기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
작업을 병렬화합니다.
성능을 최적화하려면 데이터 로드 및 변환 작업을 병렬화하는 것이 중요합니다. Apache Spark의 주요 항목에서 설명했듯이 복원력이 있는 분산 데이터 세트 (RDD) 파티션의 수는 병렬 처리 정도를 결정하기 때문에 중요합니다. Spark에서 생성하는 각 작업은 1:1 기준으로 파티션에 해당합니다. RDD 최상의 성능을 얻으려면 파티션 수를 결정하는 방법과 RDD 파티션 수를 최적화하는 방법을 이해해야 합니다.
병렬 처리가 충분하지 않은 경우 다음과 같은 현상이 CloudWatch메트릭과 Spark UI에 기록됩니다.
CloudWatch 메트릭스
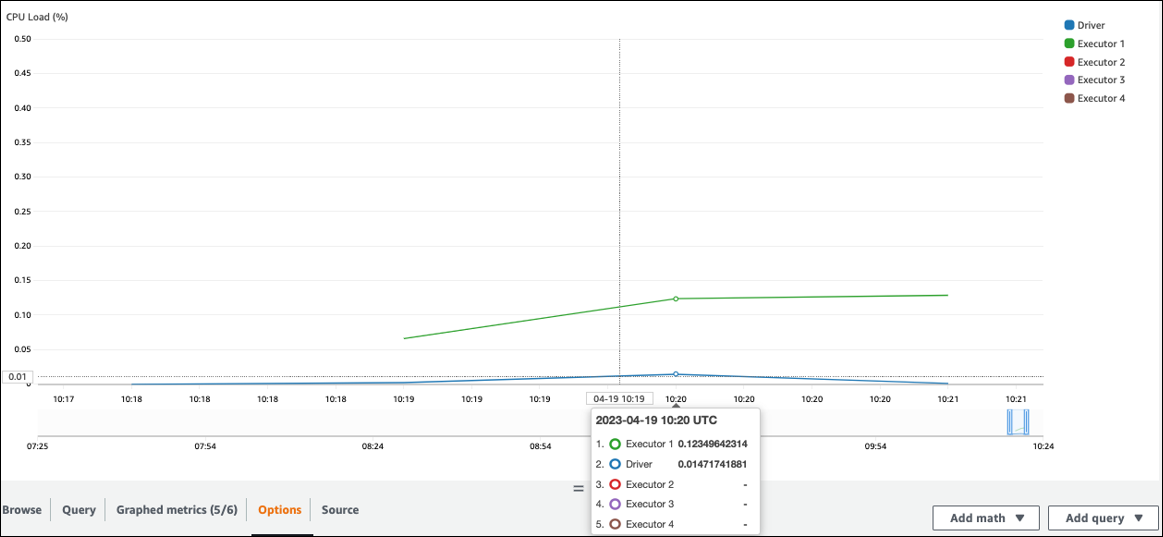
CPU로드 및 메모리 사용률을 확인하세요. 일부 실행기가 작업 단계에서 처리를 하지 않는 경우 병렬 처리를 개선하는 것이 좋습니다. 이 경우 시각화된 기간 동안 실행자 1은 작업을 수행했지만 나머지 실행자 (2, 3, 4) 는 수행하지 않았습니다. Spark 드라이버가 해당 실행기에 작업을 할당하지 않았음을 유추할 수 있습니다.
Spark UI
Spark UI의 스테이지 탭에서 스테이지의 작업 수를 확인할 수 있습니다. 이 경우 Spark는 단 하나의 작업만 수행했습니다.

또한 이벤트 타임라인에는 Executor 1이 하나의 작업을 처리하는 모습이 표시됩니다. 즉, 이 단계의 작업은 한 실행자에서만 수행되고 다른 실행기는 유휴 상태였습니다.

이러한 증상이 나타나는 경우 각 데이터 원본에 대해 다음 해결 방법을 시도해 보십시오.
Amazon S3에서 데이터 로드를 병렬화합니다.
Amazon S3에서 데이터 로드를 병렬화하려면 먼저 기본 파티션 수를 확인하십시오. 그런 다음 대상 파티션 수를 수동으로 결정할 수 있지만 파티션이 너무 많지 않도록 하십시오.
기본 파티션 수를 결정하십시오.
Amazon S3의 경우 초기 Spark RDD 파티션 수 (각 파티션은 Spark 작업에 해당) 는 Amazon S3 데이터 세트의 기능 (예: 형식, 압축, 크기) 에 따라 결정됩니다. Amazon S3에 저장된 DataFrame CSV 객체에서 AWS Glue DynamicFrame 또는 Spark를 생성할 때 초기 RDD 파티션 수 (NumPartitions) 는 다음과 같이 대략적으로 계산할 수 있습니다.
-
객체 크기 <= 64MB:
NumPartitions = Number of Objects -
64메가바이트 이상의 오브젝트 크기:
NumPartitions = Total Object Size / 64 MB -
분할 불가 (gzip):
NumPartitions = Number of Objects
데이터 스캔량 줄이기 섹션에서 설명한 것처럼 Spark는 대용량 S3 객체를 병렬로 처리할 수 있는 분할로 나눕니다. 객체가 분할 크기보다 큰 경우 Spark는 객체를 분할하고 분할할 때마다 RDD 파티션 (및 작업) 을 생성합니다. Spark의 분할 크기는 데이터 형식과 런타임 환경에 따라 달라지지만, 시작 시 이 정도면 적당합니다. 일부 객체는 gzip과 같은 분할할 수 없는 압축 형식을 사용하여 압축되므로 Spark는 객체를 분할할 수 없습니다.
NumPartitions값은 데이터 형식, 압축, AWS Glue 버전, AWS Glue 작업자 수, Spark 구성에 따라 달라질 수 있습니다.
예를 들어 DataFrame Spark를 사용하여 10GB csv.gz 객체 하나를 로드하는 경우 gzip은 분할할 수 없으므로 Spark 드라이버는 RDD 파티션 (NumPartitions=1) 을 하나만 생성합니다. 이로 인해 특정 Spark 실행기 하나에 과부하가 발생하고 다음 그림에 설명된 것처럼 나머지 실행기에는 작업이 할당되지 않습니다.
Spark Web UI Stage 탭에서 스테이지의 실제 작업 수 (NumPartitions) 를 확인하거나 코드를 실행하여 df.rdd.getNumPartitions() 병렬성을 확인하십시오.
10GB의 gzip 파일이 있는 경우 해당 파일을 생성하는 시스템에서 파일을 분할 가능한 형식으로 생성할 수 있는지 확인하십시오. 이 옵션을 사용할 수 없는 경우 파일을 처리하기 위해 클러스터 용량을 확장해야 할 수 있습니다. 로드한 데이터에서 변환을 효율적으로 실행하려면 repartition을 사용하여 클러스터의 작업자 RDD 간에 균형을 재조정해야 합니다.
목표 파티션 수를 수동으로 결정하십시오.
데이터의 속성과 Spark의 특정 기능 구현에 따라 기본 작업을 병렬화할 수 있더라도 결국 낮은 NumPartitions 값이 나올 수 있습니다. NumPartitions크기가 너무 작으면 처리를 여러 Spark df.repartition(N) 실행기에 분산할 수 있도록 실행하여 파티션 수를 늘리십시오.
이 경우 실행 횟수가 NumPartitions 1개에서 100개로 df.repartition(100) 늘어나 데이터 파티션 100개가 생성되고 각 파티션에는 다른 실행기에 할당할 수 있는 작업이 포함됩니다.
이 작업은 전체 데이터를 균등하게 repartition(N) 분할하므로 (10GB/100 파티션 = 100MB/파티션당) 데이터가 특정 파티션으로 치우치지 않습니다.
참고
등의 join 셔플 작업을 실행하면 또는 값에 따라 파티션 수가 동적으로 늘거나 줄어듭니다. spark.sql.shuffle.partitions spark.default.parallelism 이렇게 하면 Spark 실행기 간에 데이터를 더 효율적으로 교환할 수 있습니다. 자세한 내용은 Spark 설명서를 참조하십시오.
대상 파티션 수를 결정할 때 목표는 AWS Glue 프로비전된 작업자의 사용을 극대화하는 것입니다. AWS Glue 작업자 수와 Spark 작업 수는 작업자 수에 따라 달라집니다. vCPUs Spark는 각 v CPU 코어에 대해 하나의 작업을 지원합니다. AWS Glue 버전 3.0 이상에서는 다음 공식을 사용하여 대상 파티션 수를 계산할 수 있습니다.
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
이 예제에서 각 G.1X 워커는 Spark 실행기에 v CPU 코어 4개를 제공합니다 (). spark.executor.cores = 4 Spark는 v CPU Core당 하나의 작업을 지원하므로 G.1X Spark 실행기는 4개의 작업을 동시에 실행할 수 있습니다 (). numSlotPerExecutor 작업에 동일한 시간이 소요되는 경우 이 수의 파티션을 사용하면 클러스터를 최대한 활용할 수 있습니다. 하지만 일부 작업은 다른 작업보다 시간이 오래 걸려 코어가 유휴 상태가 됩니다. 이런 경우에는 2 또는 3을 numPartitions 곱하여 병목 현상이 발생하는 작업을 분류하고 효율적으로 일정을 잡는 것이 좋습니다.
파티션이 너무 많습니다.
파티션 수가 너무 많으면 작업 수가 너무 많아집니다. 이로 인해 관리 작업 및 Spark 실행자 간 데이터 교환과 같은 분산 처리와 관련된 오버헤드로 인해 Spark 드라이버에 과부하가 발생합니다.
작업의 파티션 수가 목표 파티션 수보다 훨씬 많으면 파티션 수를 줄이는 것이 좋습니다. 다음 옵션을 사용하여 파티션을 줄일 수 있습니다.
-
파일 크기가 매우 작은 경우 사용하십시오 AWS Glue groupFiles. Apache Spark 작업을 실행하여 각 파일을 처리할 때 발생하는 과도한 병렬 처리를 줄일 수 있습니다.
-
파티션을
coalesce(N)병합하는 데 사용합니다. 이는 비용이 적게 드는 프로세스입니다. 셔플을repartition(N)수행하여 각 파티션의 레코드 양을repartition(N)균등하게 분배하므로 파티션 수를 줄일 때는 이 보다coalesce(N)선호됩니다. 이로 인해 비용과 관리 오버헤드가 증가합니다. -
Spark 3.x 적응형 쿼리 실행을 사용하세요. Apache Spark의 주요 항목에서 설명한 것처럼 적응형 쿼리 실행은 파티션 수를 자동으로 통합하는 기능을 제공합니다. 실행을 수행하기 전까지 파티션 수를 알 수 없는 경우 이 방법을 사용할 수 있습니다.
에서 데이터 로드를 병렬화합니다. JDBC
Spark RDD 파티션 수는 구성에 따라 결정됩니다. 기본적으로 쿼리를 통해 전체 소스 데이터세트를 스캔하는 작업은 한 번만 실행됩니다. SELECT
둘 다 AWS Glue DynamicFrames Spark와 Spark는 DataFrames 여러 작업에 걸쳐 병렬화된 JDBC 데이터 로드를 지원합니다. 이는 where 조건자를 사용하여 하나의 SELECT 쿼리를 여러 쿼리로 분할하는 방식으로 이루어집니다. 에서 읽기를 JDBC 병렬화하려면 다음 옵션을 구성하십시오.
-
For AWS Glue DynamicFrame, 설정
hashfield(또는hashexpression)).hashpartition자세히 알아보려면 JDBC테이블에서 병렬로 읽기를 참조하십시오.connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
Spark의 경우 DataFrame,
numPartitionspartitionColumnlowerBound, 및upperBound를 설정합니다. 자세히 JDBC알아보려면 다른 데이터베이스로을참조하십시오. df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
커넥터를 사용할 때 DynamoDB에서 데이터 로드를 병렬화합니다. ETL
Spark RDD 파티션의 수는 파라미터에 의해 결정됩니다. dynamodb.splits Amazon DynamoDB에서 읽기를 병렬화하려면 다음 옵션을 구성하십시오.
-
의 가치를 높이십시오.
dynamodb.splits -
AWS Glue Spark용 ETL in의 연결 유형 및 옵션에 설명된 공식에 따라 매개변수를 최적화하십시오.
Kinesis Data Streams에서 데이터 로드를 병렬화합니다.
Spark RDD 파티션의 수는 원본 Amazon Kinesis Data Streams 데이터 스트림의 샤드 수에 따라 결정됩니다. 데이터 스트림에 샤드가 몇 개만 있는 경우 Spark 작업은 몇 개만 남게 됩니다. 이로 인해 다운스트림 프로세스의 병렬성이 낮아질 수 있습니다. Kinesis Data Streams에서 읽기를 병렬화하려면 다음 옵션을 구성하십시오.
-
Kinesis Data Streams에서 데이터를 로드할 때 병렬성을 높이려면 샤드 수를 늘리십시오.
-
마이크로 배치의 로직이 충분히 복잡한 경우 일괄 처리 시작 시 불필요한 열을 삭제한 후 데이터를 다시 파티셔닝하는 것을 고려해 보십시오.
자세한 내용은 스트리밍 작업의 비용 및 성능 최적화를 위한 모범 사례를
데이터 로드 후 작업을 병렬화합니다.
데이터 로드 후 작업을 병렬화하려면 다음 옵션을 사용하여 RDD 파티션 수를 늘리십시오.
-
데이터를 다시 파티셔닝하여 더 많은 파티션을 생성합니다. 특히 로드 자체를 병렬화할 수 없는 경우 초기 로드 직후에 더 많이 생성합니다.
파티션 수를 지정하여
repartition()DynamicFrame on이나 DataFrame 를 호출하십시오. 일반적으로 사용 가능한 코어 수의 2~3배입니다.하지만 파티션을 나눈 테이블을 작성할 때 이로 인해 파일이 폭증할 수 있습니다. 각 파티션은 잠재적으로 각 테이블 파티션에 파일을 생성할 수 있습니다. 이를 방지하기 위해 DataFrame 기준 열을 다시 분할할 수 있습니다. 여기에는 테이블 파티션 열이 사용되므로 쓰기 전에 데이터가 정리됩니다. 테이블 파티션에 작은 파일을 넣지 않고도 더 많은 수의 파티션을 지정할 수 있습니다. 그러나 일부 파티션 값에 대부분의 데이터가 포함되고 작업 완료가 지연되는 데이터 왜곡을 피해야 합니다.
-
셔플이 있는 경우에는 값을 늘리십시오.
spark.sql.shuffle.partitions셔플링할 때 발생하는 메모리 문제에도 도움이 될 수 있습니다.셔플 파티션이 2,001개 이상인 경우 Spark는 압축 메모리 형식을 사용합니다. 숫자가 이에 가까우면
spark.sql.shuffle.paritions값을 이 한도 이상으로 설정하여 더 효율적으로 표현할 수 있습니다.
