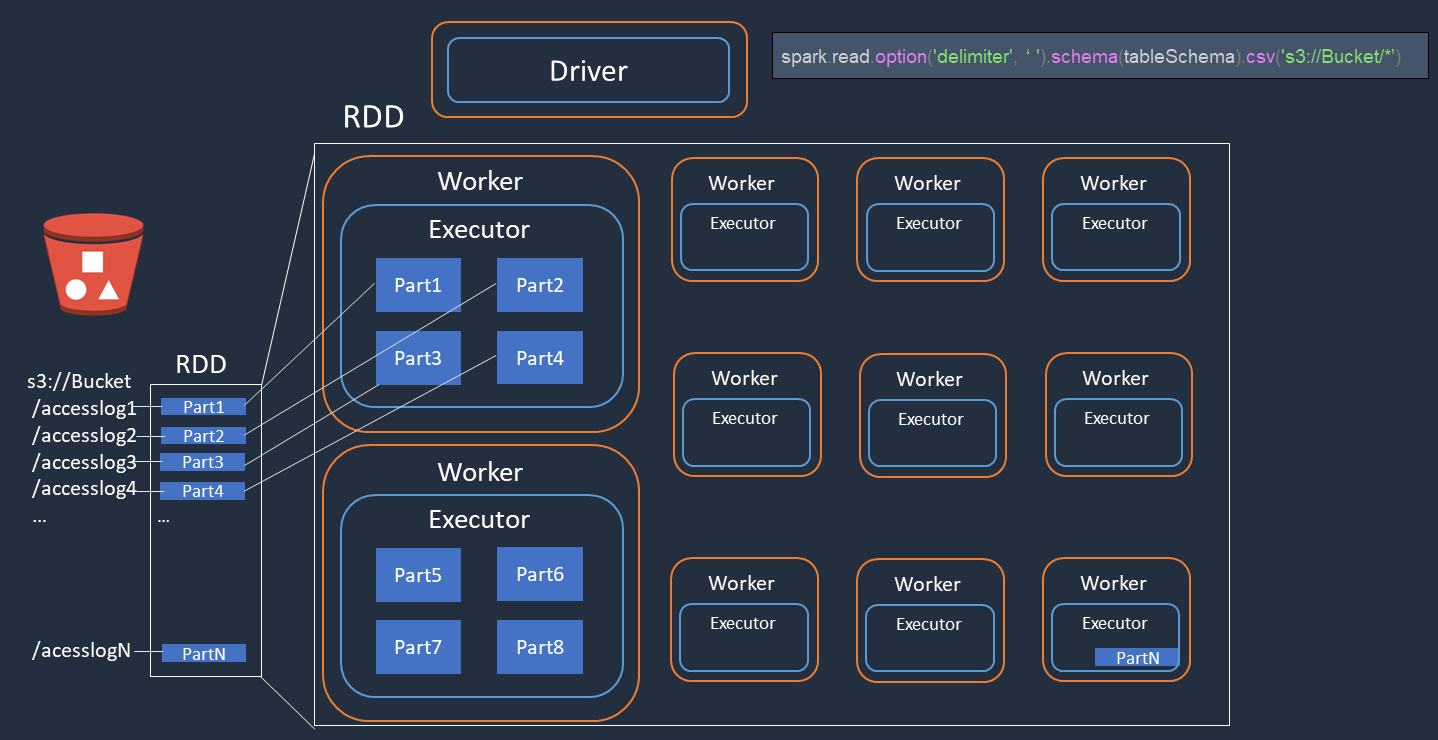
Amazon S3accesslog1 ... accesslogN에서 액세스 로그 파일()의 분산 처리를 수행하는 예를 생각해 보세요. 다음 다이어그램은 분산 처리 흐름을 보여줍니다.
-
Spark 드라이버는 많은 Spark 실행기에서 분산 처리를 위한 실행 계획을 생성합니다.
-
Spark 드라이버는 실행 계획에 따라 각 실행기에 작업을 할당합니다. 기본적으로 Spark 드라이버는 각 S3 객체()에 대해 RDD 파티션(각각 Spark 작업에 해당)을 생성합니다
Part1 ... N. 그런 다음 Spark 드라이버는 각 실행기에 작업을 할당합니다. -
각 Spark 작업은 할당된 S3 객체를 다운로드하여 RDD 파티션의 메모리에 저장합니다. 이렇게 하면 여러 Spark 실행기가 할당된 작업을 병렬로 다운로드하고 처리합니다.
초기 파티션 수 및 최적화에 대한 자세한 내용은 병렬 작업 섹션을 참조하세요.
Catalyst 최적화 프로그램
내부적으로 Spark는 Catalyst 옵티마이저
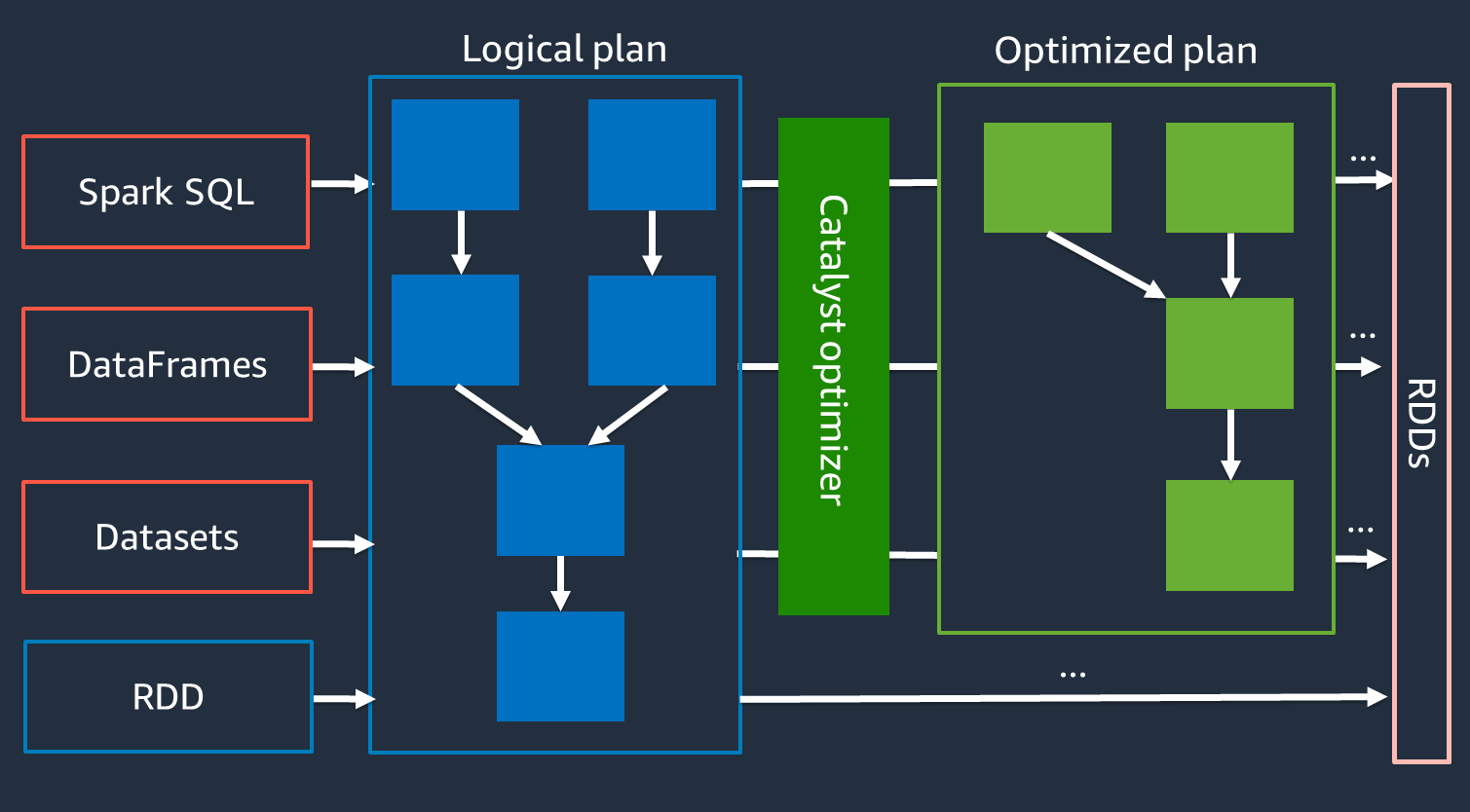
Catalyst 옵티마이저는 RDD API와 직접 작동하지 않으므로 상위 수준 APIs는 일반적으로 하위 수준 RDD API보다 빠릅니다. 복합 조인의 경우 Catalyst 최적화 프로그램은 작업 실행 계획을 최적화하여 성능을 크게 개선할 수 있습니다. Spark UI의 SQL 탭에서 Spark 작업의 최적화된 계획을 볼 수 있습니다.
적응형 쿼리 실행
Catalyst 옵티마이저는 Adaptive Query Execution이라는 프로세스를 통해 런타임 최적화를 수행합니다. 적응형 쿼리 실행은 런타임 통계를 사용하여 작업이 실행되는 동안 쿼리의 실행 계획을 다시 최적화합니다. 적응형 쿼리 실행은 다음 섹션에 설명된 대로 셔플 파티션 후 병합, 정렬 병합 조인을 브로드캐스트 조인으로 변환, 스큐 조인 최적화를 비롯한 성능 문제에 대한 여러 솔루션을 제공합니다.
적응형 쿼리 실행은 AWS Glue 3.0 이상에서 사용할 수 있으며 기본적으로 AWS Glue 4.0(Spark 3.3.0) 이상에서 활성화됩니다. 코드spark.conf.set("spark.sql.adaptive.enabled", "true")에서를 사용하여 적응형 쿼리 실행을 켜거나 끌 수 있습니다.
셔플 후 파티션 병합
이 기능은 map 출력 통계를 기반으로 각 셔플 후 RDD 파티션(코일스)을 줄입니다. 쿼리를 실행할 때 셔플 파티션 번호의 튜닝을 간소화합니다. 데이터 세트에 맞게 셔플 파티션 번호를 설정할 필요가 없습니다. Spark는 초기 셔플 파티션 수가 충분히 많으면 런타임에 적절한 셔플 파티션 번호를 선택할 수 있습니다.
spark.sql.adaptive.enabled 및가 모두 true로 설정된 경우 셔플 후 파티션 병합spark.sql.adaptive.coalescePartitions.enabled이 활성화됩니다. 자세한 내용은 Apache Spark 설명서를
sort-merge 조인을 브로드캐스트 조인으로 변환
이 기능은 크기가 상당히 다른 두 데이터 세트를 조인할 때를 인식하고 해당 정보를 기반으로 보다 효율적인 조인 알고리즘을 채택합니다. 자세한 내용은 Apache Spark 설명서를
스큐 조인 최적화
데이터 스큐는 Spark 작업에서 가장 일반적인 병목 현상 중 하나입니다. 이는 데이터가 특정 RDD 파티션(및 결과적으로 특정 작업)으로 왜곡되어 애플리케이션의 전체 처리 시간이 지연되는 상황을 설명합니다. 이렇게 하면 조인 작업의 성능이 저하되는 경우가 많습니다. 스큐 조인 최적화 기능은 스큐된 태스크를 대략 짝수 크기의 태스크로 분할(및 필요한 경우 복제)하여 정렬 병합 조인의 스큐를 동적으로 처리합니다.
이 기능은이 true로 spark.sql.adaptive.skewJoin.enabled 설정된 경우 활성화됩니다. 자세한 내용은 Apache Spark 설명서를
